
Альтернативы DataFrame DataFrame на поляры: встречайте Elusion v4.0.0
13 августа 2025 г.В экосистеме ржавчины наблюдается огромный рост библиотек обработки данных, причем поляры ведут заряд как яростно быструю библиотеку данных.
Тем не менее, появился новый соперник, который использует принципиально иной подход к разработке и анализу данных:УхладкаПолем
В то время как Polars фокусируется на чистой производительности и эффективности памяти с помощью своего столбчатого двигателя на основе стрелков Apache, Elusion позиционирует себя как равную, посвященную производительности и эффективности памяти, а также с помощью Appache Arrow и Freabusion, а также комплексной платформы для технических данных, которая приоритет гибкости, простоте использования и интеграции наряду с высокой производительностью.
Философия архитектуры: разные подходы к одинаковым целям
Поляры: Первый дизайн
Поляры написаны с нуля в ржавчине, разработанной близко к машине и без внешних зависимостей. Он основан на модели памяти Apache Arrow, обеспечивая очень эффективные конструкции столбцов данных и фокусируется на:
Ультрастрабильное выполнение запросов с помощью SIMD Оптимизации, эффективная память.
Элазия: гибкость-первый дизайн
Элазия использует другой подход, определяя приоритет опыта разработчика и интеграции:
- Основная философия:"Элайда хочет, чтобы ты был тобой!"
В отличие от традиционных библиотек данных, которые обеспечивают конкретные закономерности, Elusion предлагает гибкость в построении запросов без применения определенных закономерностей или цепочек. Вы можете построить свои запросы в любой последовательности, которая имеет смысл для вас, написание функций в любом порядке, а улалование обеспечивает последовательные результаты независимо от порядка вызова функции.
Загрузка файлов в DataFrames:
Регулярная загрузка: ~ 4,95 секунды для сложных запросов на 900 тыс.
CustomDataFrame::new()
Потоковая загрузка: ~ 3,62 секунды для тех же операций
CustomDataFrame::new_with_stream()
Повышение производительности: на 26,9% быстрее при потоковом подходе
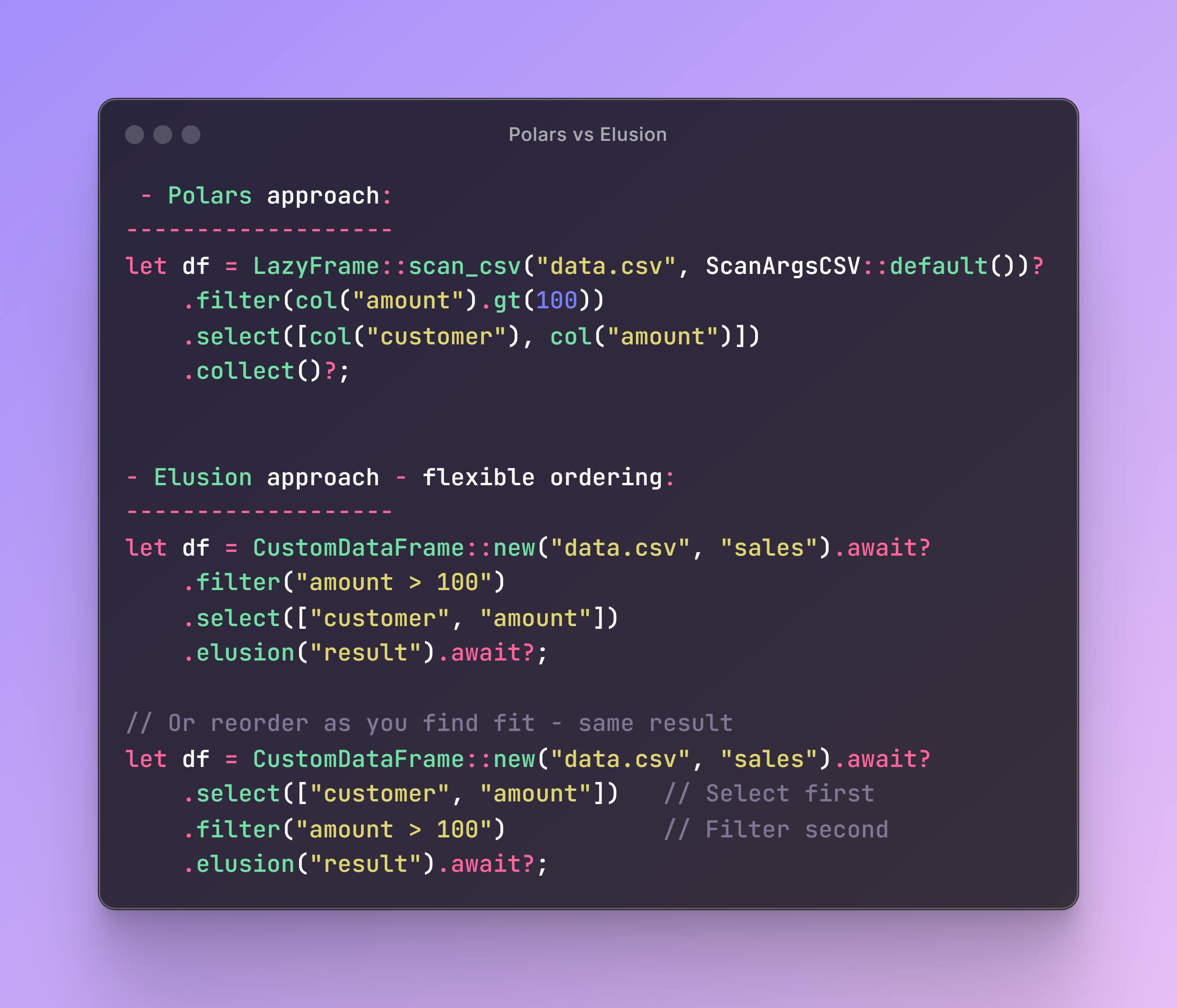
- Подход Polars:
let df = LazyFrame::scan_csv("data.csv", ScanArgsCSV::default())?
