

Почему мультимодальные LLM все еще борются с видео - и как агенты ИИ могут помочь
1 августа 2025 г.Когда я впервые начал разрабатывать агента искусственного интеллекта для анализа видео, я подумал, что это будет легко-какой оптимистичный парень! Мое оптимистическое убеждение заключалось в том, что мультимодальные крупные языковые модели (LLMS), такие как GPT-4O, будут достаточно мощными, чтобы сделать такой анализ на любом видео. Но реальность ударила сильнее, чем ожидалось. Несмотря на шумиху, реальность такова, что мы все еще довольно далеки от «магии в одиночной модели», когда речь заходит о сложных неструктурированных данных, таких как видео и сложные документы с текстом, изображениями, графиками и т. Д., В частности, для сложных видео, даже лучшие мультимодальные LLM, которые борются за анализ. Особенно, если эти видео включают в себя визуальный беспорядок, окружающий звук, спонтанную человеческую речь и т. Д. Все станет более сложным. Я не решаюсь сказать, что это дефицит интеллекта, но, скорее всего, из -за готовности вклада.
Позвольте мне провести вас через то, что я узнал, создавая агента искусственного интеллекта, который может собирать высококачественные идеи из сложного видео, и почему нам нужен полный конвейер модулей предварительной обработки и рассуждений, чтобы заставить его работать.
Почему видео так сложно для ИИ

Видео неструктурировано, богатый данными, хаотичный беспорядок сигналов и включает мультимодальные. Каждый видеофайл обычно содержит два основных метода:
- Визуальные данныесостоит из последовательностей кадров (изображений). Эти изображения могут быть размытыми, плохо освещенными или содержать быстрое движение.
- Аудиоданныеэто сочетание голосов, шума окружающей среды, а иногда и музыки. Мультимодальные LLM невероятно хороши в рассуждениях по методам, но только после того, как вы извлеките и очистили сигнал. Без надлежащей предварительной обработки даже лучшие модели будут изо всех сил пытаться генерировать высокие результаты точности. Выход, вероятно, будет расплывчатым или неточным, если не предварительно обработан должным образом.
Архитектура агента искусственного интеллекта в понимании видео
Вот дизайн агента, который я разработал (см. Диаграмму ниже). Каждая часть играет ключевую роль в структурировании беспорядка, прежде чем передавать его двигателю рассуждения. Это не только структурирование данных, но и уборка и улучшение, где это необходимо.
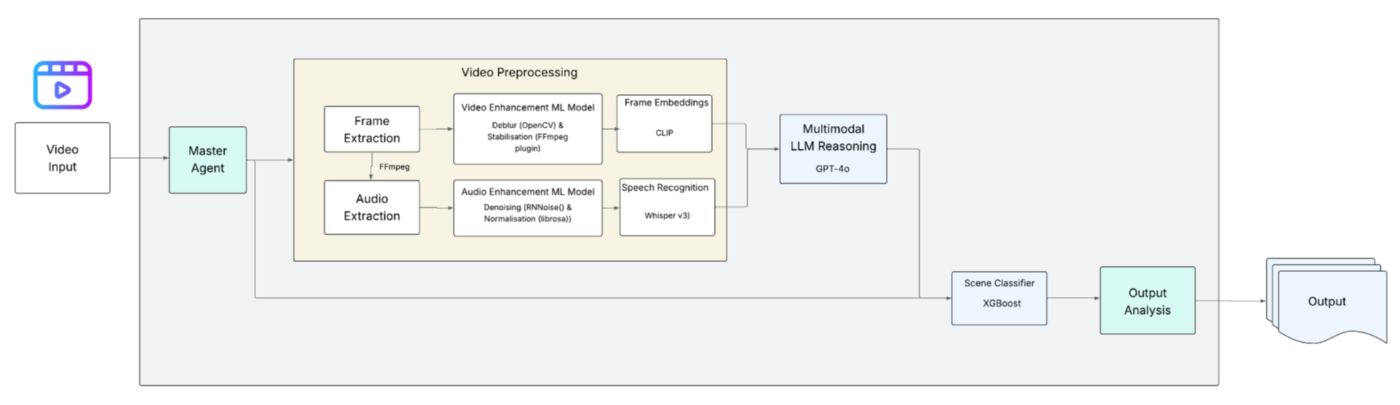
Мастер -агент
Мастер -агент является оркестратором всего рабочего процесса внутри агента. Он координирует предварительную обработку, извлечение функций, улучшение и рассуждения, обеспечивая эффективное перемещение данных от необработанного входа к конечному выводу. Видео предварительно обрабатывает это, где мы свернули наши рукава. Цель состоит в том, чтобы улучшить качество данных, прежде чем что -либо подавать в LLM для рассуждения.
