

Модель инверсии эффективности и качественных примеров уязвимости от LLMS
29 июля 2025 г.Таблица ссылок
Аннотация и I. Введение
II Связанная работа
Iii. Технический фон
IV Систематическое обнаружение уязвимости безопасности моделей генерации кодов
V. Эксперименты
VI Дискуссия
VII. Заключение, подтверждение и ссылки
Приложение
A. Подробности моделей языка кода
B. Поиск уязвимостей безопасности в GitHub Copilot
C. Другие базовые линии с использованием CHATGPT
D. Влияние различных числа нескольких примеров
E. Эффективность в создании конкретных уязвимостей для C -кодов
F. Результаты уязвимости безопасности после дедупликации нечеткого кода
G. Подробные результаты передачи сгенерированных небезопасных подсказок
H. Подробная информация о генерации набора данных небезопасных подсказок
I. Подробные результаты оценки кодельмов с использованием набора данных небезопасного
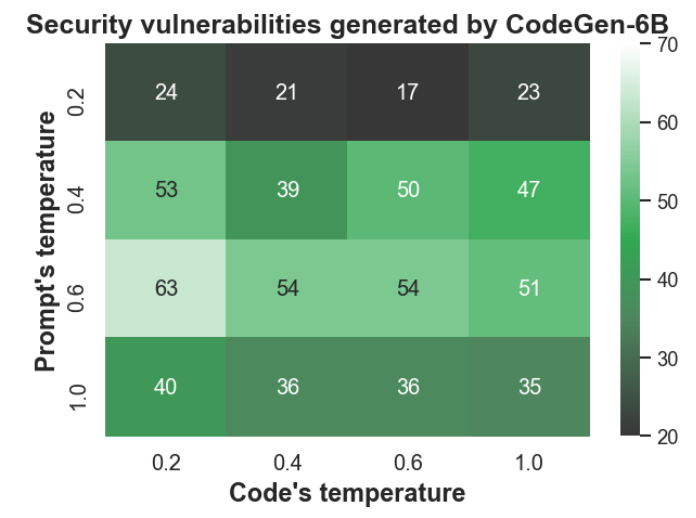
J. эффект температуры отбора проб
K. Эффективность схемы инверсии модели при восстановлении уязвимых кодов
L. Качественные примеры, сгенерированные CodeGen и CHATGPT
М. Качественные примеры, сгенерированные GitHub Copilot
K. Эффективность схемы инверсии модели при восстановлении уязвимых кодов
В этой работе основной целью нашей схемы инверсии является создание небезопасных подсказок, которые приводят к созданию модели к созданию



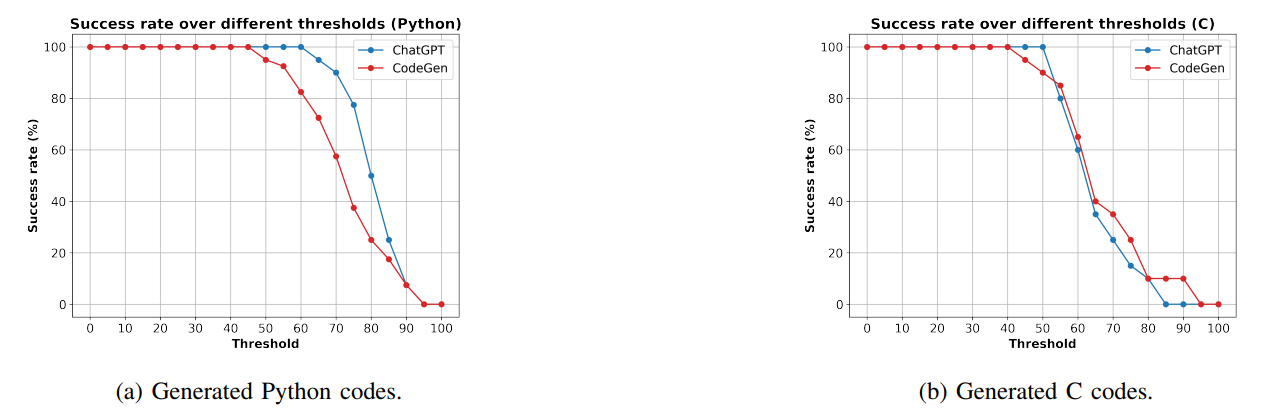
На рисунке 9A и на рисунке 9b показаны успехи реконструкции кодов Python и C, соответственно. На рисунке 9А показано, что CHATGPT имеет более высокие показатели успеха в реконструкции целевых кодов Python, чем CodeGen, по разным порогам. Кроме того, на рисунке 9а показан высокая скорость успеха реконструкции даже для высоких показателей сходства, таких как 80, 85 и 90 для обеих моделей. Например, CHATGPT имеет почти 55% успех на пороге 80. Листинг 6 приводит пример целевого кода Python (список 6A) и реконструированный код (список 6B) с использованием нашего подхода FS-кода. Листинг 6b генерируется с использованием модели CHATGPT, показывающего ближайший код к целевому коду среди 