
Оптимизировать производительность TensorFlow с использованием профилировщика
13 августа 2025 г.Обзор контента
- Установите предпосылки Profiler и GPU
- Решить проблемы привилегий
- Профилирующие инструменты
- Обзор страница
- Входной конвейер анализатор
- Tensorflow Stats
- Просмотр просмотра
- Статистика ядра графического процессора
- Инструмент профиля памяти
- Просмотрщик капсул
- TF.Data Анализ узкого места
Это руководство демонстрирует, как использовать инструменты, доступные с Profiler TensorFlow для отслеживания производительности ваших моделей TensorFlow. Вы узнаете, как понять, как ваша модель работает на хосте (процессоре), устройстве (GPU) или в комбинации как хоста, так и устройства.
Профилирование помогает понять потребление аппаратного ресурса (время и память) различных операций TensorFlow (OPS) в вашей модели и разрешить узкие места производительности и, в конечном итоге, заставляют модель быстрее выполнять.
Это руководство проведет вас через то, как установить профилировщик, различные доступные инструменты, различные режимы того, как профилировщик собирает данные о производительности, и некоторые рекомендуемые лучшие практики для оптимизации производительности модели.
Если вы хотите профилировать производительность вашей модели на облачных TPU, обратитесь кОблачный гид TPUПолем
Установите предпосылки Profiler и GPU
Установите плагин Profiler для Tensorboard с PIP. Обратите внимание, что профилировщик требует последних версий Tensorflow и Tensorboard (> = 2,2).
pip install -U tensorboard_plugin_profile
Чтобы профилировать на графическом процессоре, вы должны:
- Совместите драйверы GPU NVIDIA® и требования CUDA® Toolkit, перечисленные наТребования к программному обеспечению для поддержки GPU TensorFlowПолем
- Убедитесь, чтоNVIDIA® CUDA® Профилирование интерфейс инструментов(Cupti) существует на пути:
/sbin/ldconfig -N -v $(sed 's/:/ /g' <<< $LD_LIBRARY_PATH) | \
grep libcupti
Если у вас нет Cupti на пути, приготовьте его каталог установки к$LD_LIBRARY_PATHпеременная среды запуска:
export LD_LIBRARY_PATH=/usr/local/cuda/extras/CUPTI/lib64:$LD_LIBRARY_PATH
Затем запуститеldconfigкоманда выше, чтобы убедиться, что библиотека Cupti найдена.
Решить проблемы привилегий
Когда вы запускаете профилирование с помощью Cuda® Toolkit в среде Docker или в Linux, вы можете столкнуться с проблемами, связанными с недостаточными привилегиями Cupti (CUPTI_ERROR_INSUFFICIENT_PRIVILEGES) Перейти кNvidia Developer DocsЧтобы узнать больше о том, как вы можете решить эти проблемы на Linux.
Чтобы решить проблемы привилегий Cupti в среде Docker, запустите
docker run option '--privileged=true'
Профилирующие инструменты
Получить доступ к профилировщику изПрофильВкладка в Tensorboard, которая появляется только после того, как вы забрали некоторые данные модели.
Примечание:Профилировщик требует доступа к Интернету для загрузки
Профилировщик имеет выбор инструментов, чтобы помочь с анализом производительности:
- Обзор страница
- Входной конвейер анализатор
- Tensorflow Stats
- Просмотр просмотра
- Статистика ядра графического процессора
- Инструмент профиля памяти
- Просмотрщик капсул
Обзор страница
Страница обзора содержит представление о том, как ваша модель выполнялась во время профиля. На странице показана агрегированная страница обзора для вашего хоста и всех устройств, а также некоторые рекомендации по повышению производительности вашей модели. Вы также можете выбрать отдельные хосты в выпадении хоста.
Страница обзора отображает данные следующим образом:
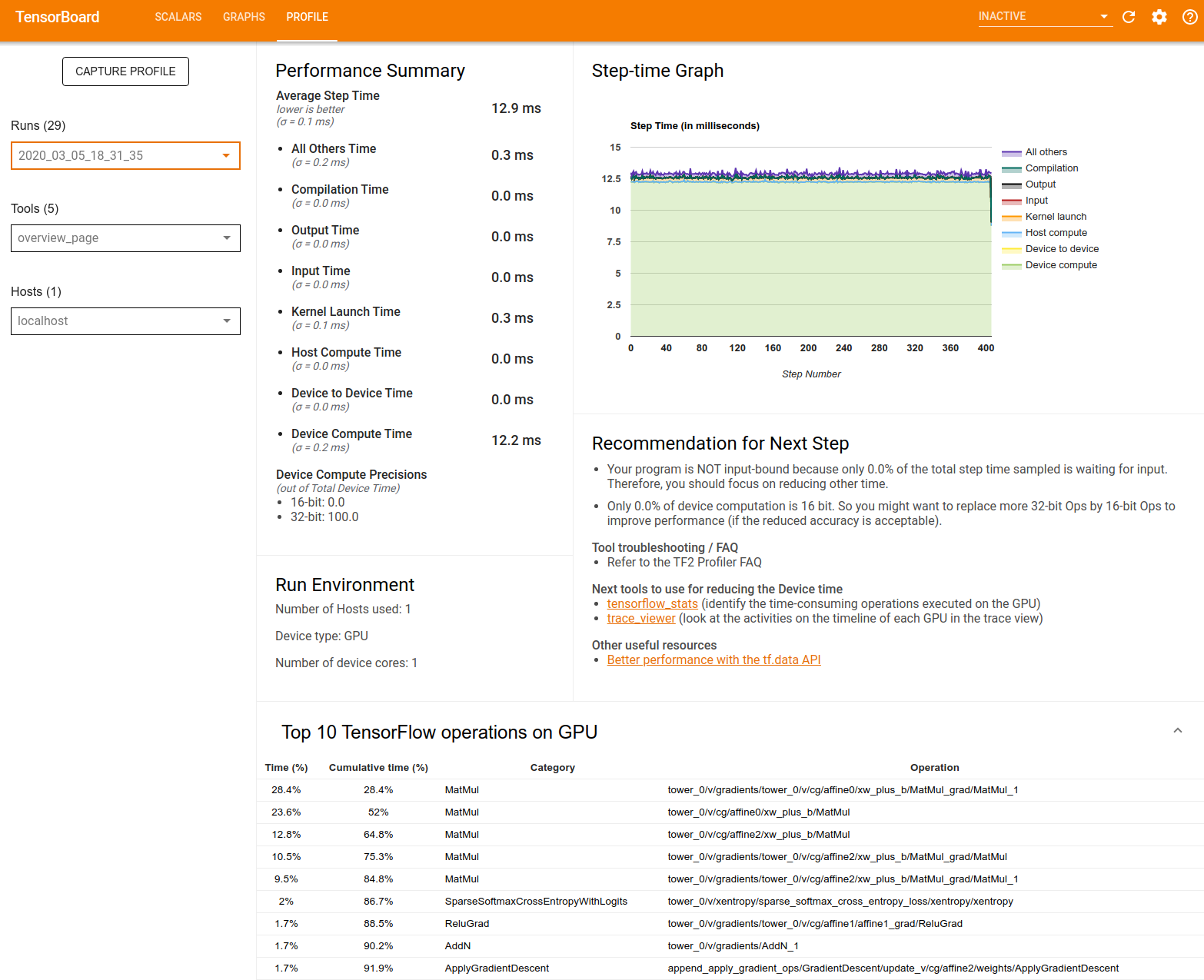
Резюме производительности: Отображает резюме высокого уровня вашей модели производительности. Резюме производительности имеет две части:
- Распад пошагового времени: разбивает среднее время шага в несколько категорий того, где тратится время:
- Компиляция: время, потраченное на компиляцию ядра.
- Ввод: время, потраченное на чтение входных данных.
- Вывод: время, потраченное на чтение выходных данных.
- Запуск ядра: время, проведенное хозяином на запуск ядра
- Хост вычислить время ..
- Устройство к устройству время связи.
- Время вычислить время.
- Все остальные, включая накладные расходы на Python.
- Устройство вычисления - сообщает о проценте времени вычисления устройств, в котором используются 16 и 32 -битные вычисления.
- Распад пошагового времени: разбивает среднее время шага в несколько категорий того, где тратится время:
Пошаговый график: Отображает график шага устройства (в миллисекундах) по всем отобранным шагам. Каждый шаг разбивается на несколько категорий (с разными цветами) того, где тратится время. Красная область соответствует части временного шага, когда устройства сидели на холостом ходу, ожидая входных данных с хоста. Зеленая область показывает, сколько времени на устройство на самом деле работает.
10 лучших операций TensorFlow на устройстве (например, графический процессор): Отображает Ops On-Device, которые работали дольше всего.
Каждая строка отображает время самостоятельно (как процент времени, затрачиваемого всеми операциями), кумулятивное время, категория и имя.
Запустить среду: Отображает резюме высокого уровня среды моделей, включая:
- Количество используемых хостов.
- Тип устройства (GPU/TPU).
- Количество ядер устройств.
Рекомендация для следующего шага: Отчеты, когда модель связана с входной границей, и рекомендует инструменты, которые вы можете использовать для поиска и разрешения узких мест производительности модели.
