

Yolo Jungle: S3, C2F, C3K2 - что они даже имеют в виду?
2 августа 2025 г.Это статья о проектировании блоков извлечения функций, разработанных для улучшения многомасштабного обнаружения объектов при сохранении быстрого вывода в реальных приложениях.
Перекрестные частичные соединения (CSP)
Во -первых, Wongkinyiu et al. [1] представил это архитектурное инновации и рассмотрела проблему избыточной информации о градиенте в более широких сверточных нейронных сетевых костях. Его основная цель - обогатить градиентные взаимодействия при одновременном снижении вычислительных затрат. Перекрестные частичные соединения (CSP) сохраняют разнообразие градиента, объединяя карты признаков как с начала, так и от конца каждой сетевой стадии: карты признаков базового уровня разделены на две части: одна проходит через плотный блок и переходный уровень, в то время как другой обходит этот путь и подключается непосредственно к следующему этапу. Эта архитектура предназначена для решения нескольких проблем, включая повышение возможностей обучения CNN, удаление вычислительных узких мест и снижение затрат на память.
![Illustrations of DensNet (a) and CSP DenseNet (b) [1]](https://cdn.hackernoon.com/images/wtbtBaJlPORareDWo7AAoAx51Yf1-64039xm.jpeg)
CSP-DENSENET сохраняет преимущества повторного использования функций Densenet, одновременно снижая дублирующую информацию градиента путем обрезки градиента потока, достигаемой с помощью стратегии слияния иерархических функций в частичном переходном уровне.
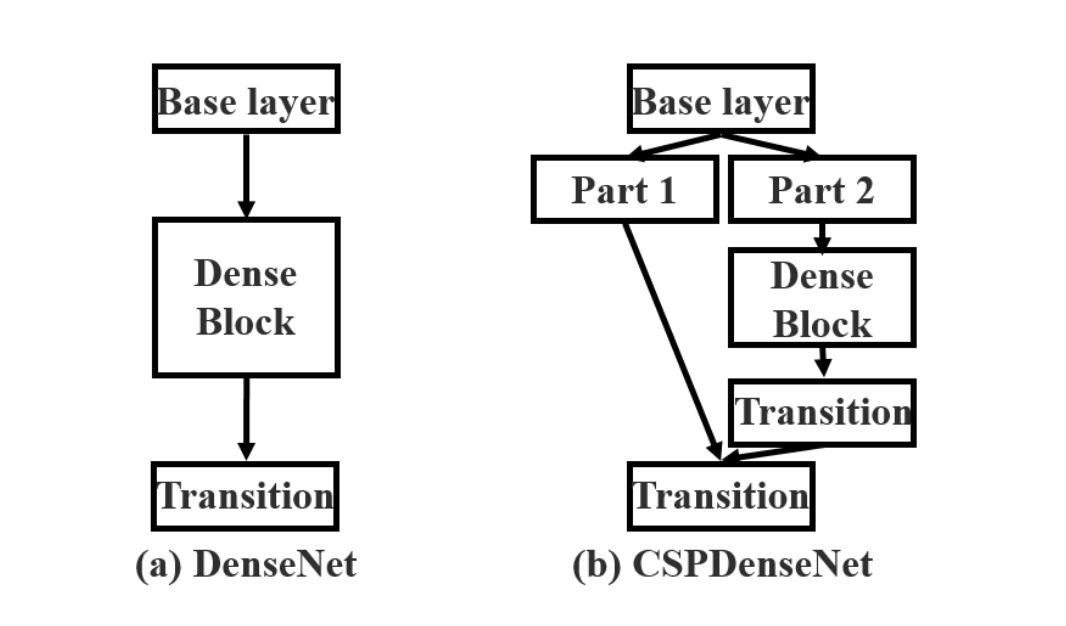
Согласноэксперименты авторовЭтот подход снижает вычисления на 20% при достижении эквивалентной или даже превосходной точности в наборе данных ImageNet.
C3
Yolov4 и Yolov5 используют поперечный частичный (CSP) модуль для улучшения извлечения признаков в узком месте. Блок C3 является практической реализацией этой архитектуры CSP вУльтралитикаМодели YOLO.
