Работая над несколькими проектами по обработке технических чертежей, мы не могли не прийти к проекту по автоматизации инженерных чертежей. Что же такого особенного в инженерных чертежах, спросите вы?
Ответ — аннотации геометрических размеров и допусков (GD&T). Эти надоедливые метки часто создают трудности при обработке и извлечении данных из инженерных чертежей из-за их положения на странице и общей структуры. Но не волнуйтесь — я здесь, чтобы поделиться тем, как нам удалось обработать аннотации GD&T на инженерных чертежах с помощью ИИ. Давайте начнем с самого начала.
Обработка неструктурированных документов
Все цифровые документы можно разделить на 2 типа: структурированные и неструктурированные:
- Структурированные документыследуют предопределенной структуре, что упрощает их обработку и анализ с помощью ИИ. Такие документы, как формы, счета-фактуры, квитанции, опросы и контракты, являются примерами структурированных документов.
- Напротив,неструктурированные документыне имеют последовательной организации, что делает их изначально сложными для автоматической обработки. Примерами неструктурированных документов являются газеты, исследовательские работы и бизнес-отчеты.
Как вы могли догадаться, технические чертежи являются классическим примером неструктурированного документа: несмотря на соблюдение строгого набора стандартов, каждый чертеж отличается от другого, поскольку им не хватает жесткой структуры. В сочетании с сочетанием печатных и рукописных текстовых данных, специальных символов, сложных электронных таблиц и различных аннотаций технические чертежи представляют собой настоящую проблему для автоматического извлечения данных.
Сложная природа технических чертежей делает их идеальным кандидатом для извлечения данных с помощью ИИ. Фактически, использование нейронных моделей для обнаружения и извлечения различных данных из чертежей является единственным способом автоматизировать их обработку. Современные модели компьютерного зрения и интеллектуальный подход к разработке продукта могут дать мощный инструмент для быстрой обработки любого технического чертежа.
Проблема с готовыми инструментами
Один быстрый поиск в Google покажет вам как минимум пару решений для обработки инженерных чертежей. Почти все они предлагают широкий функционал и обещают быструю и точную обработку сложных данных.
