
3 этапа MLOPS
9 июля 2025 г.В этой статье я расскажу о эволюции MLOP в технологических компаниях и о том, как все масштабируется по мере роста бизнеса. Я дам обзор эволюции, общих ошибок и общих руководств для команд, которые полагаются на развертывание ML и обслуживание.
Когда мы говорим ML Development, большинство людей думают, что мы должны просто получить несколько наборов данных, настраивать ее, а затем создать модель, проверить оценки и опубликовать модель. Хотя это верно для POC (доказательство концепции), это может не работать, когда мы хотим сохранить его. Представьте себе обучающую модель каждый день, когда вы начинаете работать, она становится слишком ручной и монотонной, и будет много знаний о племени, которые приведут к поддержке журналов или риска для компании или для команды. Для стартапов это будет иметь место, хотя. Они не хотят проводить много времени в инфраструктуре/CICD, когда вы хотите вести бизнес. Вначале это сработает просто отлично, даже если его руководство может быть вкладками Cron/запланированная работа AWS (Eventbridge) или скрипт оболочки на ноутбуке, когда -то отлично подойдет.

Эта стадия называется Mlops Stage 0, где в основном все в руках. Вы можете прочитать больше об этом в Google Mlopsдокумент.
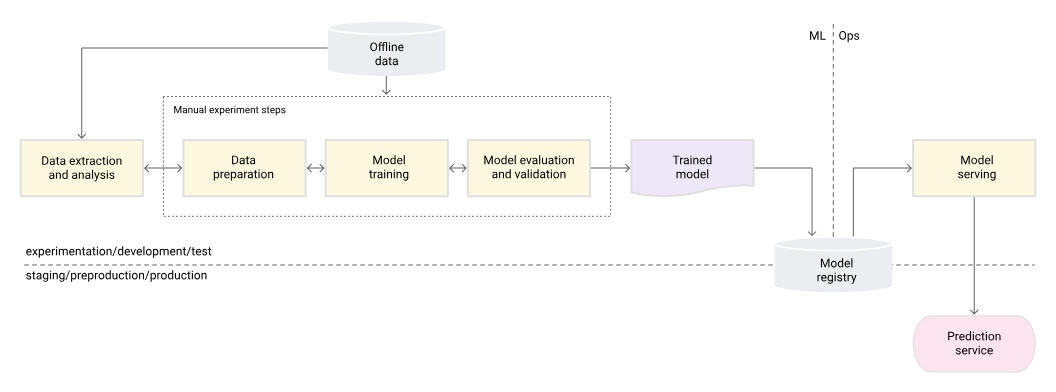
По мере того, как все идет, ваша команда будет медленно осознавать необходимость в MLOP, люди уйдут в отпуск, сценарии оболочек не пройдут, перезагружаются машины, а все не работает, обновления изменяют результаты вашей модели. Вы поймете, что пришло время пристегнуться и улучшить развертывание модели. Вы построите свой первый конвейер CICD, теперь возникают следующие проблемы. Вскоре вы понимаете, что теперь вам нужно, чтобы SLA поддерживали с вашими командами UPSTREAM, выходы моделей должны быть проверены, столбцы данных не должны менять свои определения, научная команда хочет добавлять больше функций, все больше людей хотят работать над вещами параллельно. Вот где все становится сумасшедшим, и вы находитесь в правильном направлении.
На этом этапе вы теперь будете инвестировать в создание инструментов, чтобы облегчить жизнь, мы можем назвать этот этап как Mlops Stage 1, ML Automation, большинство компаний считают это стабильным состоянием и будут жить с этой установкой. У него есть свои плюсы и минусы, но дополнительные инвестиции SDE занимают много времени, и большинство компаний с ограниченной пропускной способностью не будут учитывать это.
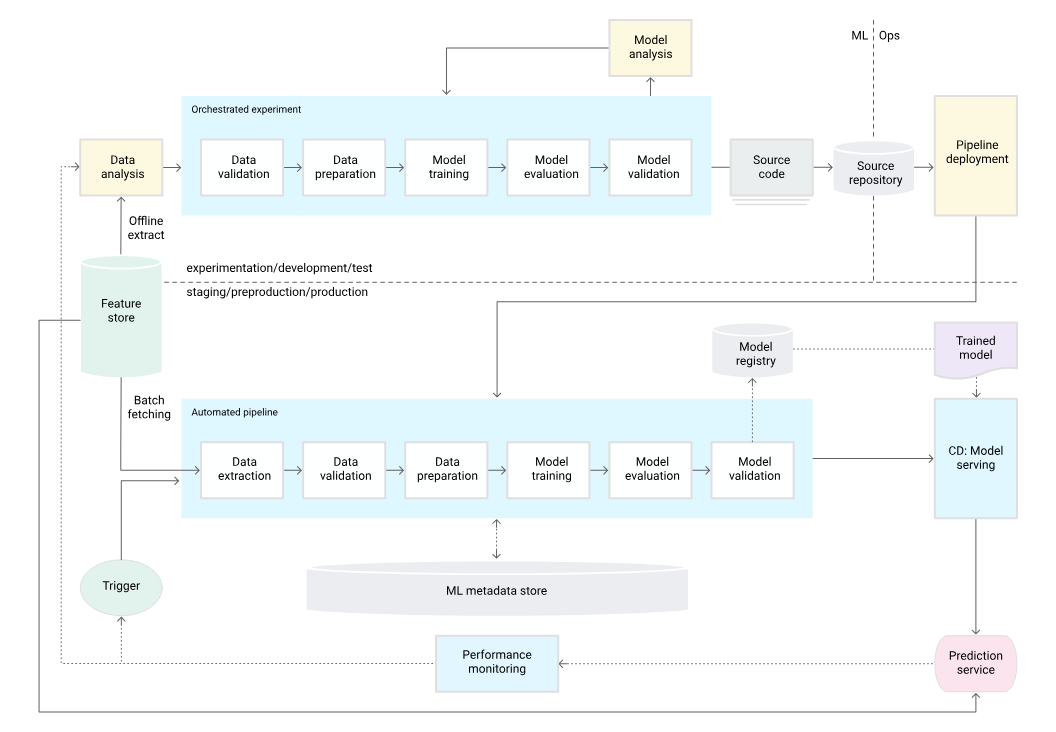
