
Масштабирование DevOps, не теряя умы (или ваш SLA)
30 июня 2025 г.Современные предприятия часто сталкиваются с общими проблемами DevOps - роскошными наборами инструментов, хлопьями трубопроводами, ручным узким местом и слепыми пятнами - которые медленные инженеры и разочарование. Исследование 2023 года из 300 ИТ -профессионалов обнаружило, что быстрые технологические изменения, скрытые IT -слепые пятна и сложные системы делают замешаемость серьезной проблемой. Без единой видимости организации могут пострадать от частых отключений стоимостью ~ 13,7 млн. Долл. США в год. Точно так же, когда каждая команда принимает свои собственные нишевые инструменты, это приводит кинструментРазрастание и хрупкие интеграции.
Общие болевые точки включают в себя:
- Разрастание инструмента:Десятки точечных решений для SCM, сборки, безопасности и т. Д. Каждый, кто требует пользовательского кода клея, ведущего к головным болям интеграции.
- Нестабильность трубопровода:Длинные, монолитные конвейеры CI/CD имеют тенденцию ломаться при изменении кода, вызывая частые сбои в сборке/тестах и переделку.
- Отсутствие наблюдения:Ограниченный мониторинг/метрики означает медленную диагностику проблем. Как отмечается в одном отчете, отсутствие четкой видимости по всему процессу приводит к указанию пальцев и задержкам.
- Ручные процессы:Одобрения человека и передача медленных и подверженных ошибкам. Любые ручные шаги приводят к обширному труду и риску неверных обновлений из -за человеческой ошибки.
Эти проблемы приводят к медленной доставке функций и стрессу для команд DevOps. Чтобы превратить хаос в контроль, предприятия должны модернизировать свои трубопроводы с помощью автоматизации, декларативной инфраструктуры и наблюдения.
Инфраструктура как код и патрон
Первым шагом является инфраструктура как код (IAC) - управление серверами, сетями и услугами через декларативный код. Хранение конфигураций инфраструктуры в GIT делает среды повторяющимися и проверенными. На практике такой инструмент, как Terraform, может автоматизировать обеспечение облаков.
Например:
provider "aws" {
region = "us-west-2"
}
resource "aws_instance" "web" {
ami = "ami-0c55b159cbfafe1f0"
instance_type = "t2.micro"
tags = {
Name = "web-server"
}
}
Этот фрагмент Terraform определяет простой экземпляр EC2. При приверженности GIT трубопровод CI/CD может автоматически применять его, обеспечивая постоянные среды каждый раз.
Опираясь на IAC, Gitops Practices делает GIT единственным источником истины для обоих кодовиинфраструктура. В рабочем процессе Gitops любые изменения вносятся с помощью запросов на притяжение и объединены в GIT; Затем автоматизированная система развертывает или возвращает живое состояние, чтобы соответствовать желаемому состоянию в GIT. Как объясняет Гитлаб, «Gitops использует репозиторий GIT в качестве единственного источника истины для определений инфраструктуры… и автоматизирует обновления инфраструктуры с использованием рабочего процесса GIT с CI/CD». Обращаясь к инфра -конфигурациям так же, как код приложения, Gitops вносит сотрудничество с OPS и устраняет дрейф конфигурации.
Автоматизированные трубопроводы CI/CD
В основе современных DevOps лежат автоматизированные конвейеры CI/CD, которые строят, тестируют и развертывают программное обеспечение на каждом коммите. Вместо дневных выпусков автоматизированные трубопроводы запускают подкладку, модульные тесты, интеграционные тесты и упаковку с каждым толчком. Например, типичный трубопровод начинается с запуска кода (или PR), проверяет код из GitHub/Gitlab, затем выполняет шаги сборки и тестирования. После успешных тестов трубопровод может автоматически развернуть артефакт в кластер виртуальной машины или контейнера. Суммируя:
Триггер и проверка:Любой коммит или запрос на вытягивание запускает трубопровод. Трубопровод «аутентифицирует SCM и проверяет код», включая любые сценарии сборки.
Строитель и тест:Код составлен, и выполняются модульные тесты (используя такие инструменты, как Maven, NPM или другие). Дополнительные шаги запустите проверки качества кода (Sonarqube, Linting) и интеграцию или сквозные тесты. Если какой -либо тест не удается, трубопровод останавливается и немедленно уведомляет разработчиков.
Пакет и развертывание:Если все тесты проходят, трубопровод упаковывает приложение и развертывает его в целевой среде. Усовершенствованные рабочие процессы могут включать в себя развертывания канарейки или сине-зеленых и автоматизированные откаты при сбое.

