Что общего между шаблонами проектирования GraphQL и ООП? Сначала они кажутся довольно крутыми, но потом вы понимаете, что в большинстве случаев это излишество. В других случаях они будут спасением.
Чтобы GraphQL стал спасением, вам действительно нужно понять, как его использовать.
Давайте рассмотрим пример запроса GraphQL, который извлекает N = 10 сообщений и автора для каждого сообщения:
posts(limit: 10) {
id
title
author {
id
name
}
}
В простейшей реализации этого запроса порядок операций будет примерно таким:
- Выбрать N записей из БД
- Для каждого сообщения:
- Разрешить идентификатор →
post.id - Исправить заголовок →
post.title - Разрешить автора → получить автора из БД по идентификатору
Это будет означать 1 запрос для N постов и N запросов для N авторов → следовательно, проблема N+1. В идеале вместо N запросов findById(id) был бы всего один запрос findByIds(id). Тогда каждый преобразователь мог бы взять автора, который ему нужен, по id. Подобные пакетные запросы в разных языках программирования выполняются по-разному, и у этого шаблона обычно есть такие имена, как загрузчик данных или пакетный загрузчик.
Для каждого типа данных требуется отдельный тип загрузчика данных. Для разрешения автора по id потребуется один загрузчик данных. Для определения количества комментариев к посту следует использовать другой. Третий потребуется для разрешения его тегов. Для определения количества лайков для каждого комментария потребуется четвертый тип загрузчика данных и так далее. Все эти загрузчики данных обычно сгруппированы для удобства использования.
Помимо пакетных операций ввода-вывода, загрузчики данных могут и обычно кэшируют извлеченные данные. Таким образом, его можно будет извлечь из кеша, если он понадобится снова, в течение времени существования экземпляра загрузчика данных. При желании кеш можно отключить, и в этом случае загрузчик данных будет выполнять только пакетную обработку.
