Введение
Это вторая часть статьи, в которой я показываю, как создать расширение Image Grabber для Google Chrome. Image Grabber – это расширение, которое позволяет извлекать все или выбранные изображения с любой веб-страницы, отображаемой в браузере Chrome, и загружать их в виде одного ZIP-архива.
Прежде чем читать ее, вы должны прочитать первую часть этой статьи здесь:
https://hackernoon.com/how-to -create-a-google-chrome-extension-image-grabber?embedable=true
В предыдущей статье мы разработали расширение, которое показывает всплывающее окно с кнопкой «ЗАГРУЗИТЬ СЕЙЧАС». Когда пользователь нажимает эту кнопку, расширение внедряет скрипт на веб-страницу, которая в данный момент открыта на вкладке браузера. Этот скрипт собирает все img> элементы, извлекает URL-адреса всех изображений, а затем отправляет информацию обратно в расширение. Затем этот список URL-адресов был скопирован расширением в буфер обмена.
В этой части мы изменим это поведение. Вместо копирования в буфер обмена расширение откроет веб-страницу со списком изображений и кнопкой «Скачать». Затем пользователь может выбрать, какие изображения загрузить. Наконец, при нажатии кнопки «Загрузить» на этой странице сценарий загрузит все выбранные изображения и сожмет их в архив с именем images.zip. Наконец, пользователю будет предложено сохранить этот архив на локальном компьютере.
Итак, к концу этой статьи, если вы выполните все шаги, у вас будет расширение, которое выглядит и работает так, как показано в следующем видео.
https://youtu.be/lUgfbmkc_5U?embedable=true
Вы также познакомитесь с важными понятиями обмена данными между различными частями веб-браузера Chrome, некоторыми новыми функциями Javascript API из пространства имен браузера chrome, понятиями работы с данными двоичных файлов в Javascript, включая ZIP-архивы и, наконец, я объясню, как подготовить расширение к публикации в Интернет-магазине Chrome — глобальном хранилище расширений Google Chrome, что сделает его доступным для всех в мире.
Итак, приступим.
Создайте и откройте веб-страницу со списком изображений
Последним шагом скрипта popup.js в предыдущей части была функция onResult, которая собирала массив URL-адресов изображений и копировала его в буфер обмена. На текущем этапе эта функция выглядит так:
/**
* Executed after all grabImages() calls finished on
* remote page
* Combines results and copy a list of image URLs
* to clipboard
*
* @param {[]InjectionResult} frames Array
* of grabImage() function execution results
*/
function onResult(frames) {
// If script execution failed on remote end
// and could not return results
if (!frames || !frames.length) {
alert("Could not retrieve images");
return;
}
// Combine arrays of image URLs from
// each frame to a single array
const imageUrls = frames.map(frame=>frame.result)
.reduce((r1,r2)=>r1.concat(r2));
// Copy to clipboard a string of image URLs, delimited by
// carriage return symbol
window.navigator.clipboard
.writeText(imageUrls.join("n"))
.then(()=>{
// close the extension popup after data
// is copied to the clipboard
window.close();
});
}
Итак, мы удаляем все после строки комментария // Copy to clipboard ..., включая саму эту строку, и вместо этого реализуем функцию, которая открывает страницу со списком изображений:
function onResult(frames) {
// If script execution failed on remote end
// and could not return results
if (!frames || !frames.length) {
alert("Could not retrieve images");
return;
}
// Combine arrays of image URLs from
// each frame to a single array
const imageUrls = frames.map(frame=>frame.result)
.reduce((r1,r2)=>r1.concat(r2));
// Open a page with a list of images and send imageUrls to it
openImagesPage(imageUrls)
}
/**
* Opens a page with a list of URLs and UI to select and
* download them on a new browser tab and send an
* array of image URLs to this page
*
* @param {*} urls - Array of Image URLs to send
*/
function openImagesPage(urls) {
// TODO:
// * Open a new tab with a HTML page to display an UI
// * Send `urls` array to this page
}
Теперь давайте шаг за шагом реализуем функцию openImagesPage.
Открыть новую вкладку с локальной страницей расширения
С помощью функции chrome.tabs.create API Google Chrome вы можете создать новую вкладку в браузере с любым URL-адресом. Это может быть любой URL-адрес в Интернете или локальная HTML-страница расширения.
Создать страницу HTML
Давайте создадим страницу, которую мы хотим открыть. Создайте файл HTML с простым именем page.html и следующим содержимым. Затем сохраните его в корень папки расширения Image Grabber:
<!DOCTYPE html>
<html>
<head>
<title>Image Grabber</title>
</head>
<body>
<div class="header">
<div>
<input type="checkbox" id="selectAll"/>
<span>Select all</span>
</div>
<span>Image Grabber</span>
<button id="downloadBtn">Download</button>
</div>
<div class="container">
</div>
</body>
</html>
Эта разметка определяет страницу, состоящую из двух разделов (двух разделов): header и container, которые имеют соответствующие классы, которые позже будут использоваться в Таблица стилей CSS. В части Header есть элементы управления для выбора всех изображений из списка и их загрузки. Часть Container, которая сейчас пуста, будет динамически заполняться изображениями с использованием массива URL-адресов. Наконец, после применения стилей CSS к этой странице она будет выглядеть так:
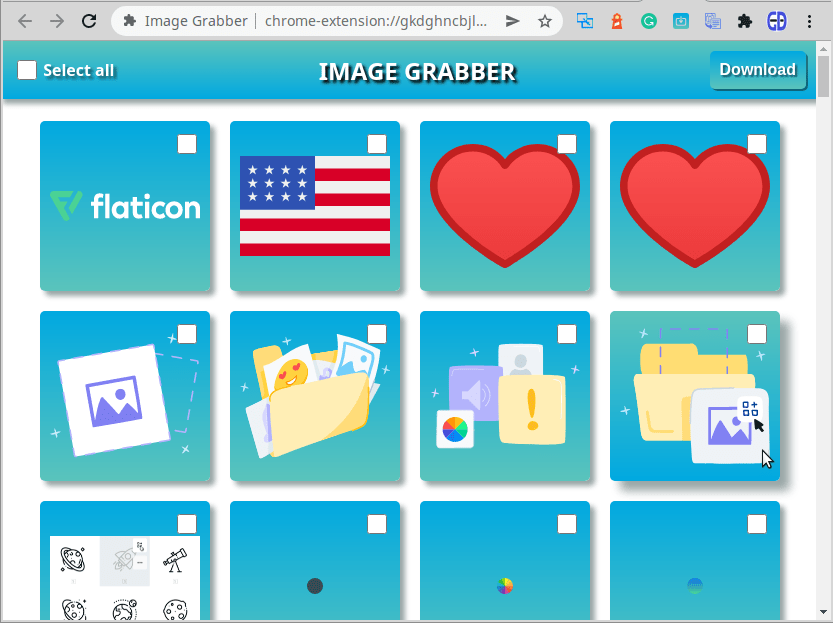
Открыть новую вкладку браузера
Итак, пришло время начать писать функцию openImagesPage(urls) в popup.js, которую мы определили ранее. Мы будем использовать функцию chrome.tabs.create, чтобы открыть новую вкладку с page.html в ней.