.filter(col("amount").gt(100))
.select([col("customer"), col("amount")])
.collect()?;
- Подход к уравнению - Гибкий заказ:
let df = CustomDataFrame::new("data.csv", "sales").await?
.filter("amount > 100")
.select(["customer", "amount"])
.elusion("result").await?;
// Or reorder as you find fit - same result
let df = CustomDataFrame::new("data.csv", "sales").await?
.select(["customer", "amount"]) // Select first
.filter("amount > 100") // Filter second
.elusion("result").await?;
Polars Базовая загрузка файлов:
let df = LazyFrame::scan_csv("data.csv", ScanArgsCSV::default())?
.collect()?;
// Parquet with options
let df = LazyFrame::scan_parquet("data.parquet", ScanArgsParquet::default())?
.collect()?;
Нагрузка данных по уплавке - всеобъемлющие источники:
use elusion::prelude::*;
Локальные файлы с автоматическим признанием
let df = CustomDataFrame::new("data.csv", "sales").await?;
let df = CustomDataFrame::new("data.xlsx", "sales").await?; // Excel support
let df = CustomDataFrame::new("data.parquet", "sales").await?;
Потоковая передача для больших файлов (в настоящее время поддерживает только файлы .csv)
let df = CustomDataFrame::new_with_stream("large_data.csv", "sales").await?;
Загрузите все папки
let df = CustomDataFrame::load_folder(
"/path/to/folder",
Some(vec!["csv", "xlsx"]), // Filter file types or `None` for all types
"combined_data"
).await?;
Azure Blob Blob Storage (в настоящее время поддерживает файлы CSV и JSON)
let df = CustomDataFrame::from_azure_with_sas_token(
"https://account.blob.core.windows.net/container",
"sas_token",
Some("folder/file.csv"), //or keep `None` to take everything from folder
"azure_data"
).await?;
SharePoint
let df = CustomDataFrame::load_from_sharepoint(
"tenant-id",
"client-id",
"https://company.sharepoint.com/sites/Site",
"Documents/data.xlsx",
"sharepoint_data"
).await?;
REST API в DataFrame
let api = ElusionApi::new();
api.from_api_with_headers(
"https://api.example.com/data",
headers,
"/path/to/output.json"
).await?;
let df = CustomDataFrame::new("/path/to/output.json", "api_data").await?;
Соединения базы данных
let postgres_df = CustomDataFrame::from_postgres(&conn, query, "pg_data").await?;
let mysql_df = CustomDataFrame::from_mysql(&conn, query, "mysql_data").await?;
Поляры: структурированный подход
Поляры требуют логического упорядочения
let result = df
.lazy()
.filter(col("amount").gt(100))
.group_by([col("category")])
.agg([col("amount").sum().alias("total")])
.sort("total", SortMultipleOptions::default())
.collect()?;
Элазия: гибкость любого порядка
Все это дает один и тот же результат:
Традиционный заказ:
let result1 = df
.select(["category", "amount"])
.filter("amount > 100")
.agg(["SUM(amount) as total"])
.group_by(["category"])
.order_by(["total"], ["DESC"])
.elusion("result").await?;
Фильтр первым
let result2 = df
.filter("amount > 100")
.agg(["SUM(amount) as total"])
.select(["category", "amount"])
.group_by(["category"])
.order_by(["total"], ["DESC"])
.elusion("result").await?;
Агрегация первой
let result3 = df
.agg(["SUM(amount) as total"])
.filter("amount > 100")
.group_by(["category"])
.select(["category", "amount"])
.order_by(["total"], ["DESC"])
.elusion("result").await?;
Все дают идентичные результаты!