На первый взгляд это может показаться очень многообещающим: оплачивать ежемесячную подписку на чертежи технологических процессов с высокой точностью. Однако на практике все часто оказывается не так гладко.
Готовые инструменты часто испытывают трудности с обнаружением и обработкой повернутых элементов, поскольку их алгоритмы обучены обрабатывать только «общий знаменатель», которым в нашем случае является инженерный чертеж с надписями и аннотациями, расположенными горизонтально.
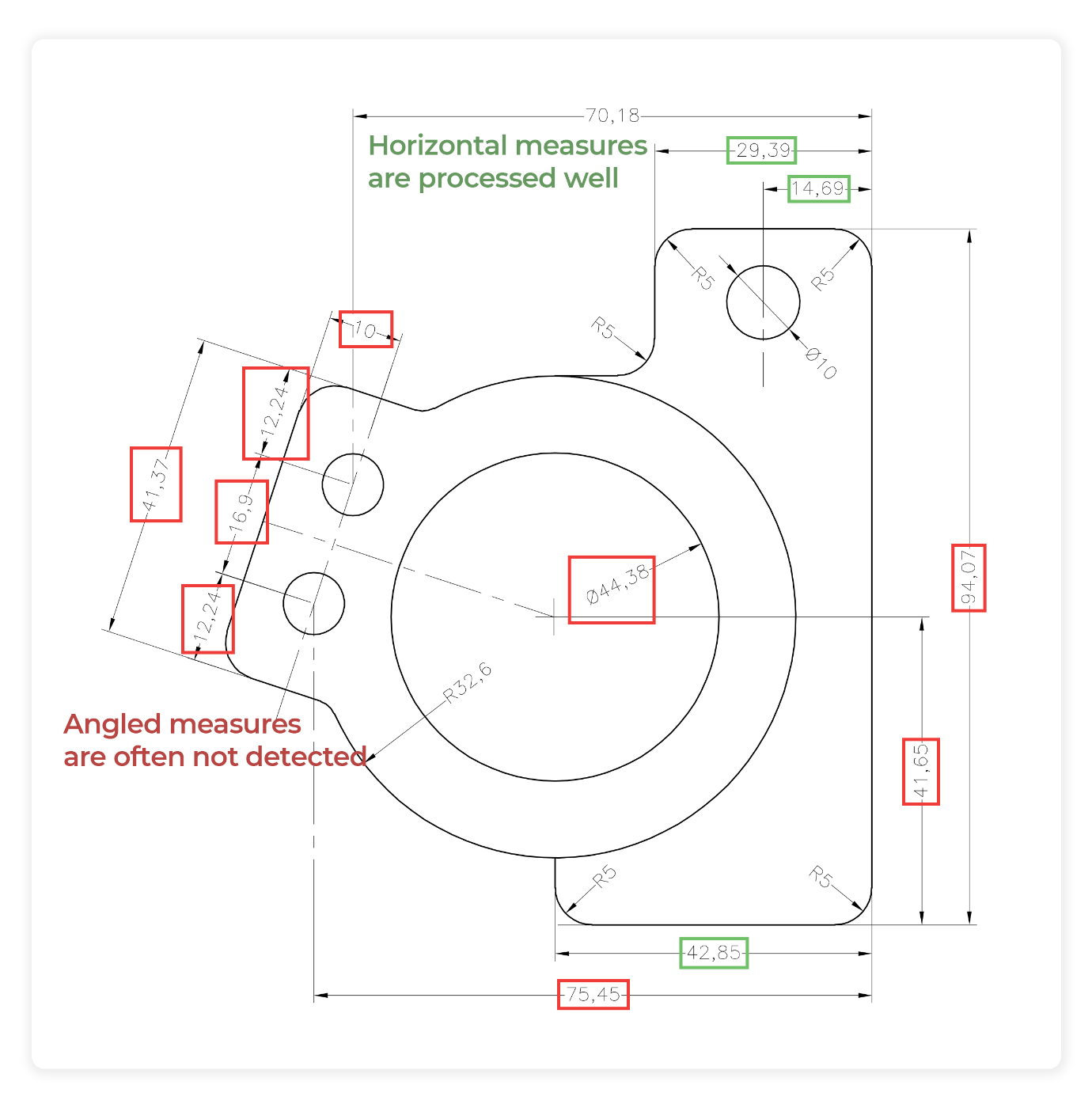
Поэтому использование готового решения подходит только тем, чьи чертежи относительно просты и включают только стандартные данные. Любое отклонение от «общего знаменателя» будет представлять собой проблему для готового инструмента.
Извлечение элементов из инженерных чертежей
Именно такая ситуация произошла с одним из наших клиентов: имеющиеся на рынке решения для обработки инженерных чертежей не отвечают потребностям обработки сложных или нестандартных чертежей, в результате чего результаты распознавания данных оказываются неудовлетворительными.
Аннотации GD&T несут в себе много очень важной информации, которую крайне важно извлечь из чертежа для дальнейшей обработки, но их расположение на странице (в нашем случае они расположены под углом) затрудняет процесс анализа чертежей с помощью готового инструмента ИИ.
Вот тут-то и вступает в игру разработка индивидуального ИИ: модели ИИ, обученные обнаруживать и извлекать информацию из вашего конкретного документа, могут решить (почти) любую задачу, с которой не справляется готовый инструмент.
Вот как мы решили одну из задач обработки инженерных чертежей с помощью разработки специальной модели ИИ — извлечение аннотаций GD&T, размещенных под углом.
Шаг 1: Определение положения аннотации
Первый шаг — определить положение аннотаций на чертеже. Модели ИИ можно обучить определять положение аннотаций независимо от их положения или угла поворота.
Примечание: Многостраничные документы требуют дополнительного шага по разделению документа на страницы и дифференциации различных инженерных чертежей. То же самое касается документов, которые включают несколько чертежей на каждой странице: вам нужно сначала запустить модель, чтобы обнаружить каждый чертеж и извлечь их из документа.
