

Мое личное руководство по оконным функциям SQL (часть 2)
23 ноября 2022 г.Впервые представленные как часть стандарта SQ:2003 и доступные в MySQL 8.0, оконные функции в MySQL привлекательны, но их синтаксис также может немного пугать, когда вы впервые начинаете их использовать. Этот пост является вторым в серии, в которой мы обсудим оконные функции, включая разбор синтаксиса и использование примеров различных оконных функций. Все примеры кода в этом посте используют таблицу базы данных и данные, которые мы создали в Часть 1. .
По мере изучения этих примеров мы должны помнить, что большую часть (если не все) этих функций можно реализовать с помощью любого языка программирования. Однако я предпочитаю, чтобы база данных делала то, что у нее получается лучше всего, — извлекала данные и манипулировала ими.
ПримерLAG() и LEAD()
Две оконные функции, которые очень тесно связаны между собой, позволяют нам просматривать строку данных n строк до или n строк после текущей строки. Это LAG() и LEAD() соответственно.
Если мы хотим показать сумму очков текущего игрока, а также предыдущего и следующего игроков, мы должны использовать этот запрос:
SELECT `full_name`,
`group_name`,
RANK() OVER( PARTITION BY `group_name`
ORDER BY `points` DESC
) group_rank,
`points`,
`points` +
LAG( `points`, 1, `points` ) OVER ( PARTITION BY `group_name`
ORDER BY `points` DESC
) with_player_above,
`points` +
