Таблица ссылок
Аннотация и 1 введение
2 Связанная работа
3 подход сутры
3.1 Что такое сутра?
3.2 Архитектура
3.3 Данные обучения
4 тренинги многоязычных токенизаторов
5 многоязычных MMLU
5.1 Массивное многозадачное понимание языка
5.2 Расширение MMLU на несколько языков и 5.3 последовательная производительность между языками
5.4 по сравнению с ведущими моделями для многоязычной производительности
6 Количественная оценка запросов в реальном времени
7 Обсуждение и заключение, а также ссылки
3.3 Данные обучения
Ключ к нашей стратегии языковой подготовки заключается в использовании языковых общих черт на этапе изучения языка. Например, хинди имеет гораздо больше общих черт с точки зрения семантики, грамматики и культурного контекста с гуджарати или бенгальскими по сравнению с скандисными языками.
Ограниченные многоязычные возможности крупных языковых моделей (LLMS) связаны с неравномерным распределением данных, способствующим горстке хорошо ресурсовых языков. Многоязычные данные в машинном переводе являются специфичными для задачи и пропускают ключевые области обучения для LLM, такие как разговор, суммирование и подход к инструкции. Чтобы решить эту проблему, набор данных Sutra включает в себя более 100 миллионов разговоров в реальных и синтетически переведенных парах на различных языках, дополненных общедоступными наборами данных для комплексного обучения. Прошлые исследования продемонстрировали роль синтетических данных в содействии рассуждениям, генерации кода и обучению сложности задач в LLMS, а также в улучшении перекрестного переноса с помощью многоязычных синтетических данных [Lai et al., 2023, Whitehouse et al., 2023]. После этого понимания мы принимаем методическое использование обильных данных из таких языков, как английский, для облегчения концептуального обучения. На этапах изучения языка и выравнивания многоязычного обучения мы используем комбинацию реальных и синтетических данных для подкрепления
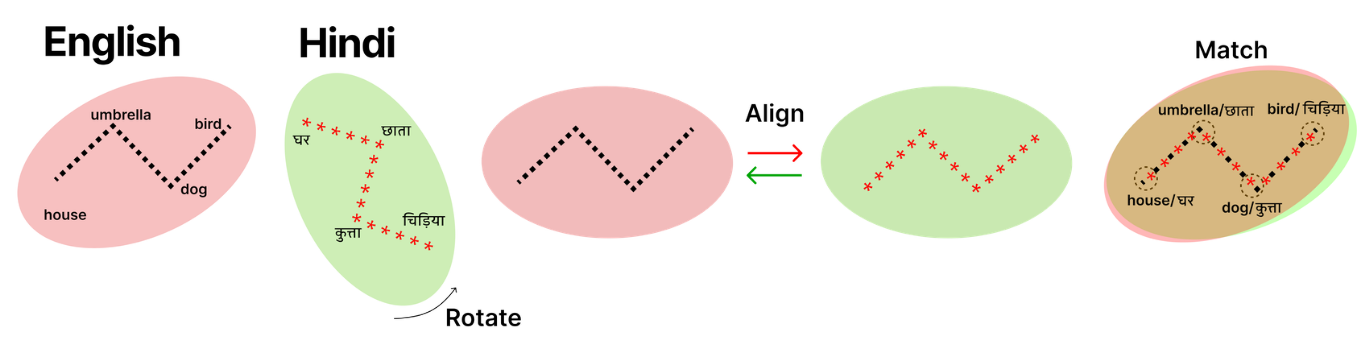
и расширить нашу учебную структуру. Иллюстрация и описание процесса соответствия и выравнивания показаны на рисунке 3.