Синтаксис функции chrome.tabs.create следующий:
chrome.tabs.create(createProperties,callback)
* createProperties — это объект с параметрами, которые сообщают Chrome, какую вкладку открывать и как. В частности, у него есть параметр url, который будет использоваться для указания, какую страницу открывать во вкладке.
* обратный вызов — это функция, которая будет вызываться после создания вкладки. Эта функция имеет единственный аргумент tab, который содержит объект созданной вкладки, который, среди прочего, содержит параметр id этой вкладки для связи с ней позже.< /p>
Итак, давайте создадим вкладку:
function openImagesPage(urls) {
// TODO:
// * Open a new tab with a HTML page to display an UI
chrome.tabs.create({"url": "page.html"},(tab) => {
alert(tab.id)
// * Send `urls` array to this page
});
}
Если вы запустите расширение сейчас и нажмете кнопку «Загрузить сейчас» на любой странице браузера с изображениями, оно должно открыть page.html на новой вкладке и активировать эту вкладку. На новой вкладке должно отображаться следующее содержимое:
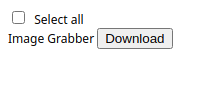
Как вы видите в предыдущем коде, мы определили функцию обратный вызов, которая позже должна использоваться для отправки массива urls на эту страницу, но теперь она должна отображать оповещение с идентификатором созданной вкладки. Однако, если вы попытаетесь запустить это сейчас, этого не произойдет из-за одного интересного эффекта, который необходимо обсудить, чтобы понять, что произошло, а затем понять, как это исправить.
Итак, вы нажимаете кнопку «Захватить сейчас» во всплывающем окне, которое вызывает появление новой вкладки. И в тот момент, когда появляется и активируется новая вкладка, всплывающее окно исчезает и уничтожается. Он был уничтожен ДО того, как был выполнен обратный вызов. Вот что происходит, когда новая вкладка активируется и получает фокус. Чтобы исправить это, мы должны создать вкладку, но не активировать ее, пока не проделаем все необходимые действия в обратном вызове. Только после того, как все действия в обратном вызове будут завершены, нужно вручную активировать вкладку.
Первое, что нужно сделать, это указать в функции chrome.tabs.create, чтобы автоматически не выбирать созданную вкладку. Для этого необходимо установить для параметра selected в createProperties значение false:
chrome.tabs.create({url: 'page.html', selected: false}, ...
Затем внутри обратного вызова необходимо выполнить все действия, которые необходимо выполнить (отобразить предупреждение или отправить список URL-адресов), и в последней строке этого обратного вызова вручную активировать вкладку.
С точки зрения API Chrome, активировать вкладку означает обновить статус вкладки. Чтобы обновить статус вкладки, необходимо использовать функцию chrome.tabs.update с очень похожим синтаксисом:
chrome.tabs.update(tabId,updateProperties,callback)
* tabId — это идентификатор вкладки, которую необходимо обновить.
* updateProperties определяет, какие свойства вкладки нужно обновить.
* Функция callback вызывается после завершения операции обновления. Чтобы активировать вкладку с помощью этой функции, необходимо сделать этот вызов:
chrome.tabs.update(tab.id,{active:true});
Мы опускаем обратный вызов, потому что он не нужен. Все, что требуется сделать с этой вкладкой, должно быть сделано в предыдущих строках этой функции.
function openImagesPage(urls) {
// TODO:
// * Open a new tab with a HTML page to display an UI
chrome.tabs.create(
{"url": "page.html",selected:false},(tab) => {
alert(tab.id)
// * Send `urls` array to this page
chrome.tabs.update(tab.id,{active: true});
}
);
}
Если вы запустите расширение сейчас и нажмете кнопку «Загрузить сейчас», все должно работать так, как ожидалось: вкладка создается, затем отображается предупреждение, затем вкладка будет выбрана, и, наконец, всплывающее окно исчезнет.
Теперь давайте удалим временное alert и определим, как отправить список URL-адресов изображений на новую страницу и как отобразить интерфейс для управления ими.
Отправить данные URL изображений на страницу
Теперь нам нужно создать скрипт, который будет генерировать HTML-разметку для отображения списка изображений внутри container на странице.
На первый взгляд, мы можем пойти тем же путем, что и в предыдущей части этой статьи. Мы можем использовать API chrome.scripting, чтобы внедрить скрипт на вкладку с page.html, и этот скрипт будет использовать urls изображения для создания списка изображений. внутри контейнера. Но внедрение скриптов - это не верный путь. Это своего рода хакерство. Это не совсем правильно и законно. Мы должны определить скрипт в том месте, где он будет выполняться, мы не должны "отсылать скрипты". Единственная причина, по которой мы делали это раньше, заключалась в том, что у нас не было доступа к исходному коду страниц сайтов, с которых мы брали изображения. Но в данном случае у нас есть полный контроль над page.html и всеми скриптами в нем, и поэтому скрипт, который генерирует интерфейс для этого, должен быть определен в page.html. . Итак, давайте создадим пустой файл Javascript page.js, поместим его в ту же папку, что и page.html, и включим его в page.html таким образом:
<!DOCTYPE html>
<html>
<head>
<title>Image Grabber</title>
</head>
<body>
<div class="header">
<div>
<input type="checkbox" id="selectAll"/>
<span>Select all</span>
</div>
<span>Image Grabber</span>
<button id="downloadBtn">Download</button>
</div>
<div class="container">
</div>
<script src="/page.js"></script>
</body>
</html>
Теперь мы можем написать в page.js все, что требуется для инициализации и создания интерфейса. Однако нам по-прежнему нужны данные из popup.js — массива urls для отображения изображений. Значит, нам еще нужно отправить эти данные в скрипт, который мы только что создали.
Настало время представить важную функцию Chrome API, которую можно использовать для связи между различными частями расширения: обмен сообщениями. Одна часть расширения может отправить сообщение с данными другой части расширения, и эта другая часть может получить сообщение, обработать полученные данные и ответить отправляющей части. По сути, API обмена сообщениями определяется в пространстве имен chrome.runtime, и вы можете прочитать официальную документацию здесь.
В частности, есть событие chrome.runtime.onMessage. Если для этого события в скрипте определен прослушиватель, этот скрипт будет получать все события, отправленные ему другими скриптами.
