

SP или не для SP
14 августа 2025 г.Введение
Код, который выглядит безвредным, часто может привести к негативным последствиям. Давайте рассмотрим, как простая копия данных с ядро Ontity Framework может создать узкое место в производительности, почему хранящаяся процедура иногда является лучшим решением, и какое это связано с командными соглашениями.
Однажды у меня была любопытная дискуссия с моим другом (давайте назовем его Беном) об операциях базы данных. Он бросил мне вызов определить потенциальные проблемы в следующем фрагменте кода:
public class GraphReplicator
{
public void CreateCopy(Guid sourceId, Guid targetId)
{
IEnumerable<Node> sourceNodes = dbContext.Nodes
.Where(node => node.StructureId == sourceId)
.AsEnumerable();
foreach(var node in sourceNodes)
{
Node newNode = CreateBasedOn(node, targetId);
dbContext.Nodes.Add(newNode);
}
dbContext.SaveChanges();
}
}
Список 1
Я сознательно сохранил код синхронным для читаемости.
Эти несколько строк кода выглядят простыми и довольно безвредными. Здесь есть серьезная проблема? Я не знаю, как, кем и при каких обстоятельствахCreateCopyМетод называется, как часто он называется, сколько записей в базе данных, где база данных расположена относительно приложения, будь то на удаленной машине, насколько быстро сеть и так далее. Короче говоря, Challenge принят! КакКот ШредингераСказал бы, проблема существует и не существует, пока мы не копаем глубже.
Копать глубже
Что делаетCreateCopyМетод?
Использование основного ядра предприятия, методПолучает немногочислоузлы из базы данных,Создает копиикаждого испасает их обратнов базу данных.
"получает"→"спасает их обратно".
Первое, что беспокоило меня: два запроса базы данных. Один для получения данных, другой, чтобы отправить копированные данные. Не секрет, что наиболее трудоемкими операциями являются сетевая связь, включая такие запросы.
Эмпирическое правило:Чем меньше сетевых запросов (любого рода), тем лучше.
Воздействие: по крайней мере 2x замедление.
"некоторыйколичество "
Сетевая связь стоит дорого, но все становится хуже, когда объем данных увеличивается. Поскольку мы не знаем, сколько организаций копируется, это может быть серьезной проблемой. Что, еслиsourceNodesсодержит 1000 узлов? Разумно ли передавать 1000 узлов из базы данных по сети? Как насчет 10 000? И помните - затем мы отправляем их копии обратно в базу данных.
Эмпирическое правило:Чем меньше объем данных, передаваемых по сети, тем лучше.
Воздействие: по крайней мере 2x замедление. (На самом деле, для этого случая нам вообще не нужно передавать какие -либо данные)
"Создает копии"
Другая проблема: материализация в памяти. Принесение 1000 узлов создает 1000 объектов в памяти. Копирование их создает еще 1000. Это увеличивает давление на сборщика мусора, и мы все помним, что эти объекты должны быть очищены по памяти, верно?
Эмпирическое правило:Чем меньше объектов распределяются на кучу, тем меньше работы должен сделать сборщик мусора. (GC Docs)
Воздействие: ухудшение общей производительности системы.
Посмотрите вокруг
А как насчет вызывающего кода? Мне удалось раскрыть некоторые важные детали. ОказываетсяCreateCopyМетод - это лишь один из трех аналогичных шагов в более широком процессе копирования (давайте назовем егоCopyStructure) КромеGraph, есть два связанных объекта:PermissionиAttribute, каждый со своим собственным репликатором. Вызовный код вызывает у каждого репликатораCreateCopyметод последовательно:
void CopyStructure(Guid sourceId, Guid targetId)
{
_graphReplicator.CreateCopy(sourceId, targetId);
_permissionReplicator.CreateCopy(sourceId, targetId);
_attributeReplicator.CreateCopy(sourceId, targetId);
}
Листинг 2
Все они следуют одному и тому же алгоритму:
- Извлечь данные из базы данных
- Создать копии
- Сохраните копии в базу данных
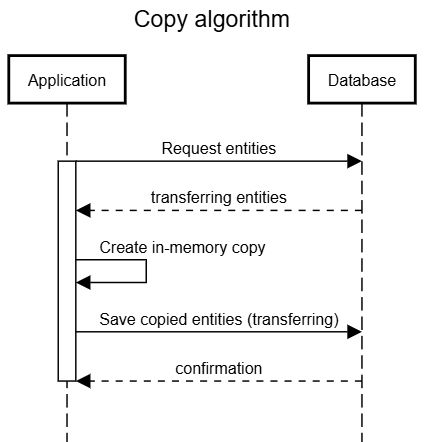
Таким образом, действия, показанные на диаграмме 1, будут выполнены 3 раза, что означает 6 запросов базы данных!
