

Внедрение ИИ в розничную торговлю с помощью Apache Cassandra и Apache Pulsar
22 августа 2023 г.Путь к внедрению решений в области искусственного интеллекта и машинного обучения требует решения многих общих проблем, которые обычно возникают в цифровых системах: обновление устаревших систем, отказ от пакетных процессов и использование инновационных технологий, основанных на искусственном интеллекте и машинном обучении, для улучшения обслуживание клиентов способами, которые еще несколько лет назад казались научной фантастикой.
Чтобы проиллюстрировать эту эволюцию, давайте проследим за гипотетическим подрядчиком, которого наняли для помощи во внедрении решений AI/ML в крупном розничном магазине. Это первая статья из серии, в которой подробно рассматриваются важные аспекты перехода к AI/ML.
Проблема: нестабильный пакетный процесс
Первый день в BigBoxCo в команде «Инфраструктура». Выполнив обязательные действия по работе с персоналом, я получил значок подрядчика и направился к своему новому рабочему месту.
После встречи с командой мне сказали, что сегодня утром у нас встреча с командой «Рекомендации».
Мой системный доступ еще не совсем работает, так что, надеюсь, ИТ-отдел уладит это, пока мы будем на встрече.
В конференц-зале нас всего несколько человек: мой менеджер и два других инженера из моей новой команды, а также один инженер из группы рекомендаций. Мы начнем с некоторых представлений, а затем перейдем к обсуждению проблемы, возникшей за неделю до этого.
Очевидно, на прошлой неделе произошел какой-то ночной сбой партии, и они все еще ощущают последствия этого.
Похоже, что текущие рекомендации по продуктам основаны на данных, собранных по заказам клиентов. С каждым заказом возникает новая ассоциация между заказанными продуктами, которая записывается.
Когда клиенты просматривают страницы продуктов, они могут получить рекомендации, основанные на том, сколько других клиентов купили текущий продукт вместе с другими продуктами.
Рекомендации по продуктам предоставляются пользователям bigboxco.com через слой микросервисов в облаке. Уровень микросервисов использует локальное (облачное) развертывание центра обработки данных Apache Cassandra для обработки результатов.
Однако то, как результаты собираются и обрабатываются, — это совсем другая история. По сути, результаты ассоциаций между продуктами (приобретенными вместе) компилируются во время задания MapReduce. Это пакетный процесс, который потерпел неудачу на прошлой неделе.
Хотя этот пакетный процесс никогда не был быстрым, со временем он стал медленнее и более хрупким. Фактически, иногда процесс занимает два или даже три дня.
Улучшение опыта
После встречи я проверяю свой компьютер и, кажется, наконец-то могу войти в систему. Пока я оглядываюсь, подходит наш главный инженер (PE) и представляется.
Я рассказываю ему о встрече с командой рекомендаций, и он рассказывает мне немного больше об истории службы рекомендаций.
Похоже, что этот пакетный процесс существует уже около 10 лет. Инженер, разработавший его, ушёл, мало кто в организации действительно его понимает, и никто не хочет его трогать.
Другая проблема, начинаю объяснять, заключается в том, что набор данных, лежащий в основе каждой рекомендации, почти всегда создан пару дней назад.
Хотя по большому счету это может не иметь большого значения, но если бы данные рекомендаций могли быть более актуальными, это принесло бы пользу краткосрочным рекламным акциям, проводимым маркетингом.
Он согласно кивает и говорит, что открыт для предложений по улучшению системы.
Может быть, это проблема с графиком?
Поначалу это звучит как проблема с графом. У нас есть клиенты, которые заходят на сайт и покупают товары. До этого, когда они смотрят товар или добавляют его в корзину, мы можем показать рекомендации в виде «Клиенты, которые купили X, также купили Y».
Сегодня на сайте это есть, поскольку служба рекомендаций делает именно это: возвращает четыре основных дополнительных продукта, которые часто покупают вместе.
Но нам понадобится какой-то способ «ранжировать» продукты, потому что сопоставление одного продукта со всеми другими, приобретенными одновременно любым из наших 200 миллионов клиентов, быстро станет большим.
