

Эта структура графика в реальном времени теперь позволяет переключаться с Neo4j на Кузу в одной линии
4 июня 2025 г.КокосоиндексТеперь предоставляет собственную поддержку Kuzu в качестве хранилища данных целевого графа. Эта интеграция оснащена высокопроизводительным стеком графов знаний с обновлениями в реальном времени.
Что такое Кузу
Кузуэто графическая база данных, которая предназначена для быстрой, масштабируемой и простых в использовании. Мы любим Кузу, потому что он высокий, легкий и открытый исходный код.
CocoIndex-это ультрапрофессиональная структура преобразования данных в реальном времени, с моделью программирования DataFlow, CocoIndex упрощает построение и поддерживая графики знаний с непрерывными обновлениями источника. Вы можете прочитать официальную документацию по кокосоиндексу для целей графа недвижимостиздесьПолем
Мы понимаем, что подготовка данных очень основана на основе использования, и нет универсального решения. Мы используем подход композиции, и вместо того, чтобы строить все, мы предоставляем собственные плагины, чтобы охватить экосистему и облегчить подключение и обмен любом модулем, стандартизируя интерфейс - точно так же, как LEGO.
Если вы используете CocoIndex для создания своего графика знаний, вы можете использовать Kuzu в качестве хранилища данных целевого графа.
Как картировать в Кузу в кокоиндексе