LEAD( `points`, 1, `points` ) OVER ( PARTITION BY `group_name`
ORDER BY `points` DESC
) with_player_below
FROM `player`
ORDER BY group_name, group_rank;
Как видите, каждая из этих функций принимает три аргумента:
- Столбец, который мы хотим получить.
- Количество строк, которые мы хотим сместить. В нашем примере мы хотим просмотреть одну строку до и одну после текущей строки, поэтому мы передаем значение
1. - Значение по умолчанию, которое возвращается, если результатом вызова функции является
NULL. Значением по умолчанию может быть жестко заданное значение или имя столбца.
В каждой строке набора результатов мы добавляем значение, возвращенное из LAG() и LEAD(), к текущему значению столбца точек в текущей строке.
На этом изображении показаны результаты вышеуказанного запроса.
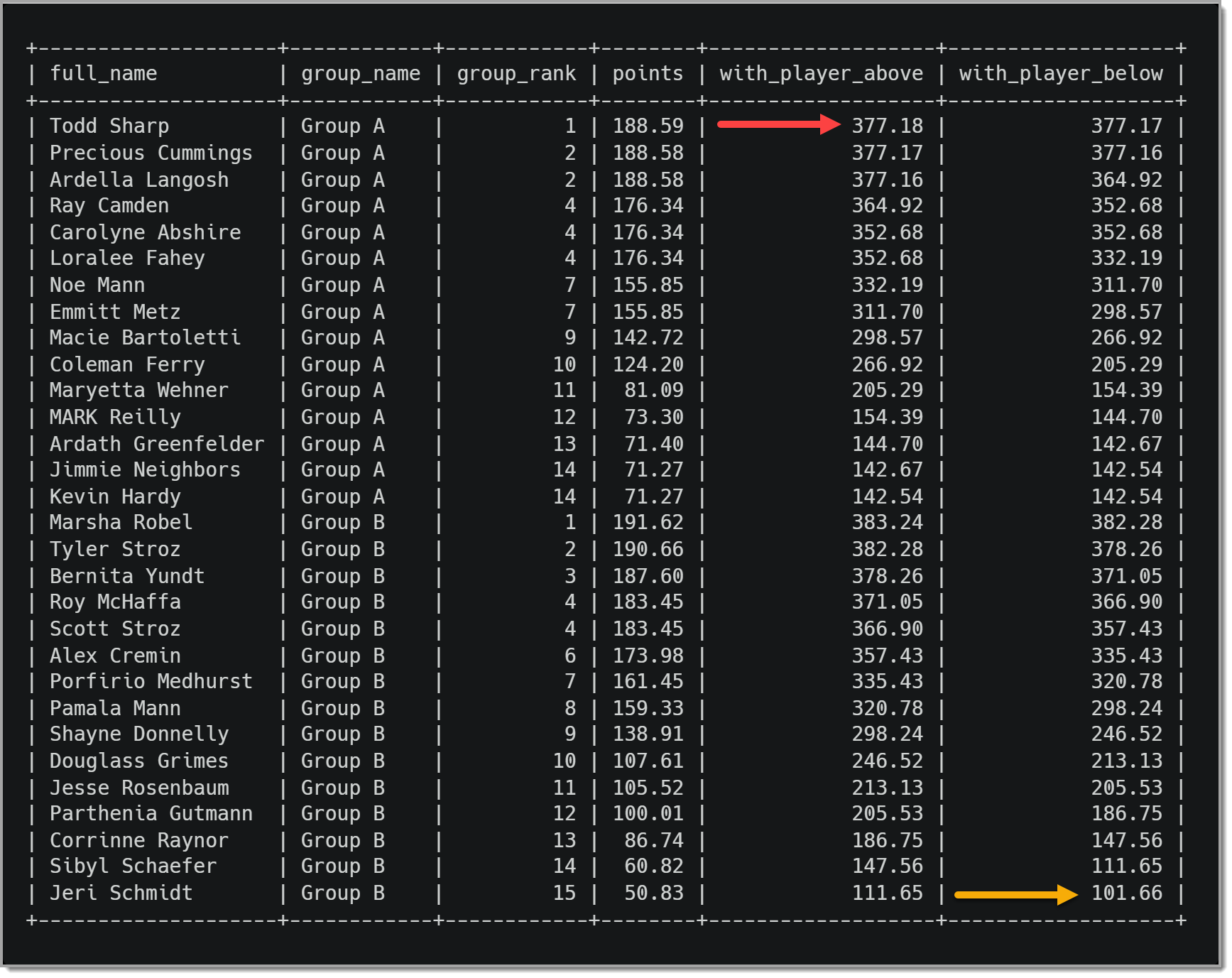
Результаты наших вызовов LAG() и LEAD(), обозначенные красной и желтой стрелками, могут быть интересными. Если бы мы опустили третий аргумент (значение по умолчанию — результат NULL), каждый результат был бы NULL. Так как мы возвращаем значение очков в текущей строке, если результат был NULL, каждый из них представляет собой удвоенное значение очков.
Пример NTILE()
Предположим, что нам нужно разделить игроков на три группы в каждой из наших групп на основе их общего количества очков. Эта подгруппа позволяет нам увидеть, какие игроки находятся в верхней, средней и нижней трети своей группы.
Для этого мы используем функцию NTILE().