Для целей Image Grabber нам нужно отправить сообщение со списком URL-адресов из скрипта popup.js на вкладку со страницей page.html. Сценарий на этой странице должен получить это сообщение, извлечь из него данные, а затем ответить на него, чтобы подтвердить, что данные были обработаны правильно. Теперь пришло время представить API, который для этого необходим.
chrome.tabs.sendMessage(tabId, message, responseFn)
* tabId — идентификатор вкладки, на которую будет отправлено сообщение
* message само сообщение. Может быть любым объектом Javascript.
* callback — это функция, которая вызывается, когда принимающая сторона отвечает на это сообщение. Эта функция имеет только один аргумент responseObject, который содержит все, что получатель отправил в качестве ответа.
Итак, вот что нам нужно вызвать в popup.js, чтобы отправить список URL-адресов в виде сообщения:
function openImagesPage(urls) {
// TODO:
// * Open a new tab with a HTML page to display an UI
chrome.tabs.create(
{"url": "page.html",selected:false},(tab) => {
// * Send `urls` array to this page
chrome.tabs.sendMessage(tab.id,urls,(resp) => {
chrome.tabs.update(tab.id,{active: true});
});
}
);
}
В этой вкладке мы отправляем urls в виде сообщения на страницу и активируем эту страницу только после получения ответа на это сообщение.
Я бы рекомендовал обернуть этот код функцией setTimeout, чтобы подождать пару миллисекунд перед отправкой сообщения. Нужно дать некоторое время для инициализации новой вкладки:
function openImagesPage(urls) {
// TODO:
// * Open a new tab with a HTML page to display an UI
chrome.tabs.create(
{"url": "page.html",selected:false},(tab) => {
// * Send `urls` array to this page
setTimeout(()=>{
chrome.tabs.sendMessage(tab.id,urls,(resp) => {
chrome.tabs.update(tab.id,{active: true});
});
},100);
}
);
}
Получить данные об URL-адресах изображений на странице
Если вы запустите это сейчас, всплывающее окно не исчезнет, потому что оно должно исчезнуть только после получения ответа от принимающей страницы. Чтобы получить это сообщение, нам нужно определить прослушиватель событий chrome.runtime.onMessage в сценарии page.js:
chrome.runtime.onMessage
.addListener(function(message,sender,sendResponse) {
addImagesToContainer(message);
sendResponse("OK");
});
/**
* Function that used to display an UI to display a list
* of images
* @param {} urls - Array of image URLs
*/
function addImagesToContainer(urls) {
// TODO Create HTML markup inside container <div> to
// display received images and to allow to select
// them for downloading
document.write(JSON.stringify(urls));
}
Чтобы получить сообщение, сценарий назначения должен добавить прослушиватель к событию chrome.runtime.onMessage. Слушатель — это функция с тремя аргументами:
* message - полученный объект сообщения, переданный как есть. (в данном случае это массив urls)
* sender - объект, который идентифицирует отправителя этого сообщения.
* sendResponse - функция, с помощью которой можно отправить ответ отправителю. Единственным параметром этой функции является все, что мы хотим отправить отправителю.
Итак, здесь этот прослушиватель передает полученное сообщение функции addImagesToContainer, которая будет использоваться для создания HTML-разметки для отображения изображений. Но сейчас он записывает строковое представление полученного массива URL-адресов. Затем слушатель отвечает отправителю с помощью функции sendResponse. В качестве ответа он отправляет просто строку «ОК», потому что не имеет значения, как отвечать. В данном случае важен только факт отклика.
После того, как это будет сделано, когда вы нажмете кнопку «ЗАГРУЗИТЬ СЕЙЧАС» в расширении, новая страница должна открыться с чем-то вроде этого в качестве содержимого: (в зависимости от того, на какой вкладке вы ее щелкнули):
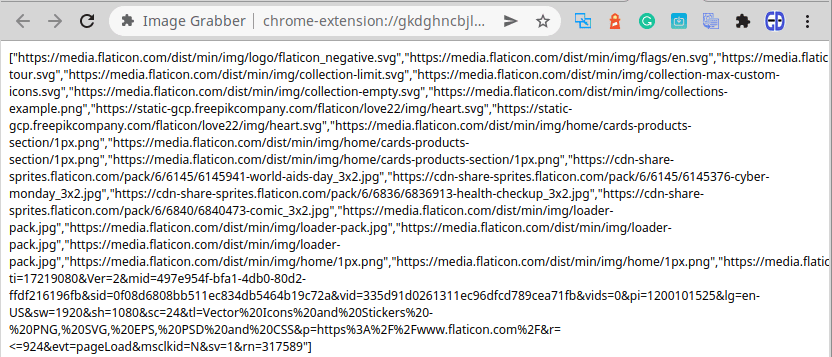
Создать интерфейс загрузчика изображений
Мы получили массив URL-адресов изображений для загрузки из всплывающего окна в скрипт, подключенный к page.html, и это все, что нам нужно от popup.js. Теперь пришло время создать интерфейс для отображения этих изображений и разрешить их загрузку.
Создать интерфейс для отображения и выбора изображений
Функция addImagesToContainer(urls) уже создана с кодом-заполнителем. Давайте изменим его, чтобы действительно добавлять изображения в контейнер
/**
* Function that used to display an UI to display a list
* of images
* @param {} urls - Array of image URLs
*/
function addImagesToContainer(urls) {
if (!urls || !urls.length) {
return;
}
const container = document.querySelector(".container");
urls.forEach(url => addImageNode(container, url))
}
/**
* Function dynamically add a DIV with image and checkbox to
* select it to the container DIV
* @param {*} container - DOM node of a container div
* @param {*} url - URL of image
*/
function addImageNode(container, url) {
const div = document.createElement("div");
div.className = "imageDiv";
const img = document.createElement("img");
img.src = url;
div.appendChild(img);
const checkbox = document.createElement("input");
checkbox.type = "checkbox";
checkbox.setAttribute("url",url);
div.appendChild(checkbox);
container.appendChild(div)
}
Давайте проясним этот код шаг за шагом.
* Функция addImagesToContainer проверяет, не пуст ли массив URL-адресов, и останавливается, если он ничего не содержит.
* Затем он запрашивает DOM, чтобы получить узел элемента div с классом container. Затем этот элемент контейнера будет использоваться в функции для добавления к нему всех изображений.
* Затем он вызывает функцию addImageNode для каждого URL-адреса. Он передает ему контейнер и сам URL
* Наконец, функция addImageNode динамически создает HTML-код для каждого изображения и добавляет его в контейнер.
Он создает следующий HTML-код для каждого URL-адреса изображения:
<div class="imageDiv">
<img src={url}/>
<input type="checkbox" url={url}/>
</div>
Он добавляет div с классом imageDiv для каждого изображения. Этот div содержит само изображение с указанным url и флажком для его выбора. Этот флажок имеет настраиваемый атрибут с именем url, который позже будет использоваться функцией загрузки для определения того, какой URL использовать для загрузки изображения.
