Введение
22 сентября 2022 г. вторая по величине телекоммуникационная компания Австралии, Optus, объявил о серьезной утечке данных. Хотя подробности об утечке данных не разглашаются, в сообщениях указывается, что утечка была вызвана человеческим фактором. В этой записи блога мы подробно расскажем о том, что произошло, и о том, как организации могут предпринять шаги, чтобы избежать такого нарушения.
Причина
Optus предоставила свою базу данных идентификации клиентов интерфейсу прикладного программирования (API) для использования во внутренних системах. Такое упражнение распространено в крупных организациях, которые должны постоянно изменять средства управления доступом к различным базам данных в компании. Однако в данном случае API был общедоступным без аутентификации. Это означает, что любой может получить доступ к этим данным через конечную точку API https://www.optus.com.au/mcssapi/rp-webapp-9-common/customer-management/contact-person/{ contactId}?lo=en_US&sc=SS.
Это классический случай ошибки перечисления, когда следующую информацию о пользователе можно получить, запросив contactId + 1. Хакеры использовали contactId, чтобы получить личные данные более 2 миллионов пользователей Optus.
Как этого можно было избежать?
Со скоростью разработки программного обеспечения становится все труднее отслеживать приложения, имеющие доступ к данным клиентов. Ограничение доступа и ручная проверка могут замедлить работу разработчика и сократить инновационный цикл организации. Кроме того, при ежедневной фиксации сотен кодов инженерам по безопасности данных и конфиденциальности становится невозможно отслеживать все изменения и выявлять уязвимости конфиденциальности.
Чтобы помочь организациям справиться с этой проблемой, требуется определенная форма автоматизации. Организациям необходима видимость в режиме реального времени потоков данных между несколькими приложениями и базами данных. Им необходимо знать, какие приложения или репозитории имеют доступ к тем или иным данным и как они раскрываются миру. Использование методов оценки или ручного моделирования угроз для получения этой информации является медленным и часто неполным.
Чтобы решить эту проблему, организации должны приблизить свои оценки к рабочим процессам разработчиков. С помощью процессов сдвига влево организации могут отслеживать, выявлять и устранять такие уязвимости безопасности данных. Это включает в себя интеграцию инструментов и рабочих процессов в конвейеры CI/CD, чтобы автоматизировать обнаружение рисков и избежать трудоемких оценок. Это также помогает предотвратить любые неожиданности со стороны специалистов по обеспечению конфиденциальности или безопасности в последнюю минуту и позволяет командам иметь четкое представление об ограничениях.
Представьте, если бы компания Optus могла определить, что новая тестовая сеть обращается к их базе данных идентификации клиентов, и что они раскрывают эту информацию через общедоступный API. Все это произошло, как только разработчик зафиксировал эти изменения. Это вызвало бы тревогу у группы безопасности приложений, и они могли бы быстро принять меры для защиты кода.
Обнаружение API с помощью открытого исходного кода Privado
Чтобы обнаруживать потоки данных в режиме реального времени и минимизировать проблемы с безопасностью приложений, мы можем использовать Privado, инструмент сканирования статического кода с открытым исходным кодом, который помогает разработчикам и организациям отслеживать, обнаруживать и устранять проблемы безопасности данных во время фиксации.