Входной конвейер анализатор
Когда программа TensorFlow считывает данные из файла, она начинается в верхней части графика TensorFlow в трубопроводной манере. Процесс считывания делится на несколько этапов обработки данных, подключенных последовательно, где выход одного этапа является входом для следующего. Эта система чтения данных называетсяВходной трубопроводПолем
Типичный трубопровод для чтения записей из файлов имеет следующие этапы:
- Чтение файлов.
- Предварительная обработка файла (необязательно).
- Передача файла с хоста на устройство.
Неэффективный входной трубопровод может сильно замедлить ваше применение. Приложение рассматриваетсявходной границыКогда он проводит значительную часть времени в входном трубопроводе. Используйте идеи, полученные из анализатора входного трубопровода, чтобы понять, где входной трубопровод неэффективен.
Анализатор входного трубопровода немедленно рассказывает, является ли ваша программа входной грани, и проведет вас через анализ устройства и хоста, чтобы отлаживать узкие места производительности на любом этапе в входном трубопроводе.
Проверьте руководство по производительности входного трубопровода для рекомендуемых лучших практик для оптимизации ваших конвейеров ввода данных.
Входной приборной панель
Чтобы открыть анализатор входного трубопровода, выберитеПрофиль, затем выберитеinput_pipeline_analyzerизИнструментыпадать.
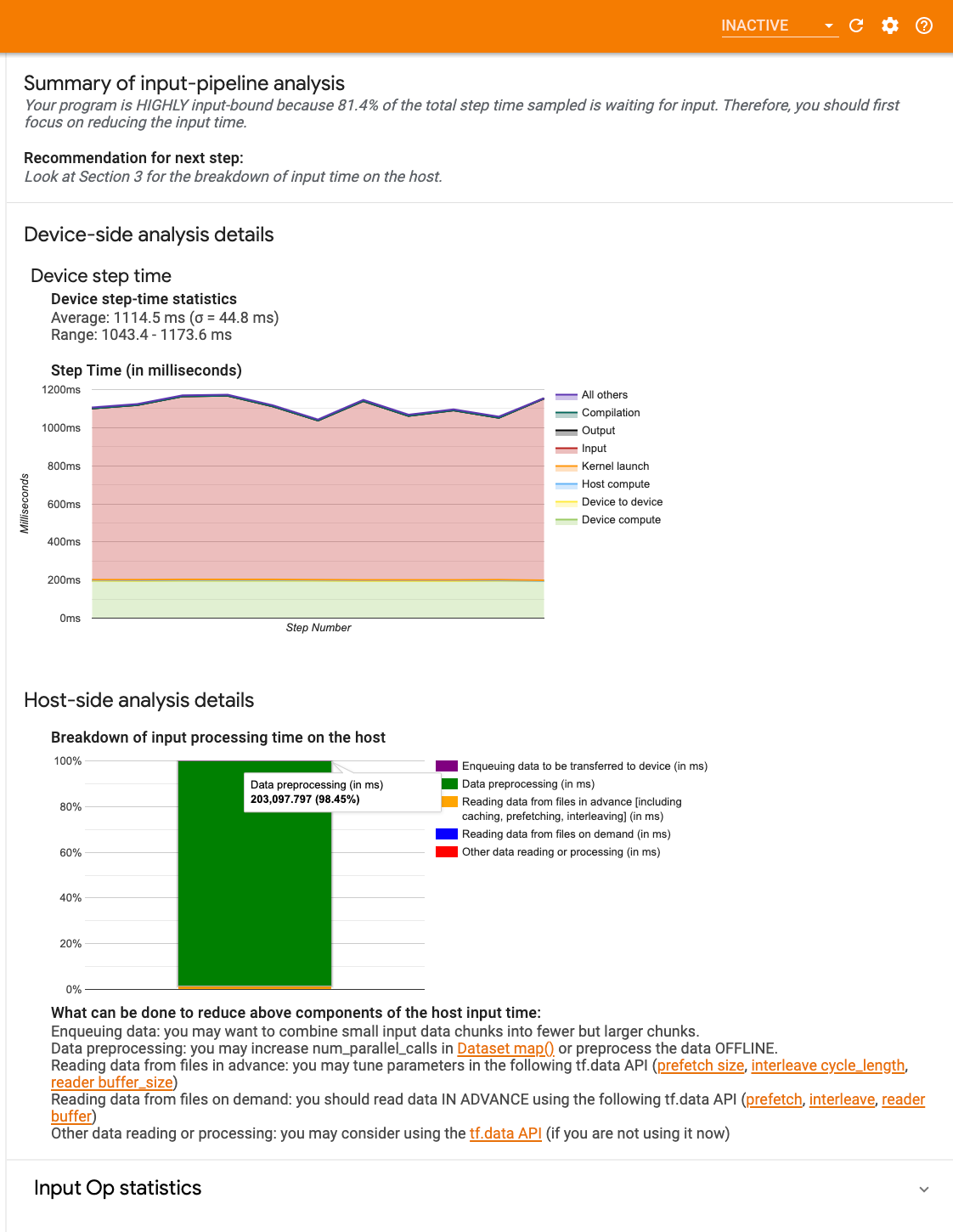
Панель инструментов содержит три секции:
- Краткое содержание: Суммирует общий входной конвейер с информацией о том, связано ли ваше приложение, и, если да, то, сколько.
- Анализ на стороне устройства: Отображает подробные результаты анализа на стороне устройства, включая время шага устройства и диапазон времени, проведенного в ожидании входных данных по ядрам на каждом шаге.
- Анализ на стороне хозяина: Показывает подробный анализ на стороне хоста, включая разбивку времени обработки ввода на хосте.
Входной резюме трубопровода
АКраткое содержаниеОтчеты, если ваша программа связана с вводом, представляя процент времени устройства, потраченного на ожидание ввода от хоста. Если вы используете стандартный входной трубопровод, который был приготовлен, отчеты инструмента, где тратится большая часть времени обработки ввода.
Анализ на стороне устройства
Анализ на стороне устройства дает информацию о времени, проведенном на устройстве по сравнению с хостом, и сколько времени устройства было потрачено в ожидании входных данных с хоста.
- Шагное время, нанесенное в соответствии с номером шага: Отображает график шага устройства (в миллисекундах) по всем отобранным шагам. Каждый шаг разбивается на несколько категорий (с разными цветами) того, где тратится время. Красная область соответствует части временного шага, когда устройства сидели на холостом ходу, ожидая входных данных с хоста. Зеленая область показывает, сколько времени устройство на самом деле работает.
- Статистика шага: Сообщает среднее, стандартное отклонение и диапазон ([минимум, максимум]) шага устройства.
Анализ на стороне хозяина
Анализ на стороне хоста сообщает о разрыве времени обработки ввода (время, потраченное наtf.dataAPI OPS) на хозяине в несколько категорий:
- Чтение данных из файлов по требованию: Время, потраченное на чтение данных из файлов без кэширования, предварительного получения и интеррелирования.
- Чтение данных из файлов заранее: Время, потраченное на чтение файлов, включая кэширование, предварительное получение и интеррелирование.
- Предварительная обработка данных: Время, проведенное на предварительную обработку OPS, например, декомпрессия изображения.
- Данные по внедрению, которые должны быть переданы на устройство: Время, потраченное на размещение данных в очередь до перехода, перед передачей данных на устройство.
РасширятьВходная статистика OPЧтобы осмотреть статистику на наличие отдельных входных операций и их категорий, разбитых временем выполнения.