SELECT `full_name`,
`points`,
`group_name`,
RANK() OVER( PARTITION BY `group_name`
ORDER BY `points` DESC
) player_group_rank,
NTILE(3) OVER ( PARTITION BY `group_name`
ORDER BY `points` DESC, `full_name`
) ntile_rank
FROM `player`
ORDER BY group_name, player_group_rank, full_name;
Мы передаем в NTILE() единственный аргумент, количество групп, на которые мы хотели бы разбить наши данные. В нашем примере мы используем 3, потому что хотим, чтобы игроки были разделены на три группы.
Когда мы запускаем этот запрос, мы видим результаты, которые выглядят следующим образом:
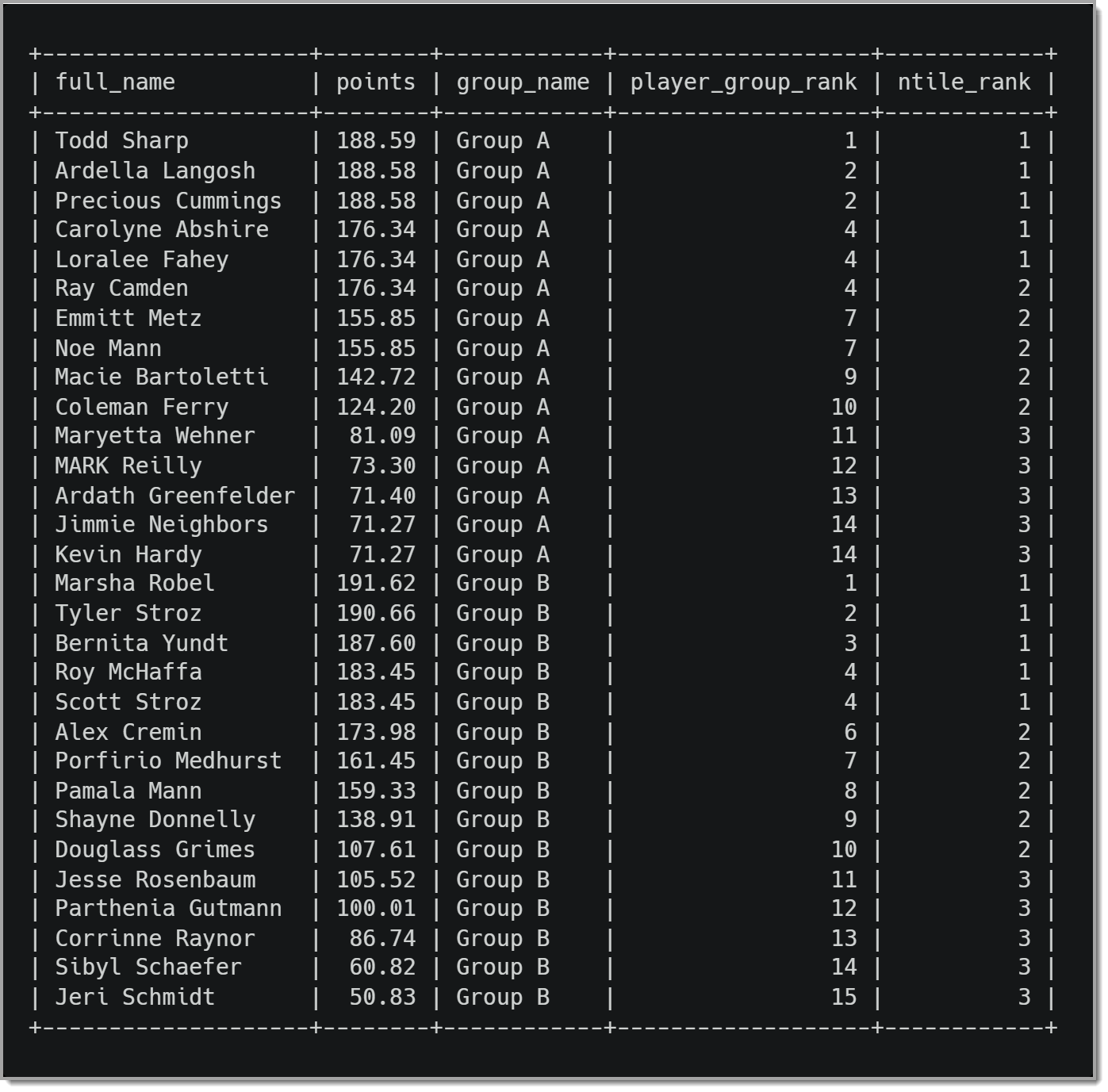
PERCENT_RANK() Пример
В более обширных наборах данных может быть полезно увидеть процентильный ранг каждой строки данных. PERCENT_RANK() рассчитает процент игроков, набравших больше очков, чем текущий игрок.
Мы можем вернуть эту информацию, используя приведенный ниже запрос:
SELECT `full_name`,
`points`,
`group_name`,
RANK() OVER( PARTITION BY `group_name`
ORDER BY `points` DESC
) player_group_rank,
ROUND(
PERCENT_RANK() OVER ( PARTITION BY `group_name`
ORDER BY `points` DESC
) * 100 ,2 ) pct_rank
FROM `player`
ORDER BY group_name, player_group_rank, full_name;
PERCENT_RANK() не принимает никаких аргументов, и чтобы упростить чтение информации, мы умножаем результат на 100, а затем округляем до 2 знаков после запятой.
Результаты этого запроса можно увидеть на изображении ниже.