В блоке C3 карты функций ввода разделены на две части. Одна часть обрабатывается сверткой 1 × 1, за которой следуетнеПараллельные блоки узкого места, в то время как другая часть проходит через отдельную свертку 1 × 1 и полностью пропускает узкие места. Эти две ветви затем объединяются вдоль измерения канала и сливаются с еще одной сверткой 1 × 1 для получения вывода.
Input (x)
│
┌────────┴─────────┐
│ │
[1x1 Conv] [1x1 Conv]
(cv1) (cv2)
│ │
[Bottlenecks] │
(m: n blocks) │
│ │
└────────┬─────────┘
│
[Concat along C]
│
[1x1 Conv → cv3]
│
Output
с ультралитической реализацией (Ссылка GitHub):
class C3(nn.Module):
"""CSP Bottleneck with 3 convolutions."""
def __init__(self, c1: int, c2: int, n: int = 1, shortcut: bool = True, g: int = 1, e: float = 0.5):
"""
Initialize the CSP Bottleneck with 3 convolutions.
Args:
c1 (int): Input channels.
c2 (int): Output channels.
n (int): Number of Bottleneck blocks.
shortcut (bool): Whether to use shortcut connections.
g (int): Groups for convolutions.
e (float): Expansion ratio.
"""
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, k=((1, 1), (3, 3)), e=1.0) for _ in range(n)))
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""Forward pass through the CSP bottleneck with 3 convolutions."""
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))
Перекрестная стадия частично с 2F-соединениями (C2F)
Блок C2F строится на CSPNET, расширяя его: вместо одного пути слияния он вводит два параллельных соединения слияния функций, каждое из которых имеет половину количества выходных каналов. Эта идея, которая впервые появилась в Yolov7 и Yolov8 [2] [3], следует тем же принципам, что и CSP, разделяя карту входных функций, чтобы уменьшить вычислительное избыточность и улучшить повторное использование функций.
![The C2f block in YOLOv8 [3]](https://cdn.hackernoon.com/images/wtbtBaJlPORareDWo7AAoAx51Yf1-j5439o8.jpeg)
В блоке C2F входной тензор делится на два пути: один обходит слои узкого места в качестве ярлыка, в то время как другой проходит через несколько слоев узкого места. В отличие от исходного CSP, который использует только конечный выход узкого места, C2F собирает все промежуточные выходы узких мест и объединяет их - повышение разнообразия и представления объектов. Эта стратегия слияния с двойной функцией (2F) также помогает сетевой окклюзии лучше, делая обнаружения более надежными в сложных сценах.
Внедрение ультралитики (Ссылка GitHub):
class C2f(nn.Module):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(self, c1: int, c2: int, n: int = 1, shortcut: bool = False, g: int = 1, e: float = 0.5):
"""
Initialize a CSP bottleneck with 2 convolutions.
Args:
c1 (int): Input channels.
c2 (int): Output channels.
n (int): Number of Bottleneck blocks.
shortcut (bool): Whether to use shortcut connections.
g (int): Groups for convolutions.
e (float): Expansion ratio.
"""
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""Forward pass through C2f layer."""
y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
def forward_split(self, x: torch.Tensor) -> torch.Tensor:
"""Forward pass using split() instead of chunk()."""
y = self.cv1(x).split((self.c, self.c), 1)
y = [y[0], y[1]]
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
Перекрестное частичное с блоком размера 2 (C3K2) ядра (C3K2)
Yolov11 [4] использует следующие блоки C3K2 в головке для извлечения функций на различных этапах своей основы для обработки многомасштабных функций-еще одна эволюция классического узкого места CSP. Блок C3K2 расщепляет карту функций и обрабатывает ее с несколькими легкими соображениями 3 × 3, объединяя результаты впоследствии. Это улучшает информационный поток, оставаясь более компактным, чем полное узкое место CSP, уменьшая количество тренировочных параметров.
Блок C3K сохраняет ту же основную структуру, что и C2F, но не разделяет выход после первоначальной сверты. Вместо этого он запускает вход черезнеСлои узкого места с промежуточными конкатенациями, заканчивающиеся окончательной сверткой 1 × 1. В отличие от C2F, C3K добавляет гибкость с настраиваемыми размерами ядра, помогая модели лучше запечатлеть мелкие детали в разных масштабах объектов.
