

Выбоины, трубопроводы и точность: детекторы бенчмаркинг -объектов для глобальной безопасности дорожного движения
13 августа 2025 г.Таблица ссылок
Аннотация и I. Введение
II Набор данных
Iii. Методы
IV Эксперименты
V. Результаты
VI Выводы и ссылки
Iii. Методы
Существует два основных класса детекторов объектов, которые последовательно хорошо работают на популярном наборе данных Microsoft Common Objects в контексте (MS Coco) [6]. В одностадийном обнаружении это YOLO [13], Retinanet [7] и в двухэтапных регионах, основанных на быстрой R-CNN [4] или маске R-CNN [8], широко используются. Маска R-CNN-это расширение более быстрого R-CNN с дополнительной ветвей предложения маски для сегментации.
YOLO имеет единую нейронную сеть, которая предсказывает ограничивающие ящики и вероятности класса непосредственно из полных изображений в одной оценке. Поскольку весь конвейер обнаружения представляет собой единую сеть, он может быть оптимизирован сквозняк непосредственно при производительности обнаружения.
Более быстрый R-CNN [4]-это подходы, основанные на регионе, которые предсказывают обнаружения на основе признаков из местного региона. Этот регион локализован с использованием сети предложений региона (RPN). Первая стадия сеть предназначена для предложения региона по функциям из костяка свертки, а второй этап - полностью подключенная сеть для классификации объектов и регрессии ограничивающей коробки.
А. Связанная костяка
Сеть магистралей представляет собой стандартные сверточные нейронные сети (CNN), используемые для извлечения визуальных функций высокого уровня со всего изображения. Особенности высокого уровня представлены в виде сверточной карты функций над изображением. Глубокие остаточные сети [9], такие как Resnet 50, Resnet 101, Resnext 101 и функция Pyramid Network (FPN) или комбинация Resnet и FPN, хорошо работают с большинством моделей обнаружения объектов, включая более быстрые R-CNN и Mask R-CNN.
Одноступенчатые сети, такие как Retinanet, также использовали остаточную сеть и основы FPN на основе FPN. Yolov5, с другой стороны, использовал неполную сеть поперечной сети (CSPNet) [16] для достижения высокого эталона на наборах данных MS Coco.
B. Один стадный детектор объектов
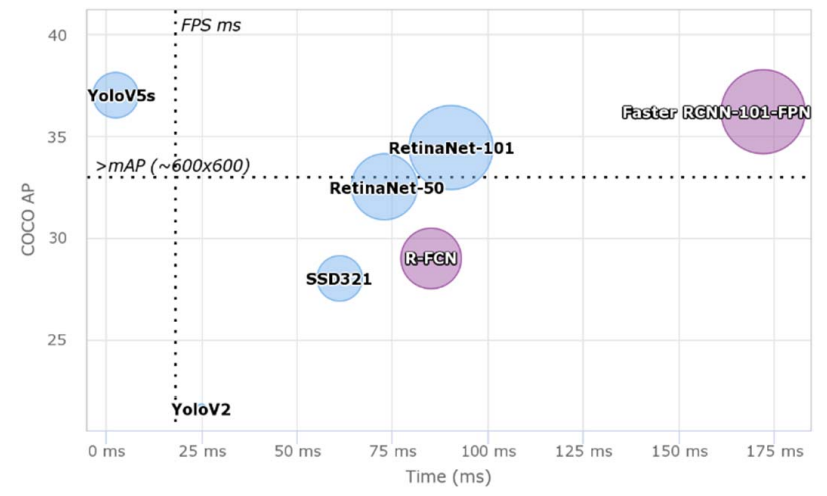
Yolo [13] и Retinanet [7] являются популярными моделями обнаружения объектов в одноэтапных объектах. Диаграммы точности, как правило, приводят двухэтапные детекторы объектов, тогда как одно стадии детекторы предпочтительнее для скорости оценки. Один стадии детектор имеет тенденцию иметь низкие вычислительные требования и может быть легко развернут на устройствах смартфонов.
