

Сохранение конфиденциальности клиентов: интеграция дифференциальной конфиденциальности с универсальным набором данных (VDK)
15 декабря 2023 г.Введение
В современном мире, управляемом данными, где корпорации собирают и используют огромные объемы личной информации, важность конфиденциальности клиентов не может быть превышена. завышено. Сохранение конфиденциальности клиентов является не только юридическим требованием, но и фундаментальным этическим обязательством. n n Метод обмена данными, который описывает закономерности в наборе данных, скрывая при этом личную информацию, называется дифференциальной конфиденциальностью. Например, различные организации могут публиковать статистическую или демографическую информацию, но из-за различий в конфиденциальности трудно определить точный вклад того или иного человека. Идея заключается в том, что независимо от того, был ли определенный фрагмент данных включен в набор данных или нет, исследователь все равно получит тот же ответ на запрос. Если специалист по данным не может идентифицировать конкретного человека, использующего данные, то система имеет дифференциальную конфиденциальность. n n В этой статье мы узнаем больше о дифференциальной конфиденциальности и о том, как защитить конфиденциальность клиентов путем интеграции дифференциальной конфиденциальности с Versatile Data Kit (VDK). ).
Понимание необходимости дифференцированной конфиденциальности
В современном цифровом мире нам нужно больше данных, чем когда-либо, чтобы принимать и проверять бизнес-решения. Без данных ни один бизнес не сможет процветать в цифровой среде; Используя данные, мы можем обучать модели машинного обучения, прогнозировать выбор пользователей и даже показывать рекламу. Пользователи не чувствуют себя в безопасности из-за доступа предприятий к их личным данным. Чтобы собирать огромные объемы данных от пользователей, нам необходимо обеспечить лучшие гарантии конфиденциальности и соблюдать стандарты правоохранительных органов (например, HIPAA, GDPR), чтобы гарантировать пользователям, что их данные будут защищены.
n Когда люди пытаются скрыть или замаскировать личную информацию (PII), они могут непреднамеренно оставить в данных другие идентифицирующие элементы. Эти дополнительные элементы известны как квазиидентификаторы. Таким образом, простого сокрытия личных данных может быть недостаточно для защиты конфиденциальности, если эти квазиидентификаторы (см. изображение ниже) все еще можно использовать для идентификации людей.
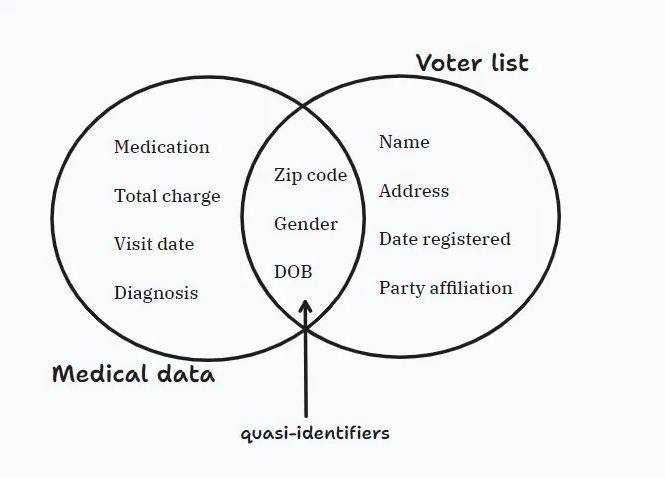
Для решения этой проблемы лучшим решением станет Дифференциальная конфиденциальность. Это математическая основа, которая обеспечивает надежные гарантии конфиденциальности личных данных, даже если они интегрированы в обширные наборы данных или объединены с другими источниками данных. Этот метод включает внесение случайного шума в данные перед анализом или обменом, что значительно усложняет потенциальным злоумышленникам определение конкретных данных человека. Шум стратегически учитывается для поддержания статистической точности, гарантируя, что результаты анализа останутся значимыми и ценными, несмотря на внесенный шум.
