

Как я успешно «перепроектировал» ChatGPT для создания неофициальной оболочки API
20 декабря 2022 г.И мои усилия стали бесполезными через 3 часа.
Всем привет, хочу рассказать вам историю, которая произошла буквально несколько дней назад.
Как известно, ChatGPT всколыхнул все мировое сообщество, причем не только из ИТ-сектора. Эксперты и ученые со всего мира проверяют, насколько хорошо эта нейросеть отвечает на заданные вопросы, Stackoverflow срочно вводит ограничения на публикацию ответов с помощью ChatGPT, на специализированных форумах идет новая дискуссия о том, как скоро работа программистов будет автоматизирована .
Меня в первую очередь интересовало, можно ли будет полностью автоматизировать процесс авторизации, отправки запросов и получения ответов в ChatGPT, чтобы я мог использовать получившийся модуль на сервере для каких-то экспериментов и просто испортить удовольствие.
Должен заметить, что я начал изучать ChatGPT довольно поздно, около 7 декабря. Когда я заглянул на GitHub, то увидел, что там уже есть несколько проектов, но все они были сделаны с помощью браузеров (таких как Selenium, Playwright и другие инструменты тестирования). Мне это показалось недостаточно спортивным, я хотел получить решение исключительно на простых HTTP-запросах, поэтому приступил к работе.
Поехали!
Инструментарий
- Инструменты разработчика Chrome
- Wireshark
- Python (httpx, bs4)
Глава 1. Авторизация
Обычно, когда дело доходит до автоматизации доступа к некоторым сервисам, прохождение авторизации вызывает много головной боли. Напротив, во время тестирования ChatGPT я видел только простую капчу, и она появляется очень редко. Иногда я также видел сообщение о временной блокировке учетной записи и необходимости смены пароля, но это, как оказалось, было связано с самим паролем: для тестовой учетной записи я использовал предельно простой пароль, который уже давно замечен в различных утечках данных. . После замены на более сложный проблема ушла.
Авторизация в ChatGPT состоит из нескольких шагов:
- Получение ключа CSRF с помощью простого запроса GET:
req = session.get("https://chat.openai.com/api/auth/csrf")
csrf = req.json().get("csrfToken")
- Получение ссылки для авторизации с помощью простого POST-запроса:
параметры = {
"callbackUrl": "/",
"csrfToken": csrf,
"json": "true"
<код>
req = session.post(
"https://chat.openai.com/api/auth/signin/auth0?prompt=login", data=params
)
login_link = req.json().get("url")
- Открытие страницы входа — может быть капча в .svg:
req = session.get(login_link)
response = BeautifulSoup(req.text, features="html.parser")
captcha = resp.find("img", {"alt": "captcha"})
если капча:
src = captcha.get("src").split(",")[1]
с открытым("captcha.svg", "wb") как fh:
fh.write(base64.urlsafe_b64decode(src))
- Получить уникальный параметр state из кода страницы:
response.find("input", {"name": "state", "type": "hidden"}).get("value")
- Отправка электронного письма с необязательным кодом проверки на следующую страницу:
параметры = {
"состояние": "<состояние>",
"имя пользователя": "<электронная почта>",
"captcha": "<captcha_code or None>",
"js-доступно": "true",
"веб-доступно": "true",
"храбрый": "false",
"доступна веб-платформа": "false",
"действие": "по умолчанию"
<код>
url = f"https://auth0.openai.com/u/login/identifier?state={state}"
req = session.post(url, data=params)
- Повторное получение параметра состояния (шаг 4)
7. Отправка электронного письма и пароля:
параметры = {
"состояние": "<состояние>",
"имя пользователя": "<электронная почта>",
"пароль": "<пароль>",
"действие": "по умолчанию"
<код>
url = f"https://auth0.openai.com/u/login/password?state={state}"
req = session.post(url, data=params)
n И все! Конечно, нюансов было больше, например с заголовками (нужно точно повторять Content-type и другие заголовки). Ну и конечно нужно инициализировать httpx.Client с поддержкой протокола http2, бережно сохраняя все сессионные куки. Но в целом проблем не было.
Мой любимый Chrome Dev Tools – это лучший инструмент для просмотра и повторного воспроизведения запросов, мне показалось. Но это оказалось не совсем так.
Глава 2. Отправка сообщения
Снова активируйте вкладку Fetch/XHR на панели Chrome Network и начните отправку тестового сообщения.
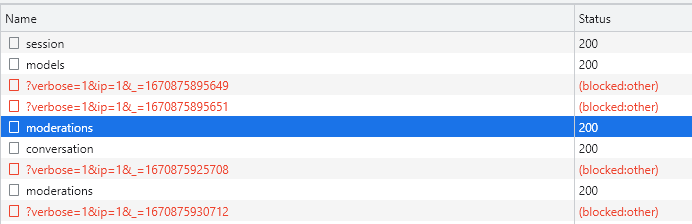
Мы видим, что при отправке сообщения отправляются два запроса: к модерациям и к конечным точкам.