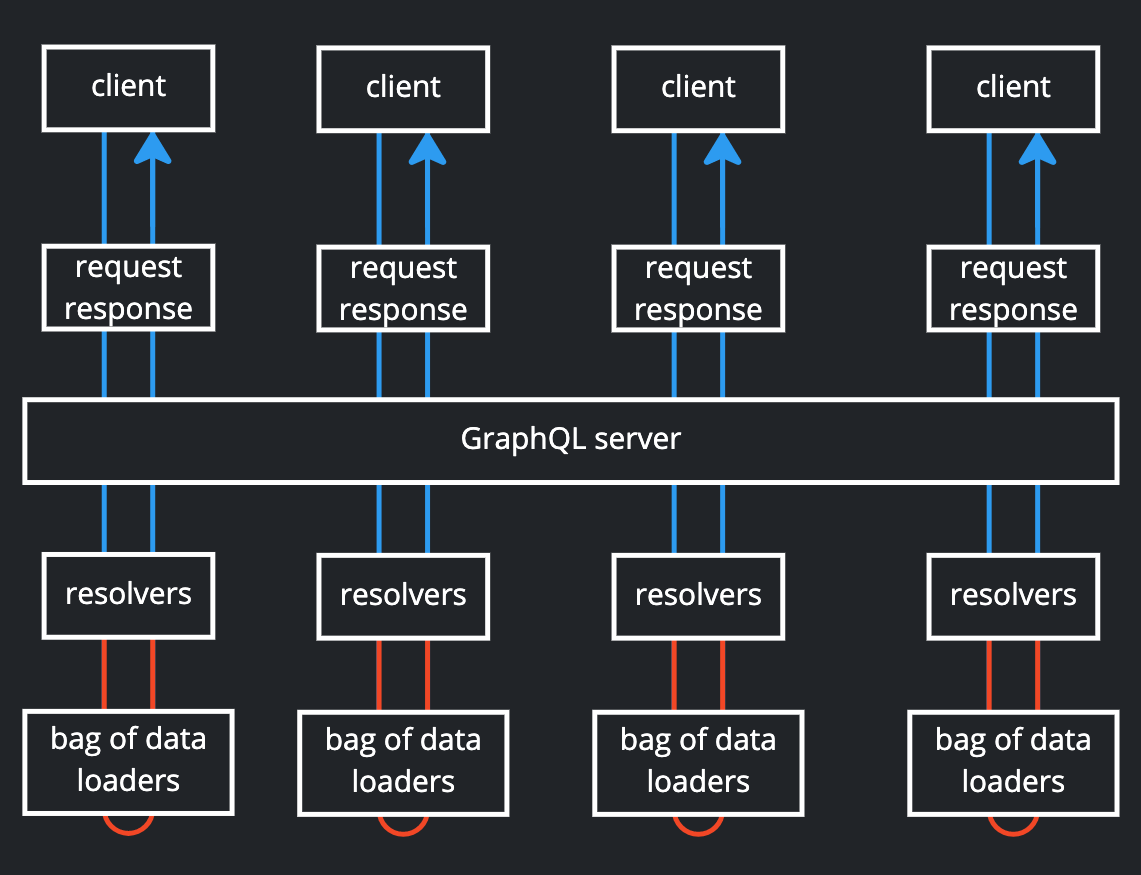
GraphQL имеет 3 типа операций: запрос, мутация и подписка. Запросы и мутации — это обычные HTTP-запросы, а подписки — это долгоживущие соединения, обычно реализуемые с помощью веб-сокетов.
Загрузчики данных в запросах и мутациях GraphQL
Загрузчики данных не предназначены для совместного использования несколькими HTTP-запросами. Вот почему, когда клиент делает HTTP-запрос к серверу GraphQL, создаются экземпляры всех загрузчиков данных (пакет загрузчиков), и этот объект пакета прикрепляется к объекту контекста запроса. Затем каждый преобразователь может извлечь из контекста нужный ему загрузчик и использовать его. После отправки ответа объект контекста удаляется вместе со всеми загрузчиками данных и содержащимися в нем кэшированными значениями.
Загрузчики данных в подписках
Использование загрузчиков данных в подписках сложнее, чем запросы и мутации. Соединение между клиентом (подписчиком) и сервером (издателем) устанавливается один раз и остается открытым. Для каждого соединения существует один объект контекста, который существует, пока соединение открыто. Но загрузчики данных не должны использоваться совместно для разных публикуемых событий, поскольку два события могут быть разделены любым промежутком времени. Кроме того, хранение такого большого объема данных в памяти приложения в течение более длительного периода времени почти никогда не является хорошей идеей.
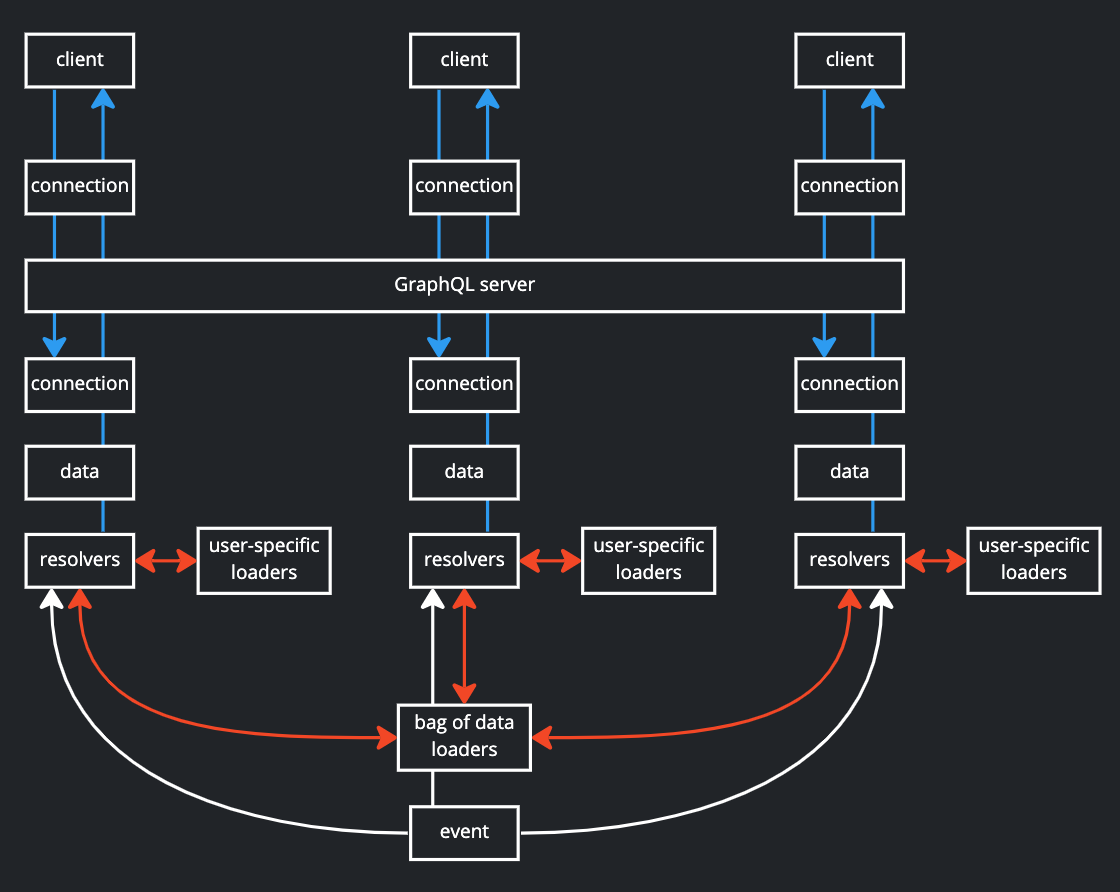
1. Одно событие, все подписчики