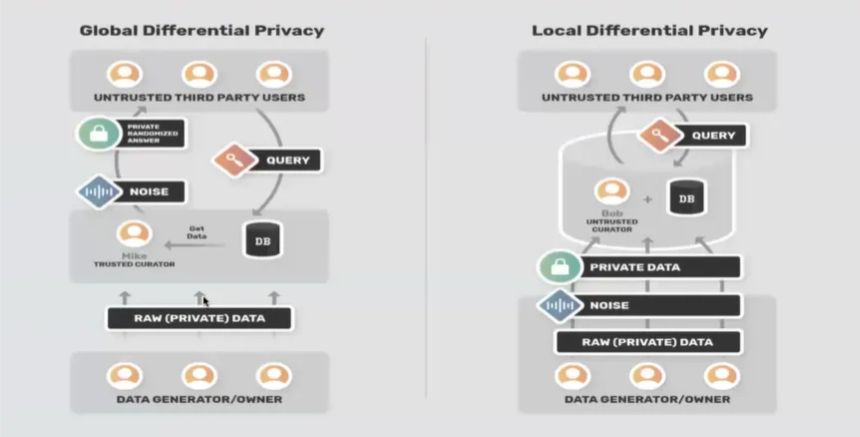
n В дифференциальной конфиденциальности участвуют три основных участника: куратор, владелец и аналитик данных. Как вы можете видеть на изображении ниже, при глобальной дифференциальной конфиденциальности мы можем доверять куратору, но не аналитику, тогда как при локальной дифференциальной конфиденциальности мы никому не доверяем.
Методы реализации дифференциальной конфиденциальности
- Случайный ответ: Он используется, когда тип данных, который мы пытаемся запутать, является логическим. Когда с использованием этого подхода выполняется запрос о логическом атрибуте (например, есть ли у человека заданная характеристика), результат рандомизируется, чтобы внести неопределенность.
Проверьте здесь или посмотрите пример ниже:
class DifferentialPrivateRandomResponse:
def __init__(self, random_response_frequency: int):
self._random_response_frequency = random_response_frequency
def privatize(self, value: bool):
# first coin flip
if np.random.randint(0, self._random_response_frequency) == 0:
# answer truthfully
return value
else:
# answer randomly (second coin flip)
return np.random.randint(0, 2) == 0
* Унарное кодирование. Оно используется для добавления шума, когда мы пытаемся добавить конфиденциальность в типы данных типа Enum. Унарное кодирование – это способ представления категориальных данных в векторе.
Проверьте здесь или посмотрите пример ниже:
def _perturb(self, encoded_response: List[int]) -> List[int]:
return [self._perturb_bit(b) for b in encoded_response]
def _perturb_bit(self, bit: int) -> int:
sample = np.random.random()
if bit == 1:
if sample <= self._p:
return 1
else:
return 0
elif bit == 0:
if sample <= self._q:
return 1
else:
return 0
Реализация дифференциальной конфиденциальности с помощью VDK
Усложнение управления данными становится все более сложным, поэтому универсальный набор данных с открытым исходным кодом (VDK) позволяет организациям обрабатывать и защищать конфиденциальные данные. Используя возможности VDK, мы можем решить проблемы внедрения дифференциальной конфиденциальности. Узнайте больше о Versatile Data Kit здесь! n n Мы подробно рассмотрим каждый шаг, необходимый для реализации дифференциальной конфиденциальности. Мы будем работать с набором данных о пациентах, обычно используемым исследователями в качестве примера, чтобы понять реализацию дифференциальной конфиденциальности с использованием VDK. n n Прием данных: VDK предоставляет понятный интерфейс для приема.
Включение дифференциальной конфиденциальности:
VDK является модульным и легко расширяемым, в нем реализована концепция плагинов, которые можно устанавливать, как и любые другие пакеты Python. Как только они будут установлены, мы сможем подключить их к заданию VDK, быстро изменив конфигурацию. Чтобы обеспечить дифференциальную конфиденциальность, нам необходимо перехватывать данные на этапе предварительного приема, чтобы мы могли добавить шум перед их синхронизацией. Плагины VDK могут перехватывать данные на разных этапах жизненного цикла потоковой передачи данных. n n Плагин случайного ответа: Давайте посмотрим пример того, как мы можем настроить и добавить шум случайного ответа к логическому типу данных. Рассмотрим исследование, проводимое некоторыми исследователями с целью определить влияние курения на рак. Они должны изучать данные различных пациентов, а также защищать конфиденциальность пациентов за счет использования дифференцированной конфиденциальности и VDK. Проверьте код здесь. n n Чтобы установить и настроить наш новый плагин Random Response, нам нужно запустить следующее:
pip install vdk-local-differential-privacy
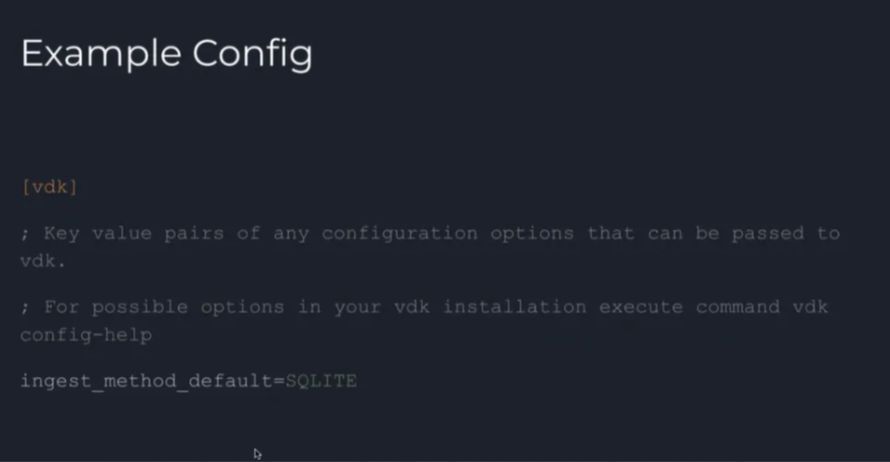
После установки плагина Random Response нам необходимо обновить файл конфигурации:
# update config
[vdk]
ingest_method_default=SQLITE
#add preprocessing step
ingest_payload_preprocess_sequence=random_response_differential_privacy
#set property specific to this plugin
differential_privacy_randomized_response_fields='{"patient_details": ["is_smoker"]}' )
Следуйте приведенному выше коду и посмотрите, как мы можем добавить этап предварительной обработки в файл конфигурации. На следующем шаге мы устанавливаем свойства, специфичные для этого плагина, и поля, которые мы хотим рандомизировать или добавить шум, расположены в таблице « Patient_details», а имя столбца «is_smoke». ».
