
Укрепление безопасности LLM: ответственное выравнивание AI PHI-3
8 июля 2025 г.Таблица ссылок
Аннотация и 1 введение
2 технические характеристики
3 академические тесты
4 Безопасность
5 Слабость
6 Phi-3-Vision
6.1 Технические спецификации
6.2 академические тесты
6.3 Безопасность
6.4 Слабость
Ссылки
Пример подсказки для тестов
B Авторы (алфавитный)
C подтверждения
4 Безопасность
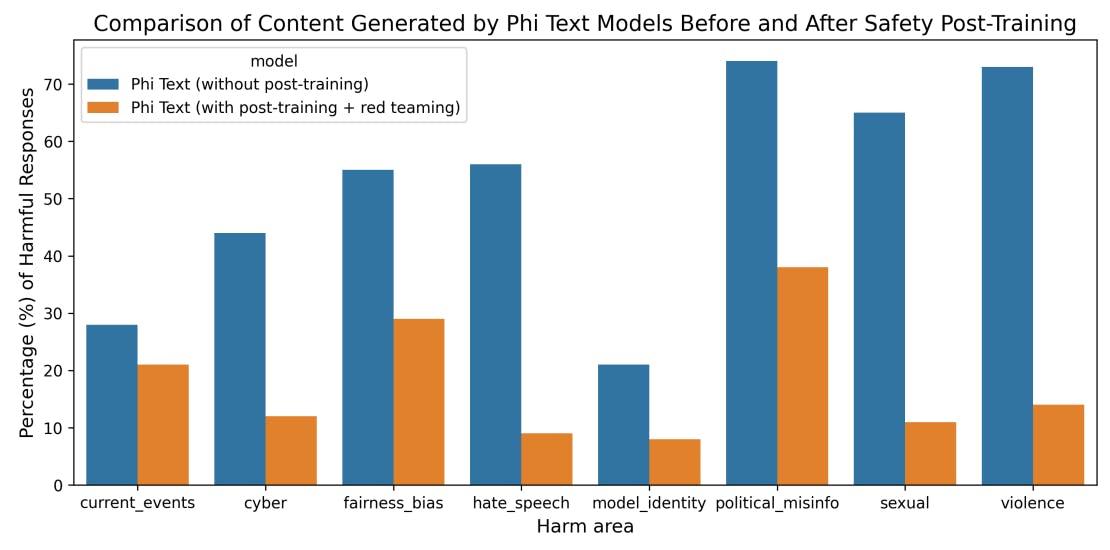
Phi-3-Miniбыл разработан в соответствии с ответственными принципами ИИ Microsoft. Общий подход состоял из выравнивания безопасности в пост-тренировочном, красном командовании, автоматическом тестировании и оценках по десяткам категорий RAI вреда. Наборы данных о полезности и безвредных предпочтениях [BJN+ 22, JLD+ 23] с модификациями, вдохновленными [BSA+ 24], и множественные внутренние наборы данных были использованы для решения категорий RAI HARM в области безопасности. Независимая красная команда в Microsoft итеративно осмотрелаPhi-3-MiniДля дальнейшего определения областей улучшения во время процесса после тренировки. Основываясь на их обратной связи, мы курировали дополнительные наборы данных, адаптированные для решения их понимания, тем самым уточнив набор данных после обучения. Этот процесс привел к значительному снижению вредных частот ответа, как показано на рисунке 4.
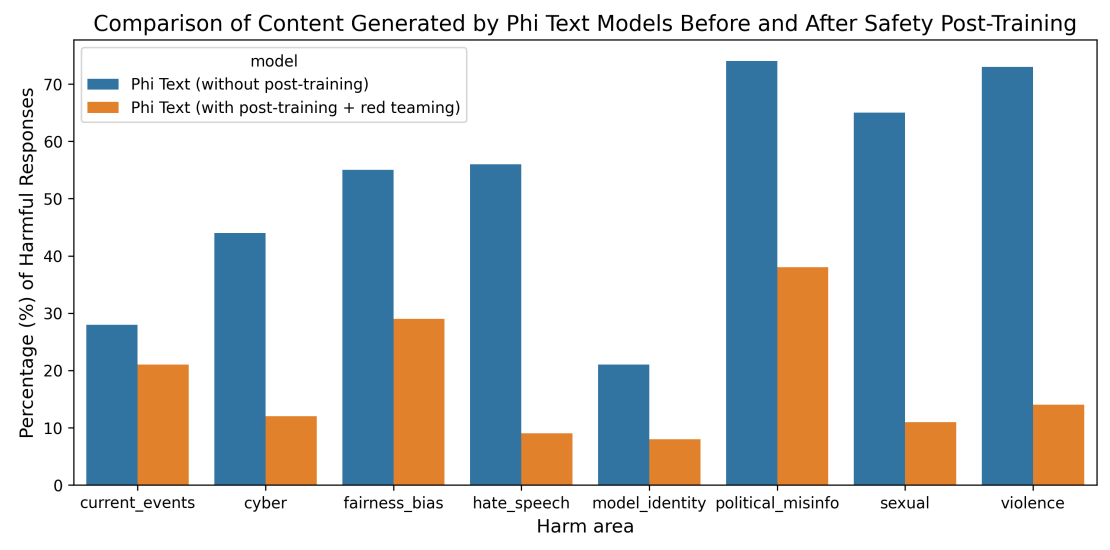
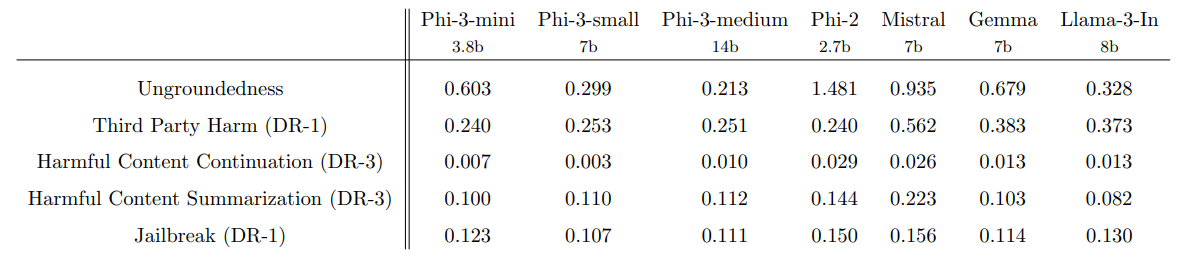
Выравнивание безопасностиPhi-3-SmallиPhi-3-Mediumпроводился путем прохождения того же процесса красного команды, с использованием идентичных наборов данных и включения немного большего количества образцов. В таблице 1 показаны результаты внутренних тестов RAI [MHJ+ 23] дляPHI-3Модели по сравнению с PHI-2 [JBA+ 23], MISTRAL-7B-V0.1 [JSM+ 23], GEMMA 7B [TMH+ 24] и Llama-3-instruct-8B [AI]. В этом эталоне использовались GPT-4 для моделирования многократных разговоров в пяти различных категориях и для оценки ответов на модели. Необоснованность между 0 (полностью заземленными) и 4 (не заземленными) измерениями, если информация в ответе основана на данной подсказке. В других категориях ответы были оценены с точки зрения тяжести вредности от 0 (без вреда) до 7 (крайний вред), а показатели дефектов (DR-X) были рассчитаны как процент образцов, при этом показатель серьезности превышал или равен X.
Авторы:
(1) Мара Абдин;
(2) Сэм Аде Джейкобс;
