
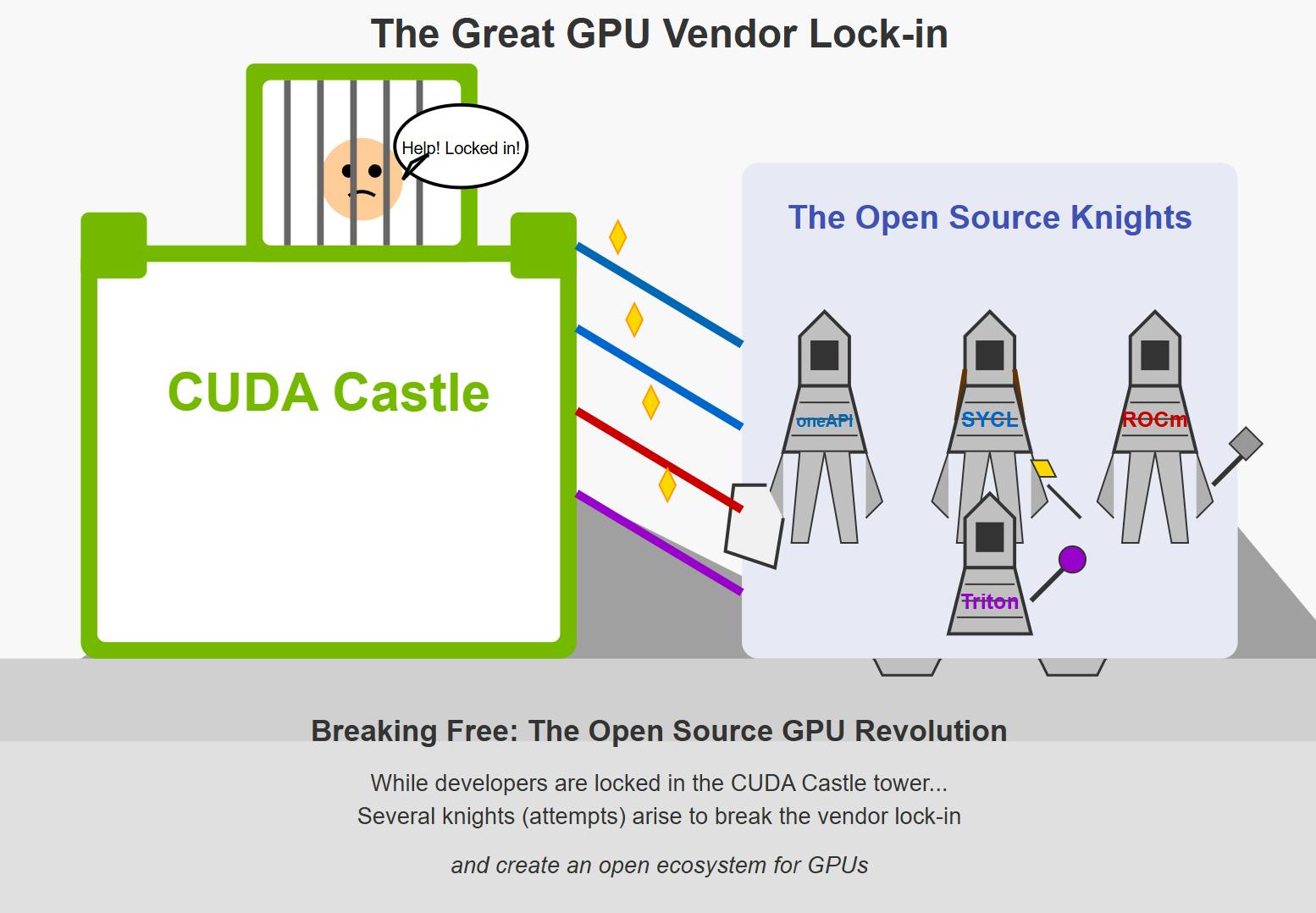
Стандарты с открытым исходным кодом-разбивание блокировки поставщиков для разработчиков графических процессоров
15 июля 2025 г.Привет, энтузиасты GPU!
Сегодня, поскольку техническая экосистема быстро изменяется, программирование графических процессоров быстро стало мощностью, стоящей за важными структурами от передового ИИ и машинного обучения до высокопроизводительных вычислений и потрясающей графики. Поскольку мы смотрим на будущее вычислений, два ключевых фактора изменяют этот ландшафт: разнообразие в подходах к программированию и растущую важность инициатив с открытым исходным кодом. Давайте посмотрим, как эти элементы преобразуют вычисления графических процессоров и создают более инклюзивную, инновационную экосистему для всех!