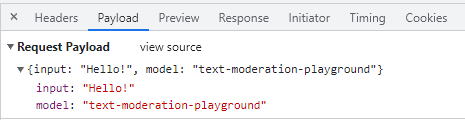
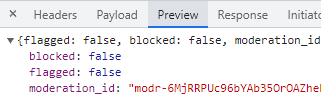
n С модерациями все понятно и прозрачно: отправляем набранный текст, указываем модель ChatGPT, в ответ получаем moderation_id (что бы это ни значило).
А как насчет беседы?
В payload видим, что текст не отправляется, только ID, причем 2 разных!
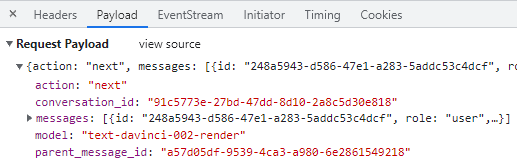
И вместо вкладок Preview/Response нас встречает EventStream, с которым я раньше не сталкивался. Более того, вкладка EventStream пуста!
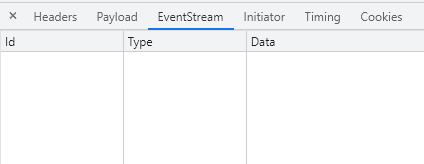
Я начал долгий поиск того, откуда берутся эти идентификаторы сообщений. Я проверил код страниц, заголовки, все, что мог. И... ничего!
Гипотеза 1: они генерируются на стороне клиента
Перейдите на вкладку "Источники" и поставьте точку останова на любом событии XHR:
Мы снова отправляем тестовое сообщение и начинаем многочасовое погружение в лабиринт минимизированного (и обфусцированного?) кода, расставляя все новые и новые точки останова.
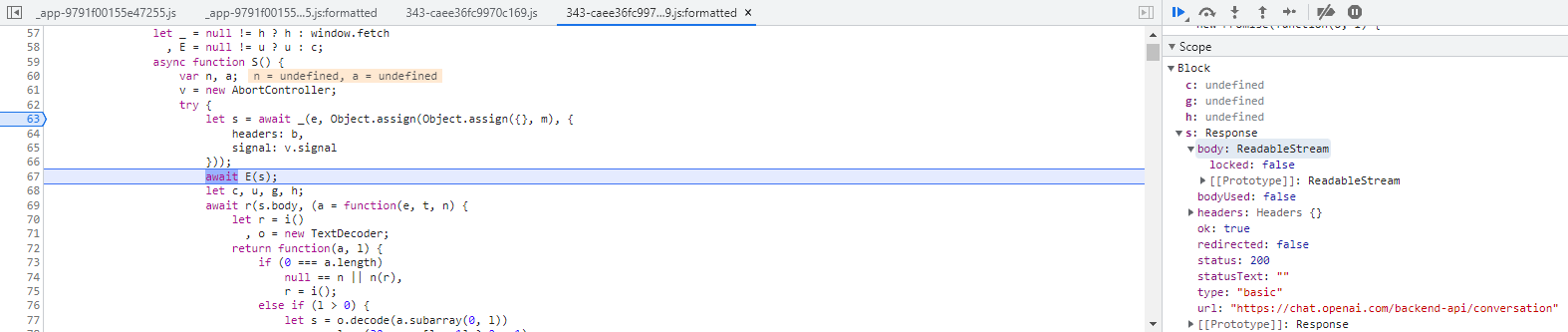
В процессе этого погружения мне не удалось найти, где генерируются эти идентификаторы. Я не очень хорошо разбираюсь в отладке JS, поэтому перешел к следующей гипотезе.
Гипотеза 2: не вся сетевая активность регистрируется на вкладке "Сеть"
Довольно очевидно, не так ли? Я начал с Chrome Network Log, с которым раньше не сталкивался. Он находится по адресу:
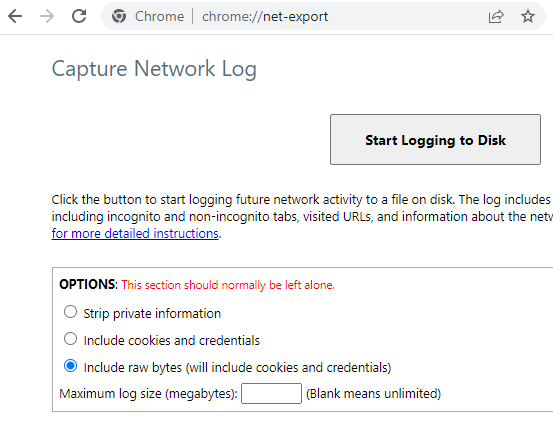
Нажмите Start Logging to Disk, вернитесь на вкладку ChatGPT, отправьте еще одно тестовое сообщение. Вернитесь в сетевой журнал, остановите ведение журнала и перейдите в Netlog Viewer.
