
Обучение Tesseract для языков с низким разрешением
20 августа 2025 г.Таблица ссылок
Аннотация и 1. Введение
1.1 Печатная станка в Ираке и Иракском Курдистане
1.2 Проблемы в исторических документах
1.3 Курдский язык
Связанная работа и 2,1 арабского/персидского
2.2 Китайский/японский и 2,3 коптса
2.4 Греческий
2.5 латынь
2.6 Tamizhi
Метод и 3.1 Сбор данных
3.2 Подготовка данных и 3.3 Предварительная обработка
3.4 Настройка среды, 3,5 подготовка набора данных и 3,6 Оценка
Эксперименты, результаты и обсуждение и 4.1 обработанные данные
4.2 Набор данных и 4.3 эксперименты
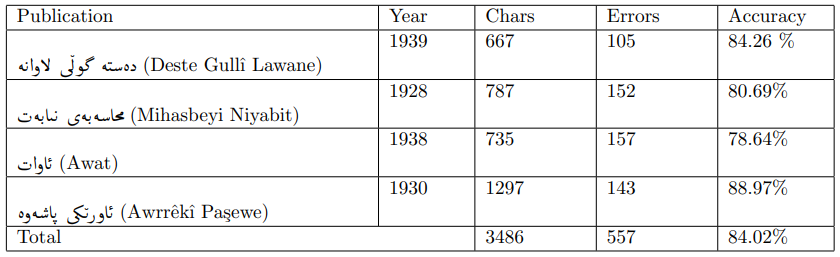
4.4 Результаты и оценка
4.5 Обсуждение
Заключение
5.1 Проблемы и ограничения
Онлайн -ресурсы, подтверждения и ссылки
5 Заключение
Основная мотивация для этого исследования проистекает из значительного количества исторических документов, хранящихся в библиотеках, которые все еще необходимо обработать. Отсутствие возможностей обработки привело к изучению технологии OCR для курда, языка с низким ресурсом. Реализация OCR для извлечения текста из исторических документов на курдском языке значительно улучшит доступные ресурсы.
Было проведено обширные исследования для оценки существующих систем OCR для курдских и других языков по всему миру. Расследование было сосредоточено на предыдущей работе, точности и базовом

технология. Было установлено, что Tesseract является подходящим вариантом для этого исследования.
После того, как технология была выявлена, были предприняты усилия по сбору цифровых копий исторических документов, напечатанных до 1950 года. Эта задача оказалась сложной задачей, так как определение документов и преобразование их в цифровой формат представлял дополнительные препятствия. К счастью, Центр документации и исследований в Цине в Сулеймании, который специализируется на архивировании исторических документов, предоставил несколько книг в виде цифровых копий.
