

Этот ИИ превращает тексты в полностью синхронизированные песни и танцевальные выступления
8 августа 2025 г.Таблица ссылок
Аннотация и 1. Введение
Связанная работа
2.1 Текст на вокальное поколение
2.2 Текст на генерацию движения
2.3 Аудио до генерации движения
Раскоростный набор данных
3.1 Рэп-вокальное подмножество
3.2 Подмножество рэп-движения
Метод
4.1 Составление проблемы
4.2 Motion VQ-VAE Tokenizer
4.3 Vocal2Unit Audio Tokenizer
4.4 Общее авторегрессивное моделирование
Эксперименты
5.1 Экспериментальная установка
5.2 Анализ основных результатов и 5.3 исследование абляции
Заключение и ссылки
А. Приложение
В этом разделе мы оцениваем предлагаемую модель на нашем предлагаемом эталонном эталоне, предназначенном для совместного вокального и целого движения тела из текстовых входов.
5.1 Экспериментальная установка
МетрикиПолем Чтобы оценить качество поколения поющего вокала, мы используем средний балл мнения (MOS), чтобы оценить естественность синтезированного вокала. Для синтеза движения мы оцениваем качество генерации жестов рук тела и реализм лица, соответственно. В частности, для генерации жестов мы используем расстояние на основе основания Frechet (FID) на основе экстрактора признаков из [13], чтобы оценить расстояние распределения признаков между генерируемыми и реальными движениями, и метрикой разнообразия (DIV) для оценки разнообразия движений. Для генерации лица мы сравниваем Vertex MSE [66] и разницу в Vertex L1 [68]. Наконец, мы принимаем Beat Constancy (BC) [29], чтобы измерить синхронность сгенерированного движения и поют вокал.
Базовые линииПолем Мы сравниваем качество вокального поколения с современным методом вокального поколения Diffsinger [32]. И мы также адаптируем модель текста в речь Fastspeech2 [51] для вокального поколения. Для генерации движений мы сравниваем наш метод с методами текста к движению и методами звука. Для методов текста к движению, поскольку не существует существующей работы с открытым исходным кодом для генерации движения в целом тел, мы сравниваем с T2M-GPT на основе трансформаторов [69] и MLD [4] для генерации тела. Для поколения аудио-движения мы сравниваем с Habibie et al. [15] и модель SOTA Talkshow [68]. Мы сообщаем о всех результатах на Rapverse с 85%/7,5%/7,5%поезда/Val/Test Split.
5.2 Анализ основных результатов
Оценки в совместном вокальном поколении и движении всего тела.Мы сравнили базовые показатели генерации движения, управляемого текстами, так и ориентированного на аудио в таблице. 2 (а). Чтобы быть отмеченным, наша настройка отличается от всех существующих методов следующими способами. Во -первых, мы используем рэп текст в качестве нашего текстового ввода вместо текстовых описаний движения, которые содержат слова прямых действий, такие как ходьба и прыжок; Во-вторых, мы используем текст для совместного генерирования как аудио, так и движения, вместо использования аудио для генерации движения в качестве звуковых методов. Как показано, наша модель соперничает с методами текста к движению, так и методам звука с точки зрения показателей, измеряющих качество движения тела и точность движения лица.
Кроме того, краеугольный камень нашего подхода заключается в одновременной генерации вокала и движения, стремясь достичь временного выравнивания между этими методами. Эта цель подтверждается нашими конкурентными результатами по метрике BC, которая оценивает синхронность между поющим вокалом и соответствующими движениями, подчеркивая наш успех в тщательно синхронизации генерации этих двух методов. Для каскадной системы мы интегрируем диффсингер для текста к модели с ток-шоу «Аудио-модель». По сравнению с каскадной системой наш трубопровод совместного поколения демонстрирует превосходные результаты, а также снижает вычислительные требования как на этапах обучения, так и на этапах обучения. В каскадных архитектурах ошибки имеют тенденцию накапливаться на каждом этапе. В частности, если модуль текста к своему своему, производит неясные вокалы, он впоследствии препятствует способности модели звука к движению генерировать точные выражения лица, которые соответствуют вокальному контенту.
Оценки вокальных поколений.Мы также сравнили наш метод с другими самыми современными базовыми показателями текста вдока в таблице. 2 (б). Хотя наша унифицированная модель обучена одновременно генерировать вокал и движение, задача значительно более сложная, чем генерирование вокала, его компонент вокального генерации по -прежнему удается достичь результатов, сопоставимых с теми системами, разработанными исключительно для вокальных поколений.
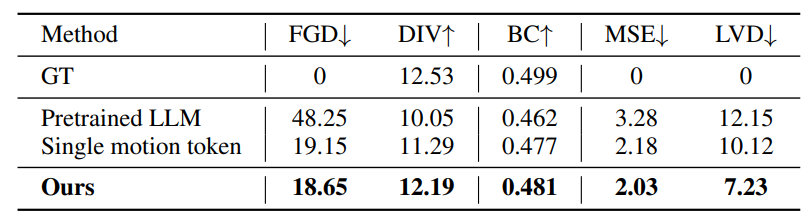
5.3 Исследование абляции
Мы представляем результаты нашего исследования абляции в таблице. 3. Первоначально мы исследовали интеграцию предварительно обученной большой языковой модели [48] для многомодальной генерации, сродни подходу в [23]. Тем не менее, эффективность использования предварительно обученных языковых моделей значительно отстает от нашего индивидуального дизайна, подчеркивая, что предварительное обучение, прежде всего, на лингвистических токенах, не способствует эффективному прогнозированию в разных модальностях, таких как вокал и движение. Кроме того, мы изучаем влияние наших композиционных VQ-VAE на генерацию движения. Напротив, был реализован базовый уровень, использующий единый VQVAE для квантования суставов лиц, тела и рук. Этот подход привел к заметному деградации в производительности, особенно отмеченной-2,89Уменьшение LVD. Это снижение может быть связано с преобладанием движений лица в исполнении певца. Использование одной модели VQ-VAE для динамики всего тела сталкивается с подробным представлением выражений лица, которые имеют решающее значение для реалистичного и когерентного синтеза движения.
Авторы:
(1) Цзябен Чен, Университет штата Массачусетс Амхерст;
(2) Синь Ян, Университет Ухана;
(3) Ихан Чен, Университет Ухан;
(4) Сиюань Сен, Университет штата Массачусетс Амхерст;
(5) Qinwei MA, Университет Цинхуа;
(6) Хаою Чжэнь, Университет Шанхай Цзяо Тонг;
(7) Каижи Цянь, MIT-IBM Watson AI Lab;
(8) ложь Лу, Dolby Laboratories;
(9) Чуан Ган, Университет штата Массачусетс Амхерст.
Эта статья есть
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27294)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)