Если вы запустите это прямо сейчас для того же списка изображений, что и на предыдущем снимке экрана, страница должна отобразить что-то вроде следующего:
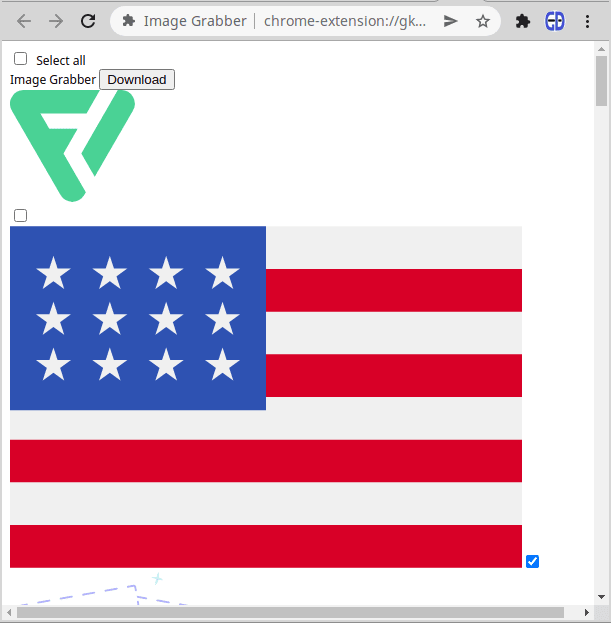
Здесь вы можете видеть, что сразу после шапки с флажком "Выбрать все" и кнопкой "Скачать" идет список изображений с флажками для выбора каждого из них вручную.
Это полный код файла page.js, используемый для получения и отображения этого списка:
chrome.runtime.onMessage
.addListener((message,sender,sendResponse) => {
addImagesToContainer(message)
sendResponse("OK");
});
/**
* Function that used to display an UI to display a list
* of images
* @param {} urls - Array of image URLs
*/
function addImagesToContainer(urls) {
if (!urls || !urls.length) {
return;
}
const container = document.querySelector(".container");
urls.forEach(url => addImageNode(container, url))
}
/**
* Function dynamically add a DIV with image and checkbox to
* select it to the container DIV
* @param {*} container - DOM node of a container div
* @param {*} url - URL of image
*/
function addImageNode(container, url) {
const div = document.createElement("div");
div.className = "imageDiv";
const img = document.createElement("img");
img.src = url;
div.appendChild(img);
const checkbox = document.createElement("input");
checkbox.type = "checkbox";
checkbox.setAttribute("url",url);
div.appendChild(checkbox);
container.appendChild(div)
}
На этом этапе мы можем выбрать каждое изображение вручную. Теперь пришло время заставить работать флажок "Выбрать все", чтобы выбрать/снять выделение со всех сразу.
Реализовать функцию «Выбрать все»
Если вернуться к макету page.html, вы увидите, что флажок "Выбрать все" является полем ввода с идентификатором selectAll. Итак, нам нужно реагировать на клики пользователя по нему. Когда пользователь включает его, все флажки изображения должны быть включены. Когда пользователь выключает его, все флажки изображений также должны выключаться. Другими словами, мы должны прослушивать событие «onChange» флажка «#selectAll» и в обработчике этого события установить статус «checked» для всех флажков таким же, как статус «Select All». "флажок. Вот как это можно реализовать в скрипте page.js:
document.getElementById("selectAll")
.addEventListener("change", (event) => {
const items = document.querySelectorAll(".container input");
for (let item of items) {
item.checked = event.target.checked;
};
});
Функция прослушивания получает экземпляр события onChange в качестве аргумента функции event. Этот экземпляр имеет ссылку на сам узел «Выбрать все» в параметре target, который мы можем использовать для определения текущего состояния этого флажка.
Затем мы выбираем все «входные» поля внутри div с классом container, например. флажки для всех изображений, потому что внутри этого контейнера нет других полей ввода.
Затем мы устанавливаем проверенный статус для каждого из этих флажков на статус флажка «Выбрать все». Таким образом, каждый раз, когда пользователь меняет состояние этого флажка, все остальные флажки отражают это изменение.
Теперь, если вы снова запустите расширение, вы сможете выбрать изображения для загрузки вручную или автоматически.
Остался единственный шаг в этом разделе — загрузить выбранные изображения. Для этого нам нужно, чтобы кнопка Скачать работала.
Реализовать функцию загрузки
После того, как пользователь выбрал изображения, он должен нажать кнопку Загрузить, которая должна запустить прослушиватель событий onClick этой кнопки. Кнопку Загрузить можно идентифицировать по идентификатору downloadBtn. Итак, мы можем подключить функцию слушателя к этой кнопке, используя этот идентификатор. Эта функция должна делать три вещи:
* Получить URL-адреса всех выбранных изображений, * Загрузите их и сожмите в ZIP-архив * Предложить пользователю скачать этот архив.
Давайте определим форму этой функции:
document.getElementById("downloadBtn")
.addEventListener("click", async() => {
try {
const urls = getSelectedUrls();
const archive = await createArchive(urls);
downloadArchive(archive);
} catch (err) {
alert(err.message)
}
})
function getSelectedUrls() {
// TODO: Get all image checkboxes which are checked,
// extract image URL from each of them and return
// these URLs as an array
}
async function createArchive(urls) {
// TODO: Create an empty ZIP archive, then, using
// the array of `urls`, download each image, put it
// as a file to the ZIP archive and return that ZIP
// archive
}
function downloadArchive(archive) {
// TODO: Create an <a> tag
// with link to an `archive` and automatically
// click this link. This way, the browser will show
// the "Save File" dialog window to save the archive
}
Слушатель выполняет действия, определенные выше, одно за другим.
Я поместил все тело слушателя в блок try/catch, чтобы реализовать единый способ обработки всех ошибок, которые могут произойти на любом этапе. Если во время обработки списка URL-адресов или сжатия файлов возникнет исключение, эта ошибка будет перехвачена и отображена как предупреждение.
Кроме того, часть действий, которые будет выполнять эта функция, являются асинхронными и возвращают промисы. Я использую подход async/await для разрешения промисов вместо then/catch, чтобы сделать код проще и чище. Если вы не знакомы с этим современным подходом, поищите простое разъяснение здесь. Вот почему, чтобы иметь возможность разрешать промисы с помощью await, функция слушателя определяется как async(), так же, как и функция createArchive.
