
Локализация текста в 3D без данных о земле.
16 июля 2025 г.Авторы:
(1) Lichao Wang, FNII, Cuhksz (wanglichao1999@outlook.com);
(2) Zhihao Yuan, FNII и SSE, Cuhksz (zhihaoyuan@link.cuhk.edu.cn);
(3) Jinke Ren, FNII и SSE, Cuhksz (jinkeren@cuhk.edu.cn);
(4) Shuguang Cui, SSE и FNII, Cuhksz (shuguangcui@cuhk.edu.cn);
(5) Чжэнь Ли, автор -соответствующий автор из SSE и FNII, Cuhksz (lizhen@cuhk.edu.cn).
Таблица ссылок
Аннотация и 1. Введение
Связанная работа
Метод
3.1 Обзор нашего метода
3.2 грубое извлечение текстовых клеток
3.3 Оценка прекрасной позиции
3.4 Цели обучения
Эксперименты
4.1 Описание набора данных и 4.2 Подробная информация
4.3 Критерии оценки и 4.4 результаты
Анализ производительности
5.1 Исследование абляции
5.2 Качественный анализ
5.3 Анализ встраивания текста
Заключение и ссылки
Дополнительный материал
- Подробная информация о наборе данных Kitti360
- Больше экспериментов по экстрактору запроса экземпляра
- Анализ космического пространства текстовых клеток
- Больше результатов визуализации
- Анализ устойчивости точек
Анонимные авторы
- Подробная информация о наборе данных Kitti360
- Больше экспериментов по экстрактору запроса экземпляра
- Анализ космического пространства текстовых клеток
- Больше результатов визуализации
- Анализ устойчивости точек
АБСТРАКТНЫЙ
Поперечная модальная локализация текста-точка облака-это новая задача на языке зрения, критическая для будущего сотрудничества робота-мужья. Он стремится локализовать позицию из городской облачной сцены, основанной на нескольких инструкциях по естественному языку. В этой статье мы рассматриваем два ключевых ограничения существующих подходов: 1) их зависимость от экземпляров-территории земли в качестве входных данных; и 2) их пренебрежение относительными позициями среди потенциальных экземпляров. Наша предлагаемая модель следует двухэтапному трубопроводу, включая грубую стадию для поиска текстовых клеток и прекрасную стадию оценки позиции. На обоих этапах мы вводим экстрактор запроса экземпляра, в котором ячейки кодируются 3D-разреженной сверткой U-Net для генерации многомасштабных облачных функций точек, и набор запросов, итеративно посещающих эти функции для представления экземпляров. На грубых этапах модуль самоупрекающего положения (ROWCOLRPA) относительно ареста (ROWCOLRPA) предназначен для захвата пространственных отношений между запросами экземпляра. На прекрасной стадии разработан многомодальный модуль относительного относительного положения (RPCA), чтобы объединить функции текста и облака точек наряду с пространственными отношениями для улучшения оценки мелкого положения. Результаты эксперимента на наборе данных Kitti360.secte демонстрируют, что наша модель достигает конкурентной работы с современными моделями, не принимая экземпляры с неверной землей в качестве ввода.
1 Введение
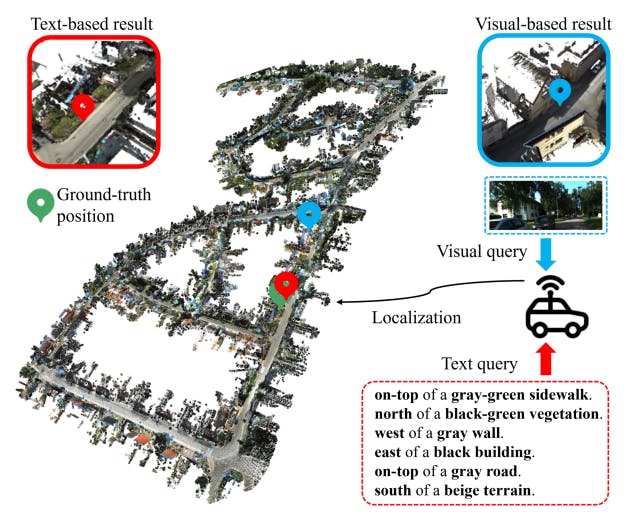
Локализация текста-точка облака имеет решающее значение для автономных агентов. Для эффективной навигации и выполнения задач будущие автономные системы, такие как транспортные средства для самостоятельного вождения и беспилотники доставки, потребуют сотрудничества и координации с людьми, что требует способности планировать маршруты и действия на основе вклада человека. Традиционно мобильные агенты используют методы визуальной локализации [2, 52] для определения позиций в карте, сопоставляя захваченные изображения/точечные облака против баз данных изображений/карт облака точек [2, 16, 34, 43]. Тем не менее, визуальный ввод не является наиболее эффективным способом для людей взаимодействовать с автономными агентами [19]. С другой стороны, использование описания естественного языка повышает эффективность передачи точек посадки или доставки автономным агентам, как показано на рис. 1. Более того, подход текста-точка облака обеспечивает большую надежность по сравнению с системами GPS [46]. Системы GPS борются в областях, скрытых высокими зданиями или густой листвой.