Интерфейс graphDB в кокодекс стандартизирован, если вы уже используете NEO4J, вам просто нужно переключить конфигурацию на экспорт в Кузу, как показано ниже. Кокоиндекс поддерживает экспорт в Кузу через свой сервер API. Вы можете запустить сервер Kuzu API локально, работая:
KUZU_DB_DIR=$HOME/.kuzudb
KUZU_PORT=8123
docker run -d --name kuzu -p ${KUZU_PORT}:8000 -v ${KUZU_DB_DIR}:/database kuzudb/api-server:latest
В вашем потоке кокодекс вам необходимо добавить спецификацию соединения Kuzu в свой поток.
kuzu_conn_spec = cocoindex.add_auth_entry(
"KuzuConnection",
cocoindex.storages.KuzuConnection(
api_server_url="http://localhost:8123",
),
)
Как это выглядит для создания индексационного потока с кокоиндексом + kuzu
Пример графа знаний о кокосоиндексе, который получил наибольшую любовь, - это создать график знаний с LLM, вот подробныйПошаговый блогПолем В проекте мы обрабатываем список документов и используем LLM для извлечения отношений между понятиями в каждом документе.
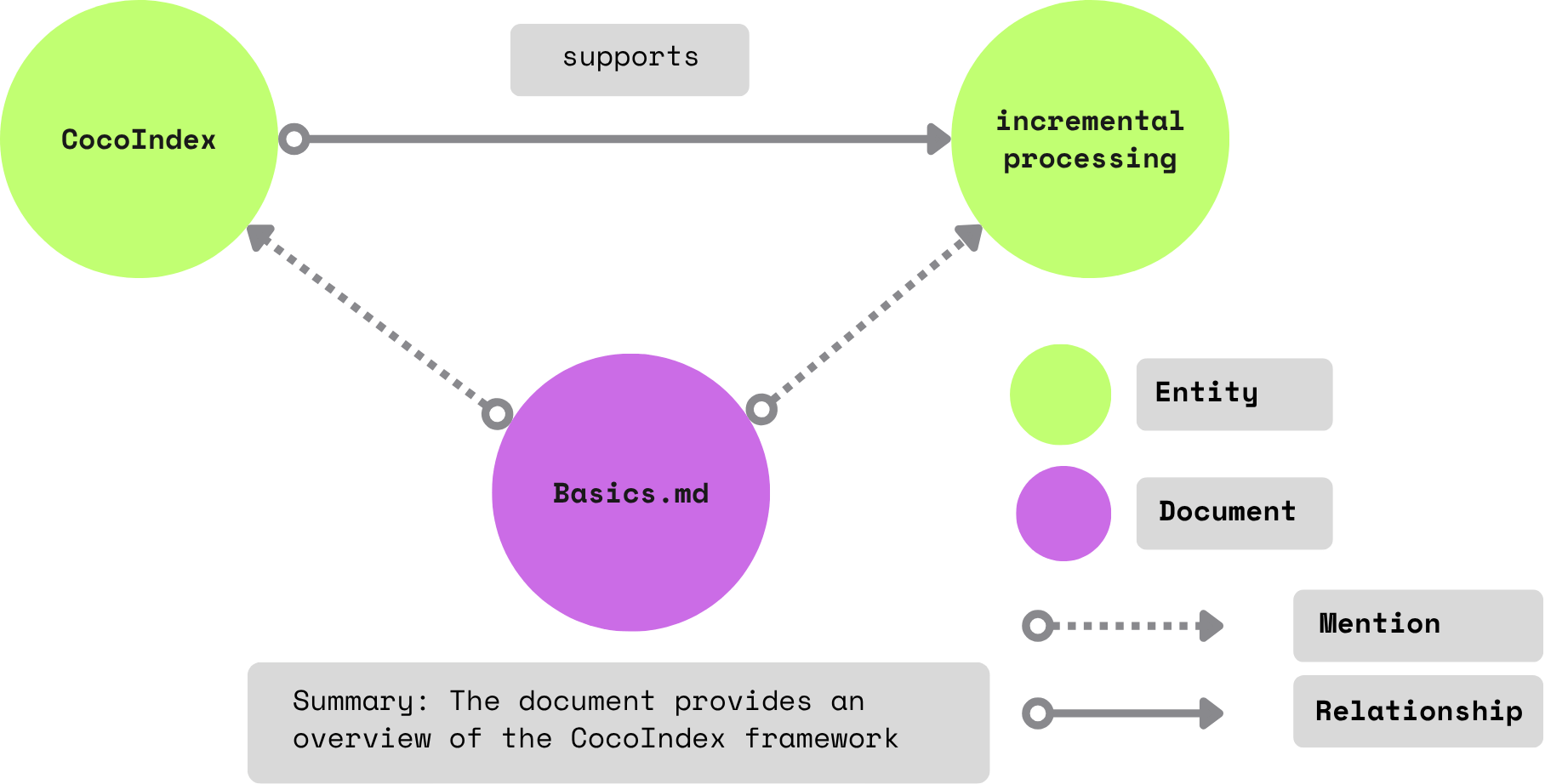
Мы будем генерировать два вида отношений из документов:
- Отношения между предметами и объектами. Например, «Кокосочеинг поддерживает постепенную обработку»
- Упоминает организации в документе. Например, «Core/Basics.mdx» упоминает кокосоиндекс и постепенную обработку.
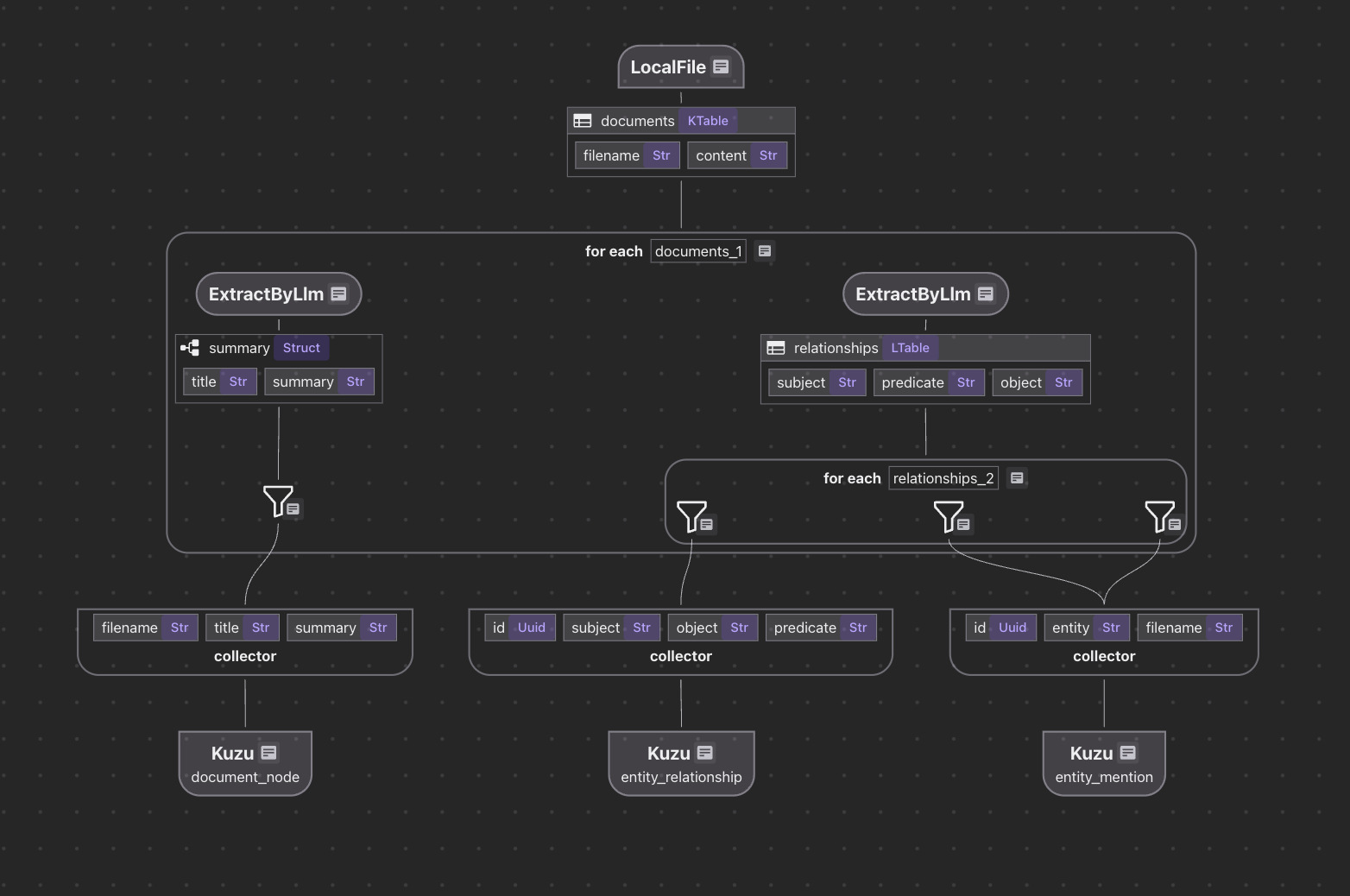
Поток индексации выглядит так для Кузу:
Код доступенздесьПолем
Проглатывание документов в кокоиндекс
Обработайте документы для каждого документа:
