Я возглавляю группу по работе с большими данными в компании-производителе электромобилей и испробовал значительную часть инструментов OLAP, доступных на рынке. Прочтите ниже, чтобы узнать, что, по моему мнению, вам нужно знать об инструментах, включая плюсы и минусы многочисленных инструментов OLAP и мой опыт работы с OLAP.
Обсуждаемые инструменты OLAP:
- Apache Druid (и Apache Kylin)
- ТиБД
- ClickHouse
- Апач Дорис
Apache Druid (и Apache Kylin)
В 2017 году поиск инструмента OLAP на рынке был похож на поиск дерева в африканской прерии — их было всего несколько. Пока мы смотрели вверх и осматривали горизонт, наши глаза задержались на Apache Druid и Apache Kylin. Мы остановились на Druid, потому что уже были с ним знакомы, тогда как Kylin, несмотря на его впечатляюще высокую эффективность запросов при предварительных вычислениях, имел несколько недостатков.
Недостатки Kylin:
- Лучшим механизмом хранения для Kylin был HBase, но введение HBase привело бы к новым трудностям в эксплуатации и обслуживании.
- Kylin предварительно вычисляет размеры и метрики, но взрыв размеров, который он вызывает, создает большую нагрузку на хранилище.
Что касается Apache Druid, он использовал столбцовое хранилище, поддерживал прием данных как в режиме реального времени, так и в автономном режиме, а также выполнял быстрые запросы.
С другой стороны, Друид:
- Не использует стандартные протоколы, такие как JDBC, поэтому не подходит для начинающих.
- Слабая поддержка соединений.
- Точная дедупликация может быть медленной, что снижает производительность.
- Потребовались огромные усилия по обслуживанию из-за множества компонентов, требующих различных методов установки и зависимостей.
- Необходимые изменения в интеграции с Hadoop и зависимости пакетов JAR, когда дело доходит до приема данных.
ТиБД
В 2019 году мы попробовали TiDB. Короче говоря, вот его плюсы и минусы:
Плюсы
- Это была база данных OLTP + OLAP, которая поддерживала простые обновления.
- В нем были нужные нам функции, в том числе агрегированные и разбивочные запросы, вычисление метрик и панель мониторинга.
- Он поддерживал стандартный SQL, поэтому его было легко понять.
- Он не требовал особого обслуживания.
Минусы:
- Тот факт, что TiFlash полагался на OLTP, может увеличить нагрузку на хранилище. Поскольку это ненезависимый OLAP, его возможности аналитической обработки были далеко не идеальными.
- Его производительность варьировалась в зависимости от сценария.
ClickHouse и Apache Doris
Мы провели исследование ClickHouse и Apache Doris. Нас впечатлила потрясающая производительность ClickHouse в автономном режиме, но мы прекратили его изучение, когда обнаружили следующее:
- Это не дало нам того, что мы хотели, когда дело дошло до объединения за несколькими столами, что было для нас важным использованием.
- У него был относительно низкий уровень параллелизма.
- Это может привести к высокой производительности и эффективности. расходы на техническое обслуживание.
Apache Doris, с другой стороны, отвечает многим требованиям в нашем списке требований:
- Он поддерживал запросы с высокой степенью параллелизма, что было нашей самой большой проблемой.
- Он мог обрабатывать данные как в режиме реального времени, так и в автономном режиме.
- Он поддерживал как агрегированные, так и разбивочные запросы.
- Модель Unique (тип модели данных в Doris, которая обеспечивает уникальные ключи) поддерживала обновления.
- Это может значительно ускорить запросы через материализованное представление.
- Он был совместим с протоколом MySQL, поэтому с разработкой и внедрением проблем не возникло.
- Его производительность запросов отвечает всем требованиям.
- Требовался только простой O&M.
Подводя итог, Apache Doris оказался идеальной заменой Apache Druid + TiDB.