Йоло
You Onlyly Look-Onke (YOLO) [13]-это унифицированный алгоритм обнаружения объектов в реальном времени, который переформулирует задачу обнаружения объекта к одной проблеме регрессии.
![Fig. 5. 1-stage You-Only-Look-Once (YOLO) detector [13]](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-kh132kf.png)
Yolo использует единую архитектуру нейронной сети для прогнозирования ограничивающих ящиков и вероятностей класса непосредственно из полных изображений. По сравнению с более быстрым R-CNN YOLO обеспечивает более быстрое обнаружение с компромиссом точности. Это было основной причиной его популярности и множественных расширений и адаптаций, таких как Yolov3 [13] и Yolov5 [15], вышли из него.
Yolov5 [15] включает в себя четыре различные модели, начиная от самых маленьких Yolo-V5 с 7,5 миллионами параметров (Plain 7 МБ и MS Coco, предварительно обученные 14 МБ) и 140 слоев до самого большого YOLO-V5X с 89 миллионами параметров и 284 слоя (простые 85 МБ и MS, предварительно обученные 170 мб). В подходе, рассмотренном в этой статье, мы экспериментировали со всеми 4 вариантами моделей Yolov5. Он использует двухэтапный детектор, который состоит из межпространственной частичной сети (CSPNet) [16], обученной MS Coco [6].
Каждое узкое место CSP состоит из двух сверточных слоев с фильтрами 1 × 1 и 3 × 3. Магистраль включает в себя сеть пространственной пирамиды (SSP) [17], которая обеспечивает динамический размер изображения ввода и является устойчивым к деформациям объектов.
C. Двухступенчатый детектор объектов
На основе региона CNN (R-CNN) служит классом модели обнаружения объектов, которая подпадает под двукратные детекторы. Более быстрый R-CNN-это регион, который предсказывает обнаружения на основе признаков из предлагаемой области.
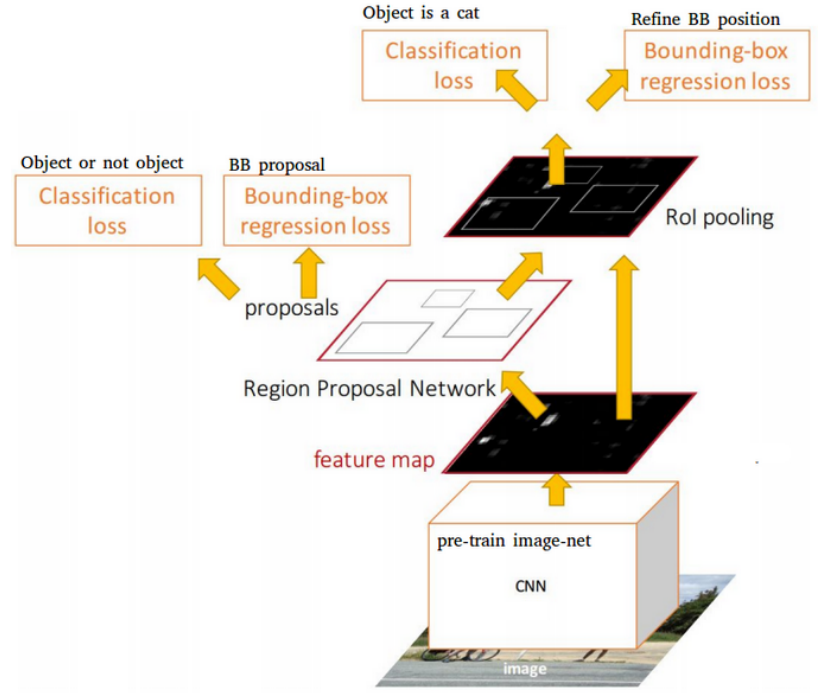
Быстрее r-cnn
Детекторы на основе региона, такие как более быстрые R-CNN [4], являются популярными двухэтапными детекторами. Первый этап генерирует редкий набор объектов -кандидатов, используя сеть объединения региона (RPN), основанный на общих картах функций, это классифицируется как передний план или фоновый класс. Размер каждого якоря настроен с использованием гиперпараметров. Затем предложения используются в области, представляющего интерес (объединение ROI) для создания карт субфувтура. Карты подфектуров преобразуются в 4096 размерных векторов и подаются вперед в полностью подключенные слои. Эти слои затем используются в качестве регрессионной сети для прогнозирования смещений ограничивающей коробки, причем классификационная сеть используется для прогнозирования метки класса каждого предложения ограничивающего бокса.