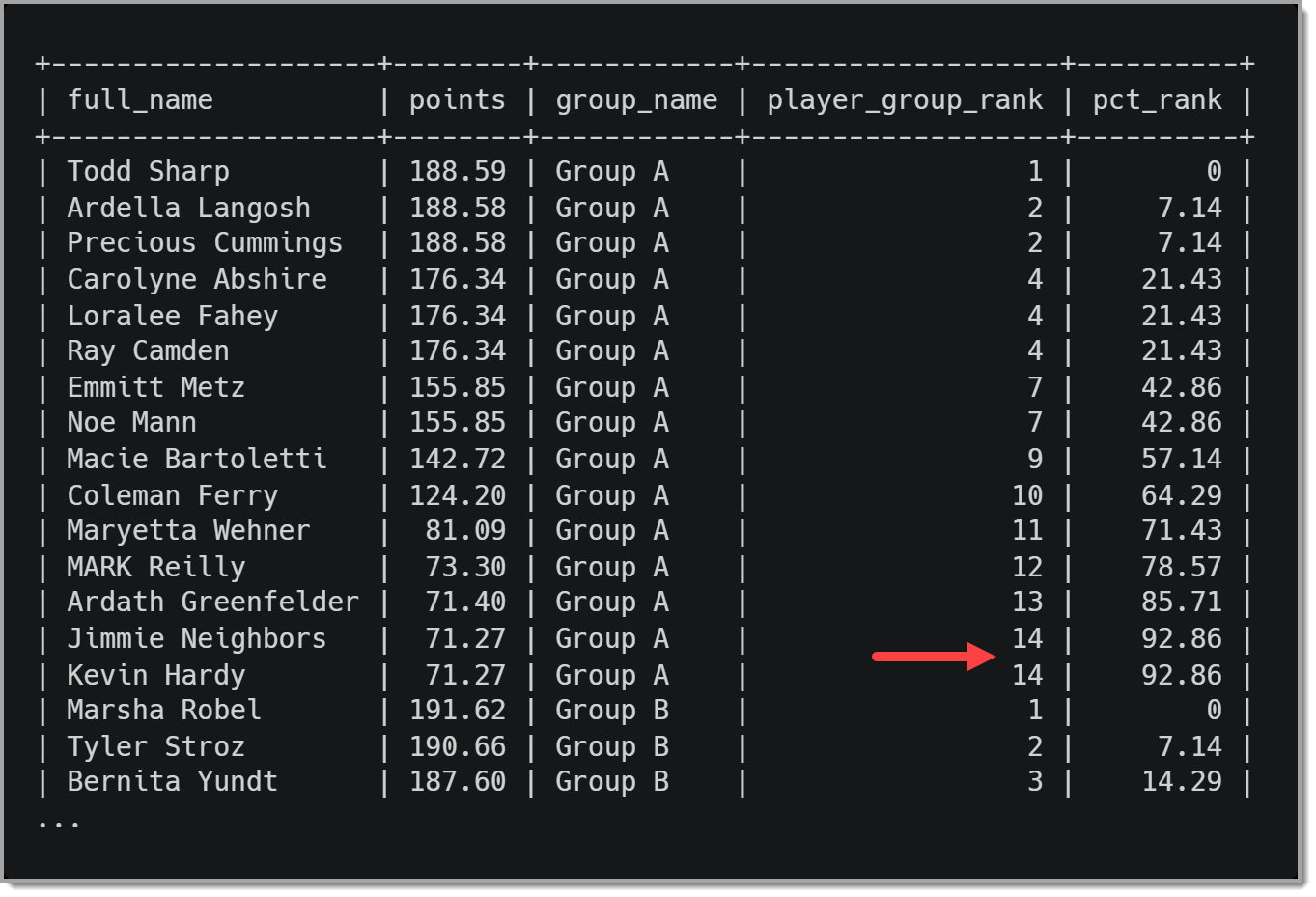
Интересно отметить, что в наборе результатов нет ни одного показателя, при котором 100 % других показателей были бы выше в группе A. Это происходит потому, что Джимми Соседи и Кевин Харди делят последнее место в группе.
Использование SUM() в качестве функции окна
Как я отмечал в Часть 1 этой серии, некоторые совокупные функции можно использовать как оконные, если мы добавим предложение OVER(). Итак, давайте посмотрим, как мы можем это сделать.
Если бы мы хотели показать, какому проценту от общего количества очков группы равны очки данного игрока. Для этого мы могли бы использовать следующий запрос:
SELECT `full_name`,
`points`,
`group_name`,
RANK() OVER( PARTITION BY `group_name`
ORDER BY `points` DESC
) player_group_rank,
ROUND(
(points / SUM(points) OVER ( PARTITION BY `group_name`) * 100), 4
) point_pct
FROM `player`
ORDER BY group_name, player_group_rank, full_name;
Обратите внимание, как мы добавляем предложение OVER() в SUM(), разделяя данные по имени группы. Значение, возвращаемое этим вызовом функции SUM(), возвращает общее количество очков для каждого игрока в группе. Чтобы определить процент данного игрока от общего количества очков, мы делим очки игрока на результат вызова SUM() и умножаем на 100. Затем мы округляем это значение до 4 знаков после запятой.