Ведущие инструменты CI/CD, которые поддерживают эти этапы, включают Jenkins, Github Actions, Gitlab CI, Azure Tipvines и новые облачные системы, такие как Tekton или Harness. Например, действия Jenkinsfile или GitHub Yaml могут определить многоэтапный трубопровод с шагами для создания, тестирования и развертывания кода.
on: [push]
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Run Tests
run: make test
- name: Deploy to Kubernetes
run: kubectl apply -f k8s/deployment.yaml
Автоматируя и отделяя CI от шагов CD, команды избегают специальных сценариев и ручной передачи. Как отмечает один из экспертов, зрелые организации «как можно чаще разрабатывают производство», используя CI, чтобы достать ошибки, и CD для надежного продвижения.
Инструменты имеют значение: компании часто консолидируют вокруг нескольких ключевых платформ, чтобы уменьшить разрастание. Автоматизированные трубопроводы также включают в себя методы смены левых (например, выполнение тестов и сканирование безопасности) и интегрируются с реестрами контейнеров, магазинами артефактов и сервисными сетками для сплоченного потока.
Контейнеризация и оркестровая
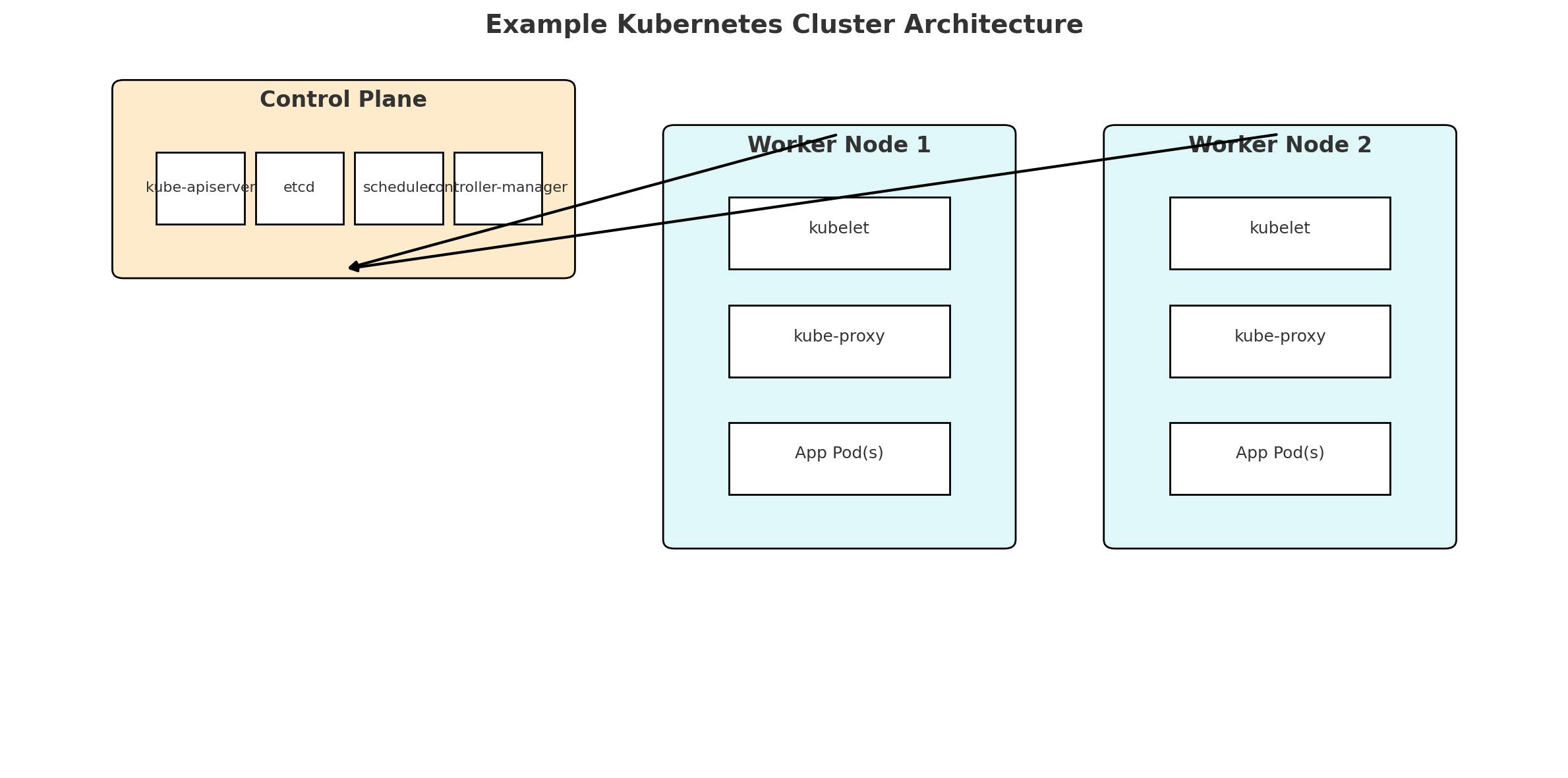
Предприятия в значительной степени пользуются стандартизацией контейнеров и оркестровки. Упаковочные приложения в контейнерах Docker гарантируют, что они работают так же при тестировании, постановке и производстве. Этими контейнерами затем управляются оркестровками, такими как Kubernetes. Кластеры Kubernetes состоят из плоскости управления (API -сервер и т. Д., Планировщики) и многих рабочих узлов, использующих стручки и сервисы.