Функция Pyramid Network (FPN) [5] используется в качестве основы сети. FPN использует нисходящую архитектуру с боковыми соединениями для создания пирамиды в сети с одномасштабным входом. Более быстрые R-CNN с экстрактами FPN-обработки экстрактов ROI от разных уровней пирамиды признака в соответствии с их шкалой, но в остальном остальная часть подхода аналогична ванильному Resnet. Мы также используем resnext101 [20] с основной цепью извлечения функций FPN для извлечения функций.
IV Эксперименты
В этом разделе мы оцениваем одноэтапную сеть YOLO V5 [15] и более быстрой сети R-CNN [4] с различной предварительной обработкой, сетью магистралей, гиперпараметрической настройкой и стратегией обучения для достижения лучших результатов AVG F1. Мы не используем ансамблевой подход, учитывая, что он отлично подходит для соревнований, но редко работает хорошо при развертывании. В нашей основе и методах мы использовали Resnet 50, Resnet 101, Resnext 101 [9, 20] и Cspnet [16] для оценки, учитывая, что при обучении эти веса могут быть обрезки и сжаты для работы на небольших устройствах с незначительной деградацией в точности.
В нашем эксперименте мы начинаем с предварительной обработки данных, где мы использовали увеличение изображения, такие как изменение размера, ориентация и сегментация Deeplab V3+ [18], чтобы выделить поверхность дороги для оценки нижней течения.
Далее мы смотрим на обучение модели обнаружения для каждой страны и рассмотрим их результаты по представленной оценке F1. Мы также обучаем одну модель с данными для всех трех стран в качестве обобщенного подхода. Мы больше сосредоточены на обобщенном подходе с учетом темы этой работы, и задача [23] состоит в том, чтобы получить модель, которая может быть передана в другие страны.
Наконец, мы рассмотрим метод порога и ранжирования предложений, применяемый к результатам обнаружения по наборам данных. Это важно, поскольку вывод, который мы представляем в эту задачу, должен быть главными предложениями.
Основанная на Pytorch и Detectron2 [14] структура из Facebook AI Research (FAIR) использовалась для обучения и оценки более быстрых моделей R-CNN [4], в то время как внедрение Yolov5 на основе Pytorch использовалась в ультралитике для сравнения. Все эти реализации доступны в репозитории OpenSource GitHub для сообщества. Мы смогли настроить объекты загрузчика данных и Mapper для настройки кодовой базы для экспериментов. Обе эти кодовые базы поддерживают проект Tensorboard для отслеживания точности обучения и потери оптимизации в течение всего процесса обучения.
Эксперименты, зарегистрированные в различных таблицах, имеют описание модели с Epoch Runs и выбранной сетью костей в первом столбце. Гиперпараметры описаны во втором столбце. Средняя оценка F1 сообщается для набора данных Test 1 и Test 2 на основе того, как эксперимент, который мы проходили.
A. Предварительные обработки изображений
Мы рассматривали сегментацию как способ исключить фон и шум из изображения, чтобы мы могли анализировать функции только на дороге. Реализация Pytorch и Detectron2 [14] DeepLab V3+ [18] используется для контуров сегментации и обрезки изображений.