Результаты этого запроса будут выглядеть примерно так, как показано на рисунке ниже.
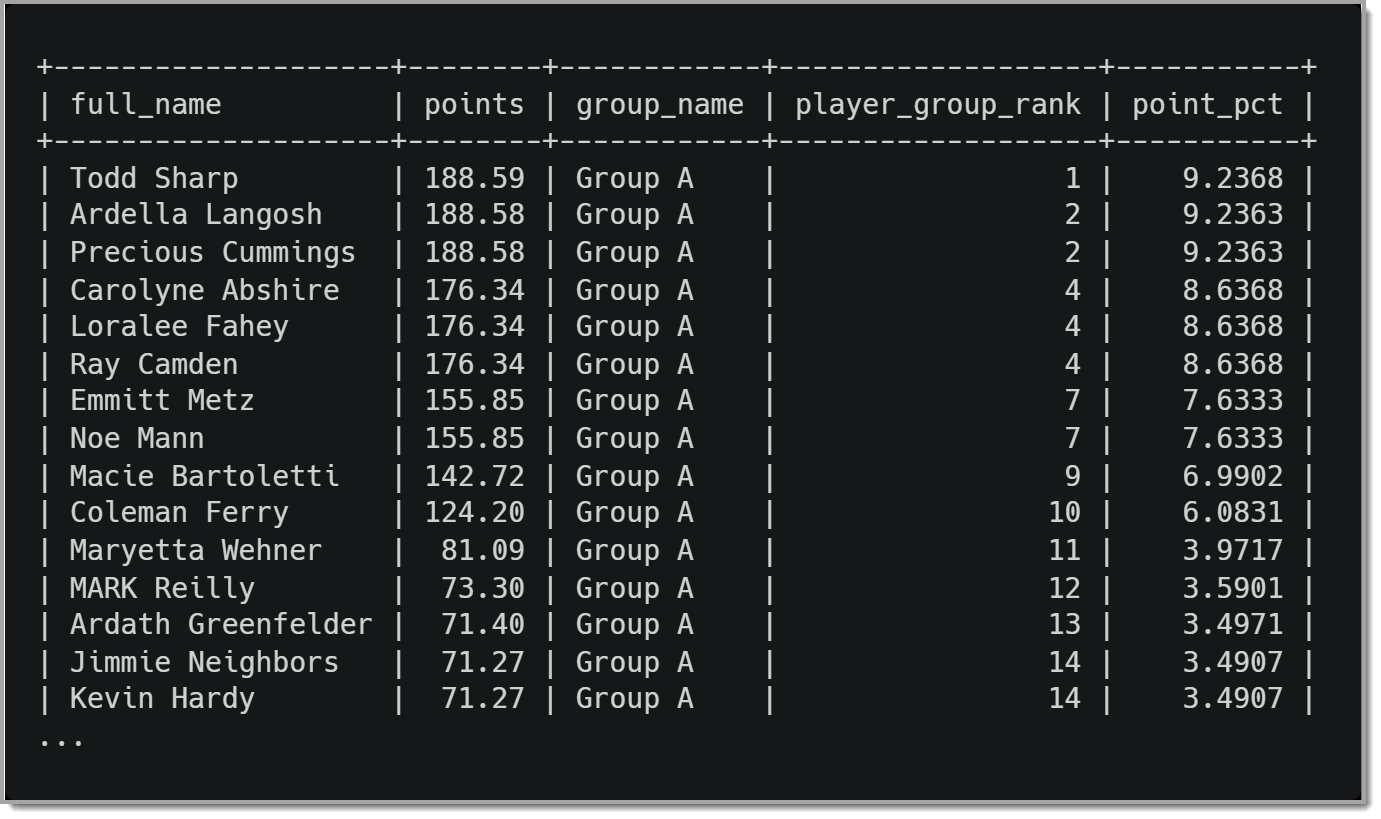
Результаты показывают, что из 15 игроков группы A Тодд Шарп набрал 9,2368% очков. Если вам интересно, я намеренно округлил эти значения до четырех знаков после запятой, чтобы мы могли увидеть разницу между процентным соотношением двух лучших игроков в группе A.