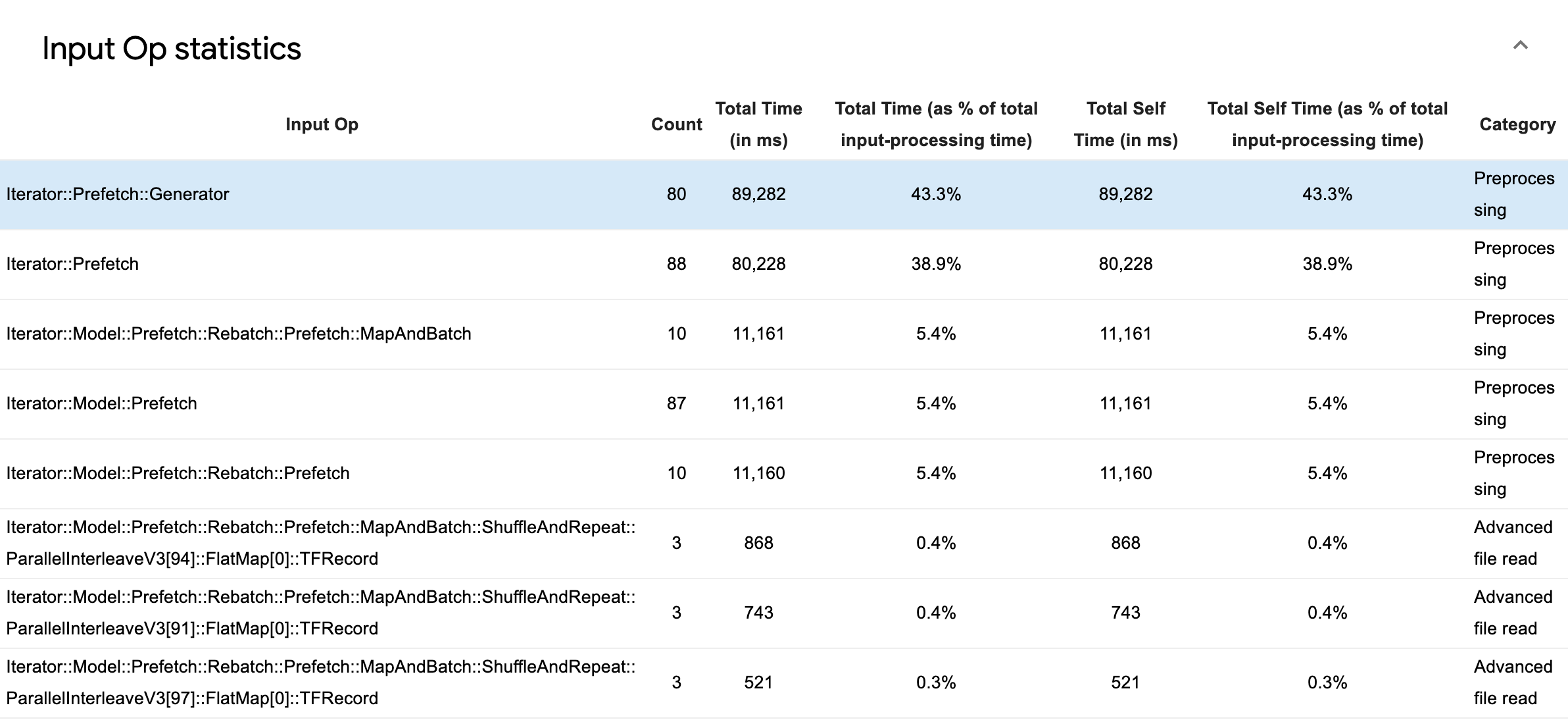
Таблица исходных данных будет отображаться с каждой записью, содержащей следующую информацию:
- Входные операции: Показывает название TensorFlow OP входного OP.
- Считать: Показывает общее количество экземпляров исполнения OP в течение периода профилирования.
- Общее время (в MS): Показывает совокупную сумму времени, проведенного на каждом из этих случаев.
- Общее время %: Показывает общее время, потраченное на OP как часть общего времени, потраченного на обработку ввода.
- Общее время самости (в MS): Показывает совокупную сумму времени, потраченного на каждый из этих случаев. Самостоятельное время здесь измеряет время, проведенное внутри функционального органа, за исключением времени, проведенного в функции, которое он вызывает.
- Общее время самости %Полем Показывает общее время самооценки как часть общего времени, потраченного на обработку ввода.
- КатегорияПолем Показывает категорию обработки входного OP.
Tensorflow Stats
Инструмент TensorFlow Stats отображает производительность каждого OP TensorFlow (OP), который выполняется на хосте или устройстве во время сеанса профилирования.
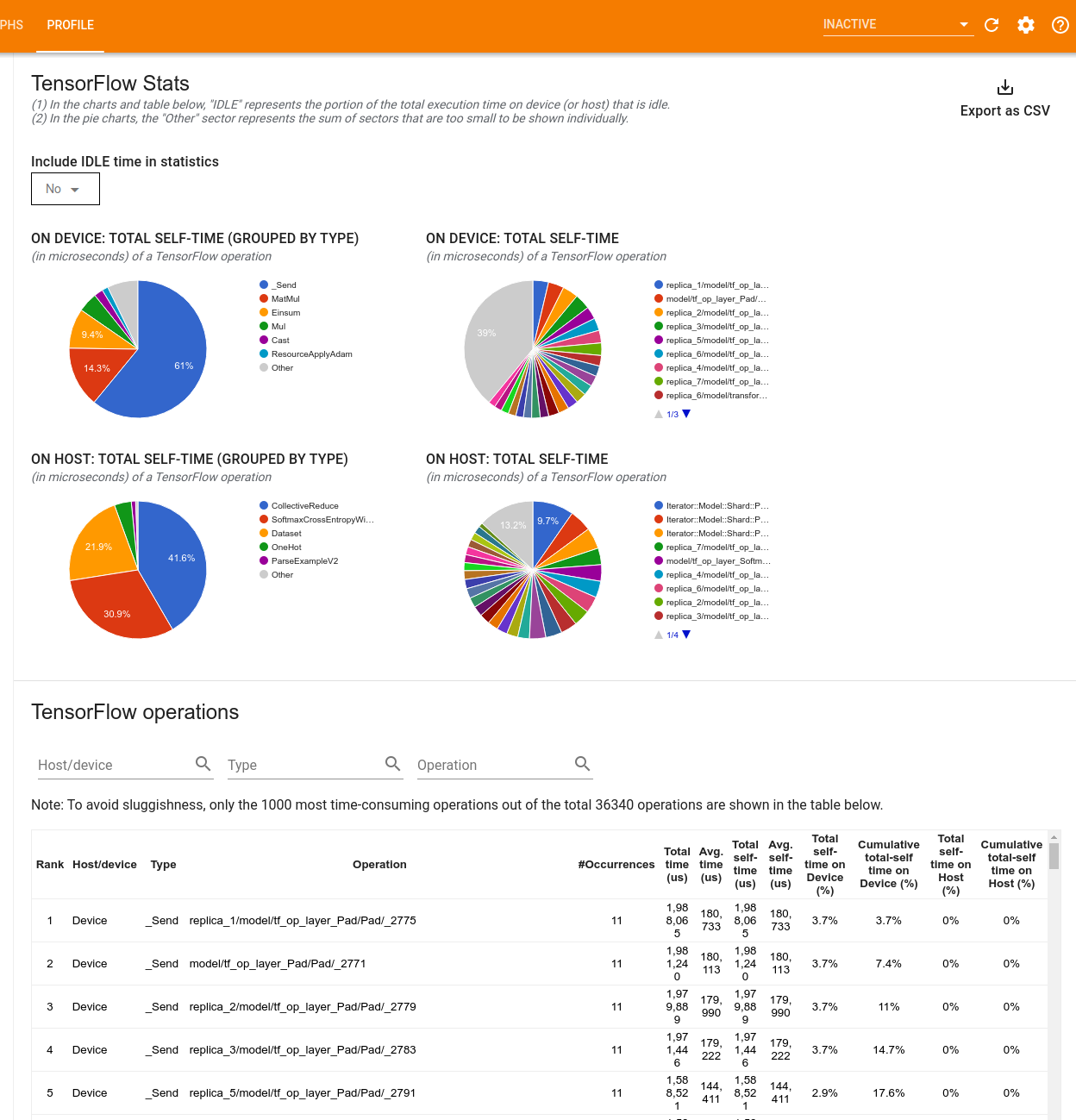
Инструмент отображает информацию о производительности в двух панелях:
Верхняя панель отображает до четырех круговых диаграмм:
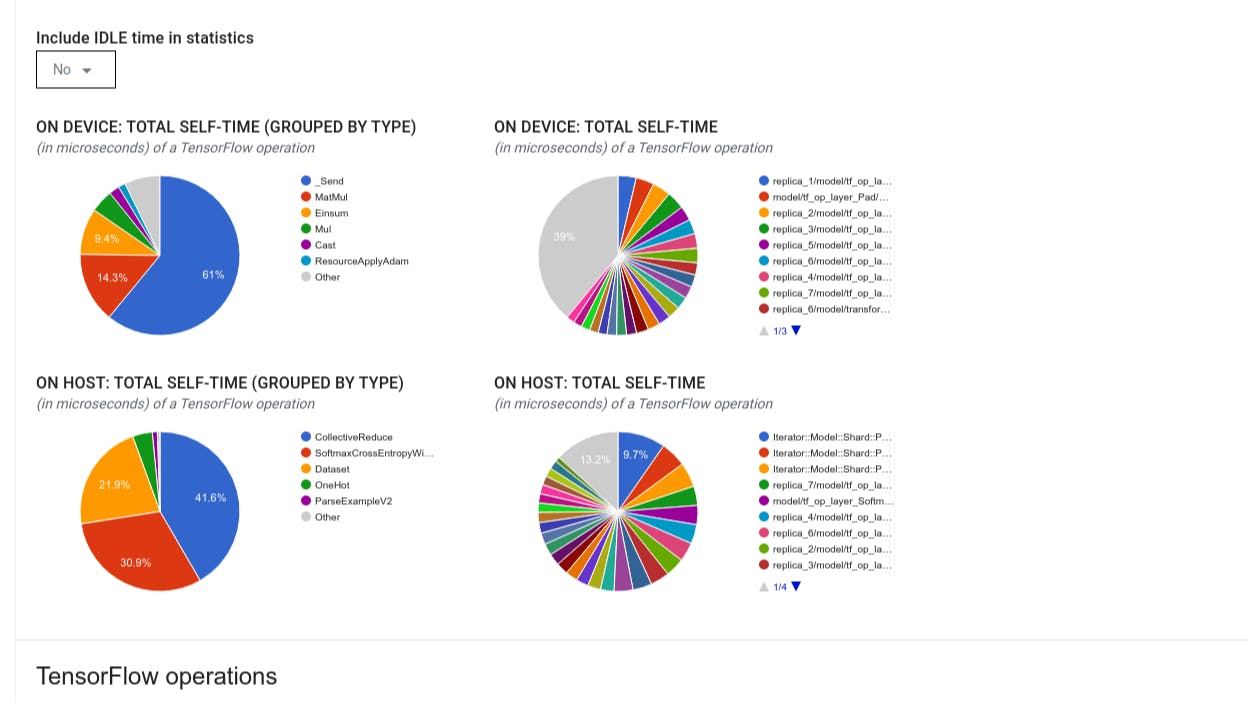
- Распределение времени самоочечения каждого OP на хосте.