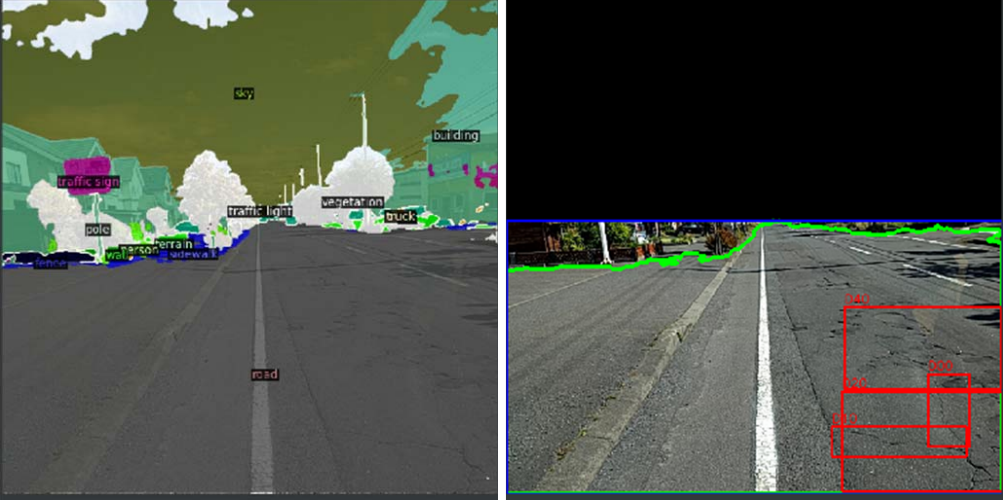
Мы использовали стандартную модель Deeplab V3+ [18], обученная набору данных семантической сегментации CityScape. Модель смогла достичь справедливой сегментации на большинстве дорог в Японии и чешском, в то время как дороги в Индии, которые имели гравий и грязь, как поверхность, она не выполняла хорошую работу по отделению дороги от окружающих поверхностей. Мы провели базовый анализ в Таблице II, чтобы проверить, предложила ли сегментация улучшение. Набор данных использовал аннотацию всех стран, чтобы обучить одну более быструю модель R-CNN [4].
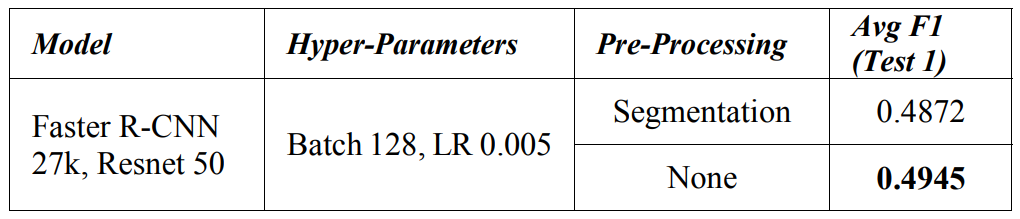
В наших экспериментах мы не наблюдали никакой выгоды на основе нашего подхода к сегментации. Похоже, что производительность модели ухудшается и может быть связана с сегментацией в наборе данных Индии. Мы продолжаем без сегментации для остальной части предварительной обработки набора данных.
B. Модель на страну
Мы обучались более быстрым моделям R-CNN [4], чтобы соответствовать данным каждой страны, чтобы достичь базовой линии. Ожидалось, что модель достигнет лучшей точности с тремя различными моделями, посвященными Чехию, Японии и Индии. Мы смотрим на сравнение этого подхода в таблице III.
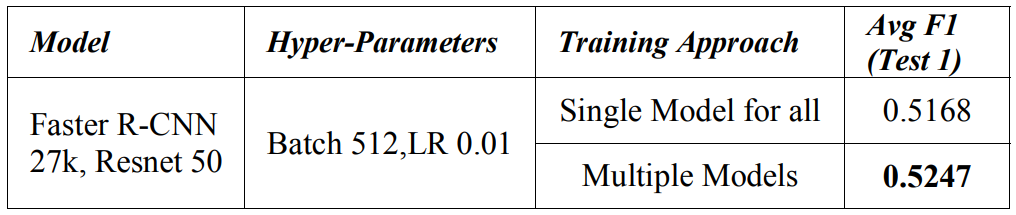
Мы получаем 1,5% преимущества в среднем показателе F1, когда мы тренируемся с базовым набором данных Train/Val (T). Тем не менее, мы используем подход к обучению одной модели по всему набору данных страны, учитывая преимущества развертывания и управления моделями.