Получить URL выбранных изображений
ФункцияgetSelectedUrls() должна запрашивать все флажки изображений внутри .container div, затем фильтровать их, чтобы оставить только отмеченные, а затем извлекать url атрибут этих флажков. В результате эта функция должна вернуть массив этих URL-адресов. Вот как могла бы выглядеть эта функция:
function getSelectedUrls() {
const urls =
Array.from(document.querySelectorAll(".container input"))
.filter(item=>item.checked)
.map(item=>item.getAttribute("url"));
if (!urls || !urls.length) {
throw new Error("Please, select at least one image");
}
return urls;
}
Кроме того, он выдает исключение, если нет выбранных флажков. Затем это исключение правильно обрабатывается вышестоящей функцией.
Загрузка изображений по URL-адресам
Функция createArchive использует аргумент urls для загрузки файлов изображений для каждого url. Чтобы скачать файл из Интернета, необходимо выполнить GET HTTP-запрос на адрес этого файла.
Для этого есть много способов из Javascript, но наиболее универсальным и современным является использование функции fetch(). Эта функция может быть простой или сложной. В зависимости от типа запроса, который вам нужно выполнить, вы можете создать очень конкретные объекты запроса для передачи этой функции, а затем проанализировать возвращенные ответы. В простой форме требуется указать URL-адрес для запроса и возвращает обещание с объектом Response:
response = await fetch(url);
Эту форму мы будем использовать для Image Grabber. Полное описание функции fetch и ее API можно найти в официальной документации: https:// www.javascripttutorial.net/javascript-fetch-api/.
Приведенный выше вызов функции либо разрешается в объект response, либо генерирует исключение в случае возникновения проблем. response — это объект HTTP Response, который содержит необработанный полученный контент и различные свойства и методы, позволяющие с ним работать.
Ссылку на него вы можете найти в официальной документации. Этот объект содержит методы для получать контент в разных формах, в зависимости от того, что предполагается получить. Например, response.text() преобразует ответ в текстовую строку, response.json() преобразует его в простой объект Javascript. Однако нам нужно получить двоичные данные изображения, чтобы сохранить его в файл. Тип объекта, который обычно используется для работы с бинарными данными в Javascript, - это Blob - Binary Large Object. Метод получения содержимого ответа в виде blob — response.blob().
Теперь давайте реализуем часть функции createArchive для загрузки изображений как объектов Blob:
async function createArchive(urls) {
for (let index in urls) {
const url = urls[index];
try {
const response = await fetch(url);
const blob = await response.blob();
console.log(blob);
} catch (err) {
console.error(err);
}
};
}
В этой функции мы просматриваем каждый элемент выбранного массива urls, загружаем каждый из них в response, затем преобразуем response в клякса. Наконец, просто запишите каждый большой двоичный объект в консоль.
blob — это объект, который содержит бинарные данные самого файла, а также некоторые свойства этих данных, которые могут быть важны, в частности:
* тип - Тип файла. Это контент типа MIME — https://developer.mozilla.org/en -US/docs/Web/HTTP/Basics_of_HTTP/MIME_types. В зависимости от MIME-типа мы можем проверить, действительно ли это изображение или нет. Нам нужно будет отфильтровать файлы по их типам mime и оставить только image/jpeg, image/png или image/gif. Мы сделаем это позже, в следующем разделе.
* size - Размер изображения в байтах. Этот параметр также важен, так как если размер равен 0 или меньше 0, то нет смысла сохранять это изображение в файл.
Справочник со всеми параметрами и методами объектов Blob здесь .
Если вы прочтете это, вы не найдете свойства name или file name. Blob касается только контента, он не знает имени файла, потому что контент, возвращаемый fetch(), может быть не файлом. Однако нам нужно каким-то образом получить имена изображений. В следующем разделе мы создадим служебную функцию, которая будет использоваться для создания имени файла, известного только как blob.
Определить имена файлов для изображений
Чтобы поместить файлы в архив, нам нужно указать имя файла для каждого файла. Кроме того, чтобы открыть эти файлы как изображения позже, нам нужно иметь расширение для каждого файла. Для решения этой задачи мы определим служебную функцию со следующим синтаксисом:
function checkAndGetFileName(index, blob)
Где index — это индекс элемента из массива urls, а blob — объект BLOB с содержимым файла.
Чтобы получить имя файла, мы будем использовать только индекс URL-адреса во входном массиве. Мы не будем использовать сам URL, потому что он может быть странным и содержать различные временные метки и прочий мусор. Таким образом, имена файлов будут такими, как «1.jpeg», «2.png» и т. д.
Чтобы получить расширение файла, мы будем использовать MIME-тип объекта blob этого файла, который хранится в blob.type. параметр.
Кроме того, эта функция не только создаст имя файла, но и проверит, имеет ли большой двоичный объект правильный size и MIME-тип. Он вернет имя файла, только если он имеет положительный size и правильный MIME-тип изображения. Правильные типы MIME для изображений выглядят так: image/jpeg, image/png или image/gif, в которых первая часть — это слово < code>image, а вторая часть является расширением изображения.
Таким образом, функция будет анализировать MIME-тип и возвращать имя файла с расширением, только если MIME-тип начинается с image. Имя файла — это index, а расширение файла — это вторая часть его MIME-типа:
Вот как могла бы выглядеть функция:
function checkAndGetFileName(index, blob) {
let name = parseInt(index)+1;
const [type, extension] = blob.type.split("/");
if (type != "image" || blob.size <= 0) {
throw Error("Incorrect content");
}
return name+"."+extension;
}
Теперь, когда у нас есть имена изображений и их двоичное содержимое, ничто не может помешать нам просто поместить это в ZIP-архив.
Создать ZIP-архив
ZIP — один из наиболее часто используемых форматов для сжатия и архивирования данных. Если вы сжимаете файлы ZIP и куда-то отправляете, то можете быть уверены примерно на 100%, что принимающая сторона сможет их открыть. Этот формат был создан и выпущен компанией PKWare в 1989 году. Здесь вы можете найти не только историю, но и структуру ZIP-файла и описание алгоритма, который можно использовать для реализации сжатия и распаковки бинарных данных с помощью этого метода.
Однако здесь мы не будем изобретать велосипед, потому что это уже реализовано для всех или почти всех языков программирования, включая Javascript. Мы просто будем использовать существующую внешнюю библиотеку — JSZip. Вы можете найти его здесь.
Затем нам нужно загрузить сценарий библиотеки JSZip и включить его в page.html перед page.js. Это прямая ссылка для скачивания. Он скачает архив со всеми исходными кодами и релизными версиями. Это большой архив, но вам нужен только один файл из него: dist/jszip.min.js.