- Распределение времени самовосставления каждого типа OP на хосте.
- Распределение времени самоочечения каждого OP на устройстве.
- Распределение времени самостоятельного представления каждого типа OP на устройстве.
The lower pane shows a table that reports data about TensorFlow ops with one row for each op and one column for each type of data (sort columns by clicking the heading of the column). Click the Экспорт как кнопка CSVНа правой стороне верхней панели экспортировать данные из этой таблицы в виде файла CSV.
Обратите внимание, что:
- Если в каких -либо операциях есть дочерние операции:
- Общее «накопленное» время ОП включает время, проведенное в детских операциях.
- Общее время «я» OP не включает время, проведенное в детских операциях.
- Если ОП исполняется на хосте:
- Процент общего самостоятельного времени на устройстве, понесенный OP ON, будет 0.
- Совокупный процент общего самостоятельного времени на устройстве до и включения этого OP будет 0.
- Если OP выполняется на устройстве:
- Процент общего самостоятельного времени на хозяине, понесенный этим ОП, будет 0.
- Совокупный процент общего самостоятельного времени на хозяине до и включения этого OP будет 0.
- Если в каких -либо операциях есть дочерние операции:
Вы можете включить или исключить время простоя в круговые диаграммы и стол.
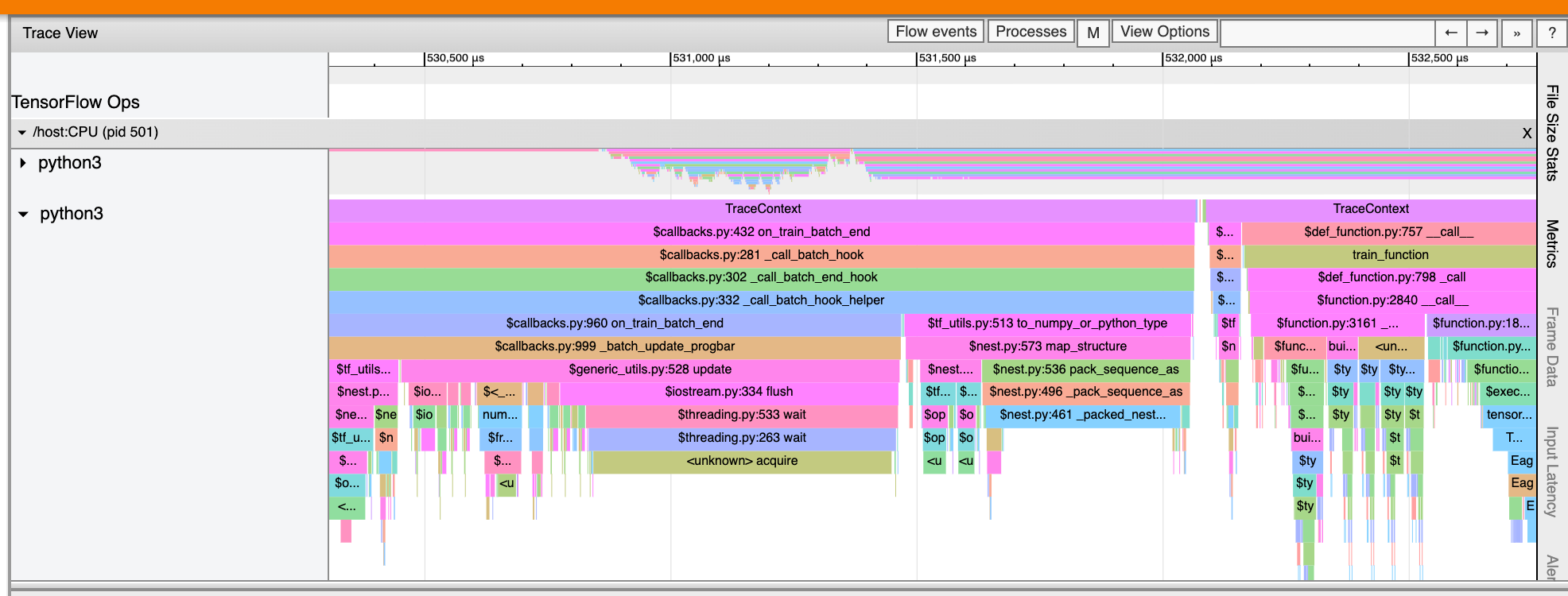
Просмотр просмотра
Просмотр просмотра трассировки отображает временную шкалу, которая показывает:
- Длительность для OPS, которые были выполнены вашей моделью TensorFlow
- Какая часть системы (хост или устройство) выполнила OP. Как правило, хост выполняет операции ввода, предварительные обработки данных и передают их на устройство, в то время как устройство выполняет фактическую подготовку модели
Просмотр Trace Lakes позволяет вам определить проблемы с производительностью в вашей модели, а затем предпринять шаги для их разрешения. Например, на высоком уровне вы можете определить, занимает ли входные или модельные тренировки большую часть времени. Выработав, вы можете определить, какие OPS занимает самое длинное для выполнения. Обратите внимание, что просмотрщик трассировки ограничен 1 миллионами событий на устройство.
Trace Viewer Interface
Когда вы откроете просмотрщик трассировки, он отображает ваш самый последний запуск:
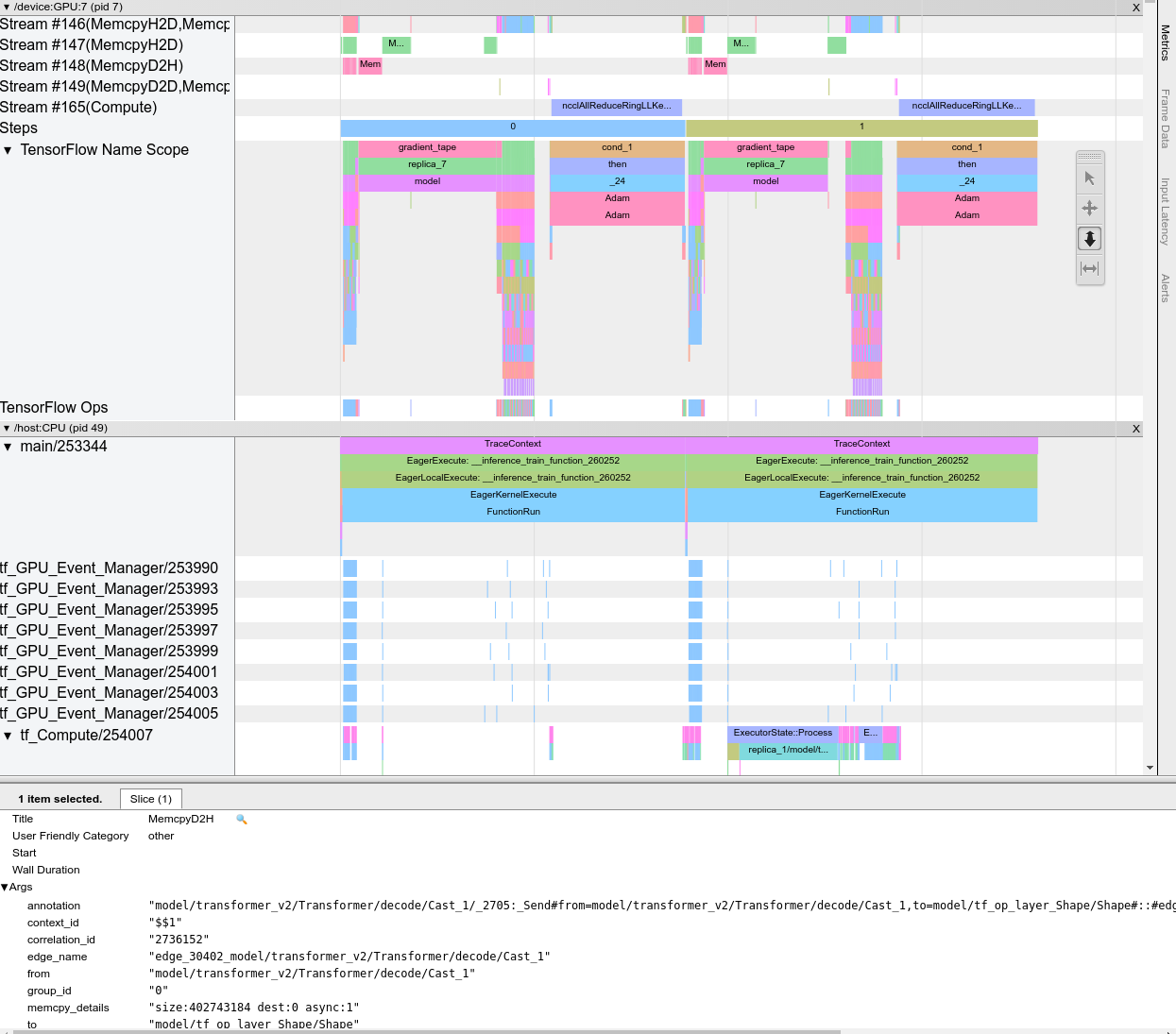
Этот экран содержит следующие основные элементы:
- Главная панель: Показывает OPS, что устройство и хост выполняются с течением времени.