Для получения дополнительной информации об использовании других агрегатных функций в качестве оконных см. Документация MySQl.
Использование оконных рам
Когда мы используем предложение PARTITION BY в оконной функции, мы сообщаем MySQL, как мы хотим сгруппировать данные. С помощью оконных функций мы можем еще более детально определить, какой набор данных мы хотим вернуть. Предложение фрейма обеспечивает такую степень детализации.
Имея дело с предложением фрейма, мы можем ограничить данные, используемые для конкретной оконной функции. Используя предложение фрейма, мы определяем диапазон строк, которые нужно включить в наше подмножество данных. Например, в этом определении мы используем следующее для установки границ нашего фрейма:
UNBOUNDED PRECEDING— каждая строка в разделе, предшествующая текущей строкеUNBOUNDED FOLLOWING— каждая строка в разделе, следующая за текущей строкойn PRECEDING— n количество строк, предшествующих текущей строке.n FOLLOWING– n количество строк, следующих за текущей строкой.CURRENT ROW– текущая строка.
При указании диапазона мы используем начальную и конечную точки. Если диапазон не определен, диапазон по умолчанию выглядит следующим образом:
- Если в оконной функции нет предложения
ORDER BY, используется весь раздел. - Если в оконной функции присутствует предложение
ORDER BY, диапазон равенМЕЖДУ НЕОГРАНИЧЕННОЙ ПРЕДЫДУЩЕЙ И ТЕКУЩЕЙ СТРОКАМИ.
ROWS Пример
При использовании предложения фрейма они могут быть определены двумя разными способами. Во-первых, ROWS определяет, сколько строк нужно включить. Например, если мы хотим использовать только две строки, предшествующие текущей строке, мы можем использовать ROWS 2 PRECEDING в нашем определении. Мы будем использовать RANGE в нашем определении, если мы хотим использовать значение, чтобы определить, сколько строк использовать. Например, если мы хотим ограничить кадр игроками в пределах десяти очков, мы должны использовать RANGE 10 FOLLOWING.
