

Объединение аудио ввода и текстовых инструкций в одну унифицированную модель
20 июня 2025 г.Таблица ссылок
Аннотация и 1 введение
2 подхода
2.1 Архитектура
2.2 Multimodal Trancing Paneletuning
2.3 Учебное обучение программы с эффективным характеристиком параметров
3 эксперименты
4 Результаты
4.1 Оценка моделей речи.
4.2 Обобщение между инструкциями
4.3 Стратегии повышения производительности
5 Связанная работа
6 Заключение, ограничения, заявление о этике и ссылки
Приложение
A.1 Audio Encoder перед тренировкой
A.2 Гиперпараметры
A.3 Задачи
5 Связанная работа
Многозадачное обучение.Предыдущие исследования показали, что одна модель глубокого обучения способна совместно изучать несколько крупномасштабных задач в разных областях [42]. Ключевая идея в обучении с несколькими задачами заключается в том, чтобы использовать общие представления по соответствующим задачам для повышения общего обобщения и эффективности. После этого подхода модель T5 [43] создает все текстовые задачи в качестве текста в указании, используя унифицированную текстовую структуру, которая облегчает общие представления по текстовым задачам. Аналогичным образом, SpeechNet [44] и SpeechT5 [19] используют общую структуру энкодера-декодера для совместных моделей речевых и текстовых методов, охватывающих 5-6 задач, такие как TTS, ASR и преобразование голоса (VC). Виола [15], единственная сеть автоматического регрессивного трансформатора только для декодеров, объединяет различные межмодальные речевые и текстовые задачи в виде модели языка условного кодека с помощью многозадачного обучения. Whisper [20] также использует крупномасштабное многозадачное обучение, обучение соответствующим речевым задачам, включая идентификацию языка, распознавание речи и перевод. В этой работе Speechverse использует многозадачную
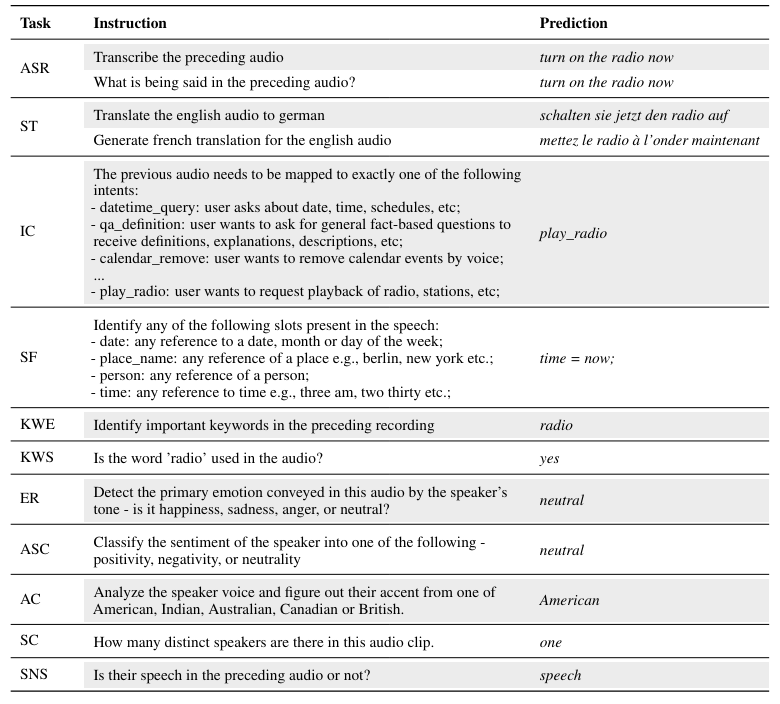
Обучение для передачи знаний между несколькими связанными задачами при использовании инструкций естественного языка для выполнения каждой задачи. В отличие от предыдущей работы, которая сгенерировала текст, речь или оба, наш метод фокусируется исключительно на производстве текстовых выводов, одновременно принимая аудио и текстовые инструкции.
Мультимодальные большие языковые модели.Предыдущая работа по мультимодальной LLMS была сосредоточена главным образом на задачах с участием изображений, таких как генерация изображений, ответ на визуальные вопросы и подписание изображений [4, 9, 45, 46]. Мультимодальные модели, включающие методы, такие как аудио и речь, получили относительно меньшее внимание по сравнению с моделями зрения и языка [47–49]. Тем не менее, растут интерес к увеличению больших языковых моделей с аудиобатными, что приводит к нескольким предлагаемым подходам [8, 14, 17, 18, 50–52]. Речигпт [18] предложил мультимодальную LLM, объединяющую дискретные единицы Хьюберта с LLM, чтобы решить несколько понимающих задач, таких как ASR, разговорный QA, а также задачи поколения, такие как TTS. [17] представляет новые возможности с нулевым выстрелом, посвященным более разнообразным задачам, таким как генерация диалогов, продолжение речи и ответ на вопросы. Совсем недавно [16] предложили Qwen-Audio, крупномасштабную аудиоязычную модель, обученную с использованием многозадачного подхода к обучению для выполнения разнообразных задач по различным типам аудио, включая человеческие речи, естественные звуки, музыку и песни. Qwen-Audio использует единый аудиокодер для обработки различных типов аудио, инициализация которых основана на модели Whisper-Large-V2 [20] и выполняет полное создание. Напротив, наша работа использует две замороженные модели, предварительно предварительную, по одной для речевого кодера и текстового декодера, чтобы сохранить свои внутренние сильные стороны. Кроме того, мы используем более 30 инструкций для каждой задачи во время обучения для улучшения обобщения, тогда как [17] использует единую фиксированную инструкцию. Кроме того, Speechverse включает в себя многозадачное обучение и создание обучения на одном этапе обучения.
Авторы:
(1) Nilaksh Das, AWS AI Labs, Amazon и равный вклад;
(2) Saket Dingliwal, AWS AI Labs, Amazon (skdin@amazon.com);
(3) Шрикант Ронанки, AWS AI Labs, Amazon;
(4) Рохит Патури, AWS AI Labs, Amazon;
(5) Zhaocheng Huang, AWS AI Labs, Amazon;
(6) Prashant Mathur, AWS AI Labs, Amazon;
(7) Цзе Юань, AWS AI Labs, Amazon;
(8) Дхануш Бекал, AWS AI Labs, Amazon;
(9) Син Ниу, AWS AI Labs, Amazon;
(10) Sai Muralidhar Jayanthi, AWS AI Labs, Amazon;
(11) Xilai Li, AWS AI Labs, Amazon;
(12) Карел Мунднич, AWS AI Labs, Amazon;
(13) Моника Сункара, AWS AI Labs, Amazon;
(14) Даниэль Гарсия-Ромеро, AWS AI Labs, Amazon;
(15) Кю Дж. Хан, AWS AI Labs, Amazon;
(16) Катрин Кирххофф, AWS AI Labs, Amazon.
Эта статья есть
Оригинал
🔥 Популярное на этой неделе
-
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27352)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)