Основная обязанность специалиста по работе с данными (специалиста по работе с данными, инженера по обработке данных, аналитика данных и т. д.) заключается в нахождении, очистке, проверке и извлечении ценной информации из данных. для деловых целей.
Это может быть сложно, особенно когда речь идет о сборе данных для проекта.
Несмотря на огромное количество доступных данных, зачастую получить к ним доступ непросто.
Я знаю, это очень утомительно, верно!😭
Но не волнуйтесь, веб-скрапинг прикроет вашу спину.
Итак,
Что такое просмотр веб-страниц и зачем мы это делаем?
Веб-скрапинг — это автоматизированный метод сбора данных с веб-сайта для анализа.
У специалистов по обработке данных есть уникальная возможность получить данные с помощью парсинга веб-страниц, доступ к которым иначе был бы невозможен.
Хорошим примером является то, что большинство компаний имеют обширные веб-сайты, недоступные для третьих лиц через API. Таким образом, нам потребуется очистить эти данные, чтобы получить к ним доступ.
Самый популярный метод парсинга веб-страниц — использование асинхронного метода с Beautiful Soup и httpx.
Сегодня мы попробуем кое-что новое.🙂
*барабанная дробь!!!🥁 Представляем….
Пакет request-html!
В организационных целях мы рассмотрим:
<цитата>- Что такое пакет request-html и как его использовать.
- Асинхронный просмотр веб-страниц с помощью пакета request-html
- Очистка данных с помощью «панд».
Что такое пакет request-html и как его использовать.
Давайте немного разберемся с «requests-html», прежде чем мы начнем его использовать. Библиотека Python «requests-html» упрощает и упрощает анализ HTML. Кеннет Рейц, который также создал библиотеку "requests", был ее создателем. В дополнение к пакету "requests" он включает следующие функции:
<цитата>- Полная поддержка JavaScript!
- Селекторы CSS (также известные как jQuery, благодаря PyQuery).
- Селекторы XPath для слабонервных.
- Имитированный пользовательский агент (как настоящий веб-браузер).
- Автоматическое перенаправление.
- Объединение соединений и сохранение файлов cookie.
- Знакомые и любимые вами функции Requests с волшебными возможностями синтаксического анализа.
- Поддержка асинхронного режима
Одна из замечательных особенностей «requests-html» заключается в том, что вы можете быстро (асинхронно) очищать веб-сайты.
Асинхронный просмотр веб-страниц с помощью пакета request-html
Мы будем использовать бесплатную облачную записную книжку для совместной работы, к которой вы можете получить доступ через свою учетную запись Google, которая называется Google Colab. для этого проекта.
Все, что вам нужно сделать, это зарегистрироваться, создать блокнот и начать работу.
!pip install requests-html
Для демонстрации мы будем собирать бестселлеры с веб-сайта bookdepository. >
Код всей статьи можно найти здесь После установки мы импортируем пакет.
from requests_html import AsyncHTMLSession
asession = AsyncHTMLSession()
r = await asession.get("https://www.bookdepository.com/bestsellers")
После создания его экземпляра мы использовали метод get сеанса для доступа к нашему веб-сайту. Проверка кода состояния сейчас покажет, что это было успешно (200).
# find out if successful
r.status_code
Мы получаем титулы
Теперь можно получить интересующую нас информацию, начиная с названий книг. Используя инструменты разработчика Chrome, мы можем изучить исходный HTML-код, чтобы определить, какой параметр xpath или CSS следует использовать для получения наших данных.
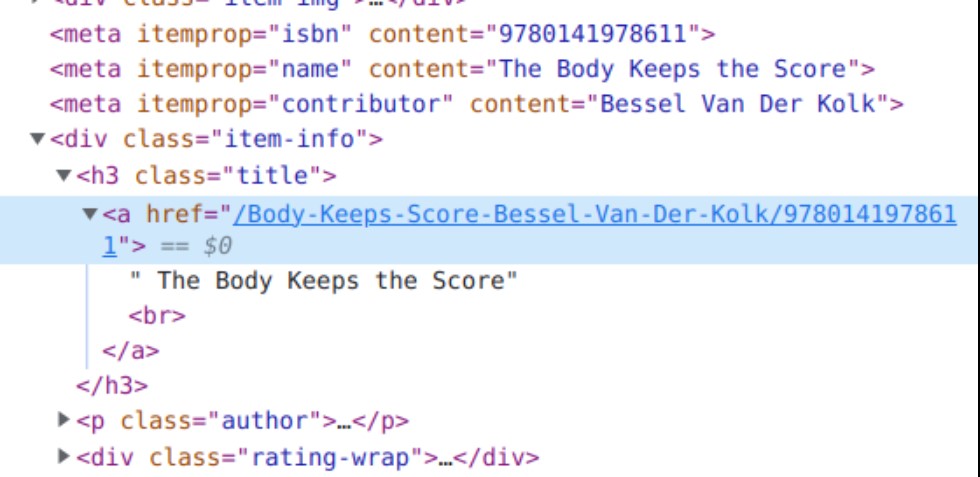
Источник: веб-страница
# We get the titles
page = 1
titles = []
while page != 35:
for x in r.html.find("h3.title"):
titles.append(x.text)
page +=1
Как видите, изначально мы установили 2 переменные: «page» для отслеживания страниц веб-сайта и «titles» для хранения наших данных. После этого мы использовали «цикл while» для перебора наших страниц и сбора данных, когда всего было менее 35 страниц (на веб-сайте 34 страницы). n Вы можете использовать «chrome devtools», чтобы проверить «нумерацию страниц» на странице.