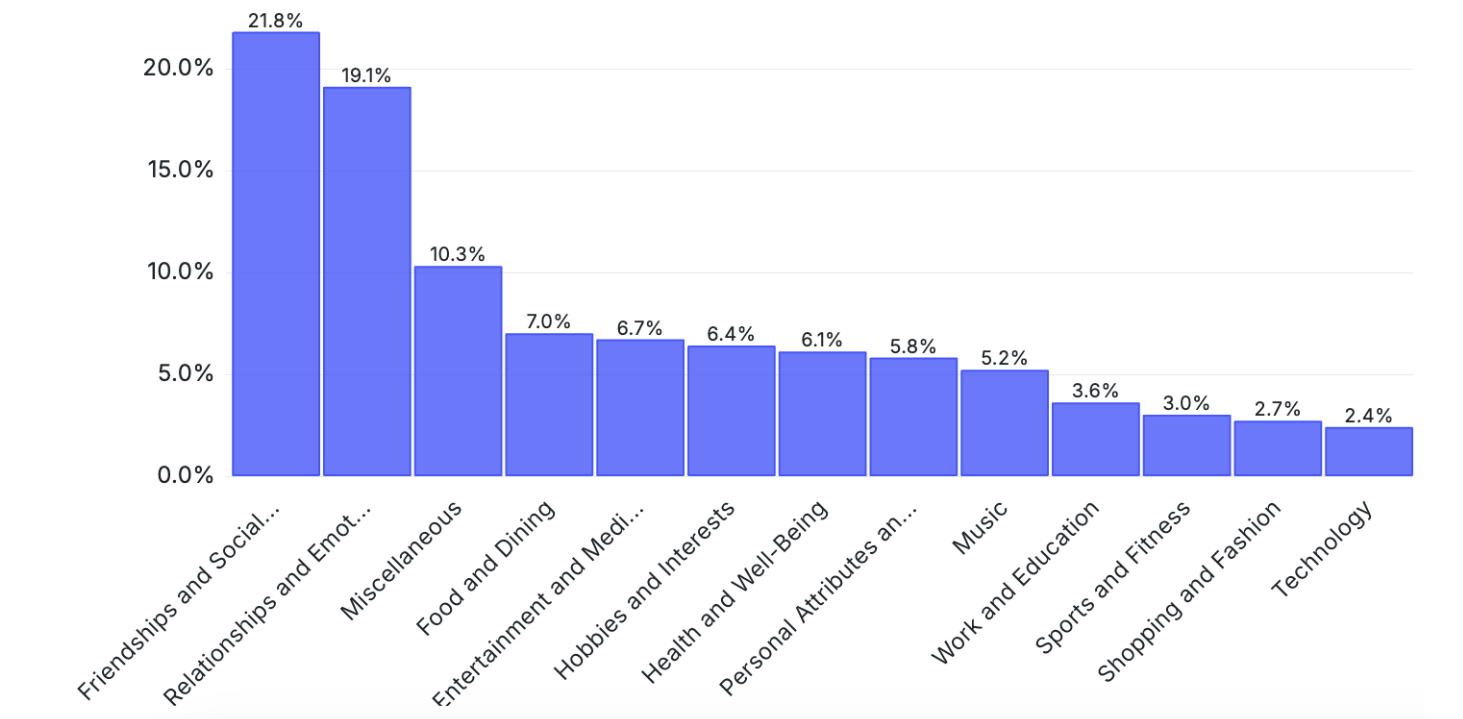
На рисунке 4 мы показываем распределение тем более 1 м разговоров. Проверка кластерных центроидов показывает, что это богатые и разнообразные данные, охватывающие широкий спектр тем.
Специально построенные многоязычные токенизаторы эффективно представляют каждый язык. Они обучаются по межязычным данным и точно настроены с базовой моделью, устанавливая новый эталон в многоязычном моделировании языка. Одним из наиболее важных аспектов получения хорошей производительности в разговорных LLMS является высококачественная инструкционная настройка (IFT). Большинство наборов данных IFT на английском языке. Мы используем перевод нейтральной машины (NMT) для перевода
![Table 3: In this table, statistics of various leading conversation datasets are shown such as Anthropic HH [Bai et al., 2022], OpenAssistant Conversations [Köpf et al., 2023], LMSys [Chiang et al., 2024] and the SUTRA dataset. The tokens are counted using Llama2 tokenizer [Touvron et al., 2023] for public datasets and for SUTRA dataset using SUTRA’s tokenizer. One of the key aspects of our dataset is having long term and multi-turn conversations.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-mba34q4.png)
Инструкции, входы и выходы из разных наборов данных, чтобы обеспечить сбалансированное представление по задачам, на нескольких индийских и неанглийских языках. В целом, мы готовим более 100 метров учебных образцов из таких языков, как английский, хинди, тамильский, корейский и т. Д. С широкими наборами данных, такими как наш внутренний набор данных сутры, а также с открытым исходным кодом, OpenAssistant и Wikihow. Переведенные примеры отфильтрованы, чтобы сохранить высококачественные примеры. Обратите внимание, что наши внутренние данные включают в себя долгосрочные и многоразмерные разговорные данные, которые помогают настроить их на лучшие беседы и взаимодействия с человеком и аи. Сравнение и подробное описание набора данных показано в таблице 3.
Авторы:
(1) Абхиджит Бендейл, две платформы (abhijit@two.ai);
(2) Майкл Сапенза, две платформы (michael@two.ai);
(3) Стивен Рипплингер, две платформы (steven@two.ai);
(4) Саймон Гиббс, две платформы (simon@two.ai);
(5) Jaewon Lee, две платформы (jaewon@two.ai);
(6) Пранав Мистри, две платформы (pranav@two.ai).
Эта статья есть