

Transic Demolising конкуренция: 81% показатель успеха против 45% для лучшей базовой линии
4 июня 2025 г.Таблица ссылок
Аннотация и 1 введение
2 предварительные
3 Transic: передача политики с рисованием в реальность путем обучения на онлайн-коррекции и 3.1 базовые политики обучения в моделировании с RL
3.2 ОБУЧЕНИЯ ОТРИЦИЯ ПОЛИТИКИ ОТНОВЛЕНИЯ НАУКЦИИ
3.3 Интегрированная структура развертывания и 3,4 Подробности реализации
4 эксперименты
4.1 Настройки эксперимента
4.2 Количественное сравнение по четырем задачам сборки
4.3 Эффективность в решении различных разрывов с рисунком (Q4)
4.4 Масштабируемость с человеческими усилиями (Q5) и 4,5 интригующих свойств и возникающего поведения (Q6)
5 Связанная работа
6 Заключение и ограничения, подтверждения и ссылки
А. Подробная информация об обучении симуляции
Б. Реальные детали обучения в реальном мире
C. Настройки эксперимента и детали оценки
D. Дополнительные результаты эксперимента
4.2 Количественное сравнение по четырем задачам сборки
Как показано на рис. 4 и таблице 1, Transic достигает лучших производительности в среднем и во всех четырех задачах со значительными полями. Теперь мы подробно сравниваем их и обсуждаем основные выводы.
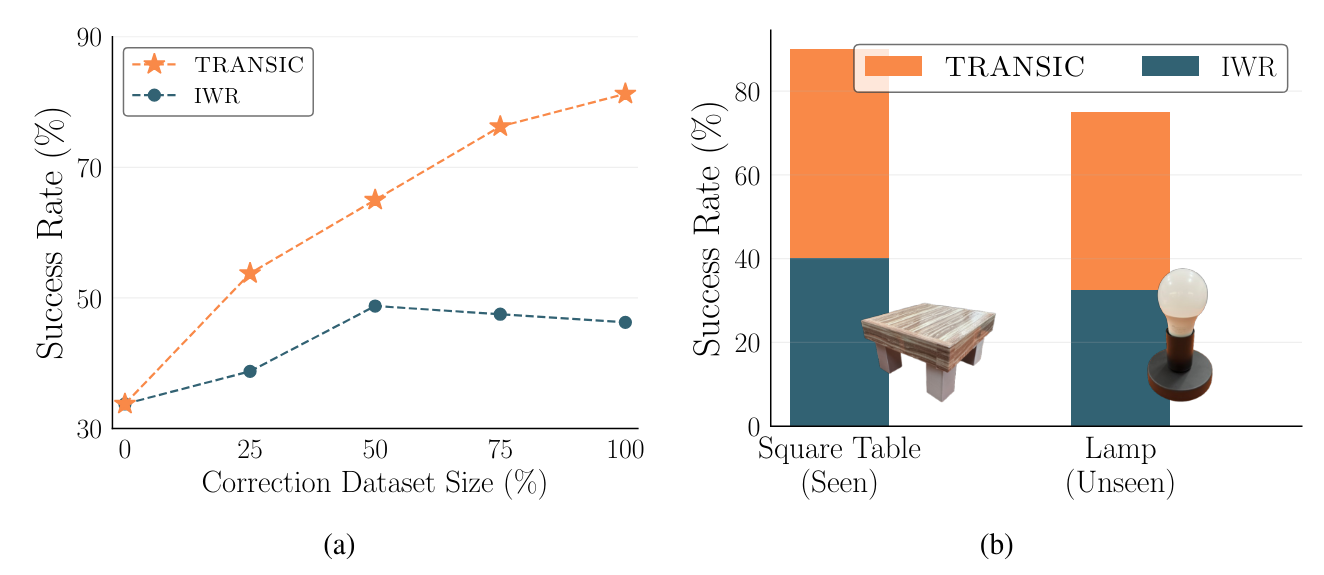
Транцик эффективен для передачи с рисованием с рисования (Q1).Он успешно достигает высокого среднего показателя успеха в 81% по четырем задачам на реальных роботах. Для стабилизирования задачи он может достичь 100% успеха, в то время как лучший базовый метод (BC Fine-Tune) имеет только половину времени. Для сложных задач, которые требуют точных и богатых контактами манипуляций, таких как вставка и винт, транспорта приводит к многообещающим результатам (45% и 85% успешных показателей соответственно), в то время как базовая линия прямого переноса никогда не достигает успеха.