Что мы там видим?
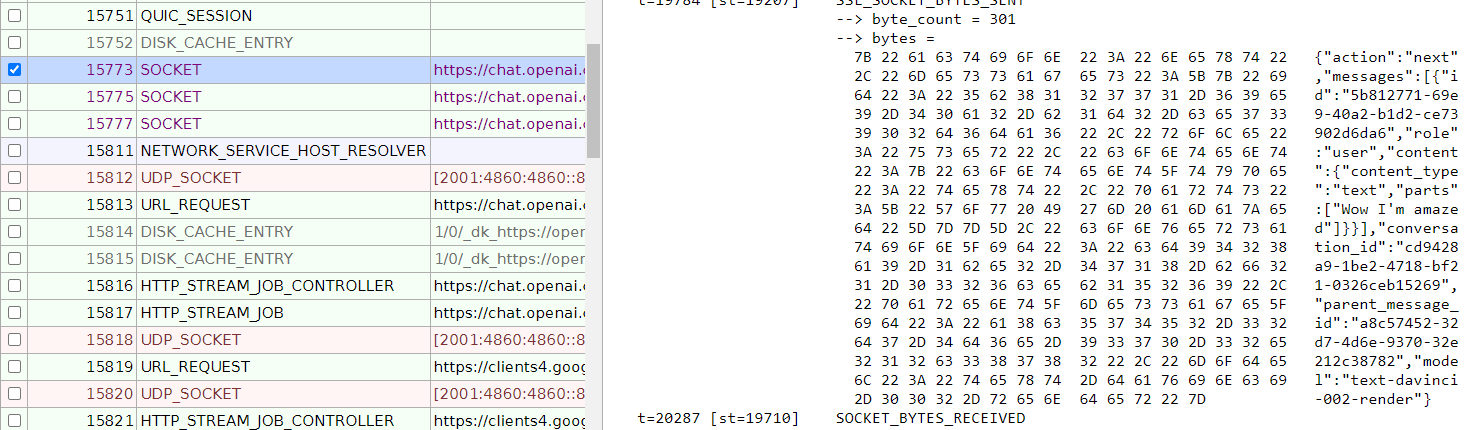
Мы снова видим отправку некоторых идентификаторов!
В этот момент я был готов сдаться и бросить все. Но я решил попробовать Wireshark. В последний раз, когда я запускал его, это было так давно, что SSL-сертификаты еще не были повсеместно распространены, а трафик был очевиден.
Вот почему мне пришлось пройти еще один квест — установить переменную среды для декодирования TLS-пакетов в Wireshark.
Подробно все описывать не буду, но в итоге и этот подход не сработал. Видимо, я не умею готовить Wireshark.
Гипотеза 3: Нуууууууууу!
Попробуем просто отправлять запросы!
Сначала мы отправляем случайный UUID4 вместо всех идентификаторов. Конечно, это не сработало.
Затем я просто попытался отправить тот же разговор_идентификатор, но с другим текстом сообщения, который я видел в журналах браузера. И это сработало! Попробовав другие комбинации, я выяснил, какие параметры требуются, а какие могут быть случайными.
Окончательный код для отправки сообщения:
n session.headers.update({
"accept": "текст/поток событий",
"X-OpenAI-Assistant-App-Id": "",
"Авторизация": f"Носитель {токен}"
})
параметры = {
"действие": "далее",
"сообщения": [
{
"id": str(uuid.uuid4()), # <-- random!
"роль": "пользователь",
"контент": {
"content_type": "текст",
"parts": ["<сообщение>"]
<код>
<код>
],
"parent_message_id": "", # <-- пусто!
"model": "<chatgpt_model>"
<код>
с помощью session.stream(
"POST", "https://chat.openai.com/backend-api/conversation",
json=params, headers={"content-type": "application/json"}
) в качестве ответа:
для чанка в response.iter_bytes():
печать(фрагмент)
n Глава 3: Грустный конец
Я был безумно счастлив, что смог выполнить этот квест. Я немного подправил код, загрузил это доказательство концепции на GitHub и лег спать, планируя чтобы закончить его на следующий день. Планы были довольно просты:
- Автоматическое распознавание капчи.
- Ведение диалогов
- Формализация кода как пакета
и многое другое.
На следующее утро я открываю свой компьютер, запускаю код и... ничего не работает! Прошло всего несколько часов, и за это время ChatGPT сменил капчу на Google Recaptcha и, самое главное, включил защиту Cloudflare. Для этого требуется эмуляция браузера, выполнение JS и многое другое, что полностью разрушило первоначальную идею использования простых HTTP-запросов.
В любом случае, я прекрасно провел время и получил отличный опыт!
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
20 самых популярных статей TechRepublic в 2023 году
23 декабря 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27720)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Социальные медиа и интернет-культура (107)
- Экономика и финансы (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)