Создайте папку lib внутри пути расширения, извлеките в нее этот файл и включите этот скрипт в page.html перед page.js :
<!DOCTYPE html>
<html>
<head>
<title>Image Grabber</title>
</head>
<body>
<div class="header">
<div>
<input type="checkbox" id="selectAll"/>
<span>Select all</span>
</div>
<span>Image Grabber</span>
<button id="downloadBtn">Download</button>
</div>
<div class="container">
</div>
<script src="/lib/jszip.min.js"></script>
<script src="/page.js"></script>
</body>
</html>
Когда он включен, он создает глобальный класс JSZip, который можно использовать для создания ZIP-архивов и добавления в них контента. Этот процесс можно описать следующим кодом:
const zip = new JSZip();
zip.file(filename1, blob1);
zip.file(filename2, blob2);
.
.
.
zip.file(filenameN, blobN);
const blob = await zip.generateAsync({type:'blob'});
Во-первых, он создает пустой объект zip. Затем он начинает добавлять в него файлы. Файл определяется по имени и blob с двоичным содержимым этого файла. Наконец, метод generateAsync используется для создания ZIP-архива из ранее добавленных файлов. В этом случае он возвращает сгенерированный архив в виде блоба, потому что мы уже знаем, что такое BLOB и как с ним работать. Однако вы можете изучить документацию JSZip API для других вариантов.
Теперь мы можем интегрировать этот код в функцию createArchive, чтобы создать архив из всех файлов изображений и вернуть BLOB этого архива:
async function createArchive(urls) {
const zip = new JSZip();
for (let index in urls) {
try {
const url = urls[index];
const response = await fetch(url);
const blob = await response.blob();
zip.file(checkAndGetFileName(index, blob),blob);
} catch (err) {
console.error(err);
}
};
return await zip.generateAsync({type:'blob'});
}
function checkAndGetFileName(index, blob) {
let name = parseInt(index)+1;
[type, extension] = blob.type.split("/");
if (type != "image" || blob.size <= 0) {
throw Error("Incorrect content");
}
return name+"."+extension;
}
Здесь при добавлении каждого файла изображения в zip мы используем ранее созданную функцию checkAndGetFileName для создания имени файла для этого файла.
Кроме того, тело цикла размещается в блоке try/catch, поэтому любое исключение, выдаваемое любой строкой кода, будет обрабатываться внутри этого цикла. Я решил не останавливать процесс в случае возникновения исключений здесь, а просто пропустить файл, который привел к исключению и только показал сообщение об ошибке на консоль.
И, наконец, он возвращает сгенерированный BLOB с zip-архивом, который готов к загрузке.
Скачать ZIP-архив
Обычно, когда мы хотим предложить пользователям скачать файл, мы показываем им ссылку, указывающую на этот файл, и просим их щелкнуть по ней, чтобы загрузить этот файл. В этом случае нам нужна ссылка, указывающая на BLOB архива. BLOB-объекты могут быть очень большими, поэтому веб-браузеры их где-то хранят, к счастью, в Javascript есть функция, позволяющая получить ссылку на BLOB-объект:
window.URL.createObjectURL(blob)
Итак, мы можем создать ссылку на блоб ZIP-архива.
Наконец, вот как выглядит функция downloadArchive:
function downloadArchive(archive) {
const link = document.createElement('a');
link.href = URL.createObjectURL(archive);
link.download = "images.zip";
document.body.appendChild(link);
link.click();
document.body.removeChild(link);
}
Этот код динамически создает элемент "a" и указывает его на URL-адрес большого двоичного объекта archive. Кроме того, он устанавливает имя загруженного файла images.zip. Затем он вставляет эту невидимую ссылку в документ и щелкает по ней. Это приведет к тому, что браузер либо отобразит окно «Сохранить файл», либо автоматически сохранит файл с именем images.zip и содержимым ZIP-архива. Наконец, функция удаляет эту ссылку из документа, потому что после клика она нам больше не нужна.
Очистка кода
Это последний этап реализации функции "Скачать". Давайте почистим, прокомментируем и запомним весь код, который мы создали в page.js:
/**
* Listener that receives a message with a list of image
* URL's to display from popup.
*/
chrome.runtime.onMessage
.addListener((message,sender,sendResponse) => {
addImagesToContainer(message)
sendResponse("OK");
});
/**
* Function that used to display an UI to display a list
* of images
* @param {} urls - Array of image URLs
*/
function addImagesToContainer(urls) {
if (!urls || !urls.length) {
return;
}
const container = document.querySelector(".container");
urls.forEach(url => addImageNode(container, url))
}
/**
* Function dynamically add a DIV with image and checkbox to
* select it to the container DIV
* @param {*} container - DOM node of a container div
* @param {*} url - URL of image
*/
function addImageNode(container, url) {
const div = document.createElement("div");
div.className = "imageDiv";
const img = document.createElement("img");
img.src = url;
div.appendChild(img);
const checkbox = document.createElement("input");
checkbox.type = "checkbox";
checkbox.setAttribute("url",url);
div.appendChild(checkbox);
container.appendChild(div)
}
/**
* The "Select All" checkbox "onChange" event listener
* Used to check/uncheck all image checkboxes
*/
document.getElementById("selectAll")
.addEventListener("change", (event) => {
const items = document.querySelectorAll(".container input");
for (let item of items) {
item.checked = event.target.checked;
};
});
/**
* The "Download" button "onClick" event listener
* Used to compress all selected images to a ZIP-archive
* and download this ZIP-archive
*/
document.getElementById("downloadBtn")
.addEventListener("click", async() => {
try {
const urls = getSelectedUrls();
const archive = await createArchive(urls);
downloadArchive(archive);
} catch (err) {
alert(err.message)
}
})
/**
* Function used to get URLs of all selected image
* checkboxes
* @returns Array of URL string
*/
function getSelectedUrls() {
const urls =
Array.from(document.querySelectorAll(".container input"))
.filter(item=>item.checked)
.map(item=>item.getAttribute("url"));
if (!urls || !urls.length) {
throw new Error("Please, select at least one image");
}
return urls;
}
/**
* Function used to download all image files, identified
* by `urls`, and compress them to a ZIP
* @param {} urls - list of URLs of files to download
* @returns a BLOB of generated ZIP-archive
*/
async function createArchive(urls) {
const zip = new JSZip();
for (let index in urls) {
try {
const url = urls[index];
const response = await fetch(url);
const blob = await response.blob();
zip.file(checkAndGetFileName(index, blob),blob);
} catch (err) {
console.error(err);
}
};
return await zip.generateAsync({type:'blob'});
}
/**
* Function used to return a file name for
* image blob only if it has a correct image type
* and positive size. Otherwise throws an exception.
