
5 гениальных структур данных (и что они на самом деле делают)
18 июня 2025 г.Любой, кто когда -либо использовал клавиатуру, пытаясь сделать вещи на компьютере, должен знать семь основополагающих структур данных компьютерных наук: массивы, связанные списки, хэш -таблицы, стеки, очереди, графики и деревья. Это строительные блоки, ABC о том, как мы организуем данные.
Если вы каким -то образом пропустили основное краткое изложение того, как на самом деле работают компьютеры, вот быстрая версия: структура данных - это просто способ организовать данные, чтобы компьютер мог эффективно создавать, читать, обновить и удалять их (Crud, для Cool Kids).
- Анонцамножествопохож на ряд пронумерованных детенышей.
- АСвязанный списокэто карта сокровищ, где каждая подсказка ведет к следующей.
- Ахэш -таблицаэто как шкафчик с вашим именем на нем.
- Акучаэто как стопка книг.
- Аочередьэто линия детей в кафетерии.
- Аграфикэто паук -раб соединений.
- Идеревоэто, как дерево - ветви и листья.
Программирование - это все о решении проблем. А для многих разработчиков классические структуры данных-это хорошо проторенные пути, инструменты, которые мы использовали так часто, мы доступаем за ними, не задумываясь.Но что происходит, когда все становится грязным?
Когда скорость, размер или структура проталкивают пределы классики, все начинает ломаться. Именно тогда вы вступаете в мир специализированных структур данных, созданных для краевых случаев, масштабирования и неприятных проблем, которые настоящие системы бросают в вас.
Вот пять структур данных, которые сияют, когда все становится странно:
- #1-B-дерево: создан для больших данных
- #2 - Radix Tree: быстрые поиски с общими префиксами
- #3 - веревка: эффективное редактирование текста в масштабе
- #4 - Фильтр цветения: вероятностный поиск масштаба
- #5-хеширование ску
#1-B-дерево: создан для больших данных
Помните ощущение реализации вашего первого бинарного дерева поиска? В тот момент, когда сложности вашего алгоритма времени перестали идтиБрррр(O (N²)) и изящно скользят в гораздо быстрее O (log n)? Чистая магия.
But binary search trees have a hidden flaw: each node can only have two children. That makes them grow deep, fast. In memory, that’s usually fine. But on disk every extra level means another slow read. And when you’re dealing with massive datasets, that depth becomes a real problem.
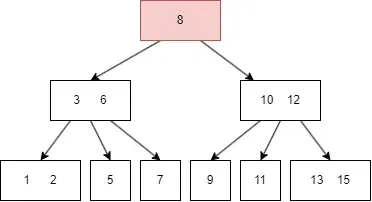
Вот гдеB Trees(и их популярный двоюродный брат, B+ дерево). Это держит дерево широко и мелким, что означает меньше чтения диска.
Внутри каждого узла B-Tree есть список отсортированных ключей. Эти ключи помогают вам решить, какой путь следует дальше, например, знаки на шоссе. Вместо того, чтобы просто выбирать между «левым» и «справа», как в бинарном дереве, вы сканируете ключи, чтобы выяснить, какую ветвь следует следовать. Внизу находятся листовые узлы, которые содержат фактические данные (или указатели на него). Результат: структура, которая обрабатывает огромные наборы данных со скоростью и эффективностью.
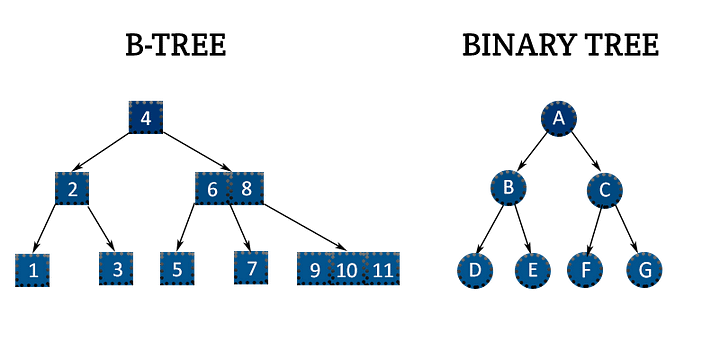
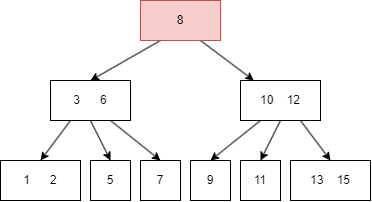 Думайте об этом, как о сверхэффективной системе подачи заявок для огромных наборов данных. Выпустив каждый узел во многих направлениях, B-деревья остаются широкими и поверхностными, что означает меньше уровней для поиска, и гораздо меньше медленных чтений диска. Вот почему они питают большинство файловых систем и баз данных сегодня. Простая идея, огромное влияние.