Эволюция языков программирования графического процессора
Собственное начало
История программирования GPU началась в основном как запатентованное усилие. Nvidia запустила CUDA в 2006 году, предоставив набор для разработки программного обеспечения и API, который позволил разработчикам использовать C для алгоритмов кодирования на графических процессорах NVIDIA. В то время как революционный, этот подход создал экосистему, заблокированную для конкретного оборудования, потенциально ограничивая инновации и доступность.
OpenCl: первый крупный открытый стандарт
В 2008 году группа Хронос (те же самые люди, стоящие за OpenGL), начала разрабатывать OpenCl (открытый язык вычислений) как ответ на необходимость открытого кроссплатформенного стандарта. OpenCL 1.0 был официально выпущен в декабре 2008 года, когда Apple играет важную роль в своей первоначальной разработке, прежде чем передать его группе Хронос.
OpenCl был новаторским, так как он позволил разработчикам писать код, который мог бы работать через гетерогенные платформы - CPU, GPU, DSP и FPGA - от различных поставщиков. Это был первый важный шаг к демократизации программирования GPU.
Тем не менее, будучи стандартом, основанным на комитете, представил проблемы для OpenCl. Необходимость достижения консенсуса среди нескольких заинтересованных сторон часто приводит к более медленным циклам развития по сравнению с запатентованными решениями. Как отметил один из разработчиков, OpenCL может быть «более медленной и аппаратной реактивной спецификацией, разработанной комитетом, который не может быть продлен в одностороннем порядке производителями графических процессоров». Иногда это оставляло отставание OpenCl в поддержке передовых функций, доступных в инструментах, специфичных для поставщиков, таких как CUDA.
Хотите исследовать OpenCl? ПроверьтеРепозиторий OpenCl GitHubдля официального SDK иOpencl.orgДля ресурсов сообщества!
OpenCV: пионеры компьютерного зрения
Примерно в то же время появлялся OpenCl, еще один важный проект с открытым исходным кодом набирал обороты. OpenCV (библиотека Computer Vision с открытым исходным кодом) была первоначально разработана Intel в 1999 году, но в 2006 году была первая стабильная выпуск 1.0. Библиотека стала краеугольным камнем для приложений Computer Vision, и начиная с 2011 года, она начала показывать ускорение графического процессора для операций в реальном времени.
Эволюция OpenCV соответствует росту открытых вычислений графических процессоров, а библиотека поддерживает различные бэкэнды, включая CUDA и OpenCl. Его кроссплатформенная природа (работающая в Windows, Linux, MacOS, Android и iOS) иллюстрирует значение открытых стандартов при расширении доступа к ускорению графического процессора.
Для компьютерного видения ультрасРепозиторий opencv Githubпредлагает множество ресурсов и примеров для изучения!
Добавление программирования графических процессоров с открытым исходным кодом через инициативы LF AI & Data Foundation
Эволюция программирования графических процессоров из проприетарных экосистем в открытые стандарты представляет собой критическую точку перегиба в развитии искусственного интеллекта. Этот переход отражает стратегическую миссию Foundation LF AI & Data Foundation по стимулированию открытых инноваций с помощью таких проектов, как такие проекты, какOnnxи инициатива открытой модели. Совместив достижения программирования графических процессоров с этими усилиями, поддерживаемыми основой, разработчики получают доступ к инструментам, которые ломают блокировку поставщиков при сохранении высокопроизводительных возможностей.
Onnx: Blueprint для успеха открытых стандартов
Обмен открытыми нейронными сетью (ONNX) демонстрирует, как LF AI & Data Projects успешно переводятся технологии, специфичные для доменов в стандарты, нейтральные поставщика. Первоначально разработан в результате сотрудничества между Facebook и Microsoft, Onnxдостигнут выпускнойСтатус под управлением фонда в 2019 году - свидетельство его зрелости и принятия промышленности
Техническая совместимость на практике
Поставщик ROCM ROCM ROCM ROCM ROCM позволяет ускорить AMD-графические процессоры через программные стеки с открытым исходным кодом, напрямую поддерживая акцент блога на разнообразие оборудования. Разработчики могут развернуть модели на графических процессорах Radeon, используя один и тот же рабочий процесс ONNX через:

Этот фрагмент кода иллюстрирует, как ONNX абстрагирует аппаратные характеристики при сохранении производительности - достигая 98% пропускной способности CUDA на акселераторах AMD Instinct при правильной настройке. Управление фонда обеспечивает постоянную поддержку новых архитектур через 138 активных участников из 30+ организаций
Восстание Сикла
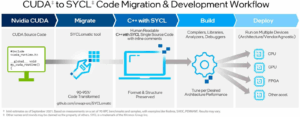
Основываясь на основе Opencl, SYCL (произносится «Серп») была разработана группой Хронос в качестве модели программирования более высокого уровня. Объявленный в марте 2014 года, SYCL представляет собой встроенный встроенный домен язык с одним источником, основанный на Pure C ++ 17, который направлен на повышение производительности программирования на различных аппаратных ускорителях.