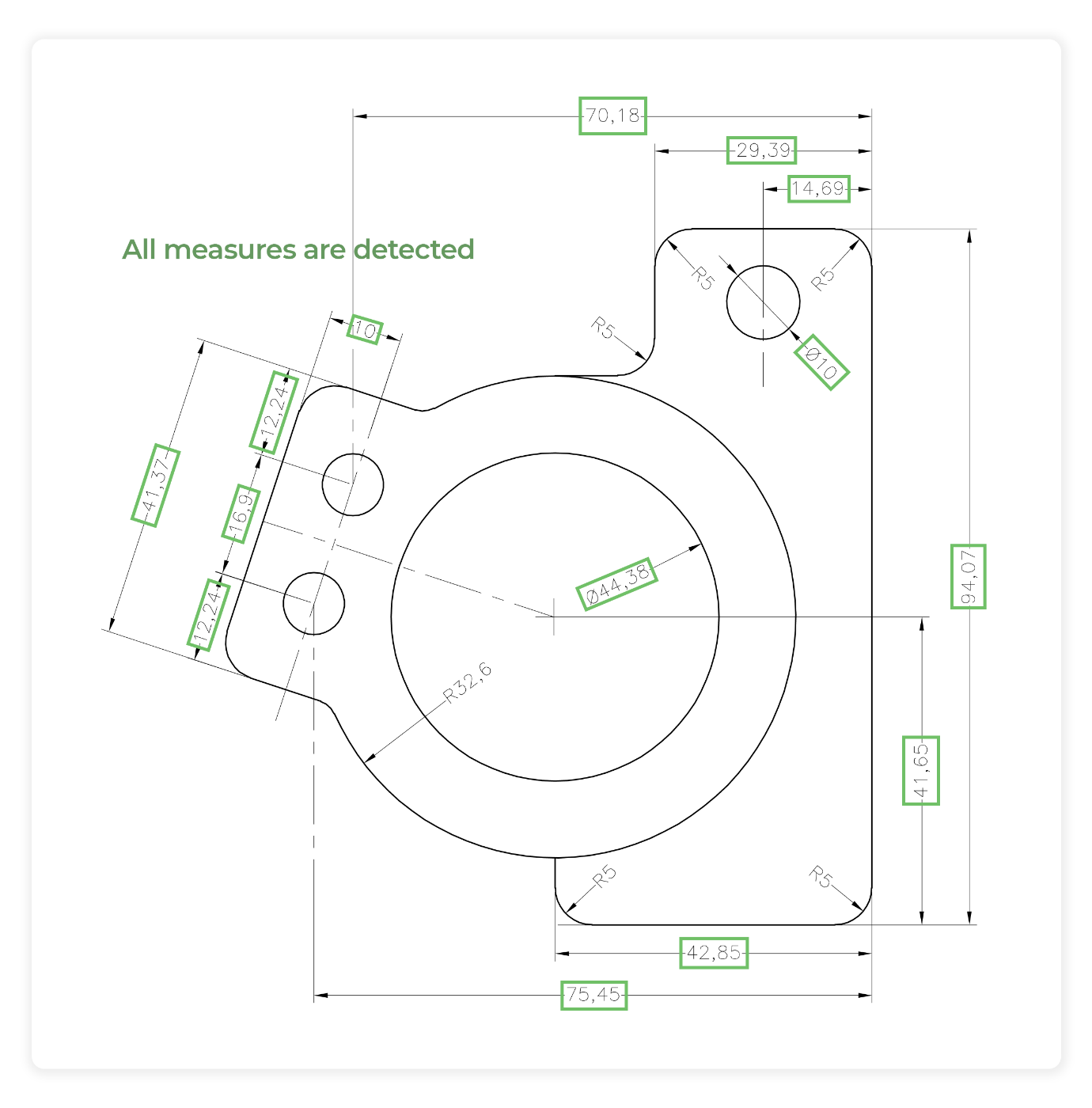
Шаг 2: Определите угол поворота
Вот важная часть: определение того, как повернута аннотация. Модель ИИ должна вычислить угол поворота и повернуть аннотацию, чтобы сделать ее горизонтальной. Вырезанные PNG затем передаются для дальнейшей обработки:
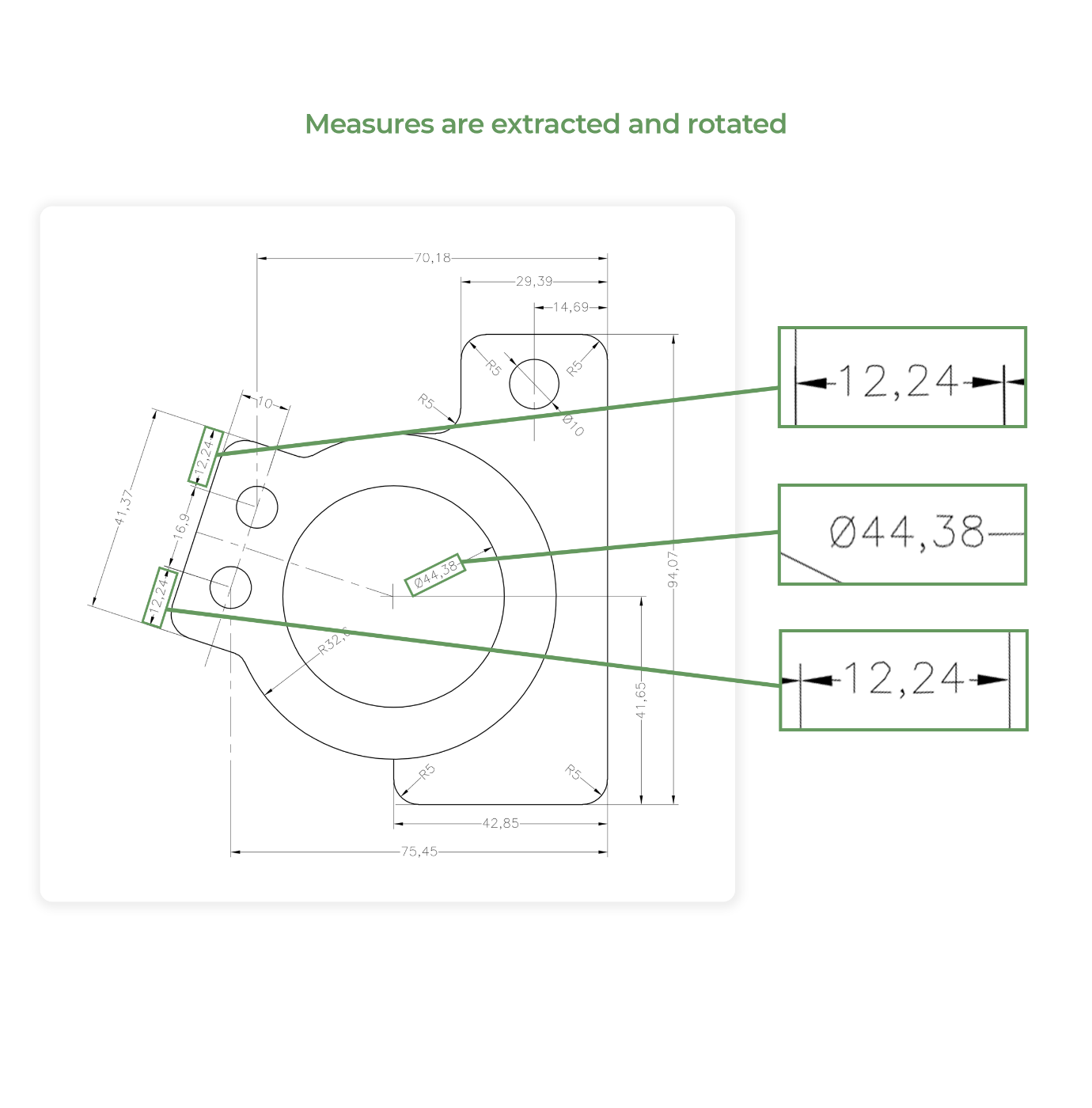
Шаг 3: Извлечение данных из аннотаций
После того, как все аннотации обнаружены, повернуты и извлечены из чертежа, они пропускаются через механизм обнаружения символов. Tesseract является хорошим выбором для этого, поскольку он обеспечивает высокую точность распознавания и может работать с многострочным текстом и символами разной высоты.
Во-первых, вам нужно найти точную область, где находится текст, чтобы улучшить процесс распознавания символов. Я бы рекомендовал использовать OpenCV, так как он отлично справляется с этими задачами и с ним относительно легко работать. Затем обнаруженная область текста передается в OCR-движок для извлечения всего текста и символов.
Шаг 4: Анализ данных
Массив букв, цифр и символов необходимо интерпретировать, чтобы предоставить «усвояемые» данные, которые люди — или система управления данными — могут понять и обработать. Обнаруженные символы разделяются на группы, формирующие размеры деталей, допуски, посадки и радиусы.
Шаг 5: Управление данными
Данные, извлекаемые системой ИИ, необходимо извлекать в соответствии с вашими потребностями:
- JSON-файлы: Идеально подходит для импорта данных в существующее программное обеспечение,
- Файлы .XLSX: Удобный для чтения формат данных, идеально подходящий для тестирования систем или небольших партий данных.
- Постобработка: данные дополнительно обрабатываются для отправки их непосредственно в систему цифровой обработки документов; отлично подходит для тех, кто ищет комплексное решение.