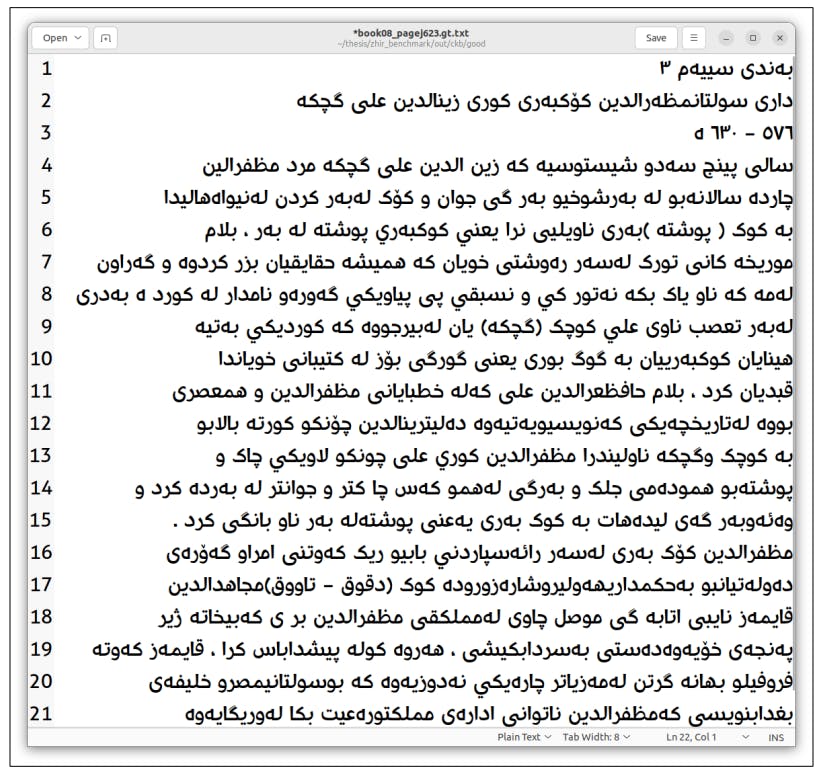
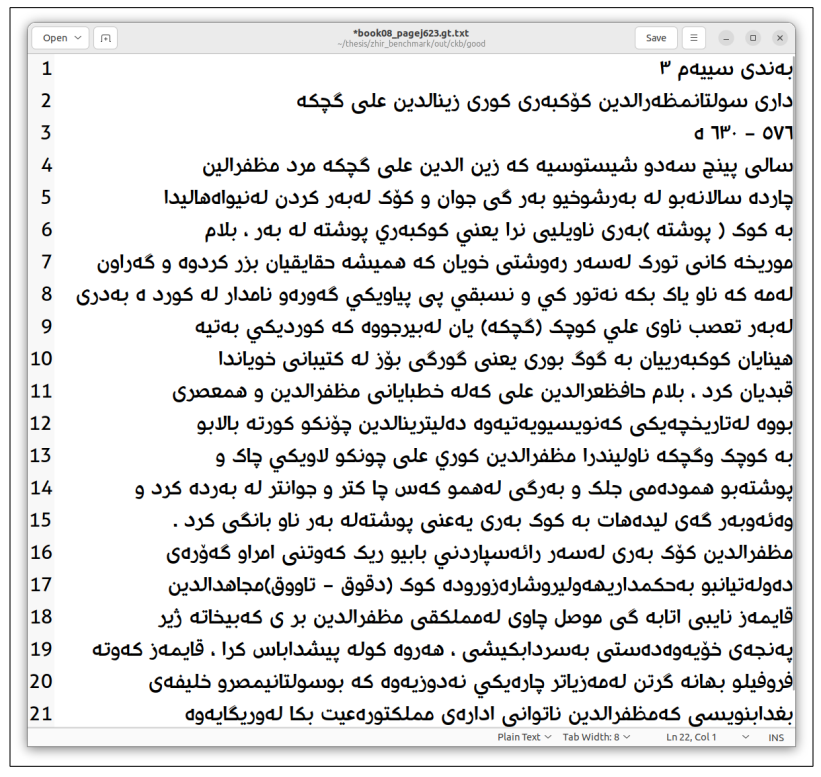
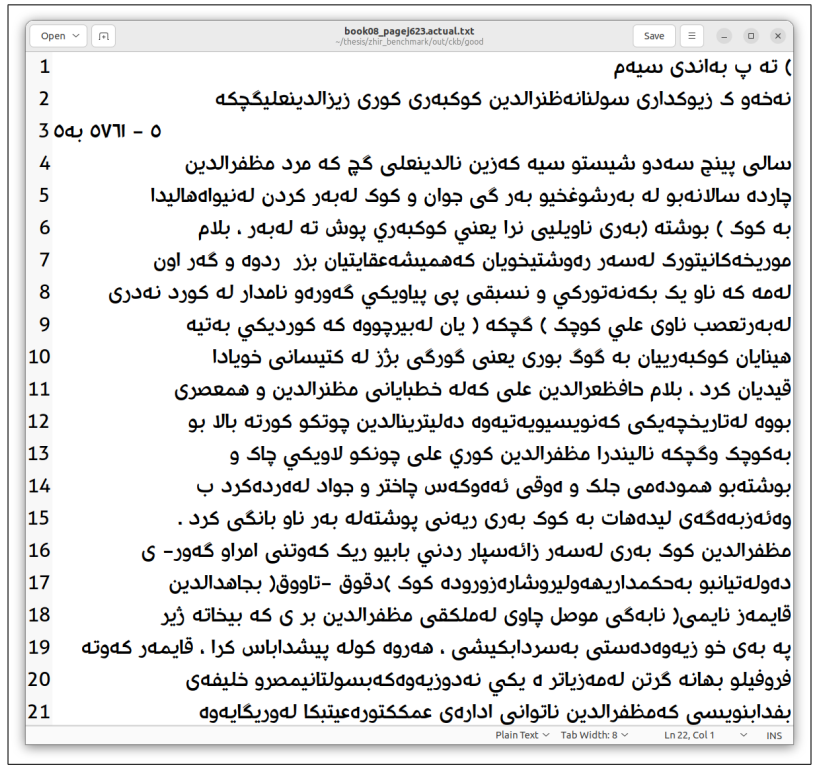
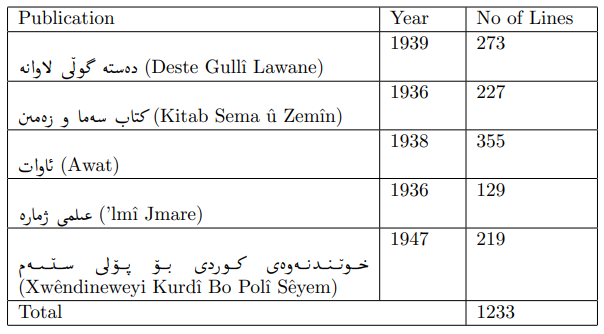
После получения оцифрованных копий был создан набор данных для обучения модели Tesseract. Текстовые линии были извлечены со страниц, транскрибировались индивидуально и подвергались предварительной обработке для подготовки набора данных.
С набором данных из 1233 линий модель была обучена на основе арабской модели. После обучения производительность модели была оценена с использованием различных методов. Встроенный оценщик Tesseract LSTMEVAL показал CER 0,755%. Кроме того, Ocreval продемонстрировал среднюю точность характера 84,02%. Наконец, собственное веб-приложение было разработано для предоставления простого в использовании интерфейса для конечных пользователей, что позволило им взаимодействовать с моделью путем ввода изображения страницы и извлечения текста.
Эта модель может быть ценным инструментом для библиотек и центров, что позволяет им извлекать текст из исторических документов и эффективно выполнять дальнейшую обработку.
Авторы:
(1) Blnd Yaseen, Университет Курдистана, Регион Курдистан - Ирак (blnd.yaseen@ukh.edu.krd);
(2) Университет Курдистана Хоссейна Хассани Курдистана Регион Курдистан - Ирак (hosseinh@ukh.edu.krd).
Эта статья есть
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27283)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)