SYCL предоставляет кроссплатформенную абстракцию, который позволяет алгоритмам переключаться между аппаратными ускорителями, такими как процессоры, графические процессоры и FPGA, не изменяя одну строку кода, что делает его особенно ценным для гетерогенных вычислительных сред.
Источник
Инициатива Intel Oneapi
В 2019 году Intel запустила OneApi как открытую модель единого программирования, основанной на стандартах, направленную на решение проблем программирования в различных архитектурах. OneApi расширяет существующие модели программирования разработчиков, чтобы обеспечить несколько аппаратных архитектур через диаграмму данных, набор библиотечных API и низкоуровневый аппаратный интерфейс для поддержки программирования межархитектуры.
По своей сути, OneApi построен на стандартах SYCL группы ISO C ++ и Khronos, обеспечивая подход программирования с одним источником, где разработчики могут писать код один раз и запускать его на процессорах, графических процессорах, FPGA и других ускорителях. Это напрямую решает проблему блокировки поставщика, которая в течение многих лет преследует вычисления графических процессоров.
«Oneapi-это межотраслевая, открытая, основанная на стандартах модель объединенного программирования, которая обеспечивает общий опыт разработчика в архитектурах ускорителя-для более высокой производительности применения, большей производительности и большей инноваций»,-говорится в официальном веб-сайте Oneapi.
Базовый инструментарий OneApi включает в себя инструмент совместимости Intel DPC ++, который может автоматически перенести код CUDA в код SYCL, предлагая разработчикам путь, чтобы вывести из экосистем, специфичных для поставщиков. Эта возможность особенно ценна для организаций со значительными инвестициями в кодовые базы CUDA, которые хотят диверсифицировать свои аппаратные варианты.
Ключевым преимуществом OneApi является его приверженность переносимости производительности - согласование кода, чтобы не только работать на разных аппаратных платформах, но и эффективно работать. Предоставляя оптимизированные реализации общих алгоритмов и функций через такие библиотеки, как OneMKL (библиотека Math Kernel), OneDnn (библиотека глубоких нейронных сети) и другие, OneApi помогает обеспечить, чтобы приложения могли достичь хорошей производительности по разным оборудованию.
Triton: упрощение программирования нейронной сети
В июле 2021 года Openai выпустил Triton 1.0, языка программирования с открытым исходным кодом, специально разработанным для программирования графических процессоров в нейронных сетях. Проект фактически начался ранее, с его фондами, описанными в публикации 2019 года под названием «Triton: промежуточный язык и компилятор для вычислений с плиточной нейронной сетью», представленных на Международном семинаре по машинному обучению и языкам программирования.
Тритон позволяет достичь пиковой аппаратной производительности с относительно небольшими усилиями; Например, его можно использовать для написания ядров умножения матрицы FP16, которые соответствуют производительности CUBLAS в до 25 строк кода.
Первоначально поддерживая только графические процессоры NVIDIA, Triton получает усыновление в сообществе ИИ. Компании, находящиеся за Openai, начинают поддерживать Triton, причем такие рамки, как Pytorch 2.0, включают Triton для его генерации бэкэнд -кода через его компилятор «индуктора». По состоянию на начало 2025 года предпринимаются усилия по расширению Triton для поддержки других поставщиков оборудования, что делает его все более важным игроком в кроссплатформенном программировании GPU.
Платформа AMD ROCM и бедра
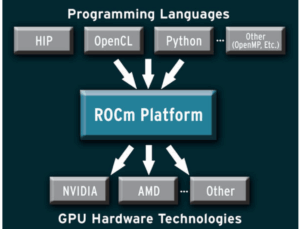
Управляя необходимость в большем количестве опций с открытым исходным кодом, AMD запустила ROCM (Radeon Open Compute) в 2016 году в качестве ответа на CUDA с открытым исходным кодом. ROCM приобрел значительную поддержку в высокопроизводительных вычислениях, используя с суперкомпьютерами Exascale, такими как El Capitan и Frontier.
Ключевым компонентом ROCM является HIP (гетерогенный интерфейс для переносимости), что особенно интересно для разработчиков, работающих на разных платформах GPU. HIP - это API времени выполнения C ++ и язык ядра, который позволяет писать портативный код, который может работать на оборудовании AMD и NVIDIA.