- Детали панели: Показывает дополнительную информацию для OPS, выбранной на панели сроков.
Панель временной шкалы содержит следующие элементы:
- Верхний бар: Содержит различные вспомогательные элементы управления.
- Время ось: Показывает время относительно начала трассировки.
- Раздел и маркировки трека: Каждый раздел содержит несколько треков и имеет треугольник слева, который вы можете нажать, чтобы расширить и свернуть раздел. В системе есть один раздел для каждого элемента обработки.
- Селектор инструментов: Содержит различные инструменты для взаимодействия с просмотром трассировки, такими как Zoom, Pan, Select и Timing. Используйте инструмент времени, чтобы отметить интервал времени.
- События: Они показывают время, в течение которого была выполнена ОП или продолжительность мета-событий, таких как учебные шаги.
Разделы и треки
Просмотр просмотра трассировки содержит следующие разделы:
- Один раздел для каждого узла устройства, помеченной номером чипа устройства и узлом устройства в чипе (например,
/device:GPU:0 (pid 0)) Каждый раздел узла устройства содержит следующие дорожки:- Шаг: Показывает продолжительность обучающих этапов, которые работали на устройстве
- Tensorflow Ops: Показывает OPS, выполненные на устройстве
- XLA OPS: ШоуXlaОперации (OPS), которые работают на устройстве, если xLA является используемым компилятором (каждый TensorFlow OP переводится в один или несколько XLA OPS. Компилятор XLA переводит xla OP в код, который работает на устройстве).
- Один раздел для потоков, работающих на процессоре хост -машины,помечен"Темы хоста"Полем Раздел содержит одну дорожку для каждого потока процессора. Обратите внимание, что вы можете игнорировать информацию, отображаемую вместе с этикетками раздела.
События
События на временной шкале отображаются в разных цветах; Сами цвета не имеют особого значения.
Просмотр TRACE также может отображать следы вызовов функций Python в вашей программе TensorFlow. Если вы используетеtf.profiler.experimental.startAPI, вы можете включить трассировку Python, используяProfilerOptionsNALITTUPLE при запуске профилирования. В качестве альтернативы, если вы используете режим отбора проб для профилирования, вы можете выбрать уровень трассировки, используя параметры раскрытия вЗахват профильдиалог
 Статистика ядра графического процессора
Статистика ядра графического процессора
Этот инструмент показывает статистику производительности и исходное ОП для каждого ускоренного ядра графического процессора.
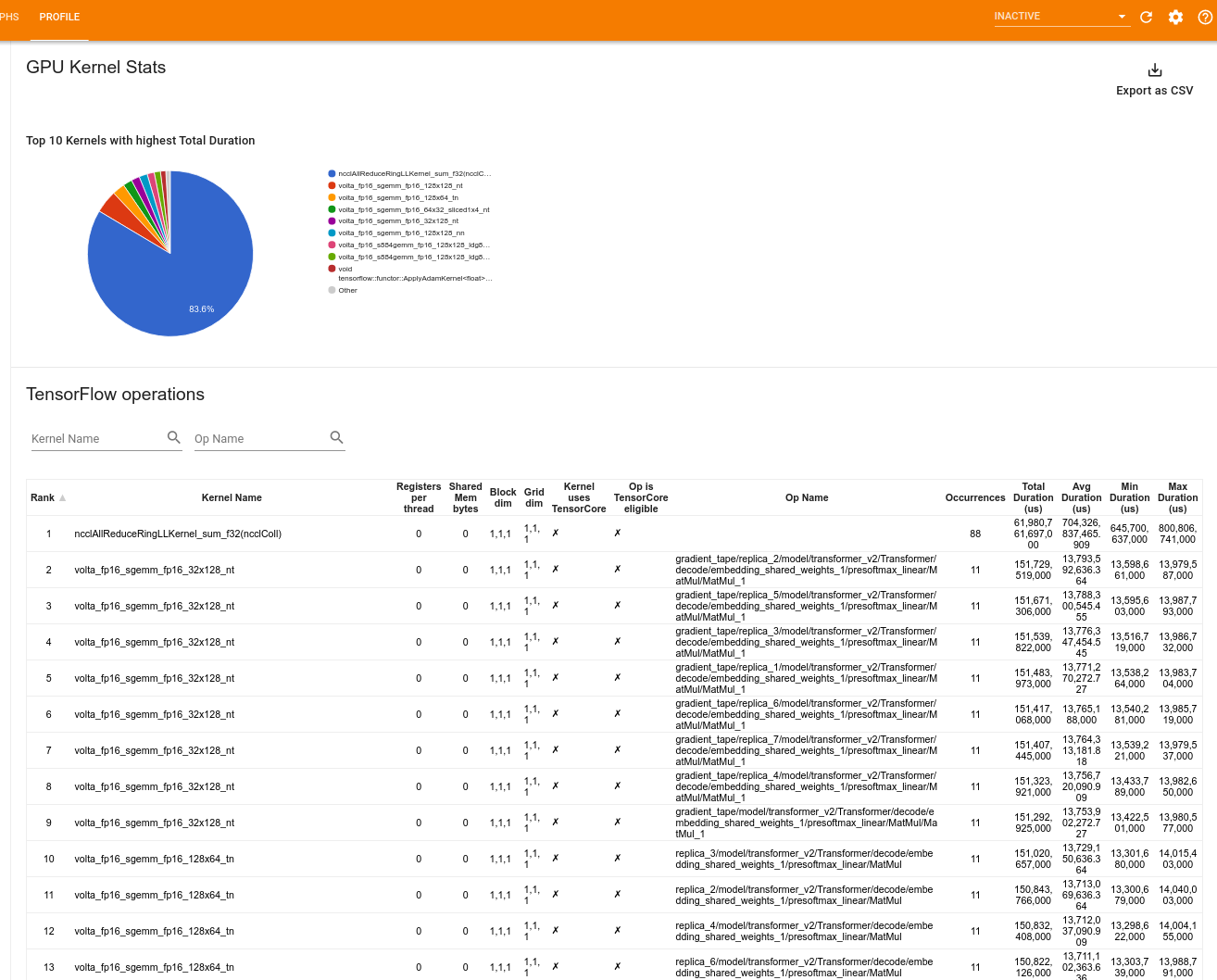
Инструмент отображает информацию в двух панелях:
- Верхняя панель отображает круговую диаграмму, которая показывает ядра CUDA, которые имеют самое высокое общее время.
- Нижняя панель отображает таблицу со следующими данными для каждой уникальной пары ядра:
- Ранг в порядке убывания общей продолжительностью графического процессора, сгруппированного по паре ядра.
- Название запускаемого ядра.
- Количество регистров GPU, используемых ядром.
- Общий размер общей (статической + динамической общей) памяти, используемой в байтах.
- Размер блока, выраженное как
blockDim.x, blockDim.y, blockDim.zПолем - Размеры сетки, выраженные как
gridDim.x, gridDim.y, gridDim.zПолем - Имеет ли право использовать OPТенсорные ядраПолем
- Содержит ли ядро тензорные инструкции.
- Название OP, которое запустило это ядро.
- Количество случаев этой пары ядра.
- Общее время истекшего графического процессора в микросекундах.
- Среднее время искаженного графического процессора в микросекундах.
- Минимальное время истекшего графического процессора в микросекундах.
- Максимальное время истекшего графического процессора в микросекундах.
Инструмент профиля памяти
АПрофиль памятиИнструмент контролирует использование памяти вашего устройства во время интервала профилирования. Вы можете использовать этот инструмент для:
- Проблемы с отладками из памяти (OOM) путем определения пикового использования памяти и соответствующего распределения памяти в Tensorflow Ops. Вы также можете отладить проблемы, которые могут возникнуть при бегемногоцелевоевывод.
- Проблемы фрагментации памяти отладки.