Затем, передавая наш селектор CSS (который представляет собой тег «h3» с классом «title»), мы использовали метод «find» из «requests-html» в нашем HTML-контенте для получения наших данных. Затем результат был добавлен в нашу коллекцию «названий». Теперь, если вы посмотрите, сколько наименований в нашем списке, их примерно 1020.
Для остальных переменных, которые нас интересуют, процедура повторится. Не забудьте просмотреть исходный код страницы, чтобы найти подходящие селекторы CSS для необходимых вам компонентов.
len(titles) # check the length -> 1020
titles[:10] # take a peek
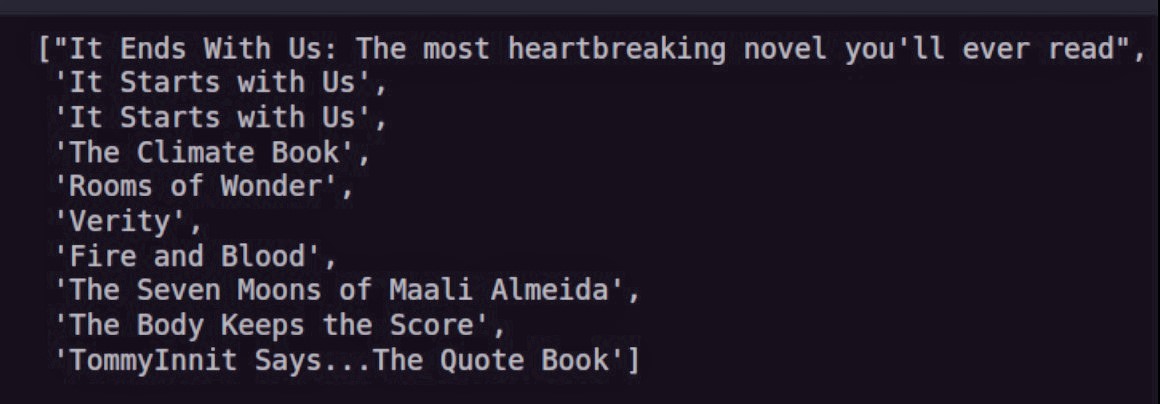
Мы получаем авторов
# We get the authors
page = 1
authors = []
while page != 35:
for x in r.html.find("p.author"):
authors.append(x.text)
page +=1
Мы также проверяем длину только что извлеченных данных.