Примером использования ROWS является вычисление промежуточной суммы, возвращаемой каждым игроком. Запрос для этого будет таким:
SELECT `full_name`,
`points`,
`group_name`,
RANK() OVER( PARTITION BY `group_name`
ORDER BY `points` DESC
) player_group_rank,
SUM( points ) OVER ( PARTITION BY `group_name`
ORDER BY `points` DESC
ROWS UNBOUNDED PRECEDING
) running_total
FROM `player`
ORDER BY group_name, player_group_rank;
Обратите внимание, что мы используем только начальную точку для оконной рамы. В этом случае конечной точкой является CURRENT ROW. Наш вызов SUM() добавляет точки в текущей строке и каждой предыдущей строке в разделе.
Результаты для этого запроса будут похожи на изображение ниже.
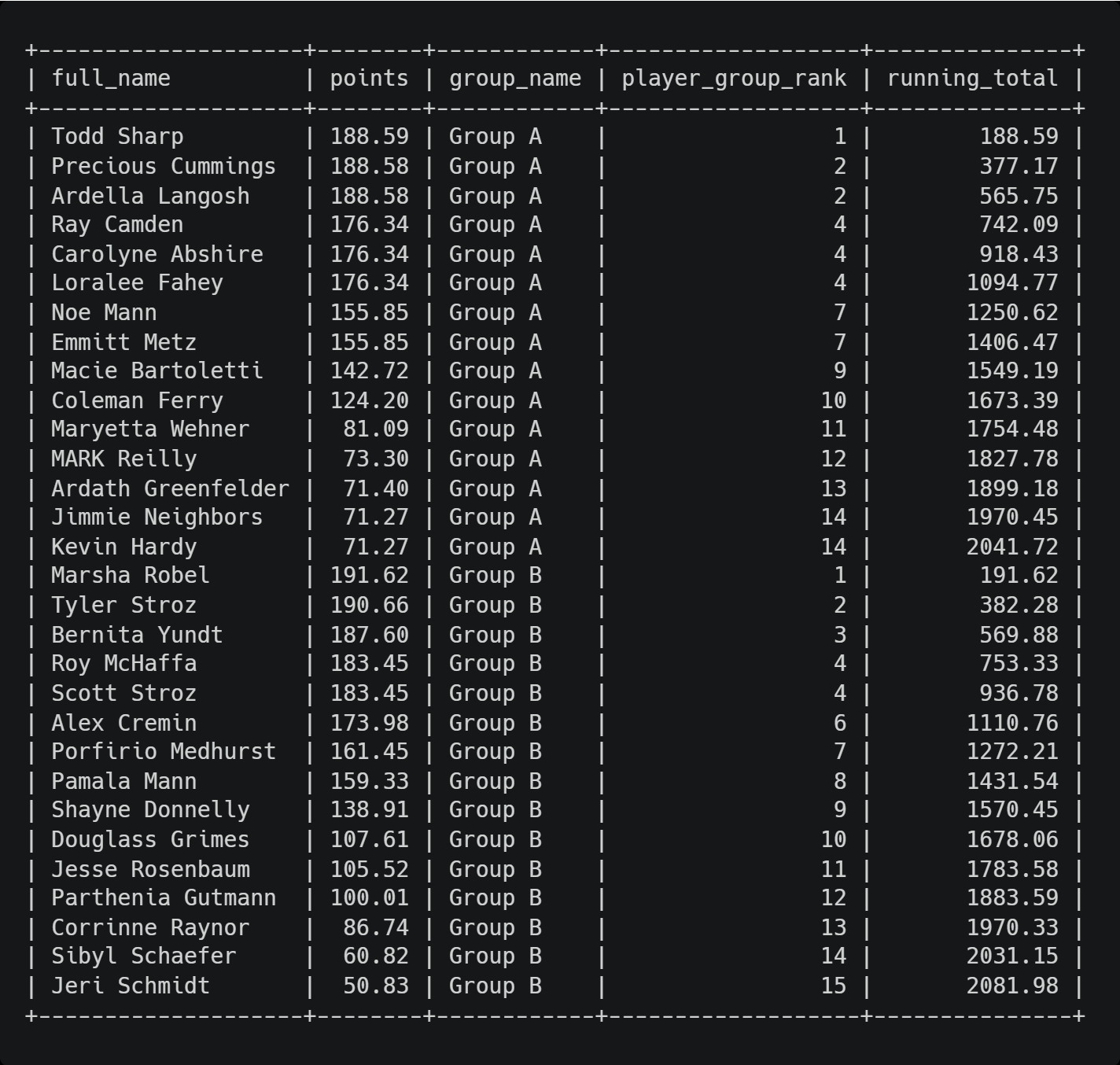
На изображении выше показано, что промежуточный итог перезапускается при запуске новой группы. Таким образом, если бы мы хотели сделать промежуточный итог для всех игроков, мы бы удалили раздел в нашем вызове SUM().
Пример RANGE
Использовать ROWS как часть оконного фрейма очень просто. Однако RANGE немного сложнее. Когда мы используем RANGE, мы извлекаем все строки, где значение соответствует критериям. Мы могли бы использовать разное количество строк в оконной функции для каждой строки в результирующем наборе.
Ниже приведен запрос, который вернет, сколько игроков отстает от текущего игрока на десять или менее очков.
SELECT `full_name`,
`points`,
`group_name`,
RANK() OVER( PARTITION BY `group_name`
ORDER BY `points` DESC
) player_group_rank,
COUNT( * ) OVER ( PARTITION BY `group_name`
ORDER BY `points` DESC
RANGE BETWEEN CURRENT ROW AND 10 FOLLOWING
) - 1 within_ten_points
FROM `player`
ORDER BY group_name, player_group_rank;
В этом примере мы используем COUNT() в качестве оконной функции. Если вы посмотрите на рамку окна, вы увидите, что наш диапазон — это значение в пунктах текущей строки до любой строки в пределах 10 пунктов от этого значения. Мы вычитаем из результата единицу, потому что это определение диапазона будет включать текущую строку, а мы не хотим включать текущего игрока в наш подсчет.