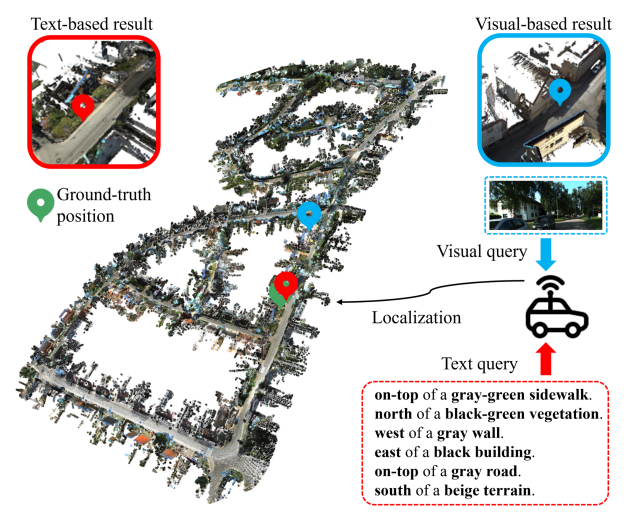
Напротив, Point Cloud - это геометрически стабильные данные, предоставляющие надежные возможности локализации, несмотря на изменения окружающей среды.
Чтобы точно интерпретировать описания языка и семантически понимать облака точек города, пионерская работа, Text2pos [21], сначала делят общегородское облако точек на ячейки и выполняет задачу, используя грубый к свежевому подходу. Тем не менее, этот метод описывает ячейку, основанную только на ее экземплярах, игнорируя отношения с экземплярами и подсказки. Для решения этого недостатка предлагается сеть усиленных трансформаторов (RET) [39]. RET захватывает подсказки и отношения экземпляров, а затем использует перекрестные атмосферы, чтобы объединить функции экземпляров в функции подсказки для оценки позиции. Тем не менее, RET только включает в себя отношения экземпляров на грубой стадии, и дизайн внимания с повышенным отношением может потерять важную информацию относительного положения. Совсем недавно Text2LOC [42] использует предварительно обученную модель языка T5 [32] с иерархическим трансформатором для захвата контекстуальных признаков по подсказкам, и предлагает модель без подходящей регрессии для смягчения шумного сопоставления на мелкой стадии. Кроме того, он использует контрастное обучение, чтобы сбалансировать положительные и отрицательные пара текстовых клеток. Тем не менее, все текущие подходы полагаются на экземпляры-территории земли в качестве входных данных, которые дорогим для получения в новых сценариях. В то время как модель сегментации экземпляра может быть принята в качестве предыдущего шага для обеспечения экземпляров, этот трубопровод страдает от распространения ошибок и увеличения времени вывода, что значительно ухудшает его эффективность. Кроме того, текущие работы не полностью используют относительную информацию о положении потенциальных экземпляров, что имеет решающее значение, учитывая, что направления между позицией и окружающими экземплярами часто появляются в текстовых описаниях.
Чтобы решить вышеупомянутые проблемы, мы предлагаем экстрактор запроса экземпляра, который принимает необработанное облако точки и набор запросов в качестве входных данных и выводит изысканные резервы с помощью семантической информации экземпляра. Чтобы получить пространственные отношения, вводится модуль маски для генерации масок экземпляра соответствующих запросов. На грубых этапах, который используется для получения глобальной информации о примечании к инстанции, относительно склонной к положению, для получения глобальной информации о запросах экземпляра с пространственными отношениями. Впоследствии, для получения функции ячейки используется максимальный слой. На прекрасной стадии запросы экземпляра подвергаются перекрестному взаимодействию с учетом положения (RPCA), чтобы объединить мультимодальные функции с относительной информацией о положении, которая эффективно использует пространственные отношения и контекстную информацию как из облака точек, так и из модальности языка. Используя экстрактор запроса экземпляра и механизмы относительного внимания с учетом положения, наш метод рассматривает два ограничения, включая зависимость от экземпляра Groundtruth в качестве ввода и неспособность захватить информацию относительного положения.
Подводя итог, основной вклад этой работы заключается в следующем:
• Мы предлагаем модель локализации текста-тклауд (IFRP-T2P), которая применяет модели с относительным условием, ориентированным на положение, которая принимает запросы экземпляров для представления потенциальных экземпляров в ячейках, таким образом, удаляя зависимость от экземпляров с неверной землей в качестве входных данных.
• Мы разрабатываем модуль Rowcolrpa на грубой стадии и модуль RPCA на тонкой стадии, чтобы полностью использовать информацию о пространственных отношениях потенциальных экземпляров.
• Мы проводим обширные эксперименты на наборе данных Kitti360 [21] и показываем, что наша модель достигает сопоставимой производительности с современными моделями без использования экземпляров с землей в качестве ввода.
Эта статья есть
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Лучшие новогодние подарки для владельцев домашних животных
29 мая 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27328)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)