C. Обобщенная модель
Мы пытаемся обобщить модель, обучая ее данным из всех стран набора данных. Здесь мы пытаемся сравнить двухэтапные модели обнаружения R-CNN [4] и одноэтапных Yolov5 [15]. В таблице IV мы четко отмечаем, что двухэтапный детектор превышает одноэтапный детектор.
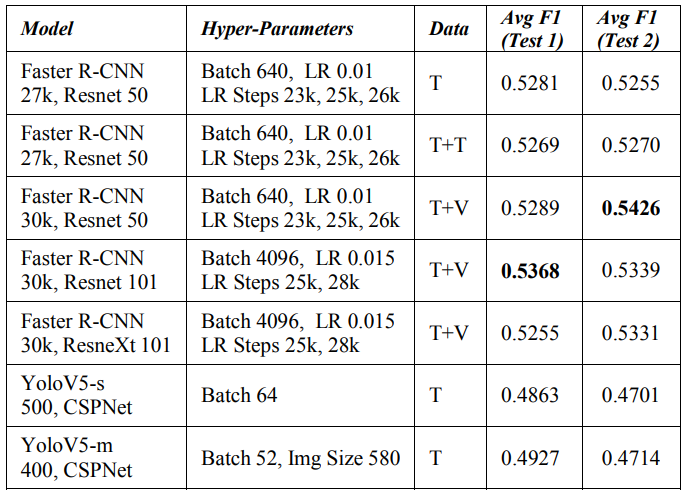
Данные, используемые при обучении этих моделей, состоит из базового разделения Train/Val (T), которое описано в разделе набора данных. Мы объединяем данные поезда и тестирование (T+T) для обучения для второго набора в таблице. После этого мы улучшаем это, составляя данные Train и Val (T+V) для обучения оставшихся более быстрых прогонов модели RCNN. Мы получаем ожидаемую выгоду от этой композиции данных.
Описание модели в таблице IV состоит из названия модели, эпохи и сети костей. Мы наблюдаем, что более быстрая модель R-CNN работает лучше, чем Yolov5. Гиперпараметры включают размер партии, скорость обучения (LR) и STEP -планировщик LR. Планировщик уменьшает LR на гамма -фактор 0,05 по этапам упомянутых значений эпохи. LR 0,01 и 0,015 хорошо показал пошаговый график (23K, 25K, 26K) и (25K, 28K) эпохи соответственно.
Мы показываем лучший показатель F1 в таблице IV для более быстрого R-CNN [4] на основе пакетного размера 640 и Resnet 50 [9] в тестировании 2 оценки, в то время как для теста 1 оценка оценки веб-сайта. Размер партии 4096 и Resnet 101 [9], по-видимому, работает хорошо.