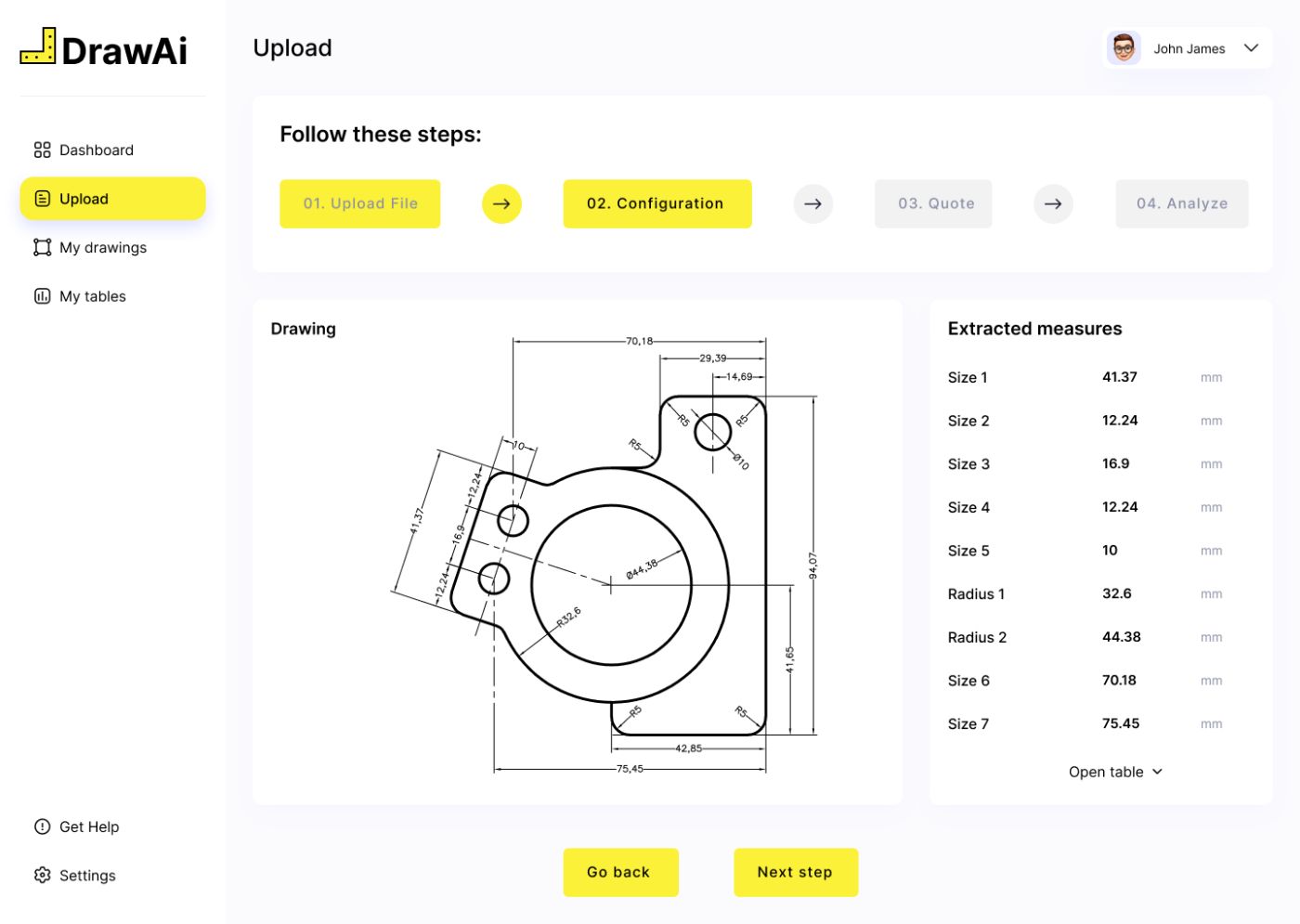
Подведение итогов
Хотя рынок полон инструментов ИИ для обработки документов, они хорошо справляются только с простыми файлами. Любое отклонение от «нормы» лучше обрабатывать с помощью индивидуального решения.
Пользовательские модели ИИ способны справиться практически со всеми задачами по извлечению данных — при условии правильного подхода и навыков разработчика.
Инженерные чертежи — это не единственные технические чертежи, о которых я писал, посмотрите
как ИИ может помочь в обработке архитектурных чертежей здесь .