Почему это важно
Вы можете подумать, что передача 10/100/1000 (помните, что я сделал это число) объектов, выделяя 20/200/2000 объектов для GC, и задержка базы данных с задержками или сотнями миллисекунд является незначительным по сравнению с современной вычислительной силой. Приложение для однопользовательской консоли с локальной базой данных может не сильно пострадать. Но многопользовательское веб-приложение с внешними интеграциями, фоновыми работниками и сотнями или тысячами пользователей? Все проблемы выше (И может быть больше, я поделюсь еще одним ниже) может сигнализировать о системных проблемах.
Я говорю: один простой метод с потенциальной проблемой быстро превращается в три метода. Как долго мы найдем больше? Какова вероятность того, что есть десятки подобных мест? Что этот код называется тысячи раз по всей системе? Мы создаем системы на основе существующего кода, иногда копируя шаблоны из других частей или даже других разработчиков. И да, иногда мы просто «копируйте вставку». У нас также есть соглашения для решения «типичных» задач. Вот почему экстраполяция здесь не надуманна.
Более того, мы часто оцениваем код в изоляции, забывая, например, о многопользовательских/многопоточных контекстах. С этой точки зрения ничто не предотвращаетCopyGraphМетод от конкуренции за ресурсы (соединения, сеть, база данных) даже с самим собой. Я не знаю бизнес -логику, стоящей за этим кодом, но я могу представить, что два, десять или сотня пользователей запускают этот процесс копирования одновременно.
На мой взгляд, оценка должна быть проведена в контексте всей системы. Два запроса здесь могут означать тысячи всей системы. «Дополнительные» передачи данных могут стать гигабайтами в месяц. Дополнительная задержка на 100 мс здесь может составлять до секунд или даже десятков секунд времени ожидания пользователя. (Не удивляйтесь, я видел это много раз).Но эй, ты всегда можешь добавить кэширование;)Ресурсы, захваченные «плохим» кодом, - это ресурсы, которые не будут доступны кому -то другому, для кого -то, кто может делать что -то важное.
Любой код существует в контексте его применения и подключен к десяткам или сотням классов, методов, условий и состояний системы. Вот почему программирование сложно.
Забытая транзакция
Вопрос: Разве код в листинге 2 выполняет все три шага в одной транзакции? Это было бы логично. Если_permissionReplicatorНе терпит неудачу, разве мы не должны отказаться от предыдущего шага? Если да, все становитсяЕще хужеПолем
void CopyStructure(Guid sourceId, Guid targetId)
{
using(TransactionScope scope = new())
{
try
{
_graphReplicator.CreateCopy(sourceId, targetId);
_permissionReplicator.CreateCopy(sourceId, targetId);
_attributeReplicator.CreateCopy(sourceId, targetId);
scope.Complete();
}
catch
{
// handle
}
}
}
Листинг 3
(Использование транзакций в основных документах Ontity Framework)
При работе с базой данных есть большое правило: «Транзакция должна быть максимально недолгой». Длинные транзакции означают:
- Более длительные длительности блокировки
- Высшие шансы на тупики
- Более низкая общая производительность системы
В ожидании сетевой связи и передачи данных между приложением и базой данных, в нашем примере значительно увеличивает продолжительность транзакции.
Диаграмма 2 показывает полученный процесс. Я слегка уменьшил количество стрел, чтобы диаграмма не выглядела загроможденной, но если вы посмотрите внимательно, вы рассчитываете 7 запросов базы данных (узлы копирования: 2 + разрешения на копию: 2 + атрибуты копирования: 2 + Commit).