Каковы причины успешной передачи? Мы наблюдаем, что добавление реальных данных о человеческой коррекции не гарантирует улучшения. Например, среди традиционных методов SIM-к реальному, лучшие базовые BC Fine-Tune превосходят DR. & Data Aug. на 7%, но IQL Fine-Tune приводит к худшей производительности. Напротив, в Tranicic эффективно используются данные по коррекции человека, что повышает среднюю производительность на 124%. Предположительно, незначительное улучшение BC Fine-Tune связано с разницей в доменах между моделированием и реальностью. Это значительное различие не может быть легко преобразовано через наивную точную настройку. В целом, Transic не только достигает наилучших результатов передачи, но и улучшает политику моделирования наиболее наиболее среди различных подходов к рисунке.
Transic может лучше включать в себя коррекцию человека в первоначальную научную политику (Q2).Из-за различий между поведением человека и робота [68], использование реальных данных для непосредственного определения политики, которая была в значительной степени обучена по машинным траекториям, может привести к нежелательной производительности. В частности, Transic превосходит интерактивные методы IL, включая HG-Dagger [66] и IWR [67] в среднем на 75%. В то время как они оба весят данные вмешательства выше во время обучения (раздел 2,2), мы обнаруживаем, что они склонны стереть первоначальную политику и привести к катастрофическому забыванию. Следовательно, в пространстве штатов, где не существует вмешательства человека, они ведут себя неоптимально и, следовательно, страдают от проблем с перерывами из-за ошибок. Напротив, путем включения коррекции человека с отдельной остаточной политикой и интеграции как базовой, так и остаточной политики посредством стробирования, Transic сочетает в себе наилучшие свойства обеих политик во время развертывания. Он опирается на имитационную политику для надежного исполнения большую часть времени; Когда базовая политика, вероятно, потерпит неудачу, она автоматически применяет остаточную политику, чтобы предотвратить сбои и правильные ошибки.
Транцик требует значительно менее реальных данных (Q3).Для достижения превосходной производительности требуется только десятки реальных траекторий для достижения превосходной производительности. Тем не менее, такие методы, как BC-RNN и IQL, обученные такому ограниченному количеству данных, страдают от переживания и обрушения модели. Transic достигает 3,6 × лучшей производительности, чем они. Фактически, по мере увеличения сложности задачи нам может потребоваться экспоненциально более реальные данные для обучения этих моделей, которые полагаются исключительно на демонстрационные данные реального мира, согласно предыдущей литературе [68]. Этот результат сначала подчеркивает важность подготовки к моделированию, а затем использует передачу с симуляцией в реальность для практикующих специалистов-роботов.
Краткое содержаниеМы показываем, что при переводе с реальностью симум хорошую базовую политику, полученную из моделирования, может быть объединена с ограниченными реальными данными для достижения успеха (Q3). Однако эффективное использование данных по коррекции человека для решения разрыва в рисунке является сложной задачей (Q1), особенно когда мы хотим предотвратить катастрофическое забывание об базовой политике (Q2).