Что делает HIP Special, так это возможности перевода - он может преобразовать код CUDA в портативный формат! КакОфициальное хранилище бедраобъясняет: «Инструменты HIPIFY автоматически преобразуют источник из CUDA в бедро». При нацеливании на платформы NVIDIA, HIP предоставляет файлы заголовков, которые переводят API -интерфейсы времени выполнения HIP на API -интерфейсы времени выполнения CUDA с очень низкими накладными расходом, что позволяет разработчикам достигать той же производительности, что и нативные CUDA. При нацеливании на платформы AMD HIP использует компилятор Hip-Clang и библиотеку времени выполнения.
Этот подход позволяет разработчикам:
- Напишите новые проекты в бедре, которые могут работать на любой платформе
- Порт существующие коды CUDA в бедро, чтобы сделать их кроссплатформенными
- Специализируйтесь на конкретные платформы, когда это необходимо для оптимизации производительности
Источник
Аппаратный агностицизм через сотрудничество сообщества
Требование LF AI & Data для интеграции проекта создает техническую синергию, которая непосредственно борется с фрагментацией программирования GPU. Совместимость Onnx Runtime с:
- Intel Oneapi для xe архитектуры графических процессоров
- Nvidia cuda через поставщиков местных исполнителей
- AMD ROCM через оптимизированные библиотеки ядра
Демонстрирует, как фонды реализуют адвокационные принципы оборудования в блоге. Матрица совместимости ROCM EP показывает оптимизацию, конкретные для конкретной версии, обеспечивая обратную совместимость в пяти поколениях аппаратного обеспечения AMD
Почему разнообразие и важность с открытым исходным кодом в программировании GPU
1. Разбивая блокировку продавца
Одним из наиболее значительных преимуществ моделей программирования GPU с открытым исходным кодом является снижение зависимости от конкретных поставщиков оборудования. Платформы, такие как OpenCl и Vulkan, снижают зависимость от конкретных поставщиков аппаратного обеспечения, предлагая большую гибкость и эффективность затрат для предприятий. Это означает, что вы не привязаны к дорожной карте одной компании или структуре цен - у вас есть варианты!
2. Содействие инновациям через сообщество
Nature ROCM с открытым исходным кодом поощряет вклад от глобального сообщества разработчиков, ускоряя рост и адаптивность платформы. Этот подход, основанный на сообществе, приводит к более быстрому инновациям и решению проблем, чем возможно в закрытых экосистемах. Просто проверьте активностьСообщество ROCM на GitHubЧтобы увидеть это сотрудничество в действии!
3. Включение кроссплатформенной совместимости
Открытые стандарты, такие как Sycl и OpenCl, позволяют разработчикам писать код один раз и запускать его на нескольких платформах. SYCL поддерживает несколько типов ускорителей одновременно в пределах одного применения посредством концепции бэкэндов, что значительно снижает время разработки и затраты.
4. Поддержка образования и исследований
Инструменты с открытым исходным кодом предоставляют бесценные ресурсы для образования и исследований. Triton-это язык программирования, специфичный для домена, который упрощает программирование GPU для высокопроизводительных задач, особенно в приложениях искусственного интеллекта, предоставляя среду с открытым исходным кодом, которая позволяет пользователям писать код высокого уровня с большей производительностью. АТритон учебные пособияПредложите отличную отправную точку для студентов и исследователей, желающих изучить программирование графических процессоров.
Текущие тенденции и будущие перспективы
Растущая важность открытого исходного кода в промышленности
Мы видим бум в проектах по графическим процессорам с открытым исходным кодом. Это предоставляет набор инструментов с открытым исходным кодом для вычислений графических процессоров, что позволяет разработчикам писать высокопроизводительный код, который может работать на любом совместимом GPU.According для недавних отраслевых отчетов, инициативы с открытым исходным кодом, такиеГрафический процессорнабирают значительную поддержку, поскольку разработчики ищут более гибкие и доступные инструменты для программирования графических процессоров.
Конвергенция вычислений ИИ и графического процессора
ИИ и машинное обучение являются движущей силой спроса на более мощные графические процессоры. Такие компании, как Nvidia и AMD, находятся на переднем крае, раздвигая границы того, что возможно. АПирогиTensorflowФреймворки продолжают развивать свою поддержку GPU, облегчая, чем когда -либо, использовать ускорение графических процессоров для рабочих нагрузок.