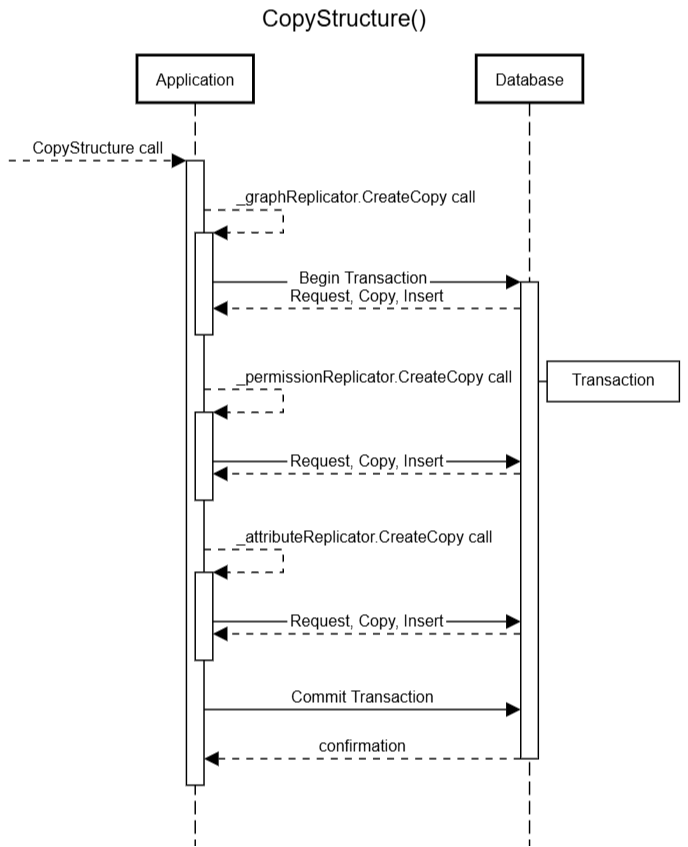
Трудно сказать окончательно, насколько это плохо.
Некоторые системы не очень требовательны с точки зрения производительности. Возможно, этот метод предназначен только для работы раз в неделю, и все прекрасные минуты ожидания и часы, чтобы он закончил.
С другой стороны, это может быть критическим потоком в системе электронной коммерции с высоким трафиком, где база данных обрабатывает десятки или сотни запросов в секунду. Метод может в конечном итоге быть вызванным очень часто. Во многих сценариях это было бы совершенно неприемлемо, особенно в многопоточной многопользовательской среде.
Раствор дилемма
И вот где Бен поймал меня в ловушку (помните, он начал это). Я ненавижу хранимые процедуры. Я вообще не могу их вынести. Но самым подходящим решением всех задач, описанных выше, было бы перенести логику в хранимую процедуру. Здесь база данных является как источником, так и пунктом назначения для данных, и эти данные не преобразуются и не обогащаются на этом пути. Почему бы просто не «спросить» базу данных, чтобы выполнить копию для нас?
Вы когда -нибудь слышали о шахматах переписки (проверкаВикипедия)? Двести лет назад люди буквально отправляли друг другу бумажные письма, описывающие их движения. Например, «KG1F3» означает, что рыцарь перешел от G1 к F3. Это вся информация, которую нужно было другому игроку, чтобы сделать такой же шаг на своей собственной доске.
Представьте себе, как было бы смешно, если бы они на самом деле отправляли по почте всю шахматную доску со всеми частями каждый раз, когда кто -то делал ход. Немного непрактично, не так ли?
Конечно, есть несколько причин моей «неприязни» хранимых процедур: их трудно отлаживать, снизить переносимость, усложнять тестирование системы, SQL не так выразителен, как «нормальные» языки. Бизнес -логика разбросана между кодом приложения и сохраненной кодом процедуры, что неудобно и иногда небезопасно во время разработки. Управление версией и изменением также может стать проблематичным.
Но, несмотря на все это, существует множество сценариев, где хранимые процедуры являются гораздо лучшим решением, чем альтернативы. Для примера, который мы обсуждаем здесь, и для условий, которые мы придумали в процессе, хранимая процедура была бы отличным выбором!