(3) Аммар Ахмад Аван;
(4) jyoti aneja;
(5) Ахмед Авадаллах;
(6) Hany Awadalla;
(7) Нгуен Бах;
(8) Амит Бахри;
(9) Араш Бахтиари;
(10) Цзянмин Бао;
(11) Харкират Бел;
(12) Алон Бенхайм;
(13) Миша Биленко;
(14) Йохан Бьорк;
(15) Sébastien Bubeck;
(16) Цин Цай;
(17) Мартин Кай;
(18) Caio César Teodoro Mendes;
(19) Вейджу Чен;
(20) Вишрав Чаудхари;
(21) Донг Чен;
(22) Дундонг Чен;
(23) Йен-Чун Чен;
(24) Йи-Линг Чен;
(25) Парул Чопра;
(26) Xiyang Dai;
(27) Элли Дель Джирно;
(28) Густаво де Роза;
(29) Мэтью Диксон;
(30) Ронен Эльдан;
(31) Виктор Фаросо;
(32) Дэн Итер;
(33) Мэй Гао;
(34) мин Гао;
(35) Цзянфенг Гао;
(36) Амит Гарг;
(37) Абхишек Госвами;
(38) Сурия Гунасекар;
(39) Эмман Хайдер;
(40) Junheng Hao;
(41) Рассел Дж. Хьюитт;
(42) Джейми Хьюнх;
(43) Mojan Javaheripi;
(44) Синь Джин;
(45) Пьеро Кауфманн;
(46) Никос Карампатцциакис;
(47) Dongwoo Kim;
(48) Махоуд Хадеми;
(49) Лев Куриленко;
(50) Джеймс Р. Ли;
(51) Инь Тэт Ли;
(52) Юаньжи Ли;
(53) Юншенг Ли;
(54) Чен Лян;
(55) Ларс Лиден;
(56) CE Liu;
(57) Менгхен Лю;
(58) Вайшунг Лю;
(59) Эрик Лин;
(60) Zeqi Lin;
(61) Чонг Луо;
(62) Пиюш Мадан;
(63) Мэтт Маццола;
(64) Ариндам Митра;
(65) Хардик Моди;
(66) ANH NGUYEN;
(67) Брэндон Норик;
(68) Барун Патра;
(69) Даниэль Перес-Бекер;
(70) Портет Томаса;
(71) Рейд Прайзант;
(72) Хейанг Цинь;
(73) Марко Радмилак;
(74) Корби Россет;
(75) Самбудха Рой;
(76) Olatunji Ruwase;
(77) Олли Саарикиви;
(78) Амин Саид;
(79) Адил Салим;
(80) Майкл Сантакрос;
(81) Шитал Шах;
(82) Нин Шан;
(83) Хитеши Шарма;
(84) Свадхин Шукла;
(85) Sia Song;
(86) Масахиро Танака;
(87) Андреа Тупини;
(88) Синь Ван;
(89) Лиджуань Ван;
(90) Чуню Ван;
(91) Ю Ван;
(92) Рэйчел Уорд;
(93) Гуанхуа Ван;
(94) Филипп Витте;
(95) haiping wu;
(96) Майкл Уайетт;
(97) бен Сяо;
(98) может XU;
(99) Цзяхан Сюй;
(100) Weijian Xu;
(101) Сонали Ядав;
(102) вентилятор Ян;
(103) Цзяньвей Ян;
(104) Зийи Ян;
(105) Йифан Ян;
(106) Донган Ю;
(107) Лу Юань;
(108) Chengruidong Zhang;
(109) Кирилл Чжан;
(110) Цзянвен Чжан;
(111) Ли Лина Чжан;
(112) И Чжан;
(113) Юэ Чжан;
(114) Юнан Чжан;
(115) Ксирен Чжоу.
Эта статья есть
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Лучшие новогодние подарки для владельцев домашних животных
29 мая 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27342)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)