Инструмент профиля памяти отображает данные в трех разделах:
- Сводка профиля памяти
- График срока памяти
- Таблица разбивки памяти
Сводка профиля памяти
В этом разделе отображается резюме высокого уровня профиля памяти вашей программы TensorFlow, как показано ниже:
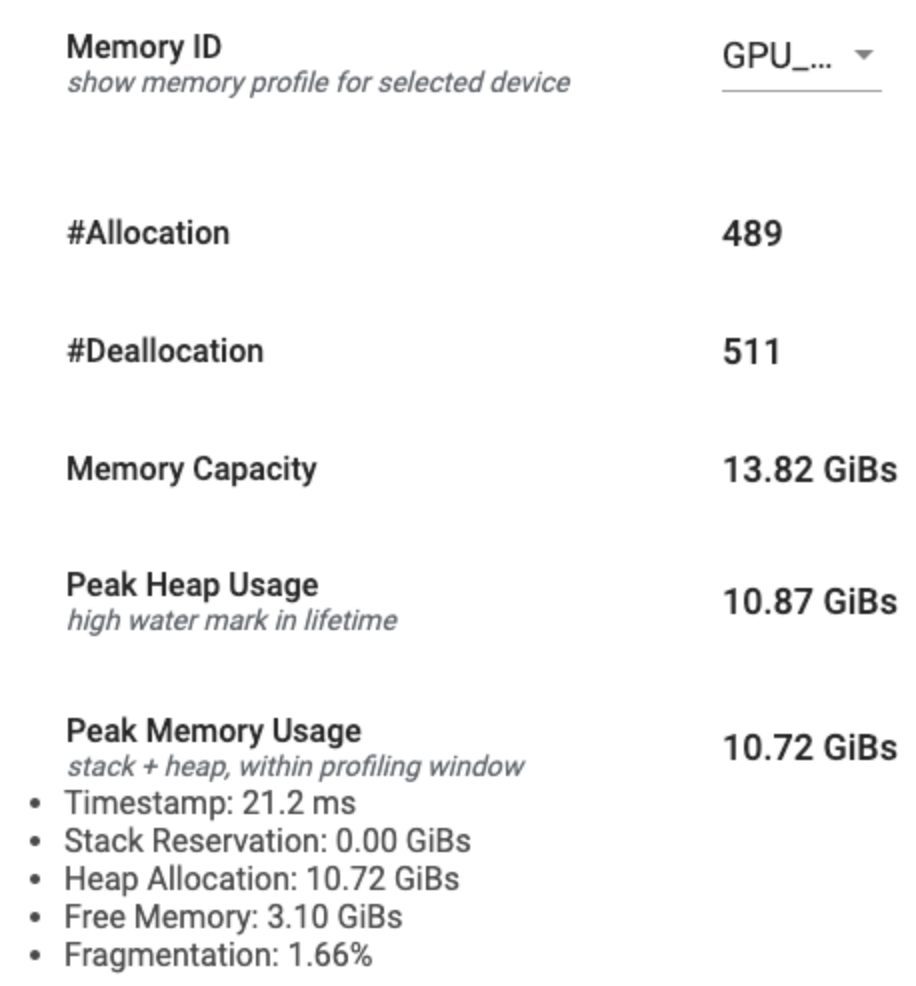
Сводка профиля памяти имеет шесть полей:
Идентификатор памяти: Раскрытие, в котором перечислены все доступные системы памяти устройства. Выберите систему памяти, которую вы хотите просмотреть с выпадающей частью.
#Выделение: Количество распределений памяти, сделанных во время интервала профилирования.
#Deallocation: Количество сделок с памятью в интервале профилирования
Емкость памяти: Общая емкость (в GIBS) выбранной вами системы памяти.
Пиковое использование кучи: Пиковое использование памяти (в Gibs) с момента начала запуска модели.
Пиковое использование памяти: Пиковое использование памяти (в Gibs) в интервале профилирования. Это поле содержит следующие суб-поля:
- Временная метка: TimeStamp of Time, когда пиковое использование памяти произошло на графике сроков.
- Бронирование стека: Размер памяти, зарезервированного в стеке (в Gibs).
- Распределение кучи: Размер памяти, выделенного на кучу (в Gibs).
- Свободная память: Количество свободной памяти (в Gibs). Емкость памяти - это общая сумма резервирования стека, распределения кучи и свободной памяти.
- Фрагментация: Процент фрагментации (лучше лучше). Он рассчитывается как процент от
(1 - Size of the largest chunk of free memory / Total free memory)Полем
График срока памяти
В этом разделе отображается график использования памяти (в GIBS) и процент фрагментации в зависимости от времени (в MS).
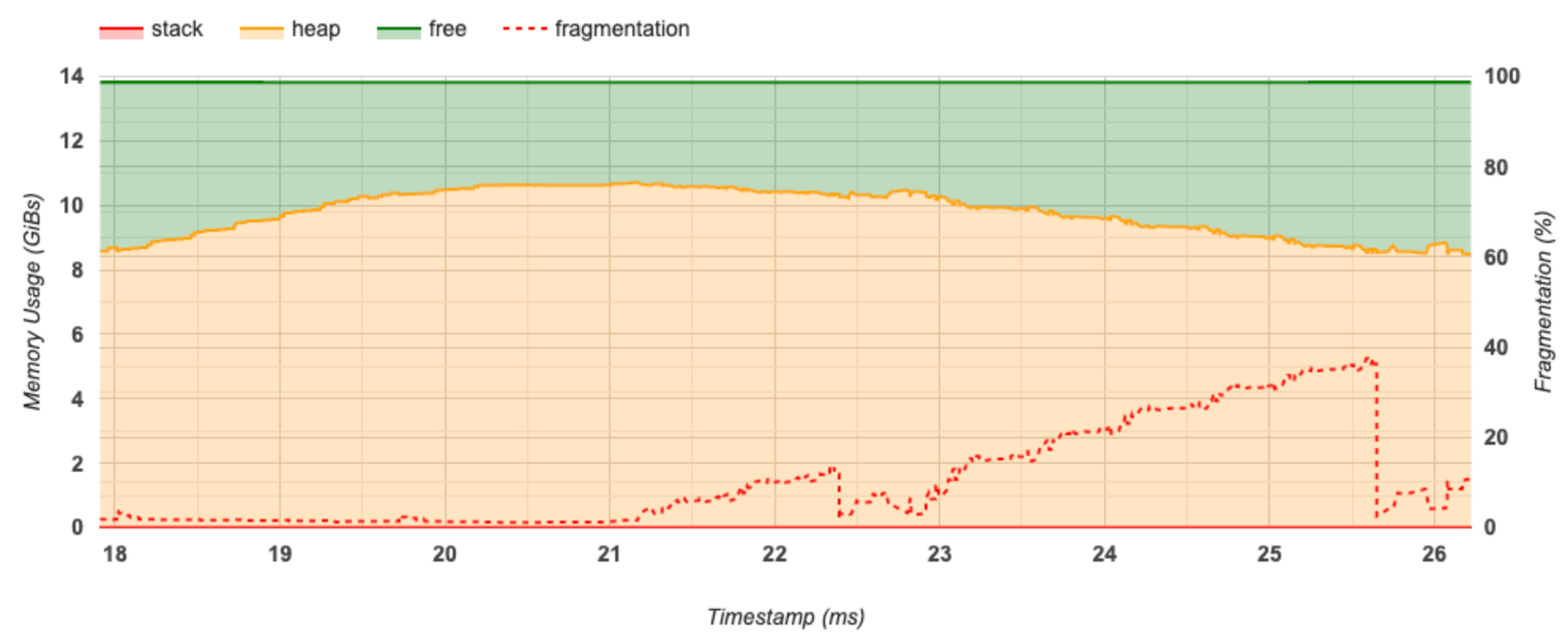
Ось X представляет временную шкалу (в MS) интервала профилирования. Ось Y слева представляет использование памяти (в GIBS), а ось Y справа представляет процент фрагментации. В каждый момент времени на оси X общая память разбивается на три категории: стек (красным), куча (в оранжевом) и бесплатно (в зеленом). Нависнуть на определенную метку времени, чтобы просмотреть подробности о событиях распределения памяти/сделки на тот момент, как ниже:
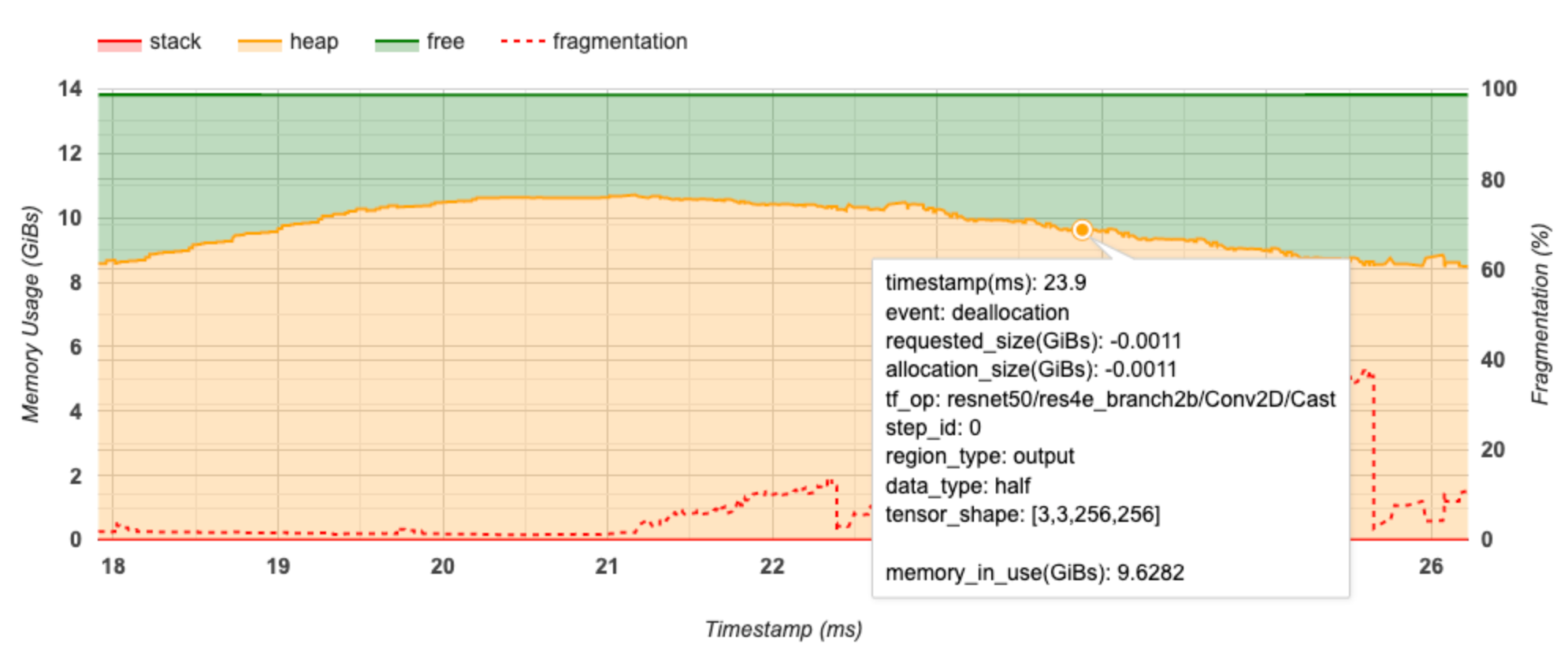
Во всплывающем окне отображается следующая информация:
- временная метка (MS): Расположение выбранного события на временной шкале.
