
Ключевые проблемы в исследованиях OCR и будущих направлениях
20 августа 2025 г.Таблица ссылок
Аннотация и 1. Введение
1.1 Печатная станка в Ираке и Иракском Курдистане
1.2 Проблемы в исторических документах
1.3 Курдский язык
Связанная работа и 2,1 арабского/персидского
2.2 Китайский/японский и 2,3 коптса
2.4 Греческий
2.5 латынь
2.6 Tamizhi
Метод и 3.1 Сбор данных
3.2 Подготовка данных и 3.3 Предварительная обработка
3.4 Настройка среды, 3,5 подготовка набора данных и 3,6 Оценка
Эксперименты, результаты и обсуждение и 4.1 обработанные данные
4.2 Набор данных и 4.3 эксперименты
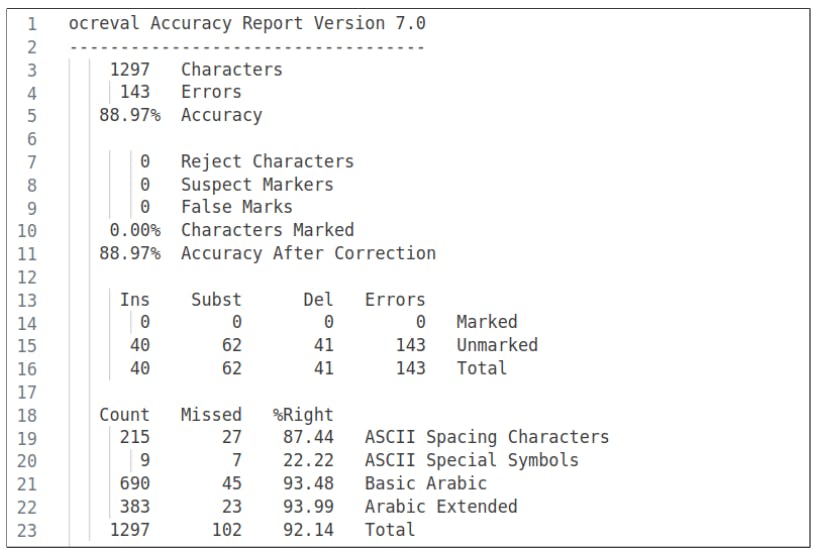
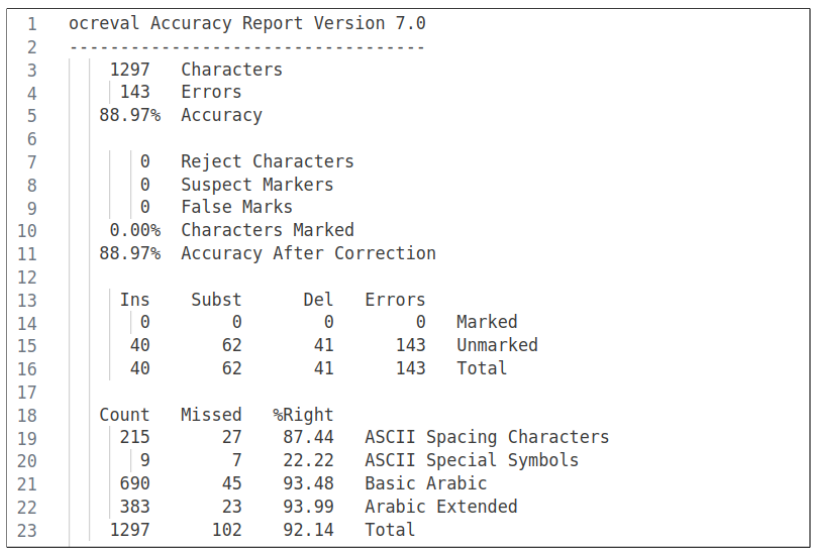
4.4 Результаты и оценка
4.5 Обсуждение
Заключение
5.1 Проблемы и ограничения
Онлайн -ресурсы, подтверждения и ссылки
5.1 Проблемы и ограничения
Ниже приведен список основных проблем и ограничений, с которыми мы столкнулись во время этого исследования:
• Ограниченная доступность ресурсов предложила значительные проблемы во время нашего сбора данных
процесс. Преобразование собранных данных в цифровой формат оказалась дополнительным препятствием. Ручная транскрипция документов была трудной из-за неясного текста, нестандартного интервала и уникального словаря под влиянием арабских букв и терминологий. Мы попытались синтетически создать набор данных, создавая небольшой инструмент, который собирал буквы из данной коллекции изображений символов. К сожалению, результаты были неудовлетворительными, и, учитывая наши временные ограничения, мы прекратили этот подход.