len(authors) -> 1020
# check the first 10 rows
authors[:10]
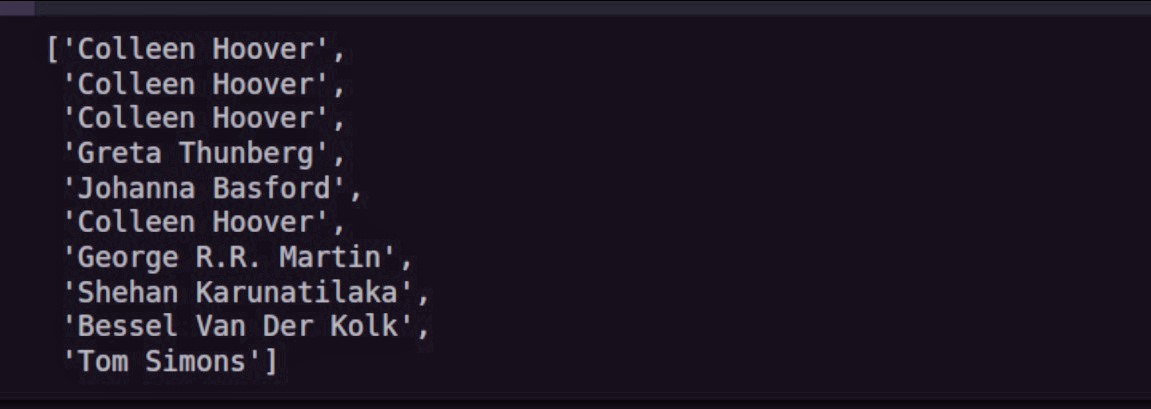
Мы получаем цены
# We get the prices
page = 1
prices = []
while page != 35:
for x in r.html.find("p.price"):
prices.append(x.text)
page +=1
len(prices) # -> 1020
prices[:10]
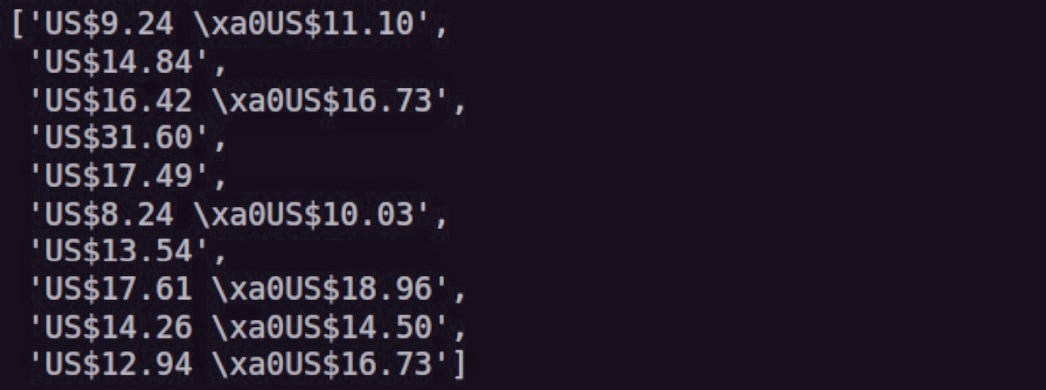
Нам, очевидно, нужно сильно почистить нашу ценовую переменную. Позже мы займемся этим.
n Затем мы получаем рейтинги
# We get the ratings
page = 1
stars = []
while page != 35:
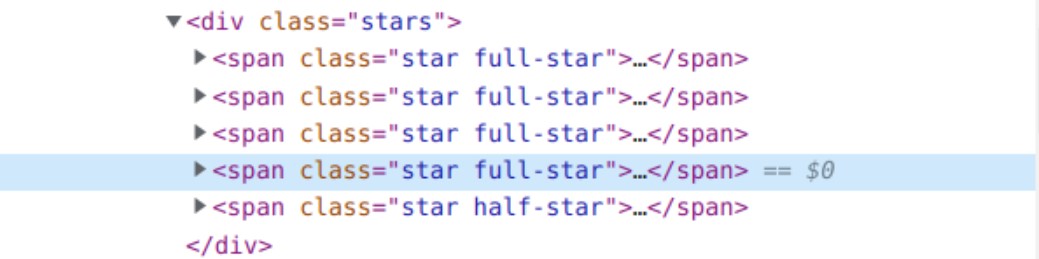
for x in r.html.find("div.stars"):
result = x.find("span.star.full-star")
stars.append(len(result))
page +=1
Сначала мы должны получить элемент со звездочками и подсчитать их количество для каждой книги, чтобы определить наши рейтинги, которые представлены звездочками.
К сожалению, не у всех книг есть оценки, поэтому недостающую информацию мы рассмотрим позже.
len(stars) -> 748
# check the rating at row 34
stars[34]
Мы получаем книжные форматы
# We get the book formats
page = 1
formats = []
while page != 35:
for x in r.html.find("p.format"):
formats.append(x.text)
page +=1
Чтобы убедиться, что у нас есть все данные, мы можем проверить длину.
len(formats) -> 1020
# check 10 rows
formats[:10]

Очистка данных с помощью «панд»
Создание кадра данных
Наши данные были эффективно очищены, однако они еще не очищены. Мы должны очистить его и сохранить для дальнейшего анализа. Для этого нам нужно использовать pandas. Мы будем использовать наши данные для создания фрейма данных.