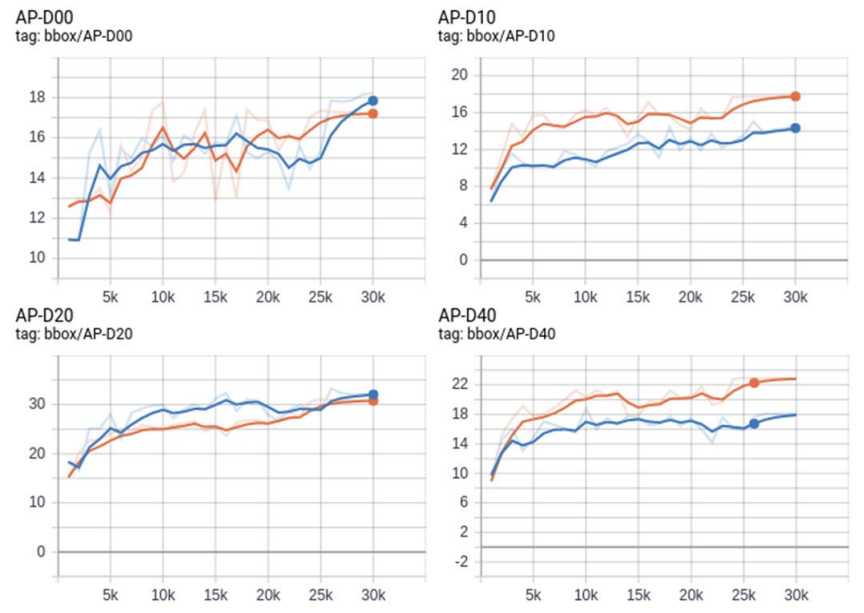
Мы смотрим на среднюю точность (iou = .50: .05: .95) на наборе данных 5% -ного тестирования (T) для мониторинга и отслеживания хода обучения моделей. На рис. 8 мы видим, что этот набор данных показывает высокую точность ограничивающей коробки при типе повреждения D20 в обеих моделях. Тем не менее, Resnet 50 с обученной моделью Batch 640, по -видимому, хорошо работает на типах повреждений D10 и D40, учитывая, что оба этих класса имеют относительно низкие аннотации.
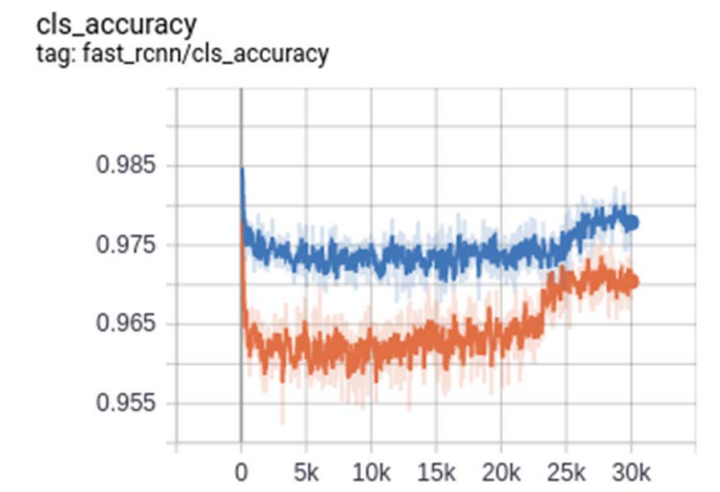
Когда мы смотрим на точность классификации повреждений на рис. 9, основная цепочка Resnet 101 [9] с большим размером партии демонстрирует высокую точность. Мы также видим, что планировщик Step Sepuler LR оказывает значительное влияние на точность около 23 тыс. Для меньшей сети и около 25 тыс. Для более крупной сети. Мы также видим, что модель перестает изучать около 30 тысяч эпохи, и для прекращения учебного процесса используется метод ранней остановки. Это останавливает модель от переживания данных обучения.
Обобщенный подход с низким размером сети может позволить модели перенести по странам и уменьшить накладные расходы на развертывание на основе целевых условий. Тем не менее, более крупная сеть имеет более высокую точность классификации.
D. Пост-обработка
На этом этапе мы смотрим на операции после обнаружения. Полученные ограничительные коробки фильтруются при 0,7 достоверного порога. Кроме того, обнаружения отсортируются по уверенности, и только в верхних 5 ограничивающих коробках отображаются для лучшего представления.
Авторы:
(1) Рахул Вишвакарма, Лаборатория Analytics & Solutions и Solutions, Hitachi America Ltd., Санта -Клара, Калифорния, США (Rahul.vishwakarma@hal.hitachi.com);
(2) Равигопал Веннелаканти, Лаборатория Analytics & Solutions, Hitachi America Ltd., Research & Development, Санта -Клара, Калифорния, США (Ravigopal.vennelakanti@hal.hitachi.com).
Эта статья есть
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27294)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)