from vdk.api.job_input import IJobInput
def run(job_input: IJobInput):
#60 people who are not smokers
for _ in range(60):
obj = dict(str_key="str", is_smoker=False)
#setup the configuration
job_input.send_object_for_ingestion(
payload=obj, destination_table="patient_details", method="memory"
)
Как вы можете видеть в приведенном выше сценарии, мы взяли 60 пациентов, которые не курят, и сохранили всю их информацию в базе данных. Он генерирует словарь и отправляет его для приема в таблицу данных с именем «пациент_детали» с использованием метода «память». Поскольку в наборе данных не все курят (is_smoker=False), в наборе данных всегда присутствует одинаковое количество шума.
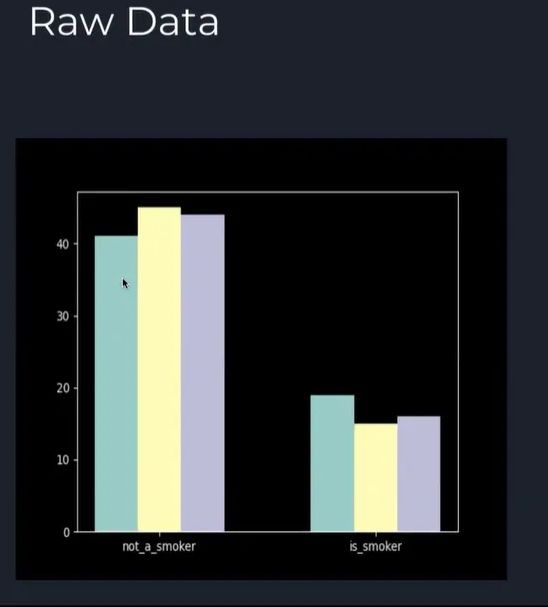
Как вы можете видеть на гистограмме зашумленных и рандомизированных данных, около 45 некурящих и около 15 курильщиков. n n Мы используем плагин случайного ответа, поэтому истинное значение может быть сообщено с определенной вероятностью, тогда как ложное значение может быть сообщено с дополнительной вероятностью.
n Понятные данные: VDK помогает создавать зашумленные данные. Мы можем перейти от зашумленных данных к фактическому распределению до того, как к данным будет добавлен шум. Переход от зашумленных данных к понятным требует управления и фильтрации шума.
Для этого необходимо учитывать несколько моментов:
<блок-цитата>- Примерно половина данных состоит из чистого шума. n – Около четверти данных составляют ответы «да», сгенерированные случайным шумом.
Чтобы определить количество реальных ответов «да» в данных, вы вычитаете сгенерированные шумом ответы «да» из общего количества ответов «да». Математически это выражается так:
<блок-цитата>реальное «да» = общее количество «да» — (1/4 x размер набора данных)
Поскольку половина данных была отброшена из-за шума, необходимо сделать поправку на эту потерю при оценке фактического количества реальных ответов «да». Удвоение количества реальных ответов «да» компенсирует исключение половины данных:
<блок-цитата>Фактическое количество реальных «да» = 2×настоящих «да»
Этот процесс помогает получить более точное представление об истинно положительных ответах в наборе данных, учитывая наличие шума и обеспечивая лучшее понимание основной информации.
n Сделав эти шаги, мы сможем получить реальное распространение. Проверьте правую гистограмму на изображении ниже: мы достигли числа 60, и вероятность погрешности очень мала или вообще отсутствует.