Таким образом, мы можем ранжировать их по количеству раз, когда они появляются в заказе. График этой системы может выглядеть примерно так, как показано ниже на рисунке 1.
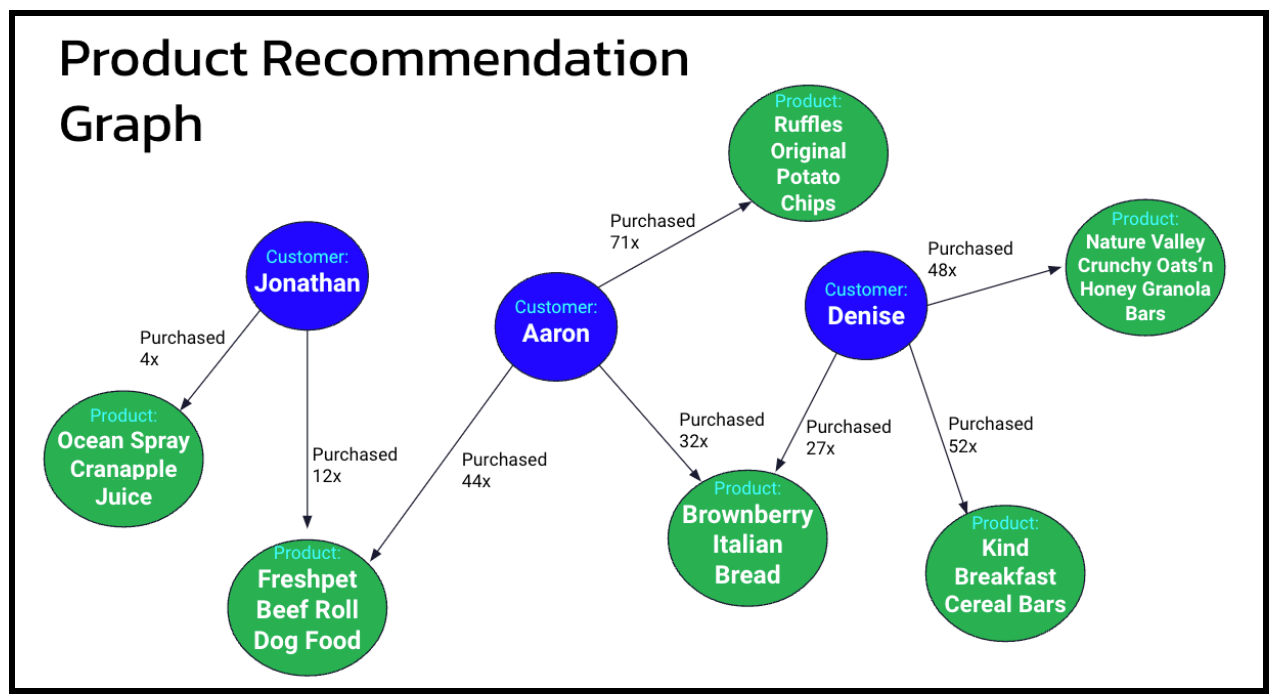
Смоделировав это и запустив в нашей графовой базе данных с реальными объемами данных, я быстро понял, что это не сработает.
Переход от одного продукта к ближайшим клиентам к их продуктам и вычисление продуктов, которые появляются чаще всего, занимает где-то около 10 секунд.
По сути, мы решили проблему двухдневной пакетной обработки, чтобы при каждом поиске задержка обхода устанавливалась именно там, где она нам не нужна: перед покупателем.
Но, может быть, эта графовая модель не слишком далека от того, что нам нужно сделать здесь? На самом деле описанный выше подход представляет собой технику машинного обучения (ML), известную как «совместная фильтрация».
По сути, совместная фильтрация — это подход, который исследует сходство определенных объектов данных на основе активности других пользователей и позволяет нам делать прогнозы на основе этих данных.
В нашем случае мы будем неявно собирать данные о корзинах/заказах из нашей клиентской базы и использовать их для предоставления более качественных рекомендаций по продуктам для увеличения онлайн-продаж.
