

Yandex выпускает огромный набор данных, чтобы помочь AI понять, что вам действительно нравится
11 июля 2025 г.Познакомьтесь с Yambda: один из крупнейших в мире открытых наборов данных для Recsys.
Алгоритмы рекомендаций помогают людям открыть для себя правильные продукты, фильмы, музыку и многое другое. Они являются основой услуг, от интернет -магазинов до потоковых платформ. Содействие этих алгоритмах напрямую зависит от исследования, которые, в свою очередь, требуют высококачественных, крупномасштабных наборов данных.
Тем не менее, большинство наборов данных с открытым исходным кодом являются либо небольшими, либо устаревшими, поскольку компании, которые накапливают терабайты данных, редко делают их общедоступными из-за проблем с конфиденциальностью. Сегодня мы выпускаем Yambda, один из крупнейших в мире наборов данных.
Этот набор данных имеет анонимизированное взаимодействие пользователей 4,79 млрд., Скомпилированные за 10 месяцев пользовательской активности.
Мы выбрали музыкальный сервис, потому что это крупнейшая потоковая служба на основе подписки в России, в среднем ежемесячную аудиторию 28 миллионов пользователей.
Значительная часть набора данных включает в себя агрегированные прослушивания, лайки и антипатия, а также атрибуты отслеживания, полученные из персонализированной системы рекомендацийМоя атмосфераПолем Все данные пользователя и отслеживания являются анонимизированными: набор данных содержит только числовые идентификаторы, обеспечивая конфиденциальность пользователей.
Выпуск больших открытых наборов данных, таких как Yambda, помогает решить несколько проблем. Доступ к высококачественным, крупномасштабным данным открывает новые возможности для научных исследований и привлекает молодых исследователей, стремящихся применить машинное обучение к реальным проблемам.
Я Александр Плошкин, и я возглавляю качество персонализации в Яндексе.
В этой статье я объясню, из чего состоит набор данных, как мы его собрали, и как вы можете использовать его для оценки новых алгоритмов рекомендаций.
Начнем!
Почему имеют значение крупномасштабные открытые наборы данных?
Рекомендательные системы испытывают истинный ренессанс в последние годы.
Технологические компании все чаще используют модели на основе трансформатора, вдохновленные успехом крупных языковых моделей (LLMS) в других областях.
То, что мы узнали из компьютерного зрения и обработки естественного языка, так это то, что объем данных имеет решающее значение для того, насколько хорошо работают эти методы: трансформаторы не очень эффективны для небольших наборов данных, но становятся почти важными, когда они масштабируются до миллиардов токенов.
Действительно крупномасштабные открытые наборы данных являются редкостью в домене Systems Recurdermer.
Известные наборы данных, такие как LFM-1B, LFM-2B и набор данных по истории прослушивания музыки (27B), стали недоступными со временем из-за ограничений лицензирования.
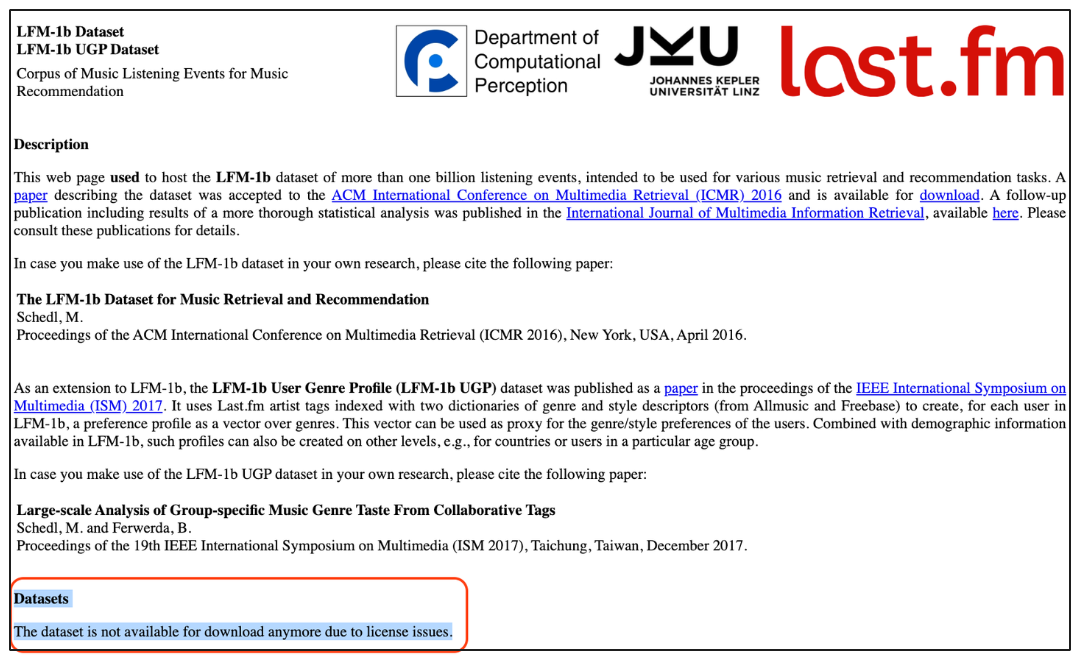
В настоящее время запись о количестве взаимодействий с пользователями проводится с помощью рекламного набора данных Criteo, с приблизительно 4 миллиардами событий. Это создает проблему для исследователей: большинство не имеют доступа к услугам в Интернете, что означает, что они не могут проверить алгоритмы в условиях, которые напоминают реальные развертывания.