Усовершенствованные функции: где сияет улавка
- Встроенная визуализация и отчет
let plots = [
(&line_plot, "Sales Timeline"),
(&bar_chart, "Category Performance"),
(&histogram, "Distribution Analysis"),
];
let tables = [
(&summary_table, "Summary Stats"),
(&detail_table, "Transaction Details")
];
CustomDataFrame::create_report(
Some(&plots),
Some(&tables),
"Sales Analysis Dashboard",
"dashboard.html",
Some(layout_config),
Some(table_options)
).await?;
- Автоматизированное расписание расписания трубопроводов
let scheduler = PipelineScheduler::new("5min", || async {
// Load from Azure
let df = CustomDataFrame::from_azure_with_sas_token(
azure_url, sas_token, Some("folder/"), "raw_data"
).await?;
// Process data
let processed = df
.select(["date", "amount", "category"])
.agg(["SUM(amount) as total", "COUNT(*) as transactions"])
.group_by(["date", "category"])
.order_by(["date"], ["ASC"])
.elusion("processed").await?;
// Write results
processed.write_to_parquet(
"overwrite",
"output/processed_data.parquet",
None
).await?;
Ok(())
}).await?;
Усовершенствованная обработка JSON может обрабатывать сложные структуры JSON с массивами и объектами
let df = CustomDataFrame::new("complex_data.json", "json_data").await?;
Если в ваших файлах есть поля JSON/столбцы, вы можете их взорвать:
- Извлеките простые поля JSON:
let simple = df.json([
"metadata.'$timestamp' AS event_time",
"metadata.'$user_id' AS user",
"data.'$amount' AS transaction_amount"
]);
- Выдержка из массивов JSON:
let complex = df.json_array([
"events.'$value:id=purchase' AS purchase_amount",
"events.'$timestamp:id=login' AS login_time",
"events.'$status:type=payment' AS payment_status"
]);
Когда выбирать, что
- Выберите Polars, когда: Чистая производительность - это основной приоритет, который вы предпочитаете структурированные, оптимизированные шаблоны запросов. Эффективность памяти имеет решающее значение, вам нужны минимальные зависимости
- Выберите Elusion, когда: вам нужна гибкость интеграции (облачное хранилище, API, базы данных). Опыт разработчика и гибкость запроса, которые вы хотите, вам нужны встроенная визуализация и отчет
Установка и начало работы
- Поляр
[dependencies]
polars = { version = "0.50.0", features = ["lazy"] }
- Элазия [зависимости]
elusion = "4.0.0"
tokio = { version = "1.45.0", features = ["rt-multi-thread"] }
- Элазия с конкретными особенностями
elusion = { version = "4.0.0", features = ["dashboard", "azure", "postgres"] }
Требование версии ржавчины:
Polars: >= 1.80
Elusion: >= 1.81
Пример реального мира: Анализ данных продаж. Реализация Polars:
use polars::prelude::*;
let df = LazyFrame::scan_csv("sales.csv", ScanArgsCSV::default())?
.filter(col("amount").gt(100))
.group_by([col("category")])
.agg([
col("amount").sum().alias("total_sales"),
col("amount").mean().alias("avg_sale"),
col("customer_id").n_unique().alias("unique_customers")
])
.sort("total_sales", SortMultipleOptions::default().with_order_descending(true))
.collect()?;
println!("{}", df);
Реализация Elusion: Используйте Elusion :: Prelude ::*;
#[tokio::main]
async fn main() -> ElusionResult<()> {
// Load data (flexible source)
let df = CustomDataFrame::new("sales.csv", "sales").await?;
// Build query in any order that makes sense to you
let analysis = df
.filter("amount > 100")
.agg([
"SUM(amount) as total_sales",
"AVG(amount) as avg_sale",
"COUNT(DISTINCT customer_id) as unique_customers"
])
.group_by(["category"])
.order_by(["total_sales"], ["DESC"])
.elusion("sales_analysis").await?;
// If you like to display result
analysis.display().await?;
// Create visualization
let bar_chart = analysis.plot_bar(
"category",
"total_sales",
Some("Sales by Category")
).await?;
// Generate report
CustomDataFrame::create_report(
Some(&[(&bar_chart, "Sales Performance")]),
Some(&[(&analysis, "Summary Table")]),
"Sales Analysis Report",
"sales_report.html",
None,
None
).await?;
Ok(())
}
Заключение
Elusion v4.0.0 представляет собой сдвиг парадигмы в библиотеках DataFrame, определяющий приоритет опыта разработчиков, гибкость интеграции и комплексные возможности для разработки данных. Выбор между полярами и уравнением зависит от ваших приоритетов:
Для необработанных вычислительных характеристик и эффективности памяти: поляры для комплексной разработки данных с гибкой разработкой: улавка
Строительство запросов «любого порядка» Elusion, обширные возможности интеграции, встроенная визуализация и автоматическое планирование делают его особенно привлекательным для команд, которые должны работать с различными источниками данных и хотят более интуитивно понятный опыт разработки. Обе библиотеки демонстрируют силу ржавчины в пространстве обработки данных, предлагая разработчикам высокопроизводительные альтернативы традиционным решениям на основе Python. Экосистема Rust DataFrame процветает, и наличие нескольких подходов гарантирует, что различные варианты использования и предпочтения хорошо обслуживаются.
Попробуйте Elusion v4.0.0 сегодня:
cargo add elusion@4.0.0
Для получения дополнительной информации и примеров посетите репозиторий Elusion Github:Управление репозиторияи присоединиться к растущему сообществу инженеров Rust Data, которые обнаруживают гибкость и мощность операций DataFrame любого порядка.
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27294)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)