Совместимость по перекрестной программе в качестве приоритета
По мере того, как отрасли все чаще принимают различные аппаратные решения, совместимость с помощью кросс-хардюра стала важным фактором в эволюции вычислений графических процессоров. И ROCM, и CUDA адаптируются для удовлетворения потребности в большей переносимости и взаимодействии, с такими инструментами, какБЕДРОиграть решающую роль в этом переходе.
АVulkan Compute APIтакже набирает обороты в качестве кроссплатформенного решения для вычислений графических процессоров, предлагая производительность и портативность в разных поставщиках оборудования.
Рост языков, специфичных для домена
Языки, специфичные для домена, такие как Triton, делают программирование GPU более доступным для исследователей в таких областях, как машинное обучение, что позволяет им писать эффективный код графического процессора без глубокого опыта в CUDA. Проекты, какТритон-лангиCunemericУпрощают процесс написания оптимизированного кода графического процессора для конкретных доменов.
Интеграция с современными языками программирования
Языки программирования, такие как Юлия, разрабатывают такие пакеты, какAmdgpu.jl, который интегрируется с LLVM и выбирает компоненты стека ROCM, оптимизируя процесс разработки. Подобные усилия можно увидеть сCuda.jlи другие языковые решения для программирования GPU.
Дорожная карта внедрения для разработчиков
Чтобы принять эти парадигмы программирования графических процессоров с открытым исходным кодом:
- Разработка модели:
- Поезд с использованием pytorch/tensorflow с Rocm 6.0+
- Экспорт в формат ONNX для аппаратной абстракции
- Оптимизация:
- Конвертировать модели в FP16 с использованием инструментов квантования времени выполнения ONNX
- Включить автоматическую настройку для целевых архитектур графических процессоров
- Развертывание:
- Модели пакетов с OMI-совместимой документацией
- Использовать DlRover для масштабирования на основе Kubernetes
Заключение
Эволюция программирования GPU от проприетарных решений в различные альтернативы с открытым исходным кодом представляет собой значительный сдвиг в вычислительном ландшафте. Этот переход - это не только технические достижения, но и о создании более инклюзивной, доступной экосистемы, которая способствует инновациям в разных отраслях и приложениях.
Поскольку мы смотрим в будущее, продолжающееся развитие инструментов программирования GPU с открытым исходным кодом, вероятно, будет играть решающую роль в решении вычислительных проблем завтрашнего дня, от моделирования климата и открытия лекарств до искусственного интеллекта и за ее пределами. Принимая разнообразие в подходах и совместном духе с открытым исходным кодом, мы можем обеспечить, чтобы вычисления графических процессоров продолжали продвигать способы, которые приносят пользу наиболее широкому сообществу разработчиков, исследователей и конечных пользователей.
Будущее программирования графических процессоров - это не только более быстрое вычисление, но и о том, чтобы сделать эту вычислительную мощность доступной для всех, кто в ней нуждается, независимо от их ресурсов или конкретных аппаратных сред. Эта демократизация доступа, вызванная инициативами с открытым исходным кодом и различными подходами к программированию, может быть наиболее важным достижением из всех.
Помните, что разнообразие в подходах к программированию GPU не просто полезно для экосистемы - это хорошо для ваших навыков! Изучая различные рамки и языки, вы получите более глубокое понимание принципов программирования графических процессоров и будете лучше подготовлены для выбора правильного инструмента для каждого проекта.
Project Project Project Project LF AI & Data Foundation предоставляет как технические, так и философские рамки для продвижения открытого программирования GPU. От аппаратной абстракции Onnx до оптимизации кластера Dlrover, эти инициативы реализуют основной тезис блога: эта совместная разработка создает более устойчивую, способную и этическую вычислительную инфраструктуру, чем проприетарные альтернативы.
Разработчики могут немедленно взаимодействовать с:
- Onnx Community Meetups
- ОМИ рабочие группы
- Dlrover Hackathons запланировано на конференцию Pytorch 2025
Закрепляя обсуждения программ GPU в этих активных фондах, в блоге сама становятся как техническое руководство, так и дорожную карту экосистемы - выполняя требования к релевантности LF и Data Data, одновременно продвигая стандарты ускорения с открытым исходным кодом.
Счастливого кодирования! 🚀
Примечание автора: я Анат Хейлпер, Архитектура программного обеспечения и систем для ИИ и передовых технологий в Intel. Взгляды и мнения, выраженные в этой статье, являются исключительно моими собственными и не отражают и не подразумевают какие -либо должности или перспективы Intel или любую мою работу в компании.
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Лучшие новогодние подарки для владельцев домашних животных
29 мая 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27342)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Социальные медиа и интернет-культура (107)
- Экономика и финансы (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)