Извлечение кадров и аудио
Первым шагом является разделение кадров и аудио компонентов видео, извлекая их с помощью специализированного инструмента. Я использовал FFMPEG для извлечения, поскольку он является эффективным, гибким и надежным для обработки необработанного видео и аудио.
Усиление сигнала
Вторым шагом является улучшение сигнала для улучшения качества на каждом визуальном и аудиокатате.
i) зрительное улучшение:Используя OpenCV для высококлассных рамков с низким разрешением и размытыми рамами, а также стабилизацией рамки, я улучшил качество кадров. OpenCV также является сильным инструментом для изменения размера кадров и преобразования формата.
ii) улучшение звука:Обеспокация и ясность звука аудиодатчиков может быть достигнута с помощью RNNOISE. Кроме того, я использовал Librosa для извлечения аудио и обеспечения чистых и последовательных речевых данных. Следовательно, мы можем сделать точную транскрипцию из речи А видео.
Извлечение функций
i) встроение кадров:Чтобы сгенерировать встроенные рамки, я использовал Openai Clip, чтобы извлечь значимые и готовые к языку функции из видео. По сути, он принимает каждую кадр в виде пиксельной матрицы и встраивает их в семантическое векторное пространство, где их можно осмысленно описать.
ii) распознавание речи:Используя Whisper V3, я преобразовал речь в текст, чтобы транскрибировать разговорной контент в формат текста. Это еще один важный вклад для LLMS.
Мультимодальные рассуждения LLM
После всех этих этапов, упомянутых выше, дело доходит до GPT-4O для рассуждения. После того, как мы подготовили встроенные фреймы и стенограммы, GPT-4O потребляет их, чтобы собрать представление о том, что происходит в видео, чтобы понять, если кто-то говорит, что говорят, какие объекты видны и как все соединяется в контексте.
Классификация сцены (для более точности)
Это необязательный шаг, но он помогает повысить точность выхода, особенно если требуются проверки соответствия, безопасности или бизнес -логики. Используя классификатор, называемый XGBOOST, я добавил дополнительный слой в дизайн агента AI, чтобы повысить уровень уверенности и точности при обнаружении конкретных сцен или событий в каждом видео.
Выходной анализ
После всех предварительных обработок, улучшения и рассуждений, упомянутых выше, мы наконец готовы перевести структурированные идеи из данного видео. Наш агент ИИ теперь может точно обнаружить сцены, суммировать ключевые моменты или теги. Он также может понять в масштабе, что является очень мощной способностью в системах автоматизации, которые используют видео в качестве входных данных. Ключевой урок? К сожалению, истинный интеллект не может быть достигнут с использованием существующих мультимодальных LLMS на данный момент. Надеюсь, они быстро развиваются, чтобы спасти нас от всего этого препятствия (хотя это не так сложно, как кажется!).
Извини! Это трубопровод, а не ярлык
Мультимодальные LLMs являются мощными, но только тогда, когда они передаются чистыми структурированными данными в качестве входных данных. Сложное, шумное и низкокачественное видео нуждается в трубопроводе инструментов и предварительно обученных моделей, прежде чем LLM может работать с высокой точностью. Истинное понимание видео в ИИ по -прежнему требует оркестровки и дизайна системы. Если вы работаете с неструктурированными данными, такими как видео, и ожидаете, что решение для AI Plug-и Play, например, использование мультимодального LLM с некоторыми подсказками, подготовьтесь к удивлению-так же, как и я.
Оригинал
🔥 Популярное на этой неделе
-
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27342)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)