Популярные наборы данных, такие как Movielens, Steam или приз Netflix, в лучшем случае содержат десятки миллионов взаимодействий и обычно фокусируются на явной обратной связи, такие как рейтинги и обзоры.
Между тем, системы рекомендации по производству работают с гораздо более разнообразными и нюансами: клики, лайки, полные прослушивания, представления, покупки и так далее.
Есть еще одна критическая проблема: отсутствие временной динамики. Многие наборы данных не допускают честного хронологического разделения между обучением и тестовыми наборами, что имеет решающее значение для оценки алгоритмов, направленных на предсказание будущего, а не просто объяснить прошлое.
Чтобы решить эти проблемы и поддержать разработку новых алгоритмов в системах рекомендаций, мы выпускаем Yambda.
Этот набор данных в настоящее время является крупнейшим открытым ресурсом для взаимодействия пользователей в домене рекомендаций.
Что внутри Ямбды?
Набор данных включает в себя взаимодействия от 1 миллиона пользователей с более чем 9 миллионами музыкальных треков от музыкального сервиса, на общую сумму 4,79 миллиарда событий.
Во -первых, чтобы быть ясным: все события анонимизированы.
Набор данных использует только числовые идентификаторы для пользователей, треков, альбомов и артистов. Это для обеспечения конфиденциальности и защиты пользовательских данных.
Набор данных включает в себя неявные и явные действия пользователя:
- Слушать:Пользователь слушал музыкальную дорожку.
- Нравиться:Пользователю понравился трек («Большинство вверх»).
- В отличие от:Пользователь удалил.
- Неприязнь:Пользователь не любил трек («большие пальцы вниз»).
- Неподобный:Пользователь удалил неприязнь.
Чтобы сделать набор данных более доступным, мы также выпустили меньшие образцы, содержащие 480 миллионов и 48 миллионов событий соответственно.
Сводная статистика для этих подмножества приведена в таблице ниже:
Данные хранятся в формате Apache Parquet, который национально поддерживается библиотеками анализа данных Python, такими как панды и поляры. Для простоты использования набор данных полностью реплицируется в двух форматах:
Flat: Каждая строка представляет собой единое взаимодействие между пользователем и треком.Sequential: Каждая строка содержит полную историю взаимодействия одного пользователя.
Структура набора данных заключается в следующем:
Ключевой особенностью Yambda являетсяis_organicфлаг, который включен в каждое событие. Этот флаг помогает различать действия пользователя, которые произошли естественным образом, и теми, которые вызваны рекомендациями.
Еслиis_organic = 0Это означает, что событие было вызвано рекомендацией.
Например, в персонализированном музыкальном потоке или рекомендуемом плейлисте. Все остальные события считаются органическими, что означает, что пользователь обнаружил контент самостоятельно.
В таблице ниже содержится статистика по рекомендациям событий:
История взаимодействия с пользователем является ключом к созданию персонализированных рекомендаций. Он отражает как долгосрочные предпочтения, так и мгновенные интересы, которые могут измениться с контекстом.