Для одного события загрузчики данных могут использоваться всеми подписчиками, но не всеми преобразователями. Некоторые распознаватели имеют ограничения аутентификации (например, поля, специфичные для администратора), а некоторые зависят от пользователя аутентификации (например, количество непрочитанных сообщений). Эти преобразователи иногда невозможно разделить между разными пользователями.
Способ достижения общих загрузчиков данных заключается в том, чтобы полезная нагрузка события содержала уникальный идентификатор. Затем каждый подписчик может использовать этот идентификатор для получения определенного пакета загрузчиков из хэш-карты пакетов. Этот пакет должен содержать только общие общие загрузчики, которые могут использоваться для каждого пользователя.
Поскольку очень трудно узнать, когда это событие было разрешено для всех подписчиков, общий пакет загрузчиков данных должен иметь TTL, после чего он должен автоматически очищаться. Это время может быть 0,5 с, 1 с или 10 с. Все зависит от баланса между ожиданием достаточного времени для разрешения всех подписчиков и не слишком долгим ожиданием, чтобы не тратить память впустую.
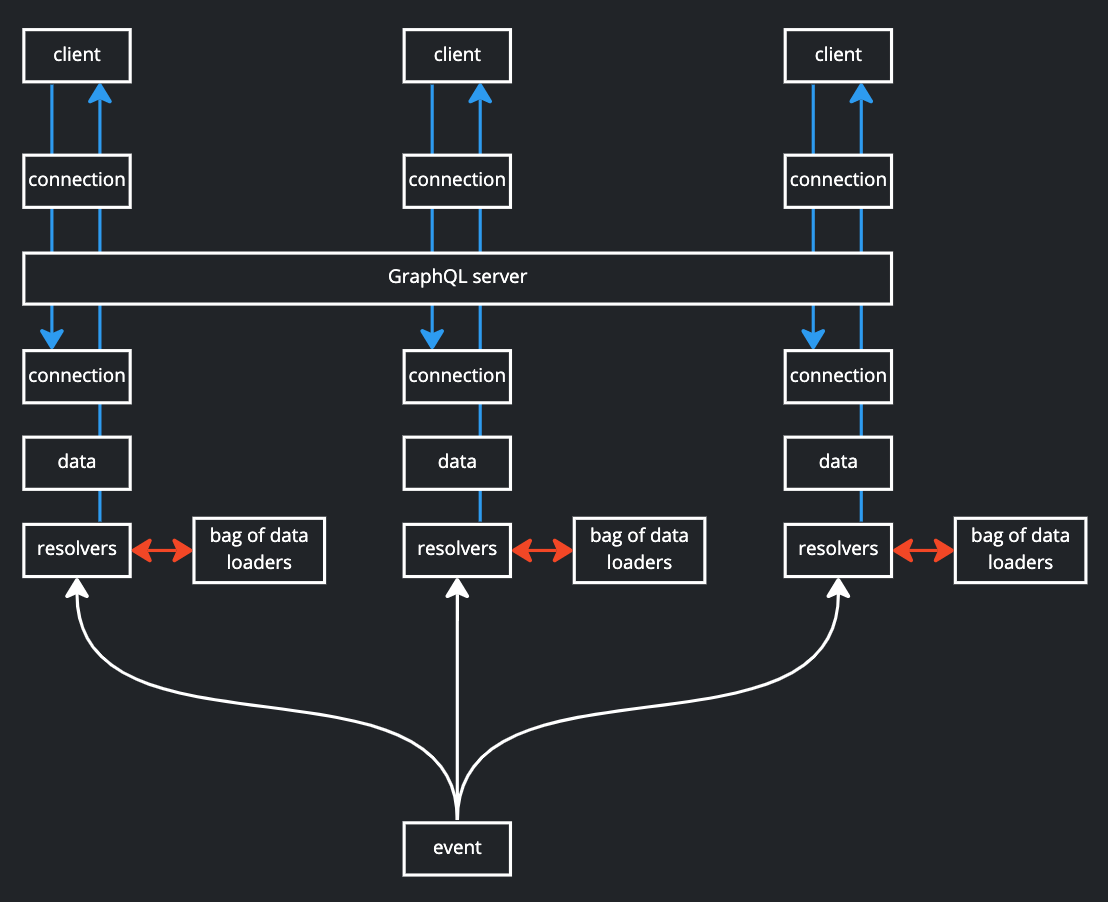
2. Одно событие, один подписчик
Загрузчики данных могут быть общими для одного события и одного подписчика. Это можно сделать без особых проблем. Каждый раз, когда публикуется событие, для каждого объекта контекста подписчика устанавливается новый пакет загрузчиков. Когда клиент/подписчик получает разрешенные данные в реальном времени, соединение остается открытым, объект контекста остается в памяти, а также пакет загрузчиков и все данные, кэшированные внутри. Есть разные способы решить эту проблему и очистить кешированные данные.