Думайте об этом, как о сверхэффективной системе подачи заявок для огромных наборов данных. Выпустив каждый узел во многих направлениях, B-деревья остаются широкими и поверхностными, что означает меньше уровней для поиска, и гораздо меньше медленных чтений диска. Вот почему они питают большинство файловых систем и баз данных сегодня. Простая идея, огромное влияние.
#2 - Radix Tree: быстрые поиски с общими префиксами
Интернет огромный, с миллиардами IP -адресов. Вы когда -нибудь задумывались, как ваш компьютер может так быстро понять правильный путь? Вот гдеРадиксное деревоПриходит (также называется Патриция Три или критическое дерево). Он построен для обработки ключей, которые разделяют общие начинания - например, IP -адреса или слова в словаре.
Вместо того, чтобы иметь узлы только с одним ребенком, дерево Radix объединяет эти узлы со своими родителями. Это делает дерево намного меньше, особенно когда многие ключи имеют одну и ту же стартовую последовательность.
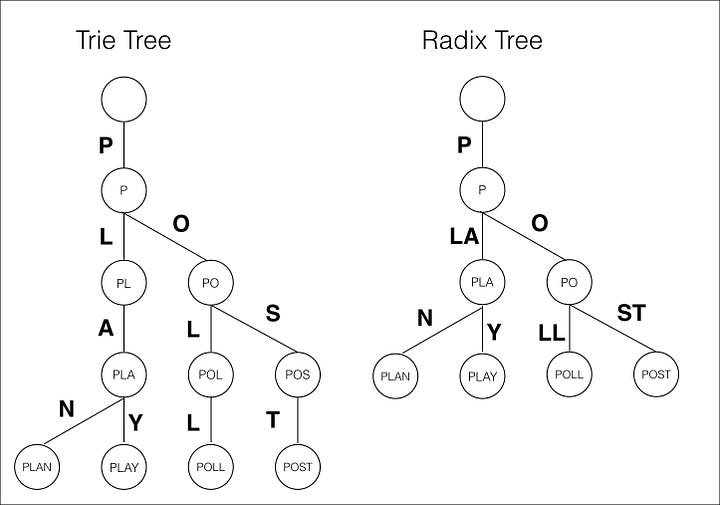
Например, простой тройник для таких слов, как «кошка», «машина» и «чашка», будет отдельные узлы для каждой буквы. Радиксное дерево объединит буквы, где это возможно - поэтому «C» и «A» могут слиться в одну ветвь с надписью «CA», потому что как «кошка», так и «автомобиль» разделяют этот префикс.
Это сжатие делает Radix Trees очень эффективными для таблиц маршрутизации и любой системы, которая требует быстрых поисков на основе префиксов. Они менее подходят для случайных или очень разных строк, но для поисков префикса они очень эффективны.
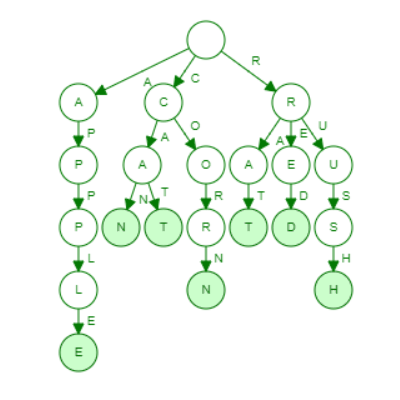
#3 - веревка:Эффективное редактирование текста в масштабе
Вы когда -нибудь пробовали редактировать огромный текстовый файл - как сотни мегабайт - и задавались вопросом, почему ваш редактор не задыхается? Это благодаря таким структурам данных, какверевкаПолем
Вместо того, чтобы хранить массивную строку в качестве одного непрерывного, громоздкого блока памяти (который делает вставки и удаляет кошмар перетасовки данных), веревка разбивает текст на более мелкие кусочки. Эти кусочки затем организованы в бинарное дерево.
Когда вы вставляете текст в середине документа, веревки не нужно перетасовать все, что происходит после. Он просто расщепляет соответствующий кусок, падает в новую часть и перебавляет дерево.
Внутренние узлы этого дерева не хранят сами персонажей; Вместо этого они хранят длину струны в левом поддерете. Это обеспечивает невероятно быстрой конкатенации, расщепления и подстроки.
#4 - фильтр цветов:Вероятностный поиск масштаба
Иногда самый умный ход - это не находить что -то - это быстро исключает. Вот чтоБлум фильтрыпостроены для.
Фильтр цветения-это космическая вероятностная структура данных, которая отвечает на простой вопрос:«Этот предмет определенно не в наборе?»Если он говорит «нет», вы можете полностью доверять этому. Но если это говорит «может быть», это может быть там - или это может быть ложным позитивным. Ключ: он никогда не дает ложных негативов.