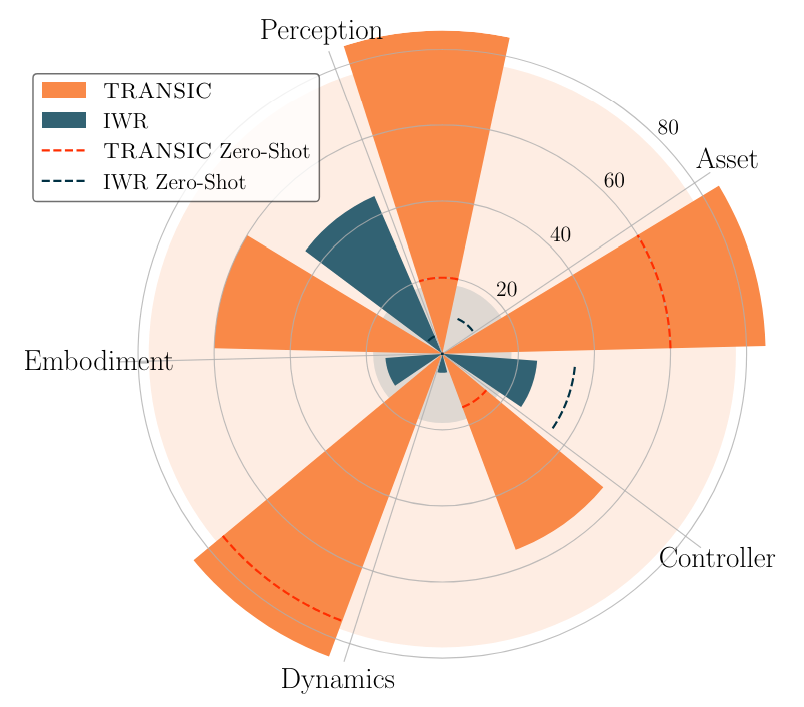
4.3 Эффективность в решении различных разрывов с рисунком (Q4)
В то время как Transic является целостным подходом для решения нескольких пробелов с рисованием с рисунком, мы пролили свет на его способность закрывать каждый отдельный пробел. Для этого мы создаем пять различных пар моделирования реальности. Для каждого из них мы намеренно создаем большие пробелы между симуляцией и реальным миром. Эти пробелы применяются к настройке реального мира, и они включают в себя ошибку восприятия, контроллер непредвзятости, несоответствие варианта, разность динамики и несоответствие активов объектных активов. Обратите внимание, что это искусственные настройки для контролируемого исследования. Смотрите приложение гл. C.2 для подробных настроек.
Как показано на рис. Это указывает на его замечательную способность закрывать эти индивидуальные пробелы. Напротив, лучший базовый метод, IWR, достигает только среднего успеха в 18%. Мы приписываем эту эффективность в решении различных пробелов с рисунком с реальностью с дизайном остаточной политики. Zeng et al. [83] Эхо наш вывод о том, что остаточное обучение является эффективным инструментом для компенсации доменных факторов, которые нельзя явно смоделированы. Кроме того, обучение с данными, специально собранными из конкретной настройки, обычно повышает производительность Transic. Тем не менее, это не относится к IWR, где точная настройка новых данных может даже привести к худшей производительности. Эти результаты показывают, что Transic лучше не только для решения нескольких разрывов SIM-к реальности в целом, но и в обработке отдельных типов пробелов совершенно другой природы.
Авторы:
(1) Юнфан Цзян, факультет информатики;
(2) Чен Ван, кафедра компьютерных наук;
(3) Руохан Чжан, Департамент информатики и Институт ИИ, ориентированного на человека (HAI);
(4) Цзяджун Ву, Департамент информатики и Институт ИИ, ориентированного на человека (HAI);
(5) Ли Фей-Фей, Департамент информатики и Институт ИИ, ориентированного на человека (HAI).
Эта статья есть
Оригинал
🔥 Популярное на этой неделе
-
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
4 признака того, что ваш Instagram взломали (и что делать)
16 ноября 2022 г. -
Предстоящие эксклюзивы для PS5 — график выхода подтвержденных игр
24 октября 2023 г. -
Как подключить беспроводную клавиатуру Apple к Windows 10
18 апреля 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
Categories
- Технологии и IT (25564)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (271)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)