• Нестандартное расстояние между словами и персонажами было сложным для транскрибирования документов и должно было быть более очевидным для модели. Модель интерпретировала чрезмерные разрывы между символами или словами как космические символы. Напротив, в других случаях, когда должен был быть космический характер, минимальный интервал остался незамеченным моделью.
• Извлечение текста со страниц с несколькими колоннами стала еще одним ограничением модели.
• Признание математических уравнений было еще одним ограничением нашей модели.
Учитывая проблемы и ограничения и основываясь на обсуждении результатов, мы заинтересованы в изучении нескольких областей в будущем следующим образом:
• Расширение набора данных - это аспект, который требует дальнейшего внимания и усилий.
• Наблюдаемая проблема, связанная с смещением пространств между словами и символами. Чтобы решить эту проблему, предлагается фаза после обработки для исправления смещенных космических символов. • Собственность страниц с несколькими колоннами является еще одной областью, требующей больше усилий.
• Точно извлечение математических уравнений.
Онлайн -ресурсы
Набор данных частично доступен для некоммерческого использования в соответствии с лицензией CC By-nc-sa 4.0 по адресу https://github.com/kurdishblark/ocr4oldtextsinsorani.
Благодарности
Мы хотели бы выразить нашу благодарность Центру документирования и исследований в Центре документов и исследований в Сулаймании, Курдистан, Ирак за их щедрую поддержку в предоставлении нам цифровых копий определенных исторических публикаций.
Ссылки
Ахмади С., Хасани Х. и Джафф Д. К. (2022). Используя многоязычные новостные сайты для построения курдского параллельного корпуса. Транзакции по обработке информации о языке азиатского и низкого ресурса, 21 (5): 1–11.
Antonacopoulos, A., Karatzas, D., Krawczyk, H. и Wiszniewski, B. (2004). Жизненный цикл цифрового исторического документа: структура и содержание. В материалах симпозиума ACM 2004 года по проектированию документов, страницы 147–154.
Ataer, E. and Duygulu, P. (2007). Соответствующие османские слова: подход к поиску изображения к индексации исторического документа. В материалах 6 -й Международной конференции ACM по поиску изображений и видео, страницы 341–347.
Аула Л. (2021). Улучшение распознавания оптических символов на сканированных исторических документах с использованием обработки изображений.
Bukhari, S.S., Kadi, A., Jouneh, M.A., Mir, F.M. and Dengel, A. (2017). Anyocr: OpenSource OCR -система для исторических архивов. В 2017 году 14 -я Международная конференция IAPR по анализу и признанию документов (ICDAR), том 1, страницы 305–310. IEEE.
Bulert, K., Miyagawa, S. и B¨ »Uchler, M. (2017). Познавание оптического персонажа с моделью нейронной сети для печатных коптских текстов. В цифровых гуманитарных актеров 2017, страницы 657–9.
Do˘gru, M. (2016). Османская турецкая оптическое распознавание персонажа и латинская транскрипция. Доктор философии Тезис, ankara yıldırım beyazıt ¨ »Универсайт, фен билимлери enstit¨” us¨ ”u.
Долек И. и Курт А. (2021). Османский OCR: напечатанный шрифт Насх. В 2021 году Международная конференция по инновациям в интеллектуальных системах и приложениях (INISTA), страницы 1–5. IEEE.