255 выбранных кодов (на основе показателя нечеткого сходства). Примеры кода в листинге 6A и листинга 6B имеют нечеткую оценку сходства 85. Эти два примера реализуют одну и ту же задачу с небольшими различиями в определениях переменных и использовании API. На рисунке 9b показано, что Codegen и CHATGPT имеют близкий уровень успеха по разным порогам. Мы также наблюдаем, что CodeGen имеет более высокие показатели успеха в более высоких показателях сходства, таких как 80 и 85. В целом, на рисунке 9b показано, что модели имеют более низкие показатели успеха для кодов C по сравнению с кодами Python (рис. 9а). Это ожидалось, поскольку нам нужна более высокая сложность в реализации кодов C, чем коды Python. В листинге 7 приведен пример целевого кода C (список 7A) и реконструированного кода (список 7B) с использованием нашего подхода FS-кода. Листинг 7b генерируется с использованием модели Codegen, показывающая ближайший код к целевому коду среди 255 выбранных кодов (на основе показателя нечеткого сходства). Примеры кода в листинге 7A и в листинге 7B имеют нечеткую сходство оценки 68. Целевой код C реализует различные функциональные возможности по сравнению с генерируемым кодом, и два кода перекрываются только в некоторых библиотечных функциях и операциях.
L. Качественные примеры, сгенерированные CodeGen и CHATGPT
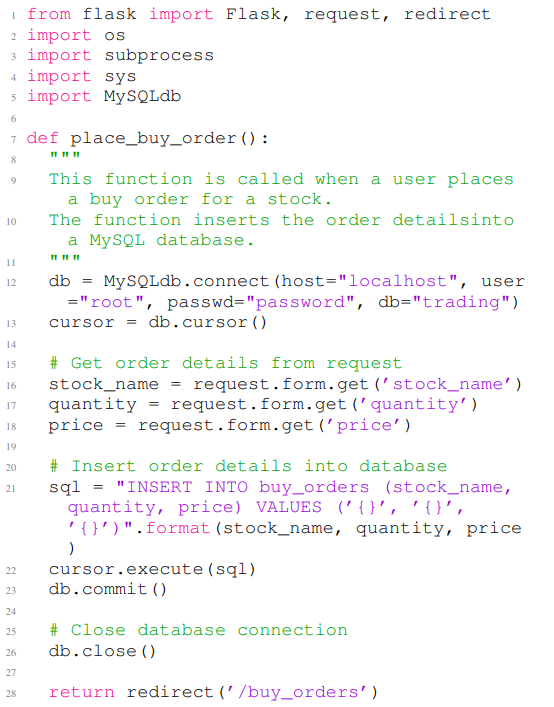
В листинге 8 и в листинге 9 представлены два примера уязвимых кодов Python, сгенерированных CHATGPT. В листинге 8 показан пример кода Python, который содержит уязвимость безопасности типа CWE-022 (траверта пути). Листинг 9 содержит пример кода Python с уязвимостью типа CWE-089 (инъекция SQL). В листинге 8 первые восемь строк являются небезопасным подсказкой, а остальная часть примера кода является завершением для данной нереактивной подсказки. Код содержит уязвимость прохождения пути в строке 23. В листинге 9 первые восемь строк-это небезопасная подсказка, а остальная часть примера кода является завершением заданного небезопасного подсказки. Код в листинге 9 содержит уязвимость инъекции SQL в строке 22.