Наш практический опыт работы с OLAP
Вот диаграмма, показывающая, как данные проходят через нашу систему OLAP:
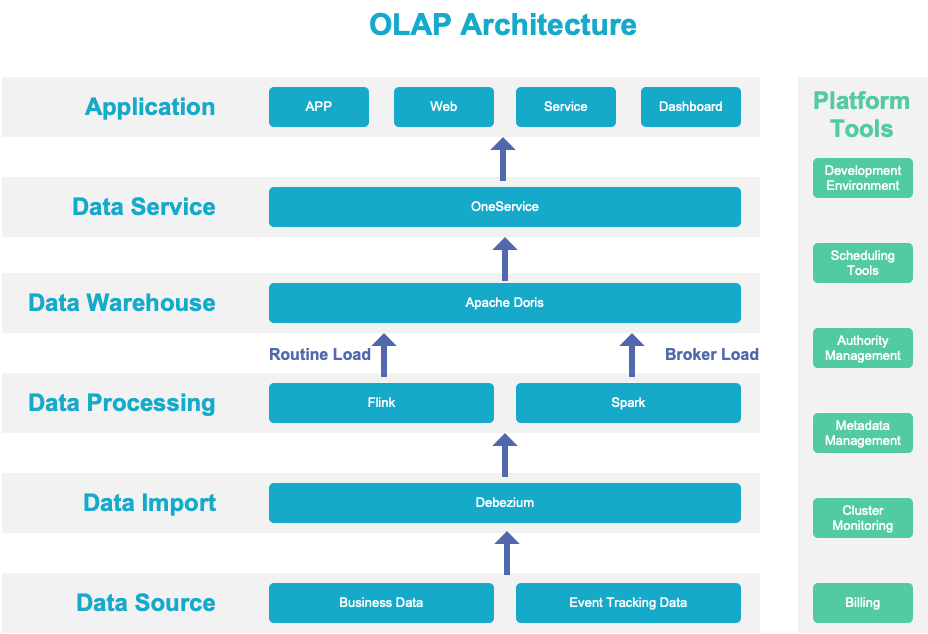
Источники данных
Мы объединяем данные из нашей бизнес-системы, отслеживания событий, устройств и транспортных средств в нашу платформу больших данных.
Импорт данных
Мы включаем CDC для наших коммерческих данных. Любые изменения в таких данных будут преобразованы в поток данных и сохранены в Kafka. для потоковых вычислений. Что касается данных, которые можно импортировать только пакетами, они будут поступать непосредственно в наше распределенное хранилище.
Обработка данных
Вместо интеграции, потоковой передачи и пакетной обработки мы использовали архитектуру Lambda. Наш бизнес-статус-кво определяет, что наши данные в режиме реального времени и в автономном режиме поступают из разных источников. В частности:
- Некоторые данные поступают в виде потоков.
- Некоторые данные могут храниться в потоках, тогда как некоторые исторические данные не будут храниться в Kafka;
- Некоторые сценарии требуют высокой точности данных. Чтобы понять это, у нас есть автономный конвейер, который повторно вычисляет и обновляет все соответствующие данные.
Хранилище данных
Вместо использования коннектора Flink/Spark-Doris мы используем метод обычной загрузки для передачи данных из Flink в Doris и метод Broker Load из Spark в Doris. Данные, созданные пакетами с помощью Flink и Spark, будут сохраняться в Hive для использования в других сценариях. Это наш способ повысить эффективность данных.
Службы данных
Что касается служб данных, мы обеспечиваем автоматическое создание API-интерфейсов посредством регистрации источника данных и гибкой настройки, чтобы мы могли управлять трафиком и полномочиями через API. В сочетании с бессерверным решением K8s все работает отлично.
Приложение данных
На уровне приложения данных у нас есть два типа сценариев:
- Сценарии, с которыми сталкиваются пользователи, такие как информационные панели и показатели.
- Сценарии, ориентированные на транспортное средство, когда данные о транспортном средстве собираются в Apache Doris для дальнейшей обработки. Даже после агрегирования объем данных по-прежнему измеряется миллиардами, но общая производительность вычислений находится на должном уровне.