Feng, J., Peng, L. и Lebourgeois, F. (2015). Гауссовое картирование переноса стиля процесса для исторического признания китайского иерите. В распознавании и поиске документов XXII, том 9402, страницы 104–115. Spie.
Gilbey, J.D. и Sch¨ »Onlieb, C.-B. (2021). Средний подход к распознаванию оптических символов для печатных текстовых изображений с ультра-низким разрешением. Arxiv Preprint arxiv: 2105.04515.
Google. (2023a). Как обучить LSTM/Нейронную сеть Tesseract. Доступ на 30-04-2023.
Google. (2023b). Улучшение качества выхода. Доступ на 15-04-2023.
Hassani, H., Medjedovic, D., et al. (2016). Автоматические курдские диалекты идентификация. Компьютерные науки и информационные технологии, 6 (2): 61–78.
Hassanpour, A. (1992). Национализм и язык в Курдистане, 1918-1985. Сан -Франциско: Mellen Research University Press.
Idrees, S. и Hassani, H. (2021). Использование сходства сценариев, чтобы компенсировать большой объем данных при обучении Tesseract LSTM: к курдскому OCR. Прикладные науки, 11 (20): 9752.
Idees, S. (2020). Улучшение обработки документов в общественных организациях Курдистанского региона Ирака (KRI) с использованием системы распознавания оптических символов (OCR). Мастер -тезис.
Kilic, N., Gorgel, P., Ucan, O.N. и Kala, A. (2008). Многофонт Османский распознавание символов с использованием вспомогательного векторного машины. В 2008 году 3 -й международный симпозиум по связям с коммуникациями, контролем и обработкой сигналов, страницы 328–333. IEEE.
Koistinen, M., Kettunen, K. и Kervinen, J. (2017). Как улучшить распознавание оптических персонажей исторических финских газет с использованием двигателя Tesseract OCR с открытым исходным кодом. Прокурор LTC, страницы 279–283.
K¨u¸c¨uk¸sahin, N. (2019). Дизайн автономной системы распознавания персонажей для перевода печатных документов на современный турецкий. Доктор философии Тезис, технологический институт Измира (Турция).
Li, B., Peng, L. и Ji, J. (2014). Исторический метод распознавания китайских иеров, основанный на картировании переноса стиля. В 2014 году 11 -й международный семинар IAPR по системам анализа документов, страницы 96–100. IEEE.
Ly, N.T., Nguyen, C.T. и Nakagawa, M. (2020). Основанная на внимании модель энкодера-дикодера с рядовыми колоннами для распознавания текста в японских исторических документах. Письма о распознавании шаблона, 136: 134–141.
Munivel, M. and Enigo, V. (2022). Оптическое распознавание символов для печатных документов тамижи с использованием глубоких нейронных сетей. Desidoc Journal of Library & Information Technology, 42 (4).
Nashwan, F.M., Rashwan, M.A., Al-Barhamtoshy, H.M., Abdou, S.M. и Moussa, A.M. (2017). Целостная техника для арабской системы OCR. Журнал Imaging, 4 (1): 6.
Nguyen, H.T., Ly, N.T., Nguyen, K.C., Nguyen, C.T. и Nakagawa, M. (2017). Попытки признать аномально деформированную кана в японских исторических документах. В материалах 4 -го международного семинара по историческим визуализации и обработке документов, страницы 31–36.
Nunamaker, B., Bukhari, S.S., Borth, D. и Dengel, A. (2016). Основная структура OCR на основе Tesseract для исторических документов, в которых отсутствует текст земли. В 2016 году IEEE Международная конференция по обработке изображений (ICIP), страницы 3269–3273. IEEE.
Озтурк А., Гунс С. и Озбай Ю. (2000). Многофонт Османский признание персонажа. В ICECS 2000. 7 -я Международная конференция IEEE по электронике, схемам и системам (Cat. № 00EX445), том 2, страницы 945–949. IEEE.