- Узлы документов MAP: используйте LLM для генерации сводки и сопоставьте документы с графическими узлами в Кузу.
- Узлы отношений карты: используйте LLM для извлечения отношений и экспорта отношений в Кузу.
Примечательно, что для того, чтобы получить готовую график знаний, требуется всего ~ 200 строк Python; включая определения класса, подсказки и конфи.
Чтобы подчеркнуть, как работает извлечение отношений, вы определите класс Python для структурированного извлечения.
@dataclasses.dataclass
class Relationship:
"""
Describe a relationship between two entities.
Subject and object should be Core CocoIndex concepts only, should be nouns. For example, `CocoIndex`, `Incremental Processing`, `ETL`, `Data` etc.
"""
subject: str
predicate: str
object: str
Если у вас есть предопределенный набор онтологии, вы можете пропустить извлечение сущности. Использование существующих сущностей.
Назовите преобразование в потоке, чтобы извлечь отношения из документа.
with data_scope["documents"].row() as doc:
# extract relationships from document
doc["relationships"] = doc["content"].transform(
cocoindex.functions.ExtractByLlm(
llm_spec=cocoindex.LlmSpec(
# Supported LLM: https://cocoindex.io/docs/ai/llm
api_type=cocoindex.LlmApiType.OPENAI,
model="gpt-4o",
),
output_type=list[Relationship],
instruction=(
"Please extract relationships from CocoIndex documents. "
"Focus on concepts and ignore examples and code. "
),
)
)
Вы можете использовать CocoinSight, чтобы проверить каждую пару отношений.