- событие: Тип события (распределение или сделка).
- Запрос_SIZE (GIBS): Сумма запрашиваемой памяти. Это будет отрицательное число для событий Deallocation.
- allocation_size (gibs): Фактическое количество распределенного памяти. Это будет отрицательное число для событий Deallocation.
- tf_op: Tensorflow OP, который запрашивает распределение/сделку.
- Step_id: Шаг обучения, на котором произошло это событие.
- Region_type: Тип объекта данных, для которого предназначена эта выделенная память. Возможные значения
tempдля временных,outputдля активаций и градиентов, иpersist/dynamicдля весов и константов. - data_type: Тип элемента тензора (например, Uint8 для 8-битного целочисленного целого числа).
- tensor_shape: Форма тензора распределяется/сделка.
- memory_in_use (gibs): Общая память, которая используется на данный момент. \
Таблица разбивки памяти
В этой таблице показаны активные распределения памяти в точке пикового использования памяти в интервале профилирования.
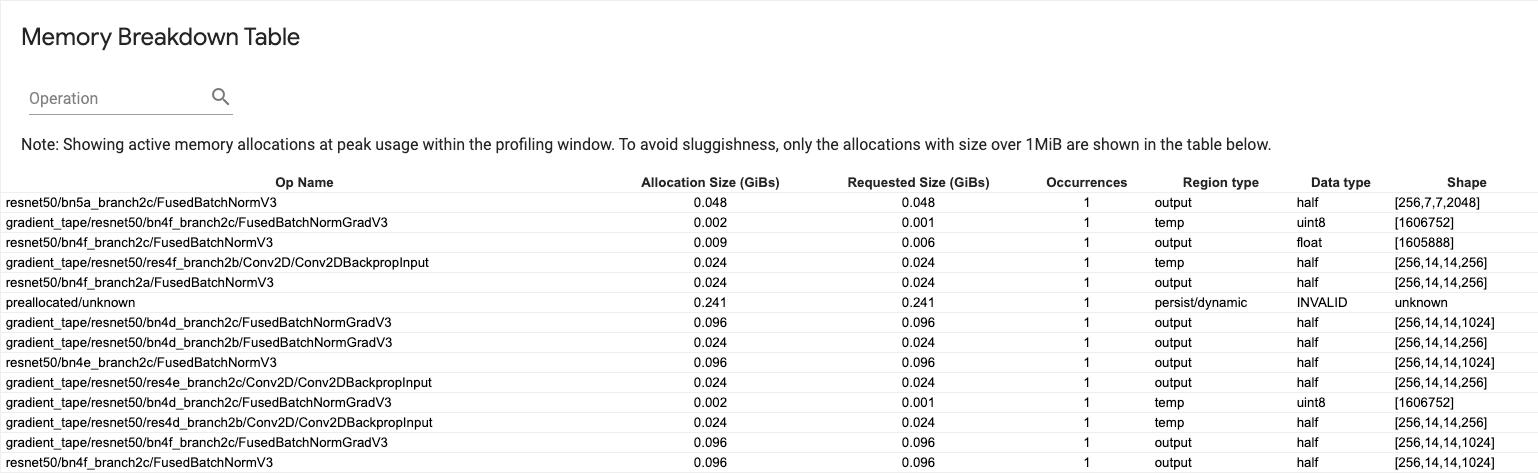
Есть одна строка для каждого OP TensorFlow, и каждая строка имеет следующие столбцы:
Op название: Название Tensorflow Op.
Размер распределения (Gibs): Общий объем памяти, выделенного для этого OP.
Запрашиваемый размер (Gibs): Общая сумма памяти, запрашиваемой для этого OP.
Случаи: Количество распределений для этого операции.
Тип региона: Тип объекта данных, для которого предназначена эта выделенная память. Возможные значения
tempдля временных,outputдля активаций и градиентов, иpersist/dynamicдля весов и константов.Тип данных: Тип тензора.
Форма: Форма выделенных тензоров.
Примечание:Вы можете сортировать любой столбец в таблице, а также фильтровать строки по имени OP.
Просмотрщик капсул
Инструмент POD Viewer показывает разбивку этапа обучения на всех работников.
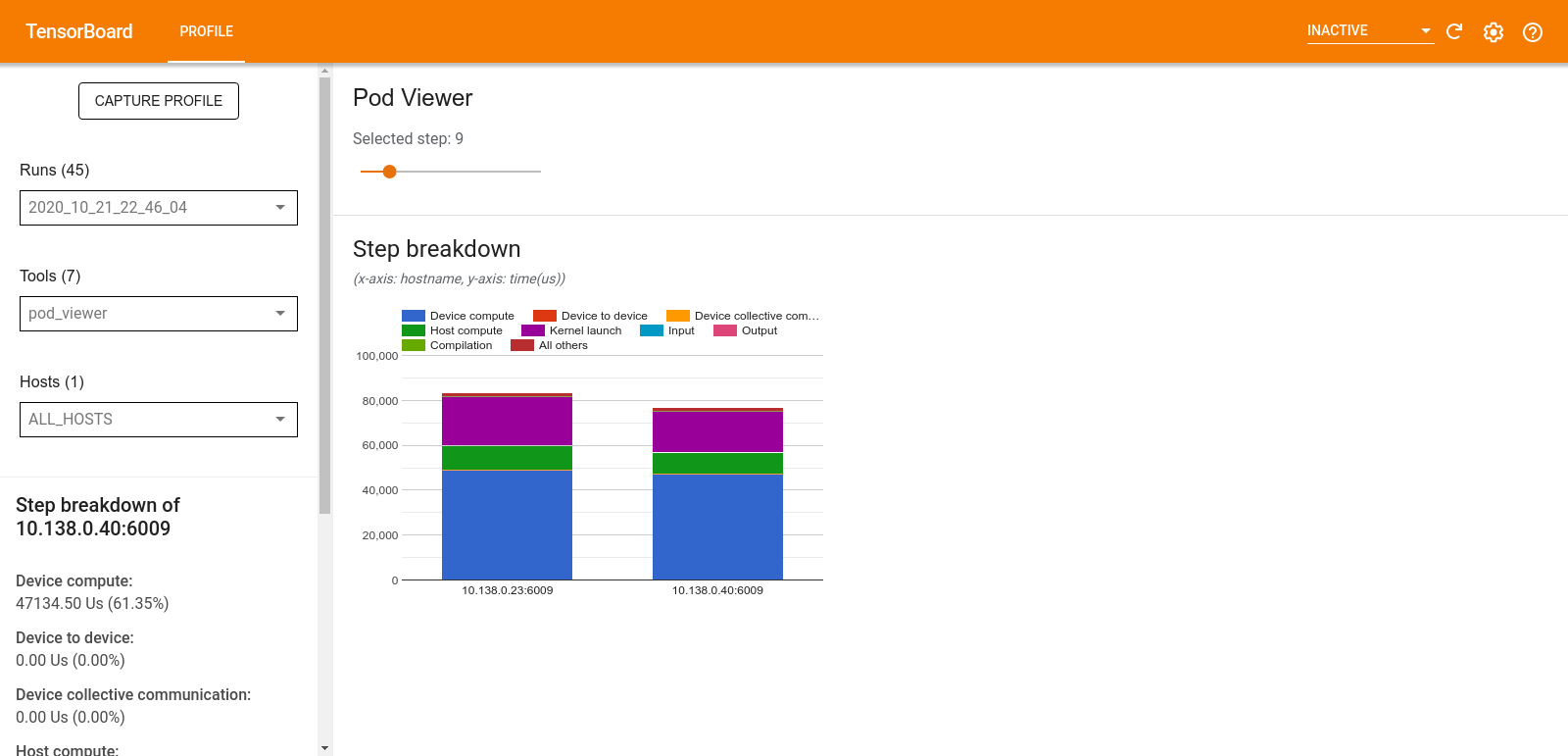
- Верхняя панель имеет слайдер для выбора номера шага.