* @param {} index - An index of URL in an input
* @param {*} blob - BLOB with a file content
* @returns
*/
function checkAndGetFileName(index, blob) {
let name = parseInt(index)+1;
const [type, extension] = blob.type.split("/");
if (type != "image" || blob.size <= 0) {
throw Error("Incorrect content");
}
return name+"."+extension.split("+").shift();
}
/**
* Triggers browser "Download file" action
* using a content of a file, provided by
* "archive" parameter
* @param {} archive - BLOB of file to download
*/
function downloadArchive(archive) {
const link = document.createElement('a');
link.href = URL.createObjectURL(archive);
link.download = "images.zip";
document.body.appendChild(link);
link.click();
document.body.removeChild(link);
}
Теперь вы можете нажать кнопку «ЗАГРУЗИТЬ СЕЙЧАС», затем автоматически или вручную выбрать изображения для загрузки, нажать кнопку «Загрузить» и сохранить ZIP-архив с этими изображениями:
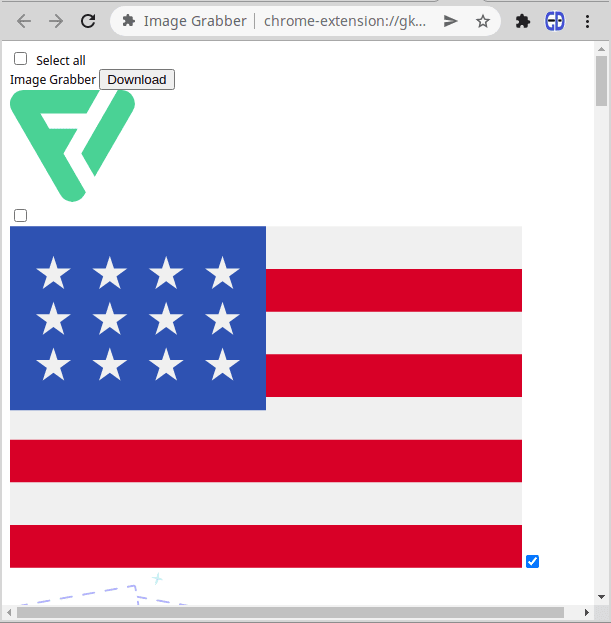
Однако это не выглядит идеально. Практически невозможно использовать это на практике. Давайте правильно стилизуем эту страницу.
Стиль страницы расширения
На текущем этапе вся разметка и функционал страницы расширения готовы. Все классы и идентификаторы определены в HTML. Пришло время добавить CSS, чтобы стилизовать его. Создайте файл page.css в той же папке, что и page.html и другие, и добавьте эту таблицу стилей в page.html:
<!DOCTYPE html>
<html>
<head>
<title>Image Grabber</title>
<link href="/page.css" rel="stylesheet" type="text/css"/>
</head>
<body>
<div class="header">
<div>
<input type="checkbox" id="selectAll"/>
<span>Select all</span>
</div>
<span>Image Grabber</span>
<button id="downloadBtn">Download</button>
</div>
<div class="container">
</div>
<script src="/lib/jszip.min.js"></script>
<script src="/page.js"></script>
</body>
</html>
Затем добавьте следующее содержимое в page.css:
body {
margin:0px;
padding:0px;
background-color: #ffffff;
}
.header {
display:flex;
flex-wrap: wrap;
flex-direction: row;
justify-content: space-between;
align-items: center;
width:100%;
position: fixed;
padding:10px;
background: linear-gradient( #5bc4bc, #01a9e1);
z-index:100;
box-shadow: 0px 5px 5px #00222266;
}
.header > span {
font-weight: bold;
color: black;
text-transform: uppercase;
color: #ffffff;
text-shadow: 3px 3px 3px #000000ff;
font-size: 24px;
}
.header > div {
display: flex;
flex-direction: row;
align-items: center;
margin-right: 10px;
}
.header > div > span {
font-weight: bold;
color: #ffffff;
font-size:16px;
text-shadow: 3px 3px 3px #00000088;
}
.header input {
width:20px;
height:20px;
}
.header > button {
color:white;
background:linear-gradient(#01a9e1, #5bc4bc);
border-width:0px;
border-radius:5px;
padding:10px;
font-weight: bold;
cursor:pointer;
box-shadow: 2px 2px #00000066;
margin-right: 20px;
font-size:16px;
text-shadow: 2px 2px 2px#00000088;
}
.header > button:hover {
background:linear-gradient( #5bc4bc,#01a9e1);
box-shadow: 2px 2px #00000066;
}
.container {
display: flex;
flex-wrap: wrap;
flex-direction: row;
justify-content: center;
align-items: flex-start;
padding-top: 70px;
}
.imageDiv {
display:flex;
flex-direction: row;
align-items: center;
justify-content: center;
position:relative;
width:150px;
height:150px;
padding:10px;
margin:10px;
border-radius: 5px;
background: linear-gradient(#01a9e1, #5bc4bc);
box-shadow: 5px 5px 5px #00222266;
}
.imageDiv:hover {
background: linear-gradient(#5bc4bc,#01a9e1);
box-shadow: 10px 10px 10px #00222266;
}
.imageDiv img {
max-width:100%;
max-height:100%;
}
.imageDiv input {
position:absolute;
top:10px;
right:10px;
width:20px;
height:20px;
}
После стилизации body он определяет стили для набора селекторов содержимого .header div, а затем для набора селекторов содержимого . контейнер раздел. Ключевой частью этого стиля является использование макета Flexbox с параметром 'flex-wrap'. Он используется как для заголовка, так и для контейнера. Это делает весь макет отзывчивым. Компоненты должным образом перестраиваются на экране любого размера:
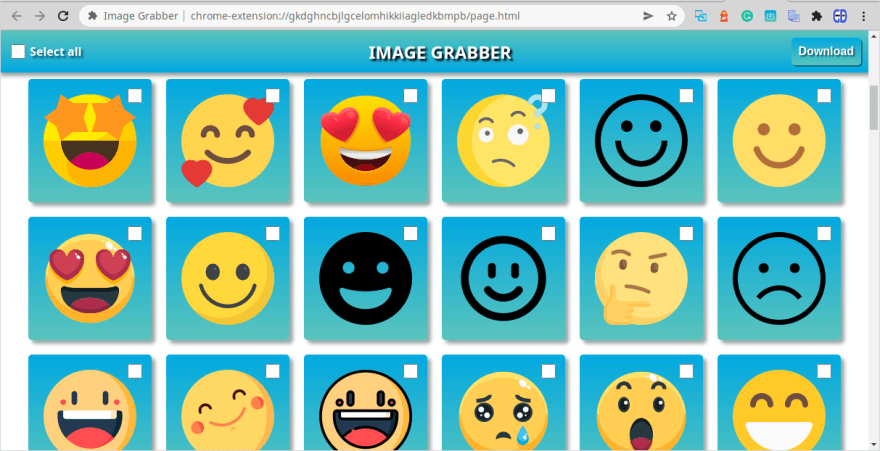
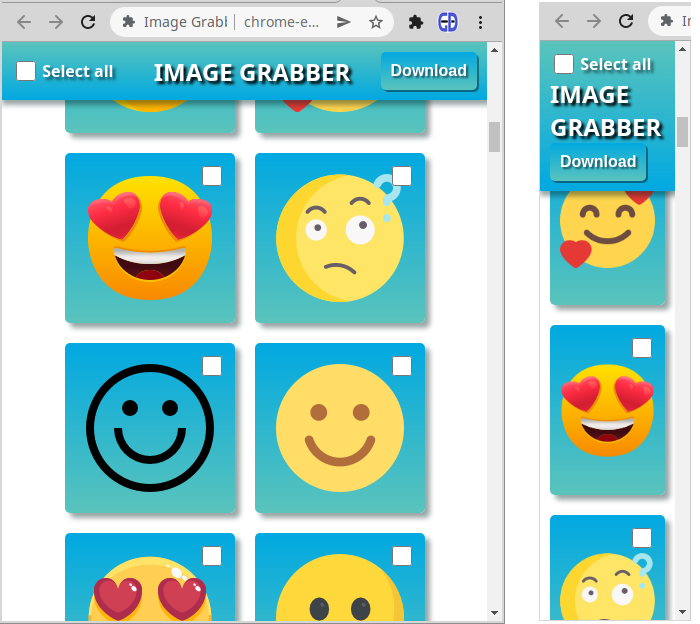
Вы можете прочитать об использовании макета Flexbox здесь. Дополнительную информацию обо всех других используемых стилях CSS можно легко найти в любом справочнике по CSS.