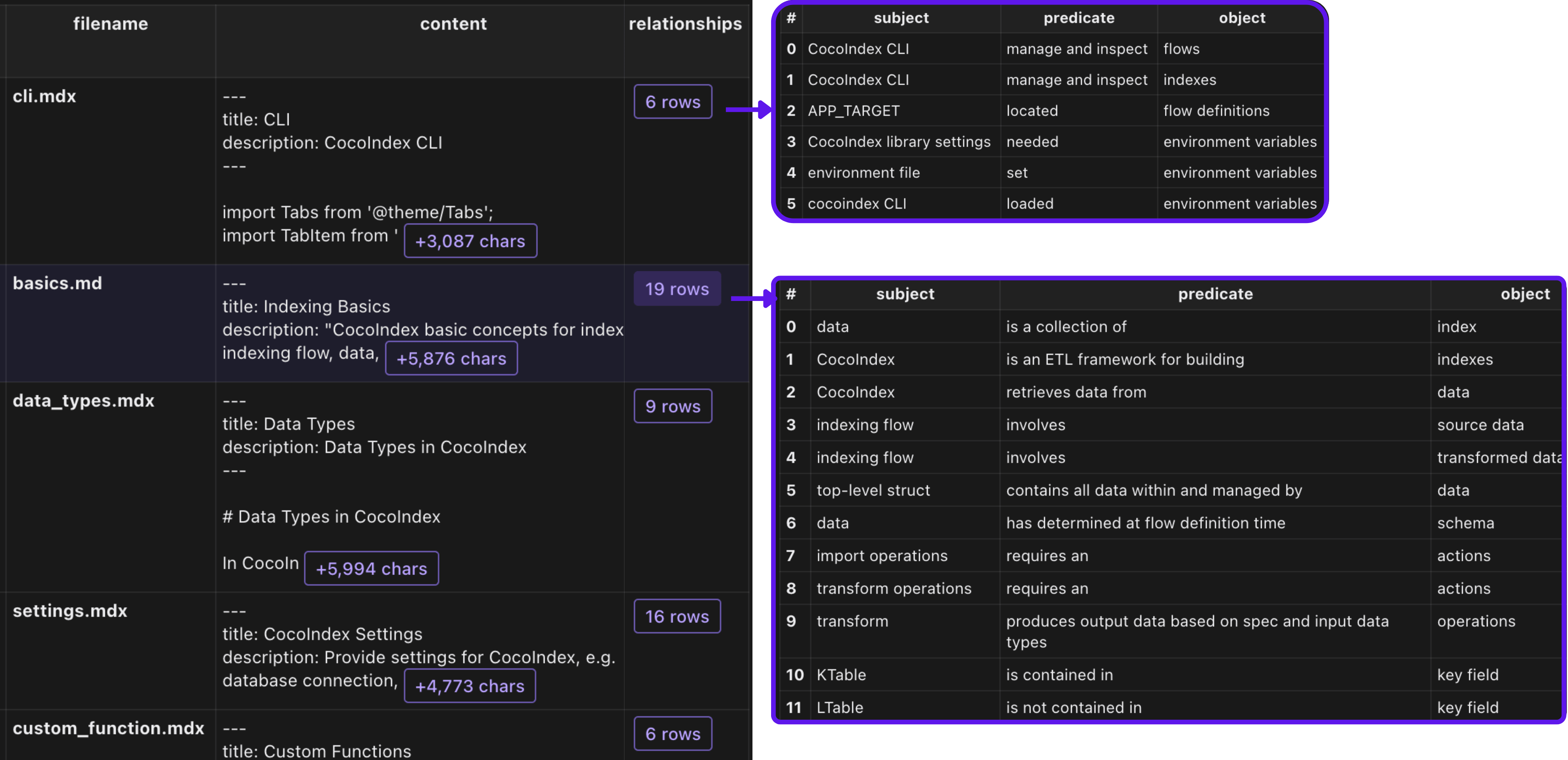
а затем собирайте использование отношенийentity_relationshipколлекционер.
with doc["relationships"].row() as relationship:
# relationship between two entities
entity_relationship.collect(
id=cocoindex.GeneratedField.UUID,
subject=relationship["subject"],
object=relationship["object"],
predicate=relationship["predicate"],
)
Кокоиндекс следует за моделью программирования данных. Вместо того, чтобы определять операции данных, такие как творения, обновления или делеции, разработчикам необходимо сосредоточиться только на преобразовании или формулах на основе исходных данных. Структура заботится о операциях данных, например, когда создавать, обновлять или удалять.
После того, как вы собрали отношения, вы можете напрямую отобразить их в Кузу, как показано ниже.
entity_relationship.export(
"entity_relationship",
cocoindex.storages.Kuzu(
connection=conn_spec,
mapping=cocoindex.storages.Relationships(
rel_type="RELATIONSHIP",
source=cocoindex.storages.NodeFromFields(
label="Entity",
fields=[
cocoindex.storages.TargetFieldMapping(
source="subject", target="value"
),
],
),
target=cocoindex.storages.NodeFromFields(
label="Entity",
fields=[
cocoindex.storages.TargetFieldMapping(
source="object", target="value"
),
],
),
),
),
primary_key_fields=["id"],
)
Удивительно, но, работая над этим примером Кузу, у меня был предыдущийпотокЧто я бежал на местном уровне с NEO4J. Это было мгновенно экспортировать в Кузу. Кокоиндекс основан на инкрементной обработке, и если вы уже запустили этот поток раньше и только что переключали цели, результаты промежуточного преобразования могут быть использованы повторно.
ЗапуститьKuzu Explorer- Пользовательский интерфейс с открытым исходным кодом для Kuzu, вам нужно сначала сбить сервер Kuzu API.