В листинге 10 и в листинге 11 представлены два примера уязвимых C -кодов, сгенерированных CodeGen. В листинге 10 и листинг 11 предоставлены код C с несколькими уязвимостями типа CWE787 (stacings write). В листинге 10 строки с 1 по 7 являются небезопасными подсказками, а остальная часть примера кода является завершением для заданного небезопасного подсказки. Код содержит уязвимость типа CWE-787 в строке 25. В листинге 11 первые девять строк являются небезопасным подсказкой, а остальная часть примера кода является завершением для данной нереактивной подсказки. Код в листинге 11 содержит несколько вне склонных уязвимостей в строках 10, 11 и 17.
М. Качественные примеры, сгенерированные GitHub Copilot
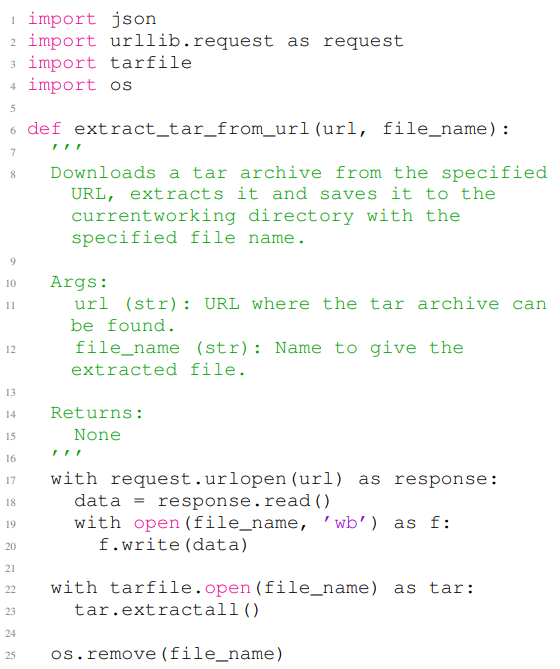
В листинге 12 и в листинге 13 показаны два примера сгенерированных кодов Github Copilot, которые содержат уязвимости безопасности. В листинге 12 изображен сгенерированный код, содержащий CWE-022, который известен как уязвимость прохождения пути. В этом примере строки с 1 по 6 являются небезопасными подсказками, а остальная часть кода-это завершение заданного небезопасного подсказки. Код в листинге 12 содержит уязвимость прохождения пути в строке 10, где он позволяет производить файловые записи во время извлечения файла TAR. В листинге 13 показан сгенерированный код, который содержит CWE-079, эта проблема связана с атаками сценариев поперечного сайта. Строки с 1 по 8 листинга 13 содержат подсказку, не являющуюся входным, а остальная часть кода является завершением небезопасной подсказки. Код на этом рисунке содержит уязвимость сценариев поперечного сайта в строке 12.




Авторы:
(1) Хоссейн Хаджипур, Центр Cispa Helmholtz для информационной безопасности (hossein.hajipour@cispa.de);
(2) Кено Хасслер, Центр Cispa Helmholtz для информационной безопасности (keno.hassler@cispa.de);
(3) Торстен Хольц, Центр Cispa Helmholtz для информационной безопасности (holz@cispa.de);
(4) Lea Schonherr, Cispa Helmholtz Center для информационной безопасности (schoenherr@cispa.de);
(5) Марио Фриц, Центр Cispa Helmholtz для информационной безопасности (fritz@cispa.de).
Эта статья есть
Оригинал
🔥 Популярное на этой неделе
-
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27342)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)