Чтобы помочь вам лучше понять структуру данных, вот несколько быстрых статистических данных о нашем наборе данных:
Приведенные выше диаграммы показывают, что длина истории пользователя следует за тяжелым хвостом распределения.
Это означает, что, хотя большинство пользователей имеют относительно мало взаимодействий, небольшая, но значимая группа имеет очень длинную историю взаимодействия.
Это особенно важно для учета моделей рекомендаций, чтобы избежать переживания до очень активных пользователей и поддерживать качество для «тяжелого хвоста» менее заинтересованных пользователей.
Напротив, распространение по трекам рассказывает совершенно другую историю.
Этот график ясно показывает дисбаланс между очень популярными треками и большим объемом нишевого содержания: более 90% треков получили менее 100 игр в течение всего периода сбора данных.
Несмотря на это, рекомендованные системы должны взаимодействовать со всем каталогом, чтобы поверхностные дорожки с низкой популярностью, которые хорошо соответствуют индивидуальным пользовательским предпочтениям.
Использование Yambda для оценки алгоритмической производительности
Академические исследования по качеству алгоритма рекомендаций часто используют схему Leav-One-One (LOO), где для тестирования используется одно пользовательское действие, а остальные используются для обучения.
Этот метод, однако, поставляется с двумя серьезными недостатками:
- Временное несоответствие:Тестовые события могут включать действия, которые произошли до начала обучения.
- Равное взвешивание пользователей: Неактивные пользователи влияют на метрики оценки так же, как и активные, что может исказить результаты.
Чтобы приблизить условия оценки к реальным сценариям системы рекомендаций, мы предлагаем альтернативу:Глобальный временный расколПолем
This simple method selects a point in time (T), excluding all subsequent events from the training set.
Это гарантирует модель поезда по историческим данным и проверяется в отношении будущих данных, имитируя настоящую производственную среду. Диаграмма ниже иллюстрирует это:
Для нашей оценки мы зарезервировали один день данных в качестве удержания по двум основным причинам:
- Даже один день данных обеспечивает достаточный объем, чтобы надежно оценить производительность алгоритма.
- Модели в производстве реального мира имеют разные характеристики: некоторые требуют частых обновлений статистики (например, рекомендации на основе популярности), другие периодически настраиваются или переподготовлены (повышение, матричная факторизация, модели с двумя башнями), а некоторые зависят от непрерывно обновленных историй взаимодействия пользователей (рецидивирующие и трансформаторные модели).
С нашей точки зрения однодневное окно является оптимальным периодом оценки, чтобы сохранить статические модели, при этом захватывая краткосрочные тенденции.
Недостаток этого подхода заключается в том, что он не учитывает долгосрочные узоры, такие как еженедельные сдвиги в поведении слушания музыки. Мы предлагаем оставить эти аспекты для будущих исследований.
Базовые линии
Мы оценили несколько популярных алгоритмов рекомендаций на Yambda, чтобы установить базовые показатели для будущих исследований и сравнения.
Алгоритмы, которые мы протестировали, включают в себя: ofpop, decaypop, itemknn, ials, bpr, sansa и sasrec.
Для оценки мы использовали следующие показатели:
- Ndcg@k (нормализованный совокупный накопительный усиление),который измеряет качество рейтинга в рекомендациях.
- Вспомнить@k,который оценивает способность алгоритма получать соответствующие рекомендации из общего пула.
- Покрытие@k,что указывает на то, как широко представлен каталог рекомендаций.
Результаты приведены в таблицах, а код доступен на
Заключение
Ямбда может быть ценной для исследования алгоритмов рекомендаций по крупномасштабным данным, где как производительность, так и способность моделировать поведенческую динамику имеют решающее значение.
Набор данных доступен в трех версиях: полный набор с 5 миллиардами событий и небольшие подмножеств с 500 миллионами и 50 миллионов событий.
Разработчики и исследователи могут выбрать версию, которая наилучшим образом соответствует их проекту и вычислительным ресурсам. Как набор данных, так и код оценки доступны на
Мы надеемся, что этот набор данных окажется полезным в ваших экспериментах и исследованиях!
Спасибо за чтение!
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Лучшие новогодние подарки для владельцев домашних животных
29 мая 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27342)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)