
Как эта модель ИИ генерирует пение аватаров из текста
8 августа 2025 г.Таблица ссылок
Аннотация и 1. Введение
Связанная работа
2.1 Текст на вокальное поколение
2.2 Текст на генерацию движения
2.3 Аудио до генерации движения
Раскоростный набор данных
3.1 Рэп-вокальное подмножество
3.2 Подмножество рэп-движения
Метод
4.1 Составление проблемы
4.2 Motion VQ-VAE Tokenizer
4.3 Vocal2Unit Audio Tokenizer
4.4 Общее авторегрессивное моделирование
Эксперименты
5.1 Экспериментальная установка
5.2 Анализ основных результатов и 5.3 исследование абляции
Заключение и ссылки
А. Приложение
Приложение
Дополнительный материал организован следующим образом: гл. A.1 предоставляет демонстрацию веб -сайта, чтобы показать дополнительные качественные результаты; Раздел A.2 Представляет дополнительную информацию о сетевых архитектурах; Раздел A.3 вводит метрики оценки; Раздел A.4 представляет дополнительные исследования абляции; Раздел A.5 показывает дополнительные качественные результаты; Раздел A.6 обсуждает более широкие социальные последствия работы.
A.1 Демо
Чтобы предоставить более яркие и четкие качественные результаты, мы сделаем дополнительную демонстрацию веб -сайта, чтобы продемонстрировать качество генерации нашей предлагаемой системы. Мы призываем читателей просмотреть результаты по адресу https://vis-www.cs.umass.edu/rapverse/.
А.2 Подробности реализации
Токенизатор движения.Мы тренируем три отдельных векторных квантовых вариационных автоэнкодеров (VQ-VAE) для лица, тела и руки соответственно. Мы принимаем ту же архитектуру VQ-VAE на основе [14, 69, 23]. Для функций потерь оптимизируют токенизаторы движения, мы используем плавную потерю реконструкции L1, потерю встраивания и потерю приверженности. Вес потери обязательства устанавливается на 0,02. В соответствии с [14, 23], такие стратегии, как экспоненциальная скользящая средняя и методика сброса кодовой книги [49], реализуются для оптимизации эффективности кодовой книги на протяжении всего процесса обучения. Мы принимаем 512 для размера кодовой книги и устанавливаем размер каждого кода на 512. Мы устанавливаем скорость временного снижения вниз на 4. Мы тренируем VQ-VAE с размером партии 256 и длиной окна последовательности 72. Мы принимаем ADAM с β1 = 0,9, β2 = 0,99 и скорость обучения 00002 в качестве оптимизатора.
Вокальный токенизатор.Для семантического энкодера мы принимаем базовый трансформатор Hubert [20], предварительно обученный 969-часовым корпусом Librispeech [41]. Следуя [27, 45], мы выводим активации функций от его шестом слоя. Этот процесс позволяет модели Hubert преобразовать входное аудио в 768-мерном векторном пространстве. Впоследствии мы используем алгоритм K-средних с 500 центроидами для получения квантовых дискретных кодов контента. Для энкодера F0 используется структура VQ-VAE для дискретизации сигнала F0 в квантованные токены F0. Мы принимаем экспоненциальные обновления скользящей средней во время обучения VQ-VAE после [6, 45]. Мы устанавливаем размер кодовой книги VQ-VAE на 20 записей. Более того, поскольку исходная работа непосредственно нормализует извлеченные значения F0 для каждого певца соответственно, мы явно не используем статистику певца, но применяем оконного сверточного слоя как с аудио входом (нарезанный в размер окна), так и внедрение певца в качестве ввода. Наконец, мы принимаем такую же архитектуру, что и [17] для энкодера певца.
Общая авторегрессивная модель.Авторегрессивная модель состоит из Embedder T5 и модели фундамента. Мы используем энкодер с T5-более широким, в качестве нашего Embedder, с 24 слоями и 16 головами. Экбеддер замораживается во время обучения моделяции фонда. Модель фундамента основана на архитектуре трансформатора только для декодера, которая имеет 12 слоев и 8 голов. Мы используем Adam Optimizer с β1 = 0,9, β2 = 0,99 и скорость обучения 0,0002. Мы не используем отступление в нашем обучении. Наша тренировочная партия размер 384 для 100 эпох
A.3 Метрики оценки
Чтобы оценить качество генерации движения, мы используем следующие метрики:
Фрехет -начальное расстояние (FID): Этот показатель измеряет расхождение распределения между основной истиной и сгенерированными движениями тела и ручных жестов. В частности, мы тренируем автоэкодер на основе [14] в качестве экстрактора функции движения.
Разнообразие (div):Div оценивает разнообразие генерируемых движений, где мы рассчитываем дисперсию от извлеченных функций движения.
Vertex MSE:После [66] мы вычислим среднюю ошибку L2 вершин губ между генерируемыми движениями лица и наземной истиной.
Разница в значении скорости (LVD):Введенный [68], LVD рассчитывает разницу в скорости генерируемых достопримечательностей лица и основной истины.