Реализация
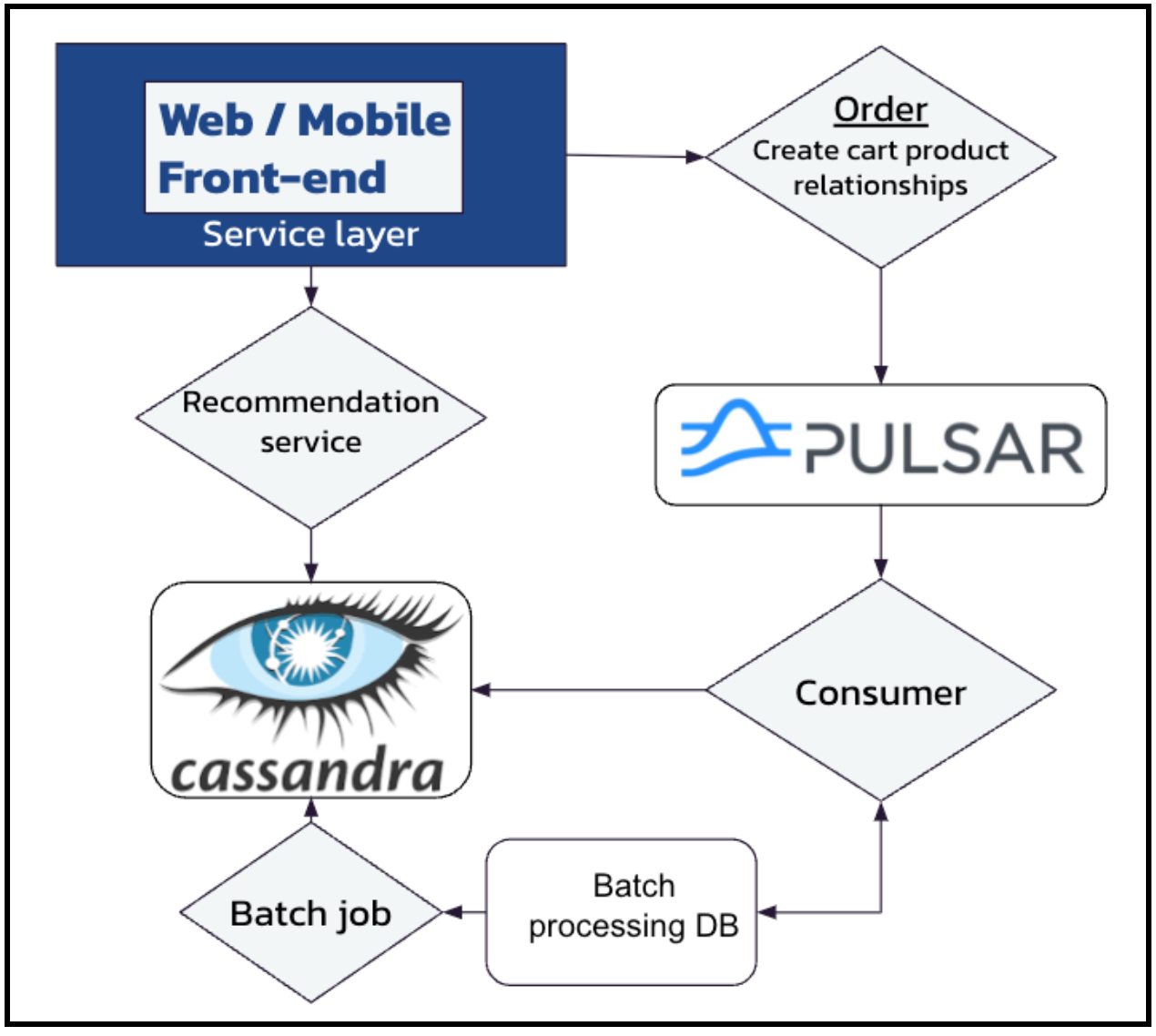
Прежде всего, давайте рассмотрим сбор данных. Добавление дополнительного служебного вызова к функции «разместить заказ» в магазине не так уж и сложно. На самом деле он уже существует; просто данные сохраняются в базе данных и обрабатываются позже. Не ошибитесь: мы все еще хотим включить пакетную обработку.