Опираясь на эту идею, C3K2 заменяет простые узкие места на несколько блоков C3K. Он начинается с блока Conv, складывает несколько блоков C3K в последовательности, объединяет свои выходы с исходным входом и заканчивает другим слоем Convine-смешивание концепции CSP Split-Merge с гибкими ядрами, чтобы сбалансировать скорость, эффективность параметров и более богатая многомасштабная извлечение.
Input: [Batch, c1, H, W]
│
[cv1] (1x1 Conv) → splits channels into 2c
│
┌─────────────┐
│ │
Branch 1 Branch 2
(Bypass) (Bottleneck chain)
│ │
├─> C3k Block #1
│
├─> C3k Block #2
│
... (n times)
│
└─────────────┬─────────────┐
Concatenate [Bypass, Split, C3k outputs]
│
[cv2] (1x1 Conv)
│
Output: [Batch, c2, H, W]
Каждый блок C3K использует параллельные узкие места с пользовательскими ядрами, обеспечивая большую гибкость для извлечения функций и позволяя модели лучше адаптироваться к сложным узорам.
C3k Input: [Batch, c, H, W]
│
[cv1] (1x1 Conv, expand/split)
│
┌───────────────┐
│ │
ByPass Bottleneck blocks
│ ┌─────────────┐
│ B1, B2, ...Bn (parallel)
└─────────────┘
└───────────────┬───────┘
Concatenate
│
[cv2] (1x1 Conv)
│
C3k Output: [Batch, c, H, W]
Внедрение ультралитики (Ссылка GitHub):
class C3k(C3):
"""C3k is a CSP bottleneck module with customizable kernel sizes for feature extraction in neural networks."""
def __init__(self, c1: int, c2: int, n: int = 1, shortcut: bool = True, g: int = 1, e: float = 0.5, k: int = 3):
"""
Initialize C3k module.
Args:
c1 (int): Input channels.
c2 (int): Output channels.
n (int): Number of Bottleneck blocks.
shortcut (bool): Whether to use shortcut connections.
g (int): Groups for convolutions.
e (float): Expansion ratio.
k (int): Kernel size.
"""
super().__init__(c1, c2, n, shortcut, g, e)
c_ = int(c2 * e) # hidden channels
# self.m = nn.Sequential(*(RepBottleneck(c_, c_, shortcut, g, k=(k, k), e=1.0) for _ in range(n)))
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, k=(k, k), e=1.0) for _ in range(n)))
class C3k2(C2f):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(
self, c1: int, c2: int, n: int = 1, c3k: bool = False, e: float = 0.5, g: int = 1, shortcut: bool = True
):
"""
Initialize C3k2 module.
Args:
c1 (int): Input channels.
c2 (int): Output channels.
n (int): Number of blocks.
c3k (bool): Whether to use C3k blocks.
e (float): Expansion ratio.
g (int): Groups for convolutions.
shortcut (bool): Whether to use shortcut connections.
"""
super().__init__(c1, c2, n, shortcut, g, e)
self.m = nn.ModuleList(
C3k(self.c, self.c, 2, shortcut, g) if c3k else Bottleneck(self.c, self.c, shortcut, g) for _ in range(n)
)
Заключение
Короче говоря, современные архитектуры YOLO продолжают развиваться, добавляя блоки, такие как C3, C2F, C3K и C3K2-все это построено вокруг основной идеи перекрестных частичных (CSP) соединений. Этот подход CSP снижает вычисление и повышает представление функций одновременно.
Блокировать | Внешняя структура | Внутренняя структура | Гибкость ядра |
|---|---|---|---|
C3 | Параллельные узкие места | Узкие места | Фиксированные ядра |
C2F | Серийные узкие места | Узкие места | Фиксированные ядра |
C3K | Параллельные узкие места | Узкие места | Пользовательские ядра |
C3K2 | Серийные блоки C3K | Каждый C3K имеет параллельные узкие места | Пользовательские ядра |
Эти архитектурные усовершенствования в совокупности помогают моделям YOLO поддерживать высокую точность обнаружения, оставаясь быстро и достаточно легким для развертывания в реальном времени-критическое преимущество для различных приложений
Ссылки
https://arxiv.org/pdf/1911.11929
https://arxiv.org/pdf/2207.02696
https://arxiv.org/pdf/2408.15857
https://arxiv.org/html/2410.17725v1#s3
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27294)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)