Poncelas, A., Aboomar, M., Buts, J., Hadley, J. и Way, A. (2020). Инструмент для облегчения OCR, опубликованного в исторических документах. Arxiv Preprint arxiv: 2004.11471.
Poulos, M., Kokkonas, Y., Papavlasopoulos, S. и Bokos, G. (2010). Система OCR для греческих печатных ранних книг на основе алгоритмов вычислительной геометрии.
Кания, М. (2012). Le Barey Ragayandinewe. Чварарра.
Reul, C., Springmann, U., Wick, C. и Puppe, F. (2018). Состояние художественного оптического признания характера сценариев Fraktur 19 -го века с использованием двигателей с открытым исходным кодом. Arxiv Preprint arxiv: 1810.03436.
Romanello, M., Najem-Meyer, S. и Robertson, B. (2021). Оптическое признание характера классических комментариев 19 -го века: нынешнее положение дел. На 6 -м международном семинаре по историческим визуализации и обработке документов, страницы 1–6.
Shafii, M. (2014). Оптическое признание характера печатных персидских/арабских документов.
Sihang, W., Jiapeng, W., Weihong, M. и Lianwen, J. (2020). Точное обнаружение китайских иероглифов в исторических документах с глубоким обучением подкрепления. Распознавание шаблона, 107: 107503.
Simistira, F., Ul-Hassan, A., Papavassiliou, V., Gatos, B., Katsouros, V. и Liwicki, M. (2015). Признание исторических греческих политонических сценариев с использованием сетей LSTM. В 2015 году 13 -я Международная конференция по анализу и признанию документов (ICDAR), стр. 766–770. IEEE.
Скелби, М. Б. и Даннэллс Д. (2021). OCR обработка шведских исторических газет с использованием глубоких гибридных сетей CNN -LSTM. В материалах Международной конференции по последним достижениям в области обработки естественного языка (RANLP 2021), страницы 190–198.
Springmann, U., Fink, F. и Schulz, K. U. (2016). Автоматическая оценка качества и (полу) автоматическое улучшение моделей OCR для исторических печати. Arxiv Preprint arxiv: 1606.05157.
Springmann, U., Reul, C., Dipper, S. и Baiter, J. (2018). Наземная правда для обучения двигателей OCR по историческим документам в немецком фрактуре и ранней современной латыни. Arxiv Preprint arxiv: 1809.05501.
Стахлберг Ф. и Фогель С. (2016). Катип - Оптическая система распознавания персонажей для коллекций арабского наследия в библиотеках. В 2016 году 12 -й семинар IAPR по системам анализа документов (DAS), страницы 168–173. IEEE.
Sulaiman, A., Omar, K. и Nasrudin, M.F. (2019). Уничтоженный исторический документ бинаризация: обзор по вопросам, проблемам, методам и будущим направлениям. Журнал Imaging, 5 (4): 48.
Vamvakas, G., Gatos, B., Stamatopoulos, N. и Perantonis, S.J. (2008). Полная методология распознавания персонажей для исторических документов. В 2008 году восьмой международный семинар IAPR по системам анализа документов, страницы 525–532. IEEE.
Yang, H., Jin, L. и Sun, J. (2018). Признание китайского текста в исторических документах с аннотациями в сценарии. В 2018 году 16 -я Международная конференция по границ по признанию почерка (ICFHR), стр. 199–204. IEEE.
Yousefi, M.R., Soheili, M.R., Breuel, T.M., Kabir, E. и Sticker, D. (2015). OCR без бинаризации для исторических документов с использованием LSTM Networks. В 2015 году 13 -я Международная конференция по анализу и признанию документов (ICDAR), страницы 1121–1125. IEEE.
Авторы:
(1) Blnd Yaseen, Университет Курдистана, Регион Курдистан - Ирак (blnd.yaseen@ukh.edu.krd);
(2) Университет Курдистана Хоссейна Хассани Курдистана Регион Курдистан - Ирак (hosseinh@ukh.edu.krd).
Эта статья есть
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Лучшие новогодние подарки для владельцев домашних животных
29 мая 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27328)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)