

Происхождение интерфейса в объектно-ориентированном программировании
25 января 2023 г.Program to Interface — это фундаментальный принцип объектно-ориентированного программирования для создания программных приложений, которые можно легко и быстро изменять. Многие другие принципы и шаблоны проектирования основаны на принципе Program to Interface. Интерфейс в основном рассматривается как полезная функция для написания более удобного в сопровождении кода.
Однако концепция интерфейса возникла для решения другой проблемы. Автор Дон Бокс объяснил это в своей книге Essential COM в мельчайших подробностях. В этом посте мы постараемся понять суть этого.
<цитата>Объяснение приведено в контексте C++. Я не программист на С++. Я рассмотрел здесь высокоуровневое объяснение концепций. Если вас интересуют подробности, рекомендую обратиться к первой главе книги Essential COM
Что ведет к интерфейсу
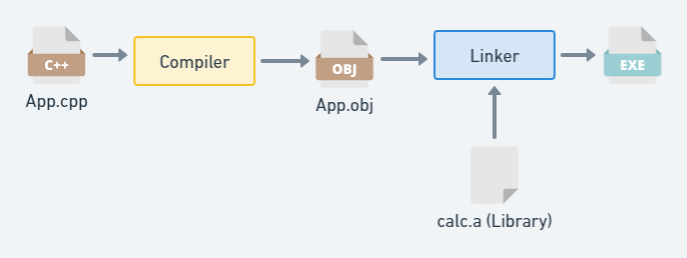
Прежде чем двигаться дальше, лучше быстро обновить роли компилятора и компоновщика в C++, как показано на рис. 1. Компилятор преобразует исходный код C++ в код сборки, а затем компоновщик объединяет весь код сборки и внешние библиотеки. в один исполняемый или библиотечный файл.
Общепринято абстрагировать общую логику или функциональность в библиотеки. Это делает систему модульной и позволяет легко использовать ее повторно.
Допустим, есть библиотека calclib, реализующая функции калькулятора. Ниже приведено подмножество функций:
// calc.h /////////////////////////////
class Calculator {
float pi;
public:
Calculator();
~Calculator(void);
float add(float a, float b); //add two numbers
} ;
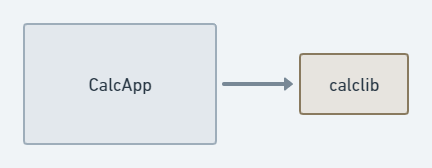
Эта библиотека затем используется в приложении CalcApp путем включения файла calc.h в исходный код CalcApp и предоставления calclib в компоновщик, который сгенерирует исполняемый файл CalcApp, содержащий calclib, как показано на рисунке 2.

Это называется Статическое связывание. Если есть какое-либо обновление для calclib, приложение CalcApp необходимо повторно скомпилировать и распространить. Любое изменение требует много усилий и времени. Это может быть проблемой для библиотек, которые используются во многих приложениях.
Эта проблема была решена с помощью Библиотеки динамической компоновки (DLL). Такие библиотеки загружаются во время выполнения, а фактическая проводка вызовов методов (на двоичном уровне) происходит при запуске приложения. При создании приложения компоновщик вставлял заглушки в исполняемый файл приложения, чтобы сделать это возможным. DLL позволяет просто распространить новую версию библиотеки, и приложение начнет работать с обновленной версией.
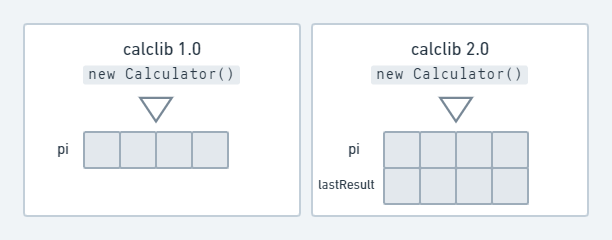
Допустим, в calclib 2.0 добавлена новая функция хранения последнего результата в памяти и возможность его извлечения.
// calc.h /////////////////////////////
class Calculator {
float pi;
float lastResult; //added in v2.0
public:
Calculator();
~Calculator(void);
float add(float a, float b); //add two numbers
float getLastResult(); //added in v2.0
} ;
Метод add сохраняет результат в lastResult
public float add(float a, float b) {
lastResult = a + b;
return lastResult;
}
В версии 2.0 в классе Calculator произошли три изменения:
- Новая закрытая переменная-член
lastResult - Новый общедоступный метод
getLastResult - Небольшие изменения в реализации метода
add. Изменение не влияет на ожидаемое поведение клиента.