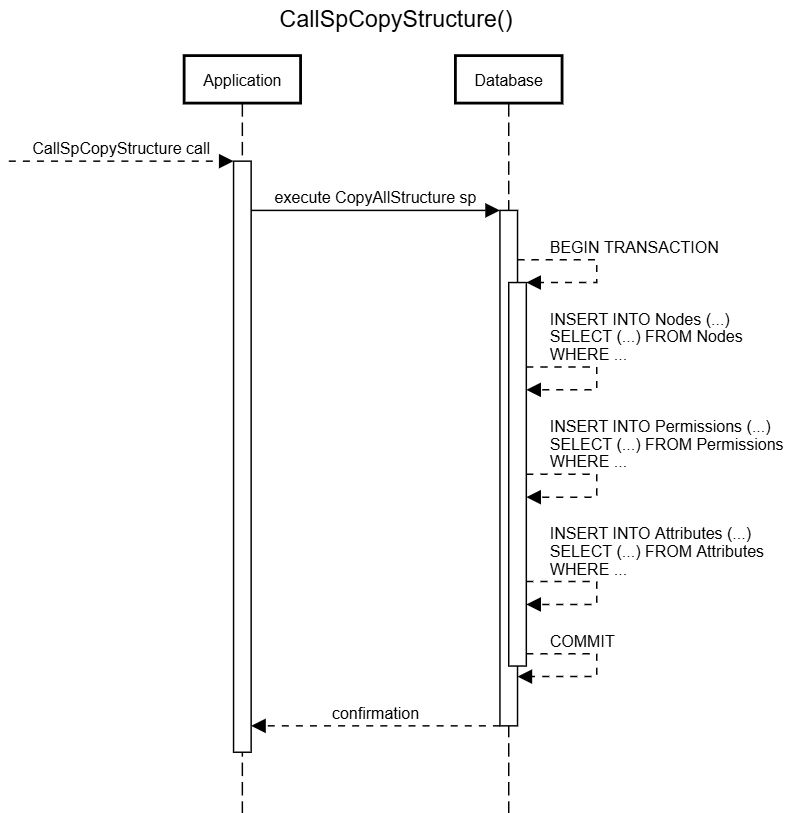
Пример кода сохраненной процедуры:
CREATE PROCEDURE CopyStructure
@SourceStructureId INT,
@TargetStructureId INT
AS
BEGIN
BEGIN TRAN
INSERT INTO Nodes (StructureId, SomeId1, SomeId2, SomeBool1, SomeString, Created1)
SELECT @TargetStructureId, SomeId1, SomeId2, SomeBool1, SomeString, Created1
FROM Nodes
WHERE StructureId = @SourceStructureId
INSERT INTO Permissions (StructureId, SomeId1, SomeId2, SomeBool1, SomeString, Created1)
SELECT @TargetStructureId, SomeId1, SomeId2, SomeBool1, SomeString, Created1
FROM Permissions
WHERE StructureId = @SourceStructureId
INSERT INTO Attributes (StructureId, SomeId1, SomeId2, SomeBool1, SomeString, Created1)
SELECT @TargetStructureId, SomeId1, SomeId2, SomeBool1, SomeString, Created1
FROM Attributes
WHERE StructureId = @SourceStructureId
COMMIT
END;
Список 4
И код, чтобы назвать это:
public void CallSpCopyStructure(Guid sourceId, Guid targetId)
{
_dbContext.Database.ExecuteSql($"EXEC CopyStructure {sourceId}, {targetId}");
}
Список 5
Что мы получили:
- 1 запрос базы данных вместо 7
- Нет передачи данных между приложением и базой данных (просто крошечная инструкция SQL и ответ).
- Значительно сокращение времени транзакции, без ненужного ожидания, только полезные действия внутри транзакции.
- Снижение давления на коллектор мусора.
Чтобы быть справедливым, это добавляет сложности к системе, но не так много.
И это все. Да, это действительно так просто!
Реакция Бена на то, почему они не делают этого в своем проекте, ожидался: «Мы не используем хранимые процедуры. БД должен хранить только данные. Мы используем только основное ядро объекта и нет необработанного SQL.«Это их соглашение, которое понятно. Может быть, их причины совпадают с моими для непреклонности сохраненных процедур.