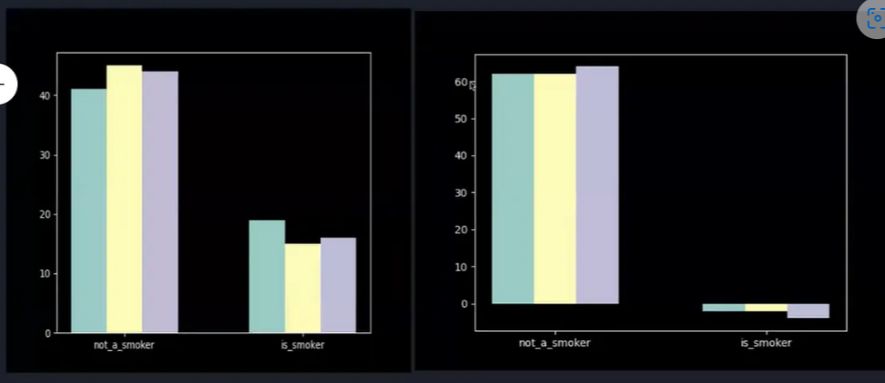
Это может помочь исследователю легко завершить исследование влияния курения на рак. Это также помогает сохранить конфиденциальность отдельных пользователей, поскольку только половина ответов в базе данных — это честные ответы, не порожденные шумом. Дополнительную информацию можно узнать здесь. n n Плагин унарного кодирования:
Похожий метод будет использоваться в качестве случайного ответа при реализации дифференциальной конфиденциальности с использованием плагина Unary Encoding VDK. n n Чтобы установить и настроить наш новый плагин Unary Encoding, нам нужно запустить следующее:
pip install vdk-local-differential-privacy
После установки плагина Unary Encoding нам необходимо обновить файл конфигурации:
# update config
[vdk]
ingest_method_default=SQLITE
#add preprocessing step
ingest_payload_preprocess_sequence=unary_encoding_differential_privacy
#set property specific to this plugin
differential_privacy_unary_encoding_fields='{"patient": {"blood": ["A","B","AB","O"]}}'
Следуйте приведенному выше коду и посмотрите, как мы можем добавить этап предварительной обработки в файл конфигурации. На следующем шаге мы устанавливаем свойства, специфичные для этого плагина «unary_encoding_dependent_privacy», а на следующем шаге мы хотим добавить унарную кодировку в таблицу «пациент» в столбце «кровь» с группами крови как Перечислимые значения.
from vdk.api.job_input import IJobInput
def run(job_input: IJobInput):
for _ in range(50):
obj = dict(str_key="str", blood_type="B")
job_input.send_object_for_ingestion(
payload=obj, destination_table="patient", method="memory"
)
В приведенном выше скрипте вы можете видеть, что у нас есть 50 пациентов с группой крови «В», и мы сохраняем их в базе данных. Реализация унарного кодирования с использованием подключаемого модуля Versatile Data Kit для реализации дифференциальной конфиденциальности в чем-то похожа на метод подключаемого модуля со случайным ответом.
n По сути, случайный ответ вводит случайность для защиты конфиденциальности статистических данных, тогда как унарное кодирование – это метод двоичного представления, обычно используемый для категориальных данных.
Заключение
Завершая эту статью о защите конфиденциальности потребителей с помощью дифференциальной конфиденциальности и универсального набора данных (VDK), мы подчеркиваем исключительную важность соблюдения этических норм в отношении данных. Для достижения баланса между конфиденциальностью и творчеством необходимы совместные усилия, и сочетание этих инструментов обеспечивает прочную основу для ответственного управления данными. В ходе переговоров в этом меняющемся мире организации должны проявлять открытость, адаптироваться к законодательству и отдавать приоритет конфиденциальности. n n Интеграция дифференциальной конфиденциальности и VDK не только защищает конфиденциальность клиентов, но и закладывает основу для надежного и ответственного цифрового будущего. VDK также работает над поддержкой дифференциальной конфиденциальности в SQL-запросах и глобальной дифференциальной конфиденциальности. n n Эта статья написана в соавторстве с Astrodevil и Пол Мерфи, объединив свой опыт, чтобы предоставить всесторонний взгляд на тему.
Дополнительные ресурсы
<блок-цитата>💡Проверьте репозиторий Versatile Data Kit на GitHub
💡Проверьте видеоруководство на YouTube
💡Чтобы узнать больше, ознакомьтесь с руководством по началу работы VDK
💡Проверьте файлы плагинов VDK
Также опубликовано здесь.
Оригинал
🔥 Популярное на этой неделе
-
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27156)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)