- Нижняя панель отображает карту с сложенным столбцом. Это высокий взгляд на разбитые категории времена, расположенные на вершине друг друга. Каждый сложенный столбец представляет уникального работника.
- Когда вы падаете над сложенным столбцом, карта на левой стороне показывает более подробную информацию о разбивке шага.
TF.Data Анализ узкого места
Предупреждение:Этот инструмент экспериментальный. Пожалуйста, откройте
Аtf.dataИнструмент анализа узких мест автоматически обнаруживает узкие места вtf.dataВходные трубопроводы в вашей программе и дают рекомендации о том, как их исправить. Он работает с любой программой, используяtf.dataнезависимо от платформы (процессор/графический процессор/TPU). Его анализ и рекомендации основаны на этомгидПолем
Он обнаруживает узкое место, выполнив эти шаги:
- Найдите наиболее входной хост.
- Найти самое медленное выполнение
tf.dataВходной трубопровод. - Реконструируйте график входного трубопровода из трассировки Profiler.
- Найдите критический путь на графике входного трубопровода.
- Определите самое медленное преобразование на критическом пути как узкого места.
Пользовательский интерфейс разделен на три раздела:Резюме анализа производительностиВРезюме всех входных трубопроводовиВходной трубопроводПолем
Резюме анализа производительности

В этом разделе содержится краткое изложение анализа. Он сообщает о медленномtf.dataВходные трубопроводы, обнаруженные в профиле. В этом разделе также показан самый входной граничный хост и его самый медленный входной трубопровод с максимальной задержкой. Самое главное, он определяет, какая часть входного трубопровода является узким местом и как его исправить. Информация о узких местах предоставляется типом итератора и его длинным названием.
Как прочитать длинное имя TF.Data итератора
Длинное название отформатируется какIterator::<Dataset_1>::...::<Dataset_n>Полем В длинном названии,<Dataset_n>соответствует типу итератора, а другие наборы данных в длинном имени представляют собой преобразования вниз по течению.
Например, рассмотрим следующий набор данных входного трубопровода:
dataset = tf.data.Dataset.range(10).map(lambda x: x).repeat(2).batch(5)
Длинные имена для итераторов из приведенного выше набора данных будут:
Тип итератора | Длинное название |
|---|---|
Диапазон | Итератор :: pactor :: repeat :: map :: range |
Карта | Итератор :: pactor :: repeat :: Карта |
Повторить | Iterator::Batch::Repeat |
Партия | Итератор :: партия |
Резюме всех входных трубопроводов
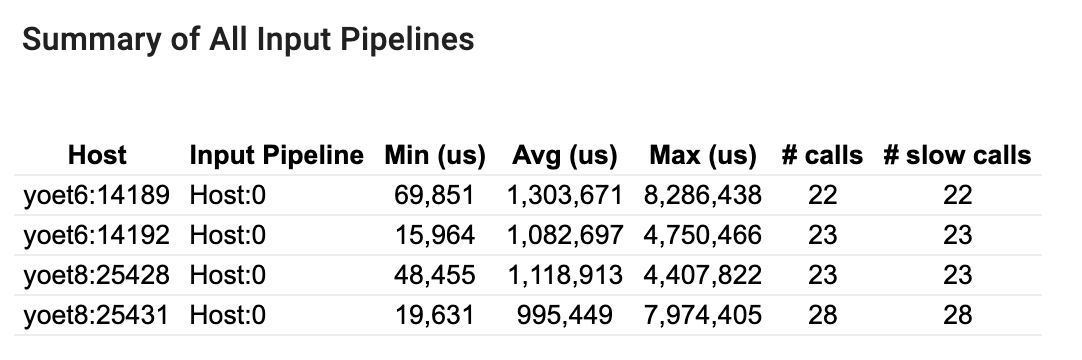
В этом разделе содержится сводка всех входных трубопроводов на всех хостах. Как правило, есть один входной конвейер. При использовании стратегии распространения, есть один входной конвейер хоста, работающий с программой.tf.dataКод и несколько входных конвейеров устройства извлекают данные из входного трубопровода хоста и передают его на устройства.
Для каждого входного конвейера он показывает статистику своего времени выполнения. Вызов считается медленным, если он занимает больше 50 мкс.
Входной трубопровод

В этом разделе показан график входного трубопровода с информацией о времени выполнения. Вы можете использовать «хост» и «входной конвейер», чтобы выбрать, какой хост и входной трубопровод стоит увидеть. Выполнения входного трубопровода отсортируется по времени выполнения в порядке убывания, которые вы можете выбрать, используяКлассифицироватьпадать.
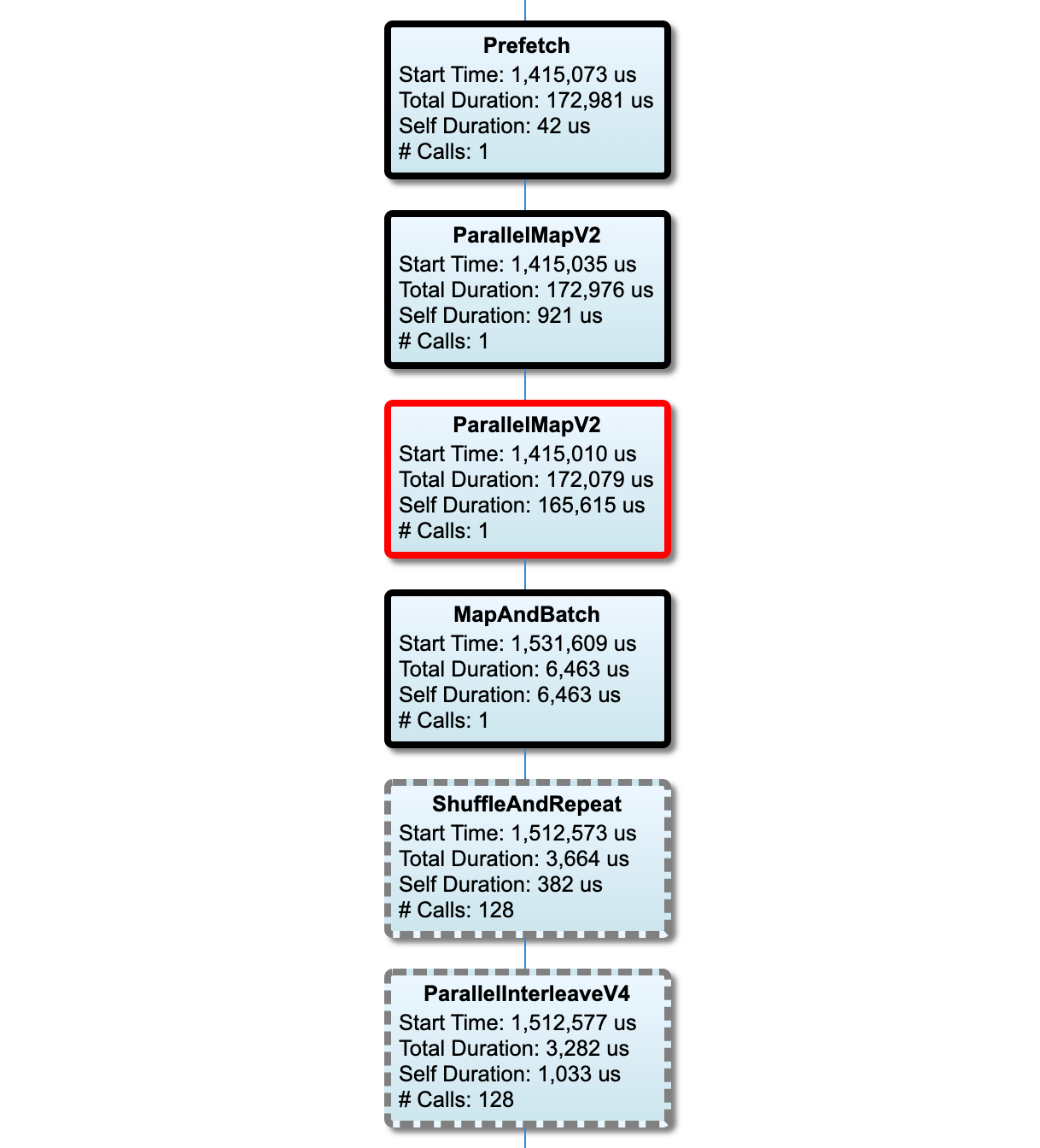
Узлы на критическом пути имеют смелые очертания. Узел узкого места, который является узел с самым длинным временем самостоятельно на критическом пути, имеет красный контур. Другие некритические узлы имеют серые пунктирные контуры.
В каждом узле,Время началаУказывает время начала исполнения. Например, один и тот же узел может быть выполнен несколько раз, если естьBatchOP в входном трубопроводе. Если он выполняется несколько раз, это время начала первого выполнения.
Общая продолжительностьэто время стены исполнения. Если он выполняется несколько раз, это сумма времен стены всех выполнений.
Самостоятельное времяявляетсяОбщее времяБез перекрывающегося времени с его непосредственными детскими узлами.
«# Вызовы» - это количество раз, когда входной трубопровод выполняется.
Первоначально опубликовано на
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27294)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)