Beat постоянство (до н.э.)[29]: BC оценивает синхронность сгенерированных движений и поют вокал, вычисляя сходство между ритмом жестов и аудио -ритмом. В частности, мы извлекаем аудиозиаты с использованием Librosa [36] и вычислим кинематические ритмы как локальные минимумы скорости суставов. Затем оценка выравнивания получена от средней близости движения до ближайшего аудио -бита.
Для оценки качества пения вокального поколения используется средний балл мнения (MOS). Он отражает воспринимаемую естественность синтезированных вокальных тонов, при этом человеческие оценщики оценивают каждый образец по шкале от 1 до 5, что предлагает субъективную меру вокального синтеза.
A.4 Дополнительные исследования абляции
Абляция на токенизаторе движения.Мы изучаем различные конструкции нашего токенизатора движения, сравнивая результаты реконструкции. В частности, мы исследуем VQ-VAE с различными размерами кодовой книги и изучаем эффект использования одного VQ-VAE для моделирования движений всего тела вместо нескольких VQ-VAE для разных частей тела. Как показано в таблице. 4, мы обнаруживаем, что использование отдельных VQ-VAE для лица, тела и рук имеет более низкую ошибку реконструкции. И мы выбираем размер кодовой книги 512 для нашей окончательной модели.
Абляция на вокальном токенизаторе.Мы также изучаем различные дизайны для нашего аудио -токенизатора, сравнивая результаты реконструкции. В частности, мы исследуем различные размеры кодовых книг для семантического энкодера, изменяя номер K-среднего. Мы также сравниваем эффект с нашим певцом, встраивающимся в постобработку значений F0. Мы используем следующие показатели для измерения качества реконструкции вокального токенизатора:
![Table 4: Evaluation of our motion tokenizer. We follow [34] to evaluate the motion reconstruction errors of our motion VQVAE model Vm. MPJPE and PAMPJPE are measured in millimeters. ACCL indicates acceleration error.](https://cdn.hackernoon.com/images/hYnD3aGcZIgKnjRGl8QfkZDGyBF2-yi832yj.png)
Частота ошибок символа (CER):Мы используем Whisper [46] для расшифровки основной истины и синтезированных звуков, а затем придерживаемся соответствующей текста основной истины в качестве ссылки на расчет CER синтезированных звуков.
Ошибка валового шага (GPE):Процент оценок шага, которые имеют отклонение более 20% вокруг истинного шага. Рассматриваются только кадры, рассматриваемые как основной истиной, так и синтезированным звуком.
Ошибка принятия решения (VDE)[38]: часть кадров с ошибкой решения о голосовании, то есть результаты с использованием наземной правды и синтезированного звука, чтобы определить, отличается ли кадр, отличается.
![Table 5: Evaluation of our unit2wav model. We follow [45] to evaluate the speech resynthesis errors of our unit2wav model. WER, GPE, and VDE, expressed as percentages, indicate the character error rate, the grand pitch error and the voicing decision error.](https://cdn.hackernoon.com/images/hYnD3aGcZIgKnjRGl8QfkZDGyBF2-jc9325k.png)
Анализ результатов показывает, что даже исходный звук демонстрирует высокий CER, который может быть связан с быстрым уровнем речи, связанной с рэпом. В некоторых случаях текст может быть отчетливо узнаваемы даже человеческими слушателями. Сравнивая различные размеры кодовой книги, наблюдается, что они достигают сопоставимых значений GPE. Это сходство в GPE ожидается, поскольку одна и та же модель F0 используется во всех размерах кодовой книги. CER, который служит прямой мерой семантической информации, сохранившейся в коде, предполагает, что более крупные кодовые книги имеют тенденцию сохранять более семантическую информацию. Тем не менее, разница в CER между размерами кода K = 500 и K = 2000 минимальна. Учитывая, что k = 500 демонстрирует лучшие GPE и VDE, мы выбираем K = 500.
Кроме того, мы поднимаем дизайн без встраивания певца в предварительную обработку F0, вместо этого нормализуя значения F0 для каждого певца. Это показывает, что этот подход приводил к значительно низкой производительности, особенно в прогнозировании высоты тона, по сравнению с модифицированной версией, которая включает в себя встраивание певца.