Теоретически это должно работать, потому что ни одно из этих изменений ничего не нарушило для клиента. Но это не так! Вот почему это не работает:
* Когда создается объект класса Calculator, память выделяется на основе его закрытых членов, как показано на рисунке 4.
* Когда CalcApp был скомпилирован с calclib 1.0, компилятор сгенерировал код для выделения 4 байтов для одного закрытого члена при компиляции следующего кода:< /p>
Calculator *c = new Calculator();
* Теперь, когда CalcApp работает с calclib 2.0, объекту Calculator было бы выделено 4 байта для одного закрытого члена в соответствии с реализацией calclib 1.0. Но метод add в версии 2.0 пытается получить доступ lastResult для которого не выделена память< /сильный>. Так что это вызывает ошибку.
Это означает, что внесение изменений в реализацию класса, которые являются частными и не влияют на общедоступные функции, также может привести к поломке системы. Это противоречит принципу инкапсуляции в объектно-ориентированном программировании.
<цитата>Дон Бокс пишет, что C++ поддерживает синтаксическую инкапсуляцию, но
не имеет понятия о двоичной инкапсуляции.
Основная причина проблемы заключается в том, что выделение памяти для объекта определяется компилятором во время компиляции, и это жестко запрограммировано в двоичном выводе на основе размера объекта во время компиляции, но с DLL размер объекта может измениться, что приведет к ошибкам, если приложение запускается с версией, отличной от версии, с которой оно было скомпилировано.
Решение: отделить интерфейс от реализации и делегировать ответственность за создание объектов реализации. Разрешить клиенту обращаться только к интерфейсу, как показано на рис. 5.
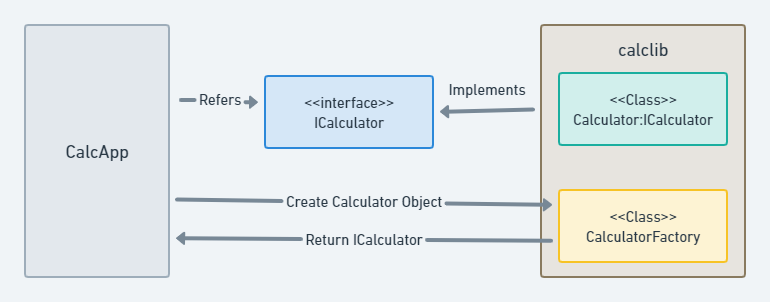
Как интерфейс решает проблему?
* Интерфейс имеет только публичное объявление метода. Нет закрытых членов или реализации метода.
* Factory используется для создания экземпляра реализации, поэтому реализация может изменяться без нарушения работы клиентов, например, добавление новой закрытой переменной-члена в calclib 2.0 не нарушит работу клиентов, скомпилированных с более ранней версией, поскольку Factory в версии 2 .0 выделит соответствующую память.
Это позволяет и клиенту, и библиотеке изменяться независимо друг от друга. Изменение сигнатуры общедоступного метода приведет к поломке клиентов. Вот почему интерфейс не модифицируется после использования, а создается версия для обеспечения обратной совместимости.
<цитата>Интерфейс на C++
Новые языки программирования, такие как Java, C# и т. д., имеют явную поддержку интерфейса. C++ не имеет встроенной поддержки интерфейса, поэтому для определения интерфейса используется абстрактный класс только с чисто виртуальными функциями.
Java (языки JVM) и C
Динамическая загрузка библиотек распространена во всех новых языках программирования, таких как Java, C# и т. д. Но они не сталкиваются с проблемой, которую мы только что обсуждали. Почему? Две причины:
* Все эти языки компилируются в промежуточный код (байт-код, IL-код), и этот промежуточный код преобразуется в машинный код средой выполнения (JVM, CLR) при запуске приложения — JIT-компиляция. Следовательно, практически процесс связывания (или его эквивалент) происходит при каждом выполнении. Любые изменения в библиотеке будут приняты средой выполнения во время выполнения.
* Управление памятью осуществляется средой выполнения (JVM, CLR). Среда выполнения может выделить соответствующую память в зависимости от последней реализации.
Надеюсь, вам было интересно. Поделитесь своим мнением в комментариях.
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
20 самых популярных статей TechRepublic в 2023 году
23 декабря 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27740)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Социальные медиа и интернет-культура (107)
- Экономика и финансы (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)