Он работает, хэшируя каждый добавленный элемент с несколькими различными хэш -функциями. Каждый результат указывает немного в массиве фиксированного размера, который устанавливается на 1. Чтобы проверить на членство, вы снова хэшируете элемент. Если какие -либо из соответствующих битов 0, элемента определенно нет. Если все 1, это может быть.

Думайте об этом, как быстро движущийся сканер безопасности в аэропорту. Это может мгновенно помечать сумки, которые определенно пусты - не нужно их открывать. Но если что -томощьБудь внутри, он отправляет сумку для ручного осмотра. Вы сохраняете тонны времени, пропустив ненужные проверки, даже если несколько ложных тревог проскользнули. Это сила фильтра цветения: быстрый, легкий и идеально подходит для того, чтобы сказать «Нет, не здесь» в масштабе.
#5 - хешинг Куку:Постоянная вставка с изюминкой
Природа полна странного вдохновения. Возьмите птицу кукушки, известную тем, что пробираясь в другое птичье гнездо, откладывая собственное яйцо, и обманывая хозяин, чтобы воспитывать свою цыпочку. Эта довольно безжалостная стратегия выживания вдохновленаХешинг кукушкиПолем
Вот как это работает: у каждого ключа есть два или более возможных пятен в таблице, выбранных различными хэш -функциями. Когда вы вставляете ключ, вы проверяете его первое место. Если это пусто, все готово. Если это взято, новый ключ выбивает существующий ключ (ход «кукушка»). Затем вычеркнутый ключ пробует своего альтернативного места, возможно, выбивая еще один ключ, и это продолжается по мере необходимости.
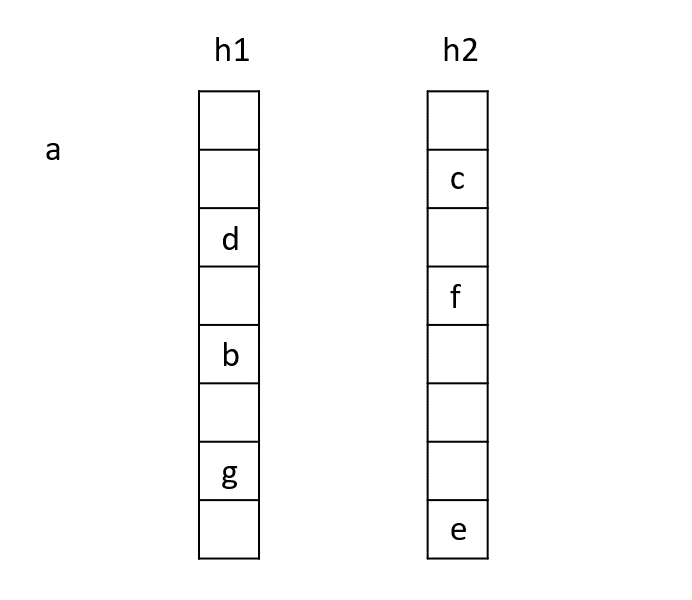
Если эта цепь выселений идет слишком долго или петли, вся таблица восстанавливается с помощью новых хэш -функций.
Выплата? Супербычные поиски, потому что каждый ключ может быть только в одном из нескольких фиксированных мест-нет поиска по длинным цепям.
За пределами учебника: изобретательность структур данных
Это не просто умные уловки. От B-деревьев, организующих мировые данные, до цветения фильтров, ускоряющих ваш веб-просмотр, эти передовые структуры данных являются свидетельством умных способов, которыми программисты имеют сгибание и формированные данные для решения действительно сложных проблем.
Они напоминают нам, что иногда самое элегантное решение - это не больше силы обработки, а принципиально более умный способ организации самой информации. Таким образом, в следующий раз, когда простой массив или список не разрезают его, помните, что существует целый мир гениальных структур, ожидающих изучения.
Хотите услышать от меня чаще?
👉 Связаться со мной на LinkedIn!
Я делюсьежедневноДействительные идеи, советы и обновления, чтобы помочь вам избежать дорогостоящих ошибок и оставаться впереди в мире искусственного интеллекта. Следуй за мной здесь:
Вы специалист по технологиям, чтобы вырастить свою аудиторию?
👉 Не пропустите мою информационную рассылку!
МойТехнологическая аудитория ускорительзаполнен действенным копирайтингом и стратегиями построения аудитории, которые помогли сотням профессионалов выделяться и ускоряют их рост. Подпишитесь сейчас, чтобы остаться в курсе.

Оригинал
🔥 Популярное на этой неделе
-
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27352)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)