И тогда вы можете запустить следующую команду, чтобы запустить Kuzu Explorer:
KUZU_EXPLORER_PORT=8124
docker run -d --name kuzu-explorer -p ${KUZU_EXPLORER_PORT}:8000 -v ${KUZU_DB_DIR}:/database -e MODE=READ_ONLY kuzudb/explorer:latest
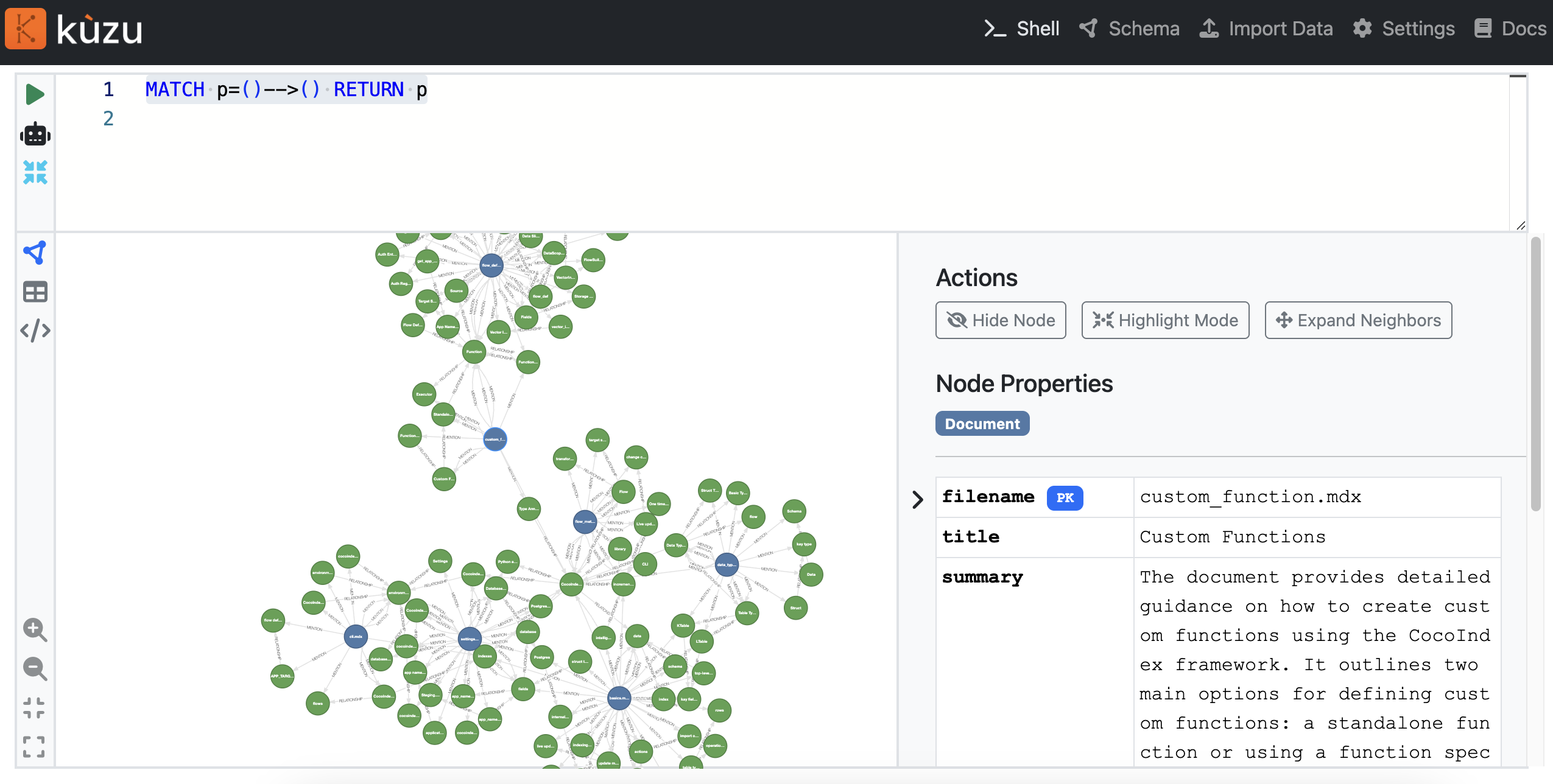
Затем мы могли бы получить доступ к исследователю вhttp: // localhost: 8124Полем Мы могли бы запустить запрос Cypher, чтобы исследовать график.
MATCH p=()-->() RETURN p
Мы постоянно улучшаемся, и скоро появятся больше функций и примеров. Если эта статья полезна, пожалуйста, бросьте нам звезду ⭐ наGitHubЧтобы помочь нам расти.
Спасибо за чтение!
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27313)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)