Но мы также хотим обрабатывать данные корзины в режиме реального времени, чтобы мы могли сразу же передать их обратно в онлайн-набор данных и сразу после этого использовать.
Мы начнем с установки решения для потоковой передачи событий, такого как Apache Pulsar. Таким образом, все действия с новой корзиной помещаются в тема Pulsar, где оно потребляется и отправляется в как базовую пакетную базу данных, так и для помощи обучить нашу модель машинного обучения в реальном времени.
Что касается последнего, наш потребитель Pulsar будет писать в таблицу Cassandra (показанную на рисунке 2), предназначенную просто для хранения записей для каждого продукта в заказе. Затем у продукта появляется строка для всех остальных продуктов из этого и других заказов:
CREATE TABLE order_products_mapping (
id text,
added_product_id text,
cart_id uuid,
qty int,
PRIMARY KEY (id, added_product_id, cart_id)
) WITH CLUSTERING ORDER BY (added_product_id ASC, cart_id ASC);
Затем мы можем запросить эту таблицу для конкретного продукта (в данном примере «DSH915»), например:
SELECT added_product_id, SUM(qty)
FROm order_products_mapping
WHERE id='DSH915'
GROUP BY added_product_id;
added_product_id | system.sum(qty)
------------------+-----------------
APC30 | 7
ECJ112 | 1
LN355 | 2
LS534 | 4
RCE857 | 3
RSH2112 | 5
TSD925 | 1
(7 rows)
Затем мы можем взять четыре лучших результата и поместить их в таблицу рекомендаций по продуктам, чтобы служба рекомендаций могла запросить их по `product_id`:
SELECT * FROM product_recommendations
WHERE product_id='DSH915';
product_id | tier | recommended_id | score
------------+------+----------------+-------
DSH915 | 1 | APC30 | 7
DSH915 | 2 | RSH2112 | 5
DSH915 | 3 | LS534 | 4
DSH915 | 4 | RCE857 | 3
(4 rows)
Таким образом, новые данные рекомендаций постоянно обновляются. Также все описанные выше инфраструктурные активы находятся в локальном дата-центре.
Таким образом, процесс извлечения товарных связей из заказа, отправки их через тему Pulsar и переработки в рекомендации, хранящиеся в Cassandra, происходит менее чем за секунду.
С помощью этой простой модели данных Cassandra может предоставлять запрошенные рекомендации за однозначные миллисекунды.
Выводы и дальнейшие действия
В долгосрочной перспективе нам необходимо обязательно изучить, как наши данные записываются в таблицы Cassandra. Таким образом, мы можем избежать потенциальных проблем, связанных с такими вещами, как несвязанный рост строк и обновления на месте.
Возможно, потребуется добавить некоторые дополнительные эвристические фильтры, например список «не рекомендовать».
Это связано с тем, что есть некоторые продукты, которые наши клиенты покупают либо один раз, либо нечасто, и их рекомендация только отнимет место у других продуктов, которые они с большей вероятностью купят импульсивно.
Например, рекомендация приобрести что-то из нашего отдела бытовой техники, например стиральную машину, вряд ли приведет к «импульсивной покупке».
Еще одним будущим улучшением будет внедрение платформы AI/ML в реальном времени, такой как Kaskada для обработки потоковой передачи информации о продуктах и обслуживания рекомендательные данные непосредственно в службу.
К счастью, мы придумали способ расширить существующий вялый пакетный процесс с помощью Pulsar для обработки событий добавления корзины в режиме реального времени. Как только мы почувствуем, как эта система работает в долгосрочной перспективе, мы должны рассмотреть возможность отключения устаревшего пакетного процесса.
PE признал, что мы добились хорошего прогресса с новым решением, и, что еще лучше, мы также начали закладывать основу для устранения некоторых технических задолженностей. В конце концов, все довольны этим.
В следующей статье мы рассмотрим улучшение продвижения товаров с помощью векторный поиск.
Узнайте, как DataStax обеспечивает ИИ в реальном времени
Аарон Плётц, DataStax
Также опубликовано здесь
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27294)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)