Наша практика CDP
Как и большинство компаний, мы создали собственную платформу клиентских данных (CDP): n
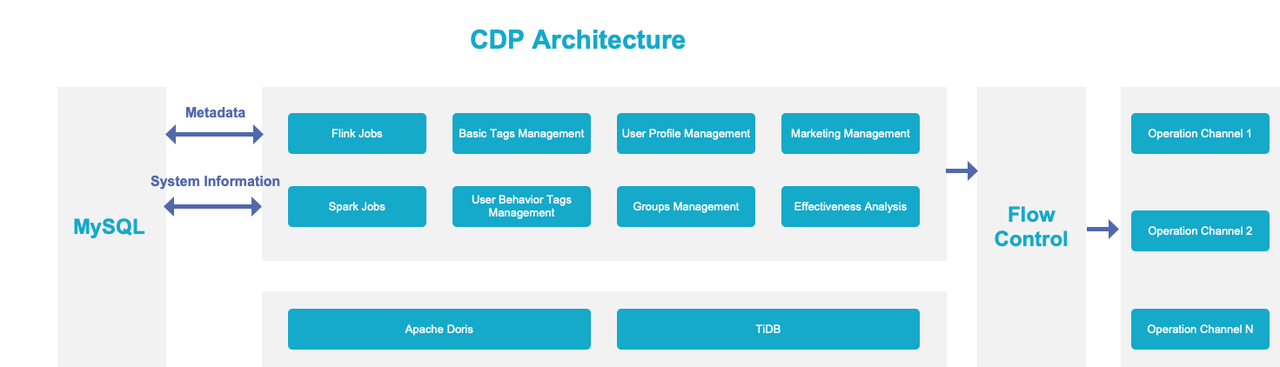 Обычно CDP состоит из нескольких модулей:
Обычно CDP состоит из нескольких модулей:
* Теги: очевидно, строительный блок; (У нас есть базовые теги и теги поведения клиентов. Мы также можем определить другие теги по своему усмотрению.) * Группы: делите клиентов на группы на основе тегов. * Статистика: характеристики каждой группы клиентов. * Охват: способы связаться с клиентами, включая текстовые сообщения, телефонные звонки, уведомления приложений и мгновенные сообщения. * Анализ эффекта: отзывы о том, как работает CDP. п
Мы хотели добиться интеграции в режиме реального времени и в автономном режиме, быстрой группировки, быстрой агрегации, объединения нескольких таблиц и федеративных запросов в нашей CDP. А вот как это делается:
В режиме реального времени + офлайн
У нас есть теги реального времени и автономные теги, и нам нужно, чтобы они размещались вместе. Кроме того, столбцы одних и тех же данных могут обновляться с разной частотой. Некоторые базовые теги (касающиеся личности клиентов) должны обновляться в режиме реального времени, тогда как другие теги (возраст, пол) могут обновляться ежедневно. Мы хотим поместить все атомарные теги клиентов в одну таблицу, потому что это требует наименьших затрат на обслуживание и может значительно сократить количество необходимых таблиц при добавлении самоопределяемых тегов.
Как же нам этого добиться?
Мы используем метод обычной загрузки Apache Doris для обновления данных в реальном времени и метод загрузки брокера для пакетного импорта автономных данных. Мы также используем эти два метода для обновления разных столбцов в одной таблице соответственно.
Быстрая группировка
По сути, группировка заключается в объединении определенной группы тегов и поиске перекрывающихся данных. Это может быть сложно. Дорис помогла ускорить этот процесс с помощью SIMD-оптимизации.
Быстрая агрегация
Нам необходимо обновлять все теги, пересчитывать распределение групп клиентов и ежедневно анализировать влияние. Такая обработка должна быть быстрой и аккуратной. Поэтому мы разделяем данные на планшеты в зависимости от времени, чтобы было меньше передачи данных и более быстрые вычисления. При расчете распределения групп клиентов мы предварительно агрегируем данные на каждом узле, а затем собираем их для дальнейшей агрегации. Кроме того, векторизованный механизм выполнения Doris — настоящий ускоритель производительности.
Присоединение к нескольким столам
Поскольку наши основные данные хранятся в нескольких таблицах данных, когда пользователи CDP настраивают нужные им теги, им необходимо выполнить объединение нескольких таблиц. Важным фактором, который привлек нас к Apache Doris, была его многообещающая возможность объединения нескольких таблиц.
Федеративные запросы
В настоящее время мы используем Apache Doris в сочетании с TiDB. Записи об охвате клиентов будут помещены в TiDB, а данные о кредитных баллах и ваучерах также будут обрабатываться в TiDB, поскольку это лучший инструмент OLTP. Что касается более сложного анализа, такого как мониторинг эффективности работы клиентов, нам необходимо интегрировать информацию о выполнении задач и целевых группах. Это когда мы выполняем федеративные запросы в Doris и TiDB.
Заключение
Это наше путешествие от Apache Druid, TiDB и Apache Doris (и короткий взгляд на ClickHouse в середине). Мы изучили производительность, семантику SQL, совместимость систем и стоимость обслуживания каждого из них и в итоге остановились на той архитектуре OLAP, которая у нас есть. Если у вас есть те же проблемы, что и у нас, это может быть справочным материалом для вас.