Публикуйте и распространяйте расширение
Теперь работа завершена, и расширение готово к выпуску. Как показать это другим людям? Вы отправляете им эту папку с файлами и объясняете, как установить распакованное расширение с помощью вкладки chrome://extensions? Конечно нет!
Это неправильный способ распространения расширений Chrome. Правильный способ – опубликовать расширение в Интернет-магазине Chrome и отправить ссылку на страницу, где оно будет доступно для всех.
Например, это ссылка на расширение Image Reader, который я недавно создал и опубликовал.
Вот как это выглядит в Интернет-магазине Chrome:

Люди могут прочитать описание расширения, посмотреть скриншоты и, наконец, нажать кнопку Добавить в Chrome, чтобы установить его.
Как вы видите здесь, для публикации расширения необходимо предоставить не только само расширение, но и изображение расширения, скриншоты, описания, указать категорию расширения и другие параметры.
Правила публикации время от времени меняются, поэтому лучше использовать официальный сайт Google, чтобы ознакомиться с руководством о том, как настройте учетную запись веб-разработчика Chrome, загрузите в нее расширение, а затем опубликуйте его.
Это основная информация в официальной документации. В нем Google описывает все, что вам нужно сделать. Страница обновляется по мере внесения изменений.
Я могу указать список ключевых моментов здесь, чтобы легко начать работу. (Однако на самом деле он действует только временно, Google может изменить правила в любое время, поэтому не слишком полагайтесь на этот список, просто используйте его как общую информацию):
* Заархивируйте папку расширения в zip-файл * Зарегистрируйтесь как разработчик Интернет-магазина Chrome. Вы можете использовать существующую учетную запись Google (например, если у вас есть учетная запись, используемая для Gmail, она будет работать). * Оплатите один раз регистрационный сбор в размере 5 долларов США * С помощью консоли разработчика Chrome Web Store создайте в ней новый товар и загрузите в него созданный ZIP-архив. * Заполните обязательные поля в форме продукта, указав информацию о названии и описании продукта. Загрузите изображение товара и скриншоты разных размеров. Эта информация может быть переменной, поэтому я думаю, что вам нужно будет подготовить ее в процессе заполнения этой формы. * Не обязательно заполнять все поля за один раз. Вы можете заполнить часть формы и нажать кнопку «Сохранить черновик». Затем вернитесь назад, выберите свой товар и продолжите заполнение. * После заполнения всех полей нажмите кнопку «Отправить на проверку», и, если форма заполнена без ошибок, расширение будет отправлено в Google на проверку. Проверка может занять время. Статус отзыва будет отображаться в списке товаров. * Вам необходимо время от времени проверять статус отправки, поскольку Google не отправляет никаких уведомлений по электронной почте о ходе проверки. * После успешного рассмотрения статус продукта изменится на «Опубликовано», и он будет доступен в Интернет-магазине Google Chrome. Люди смогут найти его и установить.
В случае с моим расширением на скриншоте выше проверка Google заняла два дня и была успешно опубликована. Я надеюсь, что это так же быстро для вас, или даже быстрее. Удачи!
Заключение
Создание расширений Google Chrome – это простой способ распространить ваше веб-приложение по всему миру с помощью всемирной глобальной платформы, которая просто работает и не требует какой-либо поддержки и продвижения. Таким образом, вы можете легко реализовать свои онлайн-идеи практически бесплатно. Более того, вы можете расширить возможности существующих веб-сайтов с помощью расширений браузера, чтобы ваши пользователи чувствовали себя более комфортно при работе с вашими онлайн-ресурсами. Например, расширение, которое я недавно опубликовал, использовалось для работы с онлайн-сервисом распознавания текста — «Image Reader». С помощью этого сервиса вы можете получить изображение с любого сайта, вставить его в интерфейс и распознать текст на нем.
Браузерное расширение для этого сервиса помогает автоматически отправлять изображения с любой вкладки браузера в этот сервис. Без расширения пользователю нужно сделать 5 щелчков мышью, но с расширением то же самое можно сделать всего за два щелчка мыши. Это большое улучшение производительности. Вы можете посмотреть это видео, чтобы увидеть, как это расширение помогает доставлять изображения в веб-службу с помощью контекстного меню:
https://youtu.be/LrnVEmgvnpg?embedable=true
Я считаю, что вы можете найти множество способов использования автоматизации веб-браузера с помощью расширений, чтобы повысить производительность и уровень комфорта ваших онлайн-пользователей, сделать их работу с вашими онлайн-ресурсами лучше, быстрее и умнее. Я надеюсь, что мой учебник открыл для вас мир расширений веб-браузера. Однако я не уточнил даже нескольких процентов особенностей, существующих в этой области. Возможно, я скоро напишу об этом подробнее.
Полный исходный код расширения Image Grabber можно клонировать из моего репозитория GitHub.
Пишите в комментариях, если у вас есть что добавить, вы нашли ошибки или у вас есть идеи, что нужно улучшить.
Не стесняйтесь подключаться и следить за мной в социальных сетях, где я публикую объявления о моих новых статьях, подобных этой и другим новостям разработки программного обеспечения.
Удачного программирования, ребята!
Также опубликовано здесь