Результаты этого запроса будут выглядеть следующим образом:
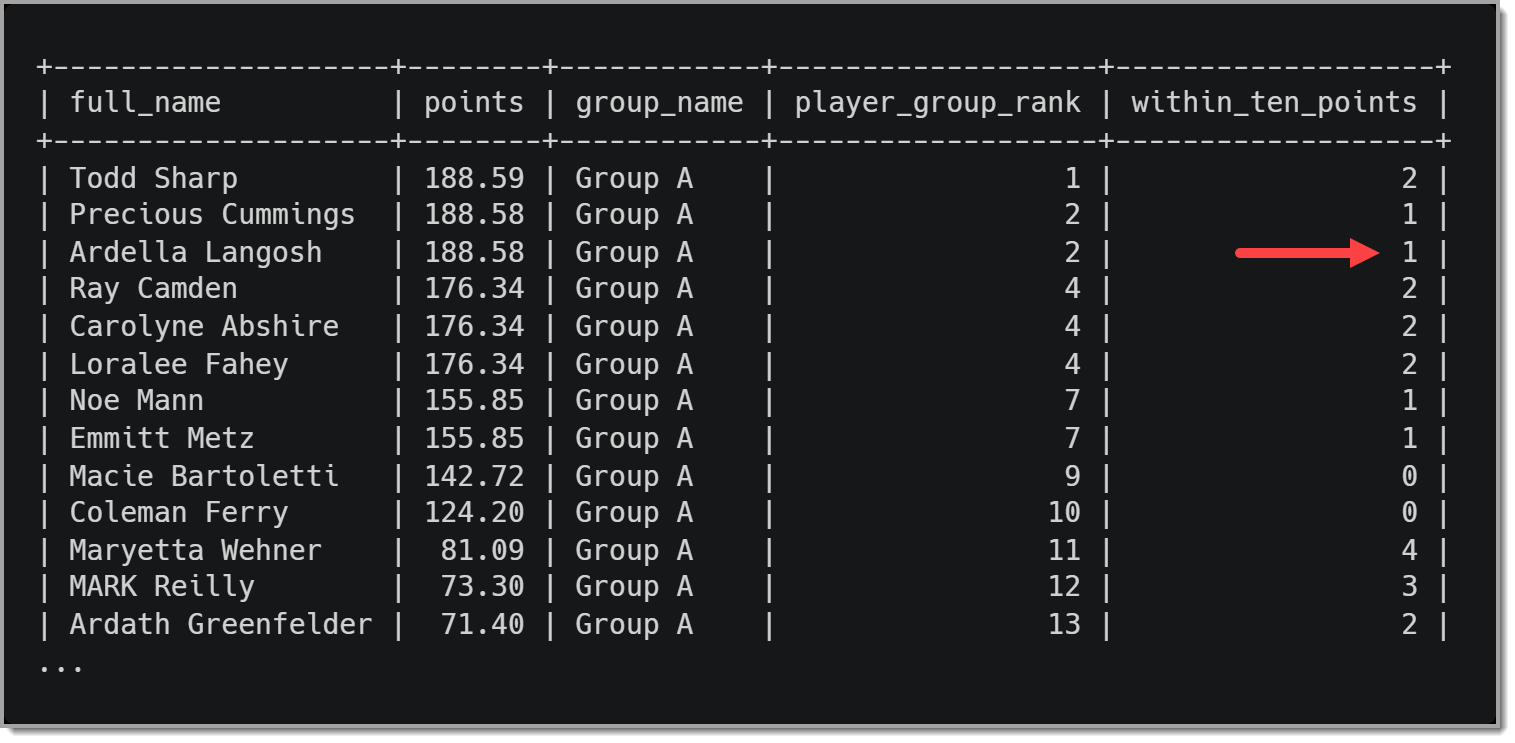
Интересно, что Арделла показывает, что один игрок находится в пределах десяти очков, но игрок, находящийся ниже нее в турнирной таблице, отстает более чем на десять очков. Это связано с тем, что Арделла и Прешес Каммингс равны, поэтому в этом расчете используются очки Драгоценности.
Важно отметить, что мы можем использовать RANGE только для значений в ORDER BY, которые являются числами или датами. Так, например, мы не могли бы использовать RANGE, если предложение ORDER BY в COUNT() использовало full_name.
Подведение итогов
Хотя функциональность оконных функций может быть воспроизведена на любом языке программирования, их использование для возврата данных непосредственно из базы данных может немного облегчить работу разработчиков. Синтаксис оконных функций может показаться немного сложным, но его разбивка на отдельные части может облегчить чтение и понимание. Я надеюсь, что эта серия поможет вам справиться с этой проблемой.
Ознакомьтесь с документацией, чтобы узнать больше об оконных функциях.
Также опубликовано здесь
Главное изображение: Вальдемар Брандт.< /эм>
Оригинал
🔥 Популярное на этой неделе
-
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27222)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)