Самый простой способ освободить память — отключить опцию кеша для загрузчиков данных. Запросы будут группироваться, но как только данные распределяются по распознавателям, они удаляются из загрузчика данных. Главный недостаток — возможная потеря производительности. Если одни и те же данные будут запрошены снова во время существования экземпляра загрузчика данных, загрузчик данных должен будет снова загрузить их.
Другой вариант доступен, если серверная библиотека предоставляет ловушку, когда данные передаются подписчику клиента. Этот крюк можно использовать для снятия или очистки сумки от погрузчиков. Это лучший вариант, потому что он может очистить сумку от загрузчиков именно тогда, когда они больше не нужны.
Последний вариант - подход с ТТЛ на сумке грузчиков. Опять же, ключевым моментом является достижение правильного баланса TTL.
Ленивое создание экземпляра
Создание всех загрузчиков данных для каждого запроса/события тратит тем больше памяти, чем больше загрузчиков данных существует, поскольку не все загрузчики требуются для каждого запроса. Вместо этого загрузчики должны лениво создаваться только тогда, когда они необходимы. Сумка грузчиков начинается пустой. По мере того как загрузчики запрашиваются распознавателями, они создаются и сохраняются в сумке. У каждого загрузчика есть свое имя, по которому он указан в хэш-карте. К концу запроса пакет загрузчиков содержит только те загрузчики, которые были необходимы для этого запроса. При отправке ответа все загрузчики удаляются сборщиком мусора.
Заключительные мысли
Для проверки концепции или небольшого приложения наличие проблемы N+1 на вашем сервере может не иметь значения. Если вас вообще беспокоит производительность или нагрузка на сервер GraphQL, загрузчики данных — лучший подход для оптимизации. Для подписок допустимы оба перечисленных здесь подхода, но первый подход (одно событие, все подписчики) дает максимально возможную производительность.