Конвенции - это хорошо. Они определяют, как развивается проект, и помогают дисциплинировать разработчиков. Я искренне верю, что нет ничего хуже, чем вообще не иметь никаких соглашений. Тем не менее, мы не должны забывать, что условия, при которых эти конвенции были приняты, могут измениться.
Например, по мере роста вашего продукта могут возникнуть новые требования к производительности и потреблению ресурсов. Количество пользователей может взлететь за рамки, или, может быть, в какой -то момент вы понимаете, что поддержание ваших серверов слишком дорого, и вы решите сосредоточиться на оптимизации для экономии затрат. В бизнесе время часто является критическим фактором, вам нужно выпустить свой новый продукт перед конкурентами. Логично выбрать технологии и подходы, которые дают самые быстрые результаты, но это не значит, что вы должны оставаться заблокированными в этой парадигме после выпуска и успеха. Это может быть хуже, если условия не изменились, но были неправильно оцениваются изначально, и в самом начале вы просто совершили ошибку, выбрав инструмент, который не был оптимальным, а не наиболее подходящим.
В любом случае, я здесь не для того, чтобы вынести суждение. Я просто хочу сказать: важно оставаться гибким, исследовать альтернативные решения и не бояться менять правила, если они начнут наносить ущерб вашему проекту, даже если вам не нравятся новые правила. (Вы можете прочитать оЭффект SemmelweisнаВикипедия)
В целом, лучше думать меньше с точки зрения «анализа» и «неприязни», и больше с точки зрения того, насколько полезным инструмент или решение для вашего проекта и лучше всего ли он подходит для этой задачи.
Альтернативные решения?
Важно уточнить: почти нет ситуаций, когда единственное решение является единственным действительным. Тот, который я предложил, не является исключением. Например, вам не обязательно нужна хранящаяся процедура, это не процедура, которая решает проблему, но это тот факт, что мы делегируем работу в базу данных с помощью SQL. Мы могли бы так же хорошо позвонить_dbContext.Database.ExecuteSqlи передайте тот же код SQL, который я разместил в хранимой процедуре. Эффект будет точно таким же.
Просто для развлечения я подал черновик этой статьи нескольким LLMS и попросил их критиковать ее. Каждый по праву отметил отсутствие альтернативных подходов, таких как:
- SQLBULKCOPY
- Партийные операции через RAW SQL
- Окрашивать
- Временные таблицы
- CQR или управляемые событиями шаблоны
Примечательно, что последние два (особенно ориентированные на события) похожи на зуб, растущий в носу, что совершенно не имеет отношения к описанной проблеме. Первые три действительно должны быть рассмотрены вПодобные сценарии, но для этогоконкретный случай, они не применимы, поскольку они не решают корневую проблему.
Итак, это ожидаемый, но в конечном итоге бесполезный ответ, спасибо, ИИ.
«Возможность искать и оценивать все возможные альтернативы» - невероятно ценный навык.
Заключение
Вся эта статья основана на предположениях и предположениях, как и большая часть нашей работы.
Моя цель состояла в том, чтобы продемонстрировать необходимость «копать глубже»: поставить под сомнение код, инструменты, которые мы используем, и конвенции, в которых проводится разработка. Догматическая приверженность правилам может привести к негативным последствиям. Технические решения должны быть приняты на основе контекста, а не принципов или предпочтений. Конвенции должны оставаться гибкими и адаптироваться к изменяющимся условиям.
Я работаю над системами, где проблемы, на которые я указал, чрезвычайно важны, потому что мы должны учитывать эти факторы; В противном случае система может просто прекратить функционирование. Ваша ситуация может быть и, вероятно, отличается. Вы работаете в уникальных условиях над уникальным проектом. Успех проекта определяется вашей способностью найти оптимальный баланс между различными решениями.
Только вы можете решить, стоит ли следующая оптимизация, которую она добавляет в систему. В то же время важно рассмотреть вопрос о том, может ли пренебрежение этой оптимизацией в пользу определенных конвенций в конечном итоге разрушить вашу систему.
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27294)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)