Для этого примера мы возьмем репозиторий, который обрабатывает пользовательские данные. Предположим, у нас есть старый репозиторий BankingSystem-Backend со всеми настройками безопасности, которые обрабатывают личные данные клиентов. Сначала мы сканируем репозиторий с помощью Privado и находим существующие API, обрабатывающие пользователя. данные. Чтобы отсканировать проект, мы делаем следующие шаги:
Шаг 1. Клонируйте необходимые репозитории
git clone https://github.com/saurabh-sudo/BankingSystem-Backend
git clone https://github.com/Privado-Inc/privado
Шаг 2. Установите Privado
curl -o- https://raw.githubusercontent.com/Privado-Inc/privado-cli/main/install.sh | bash
Шаг 3. Запустите сканирование
privado scan BankingSystem-Backend
После завершения сканирования мы можем просмотреть результаты в BankingSystem-Backend/.privado/privado.json. Чтобы интерпретировать результаты, вы можете обратиться к следующему руководству. В разделе «Коллекции» в результате мы видим, что сканирование Privado обнаружило 2 API, которые собирают пользовательские данные. Однако в приложении есть еще несколько API, которые также обрабатывают некоторые данные — возможно, не пользовательские. Один из таких примеров показан ниже:
@GetMapping("/getById/{id}")
public ResponseEntity getById(@PathVariable Long id) throws Exception {
try {
Account acc = accountDao.findById(id).get();
return ResponseEntity.ok(acc);
} catch (Exception e) {
System.out.println("Error is " + e);
return new ResponseEntity(HttpStatus.BAD_REQUEST);
}
}
По умолчанию сканирование Privado не обнаруживает этого, поскольку неясно, связаны ли данные с пользователем. Итак, давайте предположим, что мы просматриваем код и обнаруживаем этот фрагмент выше. Мы немного чешем в затылках и решаем, что нам следует начать отслеживать любые данные, ведущие к DAO учетной записи, которые у нас есть, поскольку похоже, что данные могут входить и выходить отсюда. Для этого мы можем определить простое правило в Privado для обнаружения API, которые предоставляют все записи в базе данных, используя метод JDBC findById(), который извлекает конкретную запись из базы данных. . Затем мы помечаем эти утечки как стоки. Мы должны поместить вышеуказанное правило в rules/sinks/storages/jdbc/java.yaml проекта Privado файл:
sinks:
- id: Storages.SpringFramework.AccountDao.Read
name: AccountDao JBDC Connector
patterns:
- "(i?)com.common.BankData.dao.AccountDao.*findById.*"
tags:
Теперь, чтобы передать эти пользовательские правила сканированию, мы запускаем privado scan BankingSystem-Backend -c
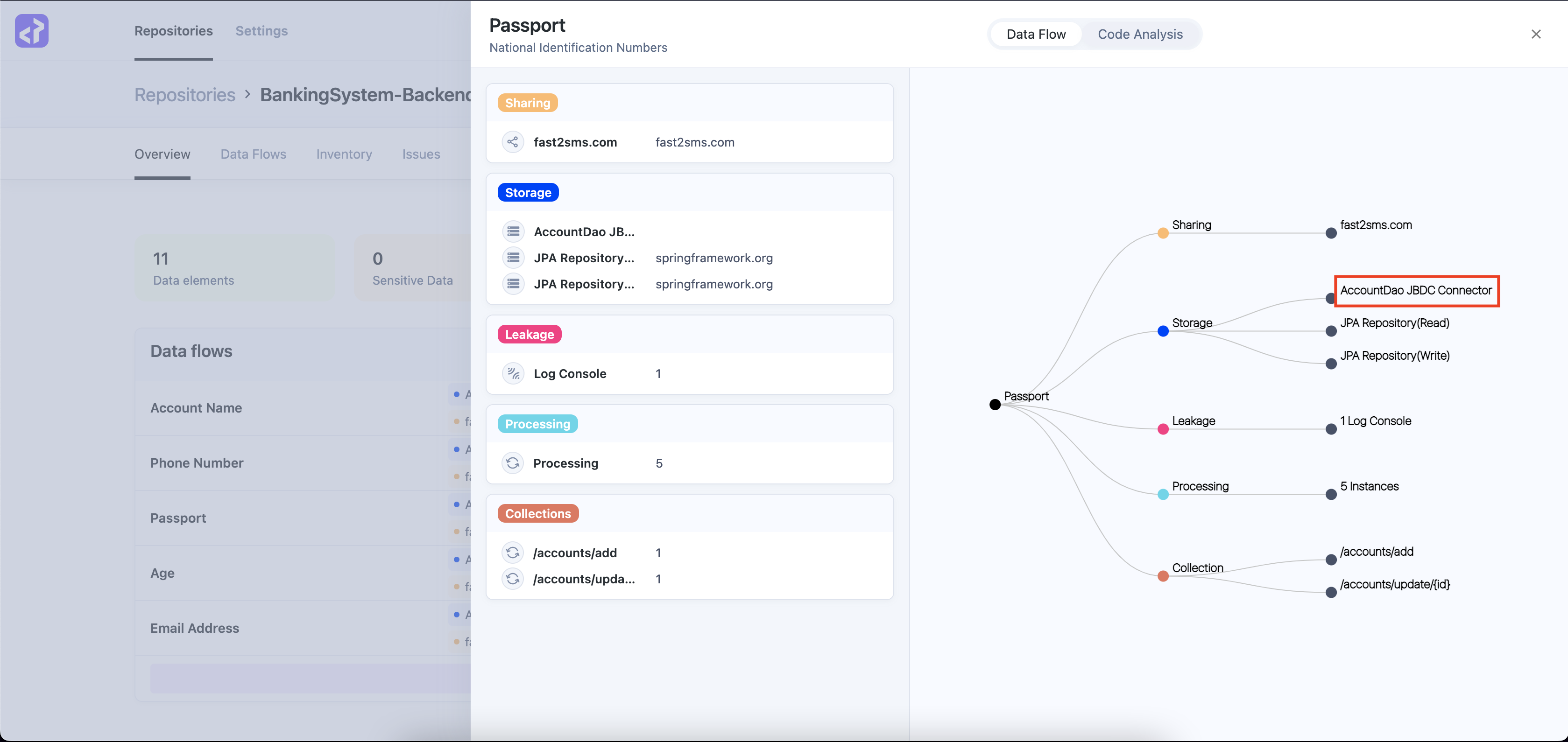
Он также генерирует построчный анализ кода, который разработчики могут просмотреть, чтобы понять поток информации внутри кода. Обратите внимание, что этот процесс не решает саму проблему. Однако это помогает улучшить видимость потока данных в организации и сотрудничество между разработчиками и инженерами по безопасности данных. Это особенно полезно в крупных организациях, где ежедневно вносятся сотни изменений в код и в кодовую базу добавляются новые репозитории.
Вы можете сами проверить этот инструмент на GitHub. Не стесняйтесь публиковать любые вопросы или вносить свой вклад в проект.
:::информация Также опубликовано здесь.
:::