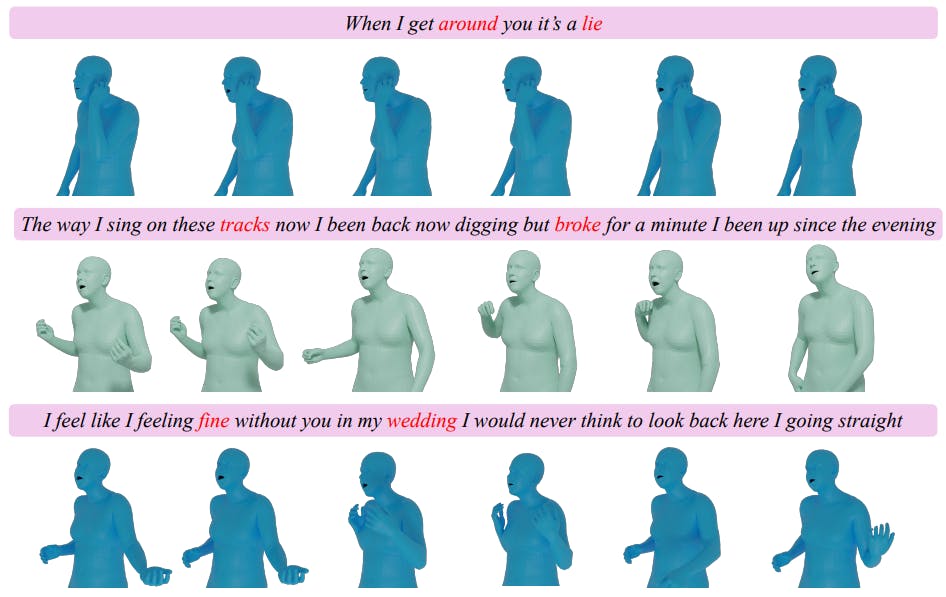
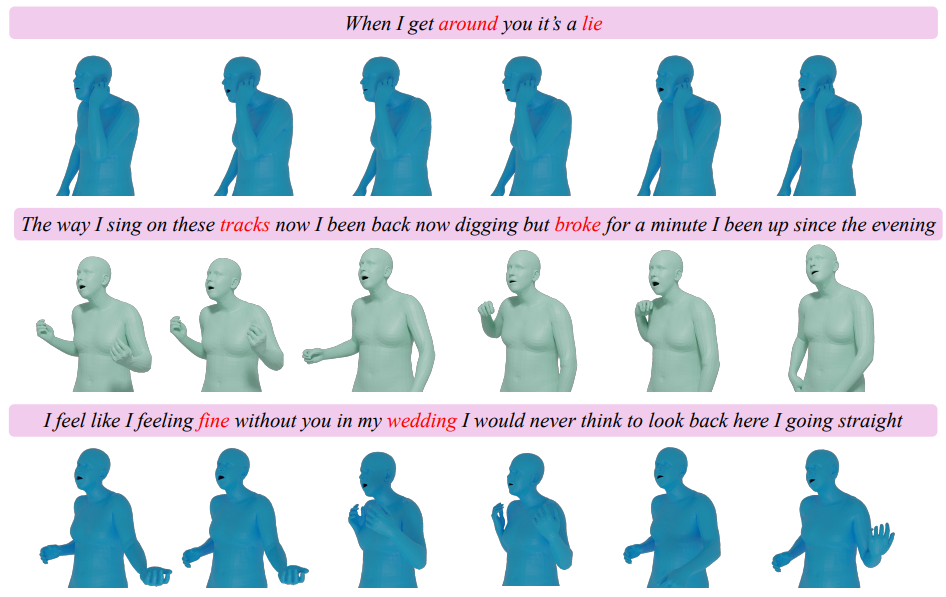
A.5 Дополнительные качественные результаты
Мы показываем дополнительные качественные результаты на рис. 4. Наша модель искусно генерирует всеобъемлющие движения цельного тела, которые воплощают сущность входных текстов. К ним относятся подлинные движения жестов, которые резонируют с ритмом песни и синхронизированными движениями губ, которые сформулируют тексты.
A.6 Более широкие воздействия
Это исследование способствует достижениям в генерации синхронизированного вокала и человеческого движения из текстовой текста, стремясь повысить способность виртуальных агентов обеспечивать захватывающие и интерактивные
Опыт в цифровых медиа. Потенциальное положительное влияние этой работы заключается в ее способности создавать более реалистичные и привлекательные виртуальные выступления, такие как виртуальные концерты и игры, где персонажи могут работать и реагировать способами, которые глубоко резонансны с человеческими выражениями. Это может значительно улучшить вовлечение пользователей в условиях виртуальной реальности и предоставить инновационные решения в области развлекательной индустрии.
Тем не менее, эта возможность несет неотъемлемые риски злоупотребления. Способность технологии генерировать реалистичные человеческие действия и пение вокала из простого текста вызывает обеспокоенность по поводу его потенциала для создания вводящего в заблуждение или обманчивого контента. Например, это может быть использовано для производства поддельных видео или глубоких флажок, где люди, кажется, пеют и работают, которые никогда не возникали, которые можно было бы использовать для распространения дезинформации или повреждения репутации. Признавая эти риски, крайне важно защищать этические руководящие принципы и надежные рамки, чтобы обеспечить ответственное использование таких технологий.
Авторы:
(1) Цзябен Чен, Университет Массачусетса Амхерст;
(2) Синь Ян, Университет Ухана;
(3) Ихан Чен, Университет Ухан;
(4) Сиюань Сен, Университет штата Массачусетс Амхерст;
(5) Qinwei MA, Университет Цинхуа;
(6) Хаою Чжэнь, Университет Шанхай Цзяо Тонг;
(7) Каижи Цянь, MIT-IBM Watson AI Lab;
(8) ложь Лу, Dolby Laboratories;
(9) Чуан Ган, Университет штата Массачусетс Амхерст.
Эта статья есть
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27294)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)