Рисунок: пример кластерной архитектуры Kubernetes. Плоскость управления (мастер) включает в себя такие компоненты, как Kube-Apiserver и ETCD, в то время как рабочие узлы запускают кубелеты и прикладные стручки.
Используя Kubernetes, команды DevOps получают среду самообслуживания и быстрое масштабирование. Определения инфраструктуры часто хранятся в GIT и развернуты через CI/CD. Как отмечалось выше, инструменты Gitops, такие как CD Argo, непрерывно сравнивают «живое состояние с желаемым целевым состоянием», автоматически исправляя любой дрейф. Например, если кто -то вручную изменяет развертывание, CD Argo будет помечать его «Outofsync» и сможет отказаться или обновить его в соответствии с GIT, обеспечивая безопасность и согласованность.
Контейнеры и оркестровая также позволяют легко включить современные стратегии развертывания. CI/CD трубопроводы могут создавать новое изображение контейнера, подтолкнуть его к реестру, а затем запускать обновления kubernetes или развертывания канарейки. Сетки обслуживания и операторы могут автоматизировать обеспечение базы данных, хранение и многое другое. На практике многие предприятия управляют кластерами Kubernetes на публичных облаках или в центре, причем инструменты IAC создают базовые узлы и сеть. Результатом является повторяемая, упругая платформа, где команды разработчиков могут надежно предоставлять услуги.
Наблюдение и мониторинг
Сильная практика DevOps требует не только автоматизации, но и понимания. Предприятия должны постоянно контролироваться. Популярные стеки с открытым исходным кодом включают Prometheus для коллекции метрик и Grafana для приборной панели. Прометея скрещивают метрики (приложение, инфраструктура, обычая) и Графана позволяют командам визуализировать их в режиме реального времени. Централизованная регистрация (EFK/ELK) и распределенная трассировка (Jaeger, Opentelemetry) добавляют дополнительную наблюдаемость.
Это имеет значение, потому что без него команды «не могут определить гранулированные метрики» и тратить время, преследующее неизвестные неудачи. Высокопроизводительные организации DevOps инвестируют в наблюдаемость полного стека, поэтому проблемы обнаруживаются на ранней стадии. Оповещения о ключевых метрик (задержка, частота ошибок, продолжительность трубопровода) и резюме на панели панели помогают командам OPS уйти, когда что -то пойдет не так. Фактически, SolarWinds сообщает, что предприятия в настоящее время используют платформы наблюдаемости, чтобы «исследовать основную причину проблем, которые негативно влияют на предприятия». Изучая каждый уровень (от аппаратного кода до кода приложения), команды получают потенциалы «автономных операций» с помощью ИИ-управляемых.
Ключевые инструменты здесь включают Prometheus/Grafana для метрик, Alertmanager или Grafana Alerts для уведомлений, а также централизованное управление журналами, привязанное к информационным панели. Многие команды также используют трассировку для микросервисов. Результат: когда трубопроводы сбой или приложения сбой, богатая телеметрия избегает догадков. Наблюдение закрывает цикл-включает обратную связь, управляемую данными для улучшения процессов CI/CD и ускорить среднее время к переходу.
Заключение
Enterprise DevOps не должны быть источником разочарования. Благодаря консолидации инструментов, кодификации инфраструктуры и автоматизации трубопроводов, команды могут переехать из хаоса для контроля. Ключевые практики включают в себя принятие Gitops для инфраструктуры, строительство надежного CI/CD с автоматическим тестированием и выполнение рабочих нагрузок в оркестренных контейнерах. Наблюдение и мониторинг затем обеспечивают обратную связь и ограждения. В результате организации могут достичь быстрой, надежной доставки-например, многочисленных ежедневных развертываний в стиле Netflix или выпуски BT-10 минут вместо громоздких, подверженных ошибкам процессов. Короче говоря, Modern DevOps - это превращение сложности в оптимизированные, повторяемые рабочие процессы. Учившись на отраслевых примерах и используя правильные инструменты, любое предприятие может оптимизировать свой конвейер программного обеспечения и восстановить контроль над жизненным циклом программного обеспечения.
Оригинал
🔥 Популярное на этой неделе
-
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г.
⭐ Самое популярное
-
4 признака того, что ваш Instagram взломали (и что делать)
16 ноября 2022 г. -
Предстоящие эксклюзивы для PS5 — график выхода подтвержденных игр
24 октября 2023 г. -
Как подключить беспроводную клавиатуру Apple к Windows 10
18 апреля 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
Categories
- Технологии и IT (25400)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (270)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)