Напомнить, чтобы установить Pandas:
pip install pandas
# We put it into a DataFrame
import pandas as pd
stars = pd.Series(stars)
df = pd.DataFrame(list(zip(titles, authors, prices, formats)),
columns=["titles", "authors", "prices", "formats"])
# to add the stars
df["rating"] = stars
df.shape # -> (1020, 5)
# To check our data
df.head()

# To check the last values
df.tail()

Вы увидите, что наши данные содержат несколько пропущенных значений. Позже нам нужно решить эту проблему. С пропущенными значениями можно работать различными способами. У вас есть два варианта: лечить их или бросить. Мы будем обрабатывать их, потому что отказаться от них для нашего небольшого набора данных не вариант. Это можно сделать разными способами. Мы можем либо заменить значения новыми, либо заполнить их средним или медианным значением переменной (не числовым).
Очищаем данные
# We start by cleaning the price values
# We remove the strike-through price.
df["prices"] = df.prices.str.replace("xa0*", "")
Чтобы удалить нежелательные символы из данных, мы используем метод replace метода 'str' в этом коде. Вы также заметите, что наши данные содержат две цены. У нас есть старые данные в списке после новых данных. Для нас важна только новая цена, которая появляется первой в столбце цен.
# To get the current price value
df["prices"] = df["prices"].apply(lambda x: x.split(" ")[0])
Мы применили функцию, которая делит значения на "пробелы", а затем извлекли первое значение, которое является нашей новой ценой, используя метод применения "pandas" для получения новой цены. Вы увидите, что мы также искали все символы после 0 символов, используя подстановочный знак *.
Наша колонка с ценами все еще нуждается в некоторой доработке, но если мы проверим наши данные прямо сейчас, мы увидим, что они практически безупречны. Как видно, символы доллара США все еще присутствуют в наших значениях. Это не то, что мы хотим для столбца, который должен иметь значение с плавающей запятой или десятичное число. Поэтому мы избавимся от них, прежде чем менять наши цены на числа с плавающей запятой. К счастью, панды делают это просто. Просто ничего не заменяйте этими символами.
# To remove the `US` abbreviation
df["prices"] = df["prices"].str.replace("US", "")
# To remove dollar sign
df["prices"] = df["prices"].str.replace("$", "")
df.head()

Столбец с ценами теперь аккуратный, однако чего-то еще не хватает. Мы обнаружим, что цена по-прежнему является строковым типом, когда посмотрим на типы данных в нашем фрейме данных. Мы понимаем, что для числового столбца этого быть не должно. Нам нужно только изменить представление этого типа данных string на число с плавающей запятой.
df.info()

# To convert prices to float type
df["prices"] = df.prices.astype("float")
df.info()

Теперь мы обратимся к нашим отсутствующим значениям в столбце рейтинга на этом этапе. Подсчитаем количество значений, которых сейчас не хватает. Как видите, пропущены значения примерно в 272 строках. Мы не можем отбросить их, потому что у нас слишком мало данных, поэтому вместо этого мы заполним их средним значением столбца цены. Теперь у нас нет отсутствующих данных в нашем столбце рейтинга, и мы это увидим, если проверим его еще раз.
# We fill Na values in rating
df.rating.isna().sum() # 272
import numpy as np
df["rating"] = df["rating"].fillna(round(np.mean(df.rating), 1))
# We recheck for missing values -> 0
df.rating.isna().sum()
Если мы проверим наш окончательный вариант, мы увидим, что данные чистые, а столбцы имеют правильные типы. Теперь мы можем экспортировать наши данные в CSV-файл для дальнейшего анализа.
df.head()
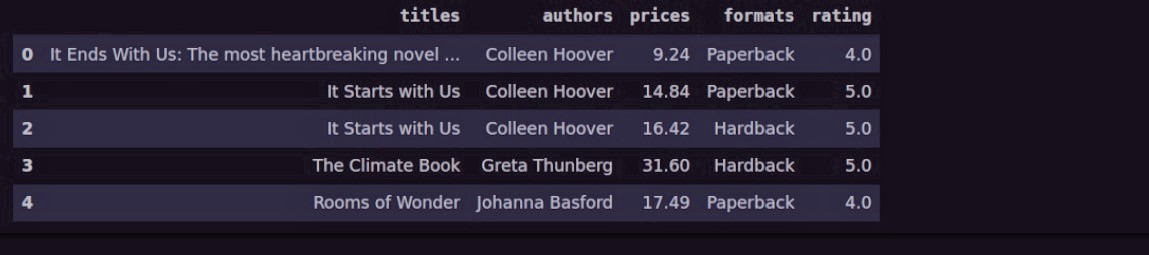
Наконец, мы должны сохранить данные для дальнейшего изучения в качестве последнего шага.
# To save for further analysis
df.to_csv("book_depository_clean.csv")
n **Пакет request-html делает парсинг веб-страниц простым и удобным для начинающих. Вы должны попробовать🔥 n Вы все еще можете прочитать о пакете здесь.