На первом этапе у вас будет команда из 4-10 SDE или ученых-исследователей, вы хотите, чтобы все прошло быстро, традиционный подход к созданию модели каждый день не будет работать для вашей команды. Вы начинаете строить трубопроводы сейчас, эти трубопроводы теперь автоматизируют большую часть детали для вас, например, проверка данных, подготовка к подготовке, обучение модели и валидации, и вы можете полагаться на Docker для поддержания пакетов и зависимостей. Вы будете использовать конвейер прогнозирования, который будет служить модели. Вы можете полагаться на такие оркестраторы, как воздушный поток, AWS SWF, Docker для пакетов и использовать GIT для CICD, и все будут иметь структурированные данные, и теперь вы определяете что -то, что называется SLA (Соглашение об уровне обслуживания). В течение нескольких лет дела идут гладко, и теперь ваша система развивается, и теперь у вас есть команда из 10 SDE и 10 ученых -исследователей. Теперь каждый RS хочет построить модель и быстро развернуть вещи, и у вас есть потребности в бизнесе. SDE не могут вручную удерживать каждый трубопровод, и у вас будет слишком много зависимостей, базовый пакет станет раздутым, и служба прогнозирования требует от руки, чтобы удерживать каждое изменение, он может координировать развертывание, чтобы убедиться, что вещи не сломаются. Теперь нам нужно развиваться до стадии 3, автоматизации трубопровода CI/CD.
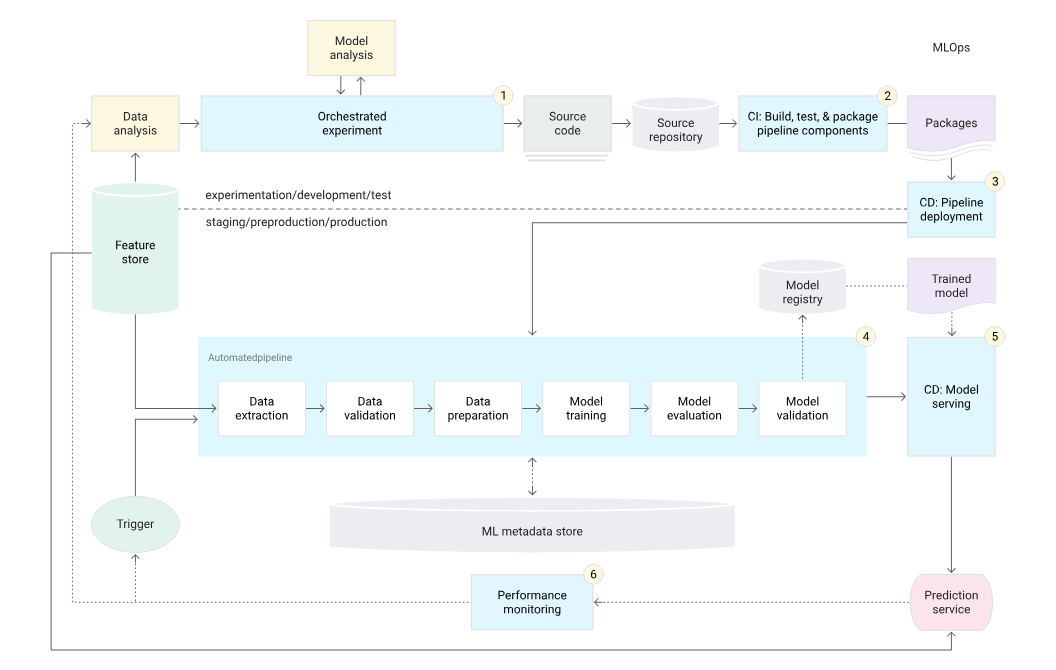
На этапе 2 нам нужно сделать шаг назад и понять, как строятся трубопроводы, абстрактные зависимости данных, и все еще полагаться на существующую инфраструктуру. Вероятно, это работа в большинстве компаний и нуждается в инновациях. Вам необходимо перейти от экспериментов к производству без основных переписываний кода, это означает, что вам необходимо создать платформу для работы и абстрактных деталей низкого уровня. Как только это завершено, научные команды и SDE могут двигаться быстрее, но здесь есть общая проблема, поскольку мы создали несколько абстракций, каждый должен изучить технический стек, чтобы ваша конкретная команда двигалась быстрее. Это приводит к крутой кривой обучения, и команды должны убедиться, что учебные документы были обновлены своевременно, в противном случае это не сработает.
В будущих статьях мы обсудим о основополагающих модельных трубопроводах и о том, как они обучены и поддерживаются. И мы рассмотрим каждый компонент в более технических деталях и существующем техническом стеке, который вы можете использовать для каждого варианта использования. Эти истории или мнения связаны с моим личным опытом, и это может отличаться для других SDE. Спасибо за чтение и за статьи Google Mlops за вдохновение.
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Лучшие новогодние подарки для владельцев домашних животных
29 мая 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27342)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)