
Контрольная обработка параллелиз
12 августа 2025 г.Кокосоиндексразработан, чтобы бытьготовый к производству с первого дня- Построен для обработки данных параллельно, максимизируя пропускную способность при обеспечении безопасности ваших систем. Сегодня мы посмотрим, какОптимизировать производительность без перегрузки вашей средыПолем С кокосоиндексом, это простоодна конфигурация в сторонеПолем
🌟 Star Cocoindex, если вам это нравится -https://github.com/cocoindex-io/cocoindex
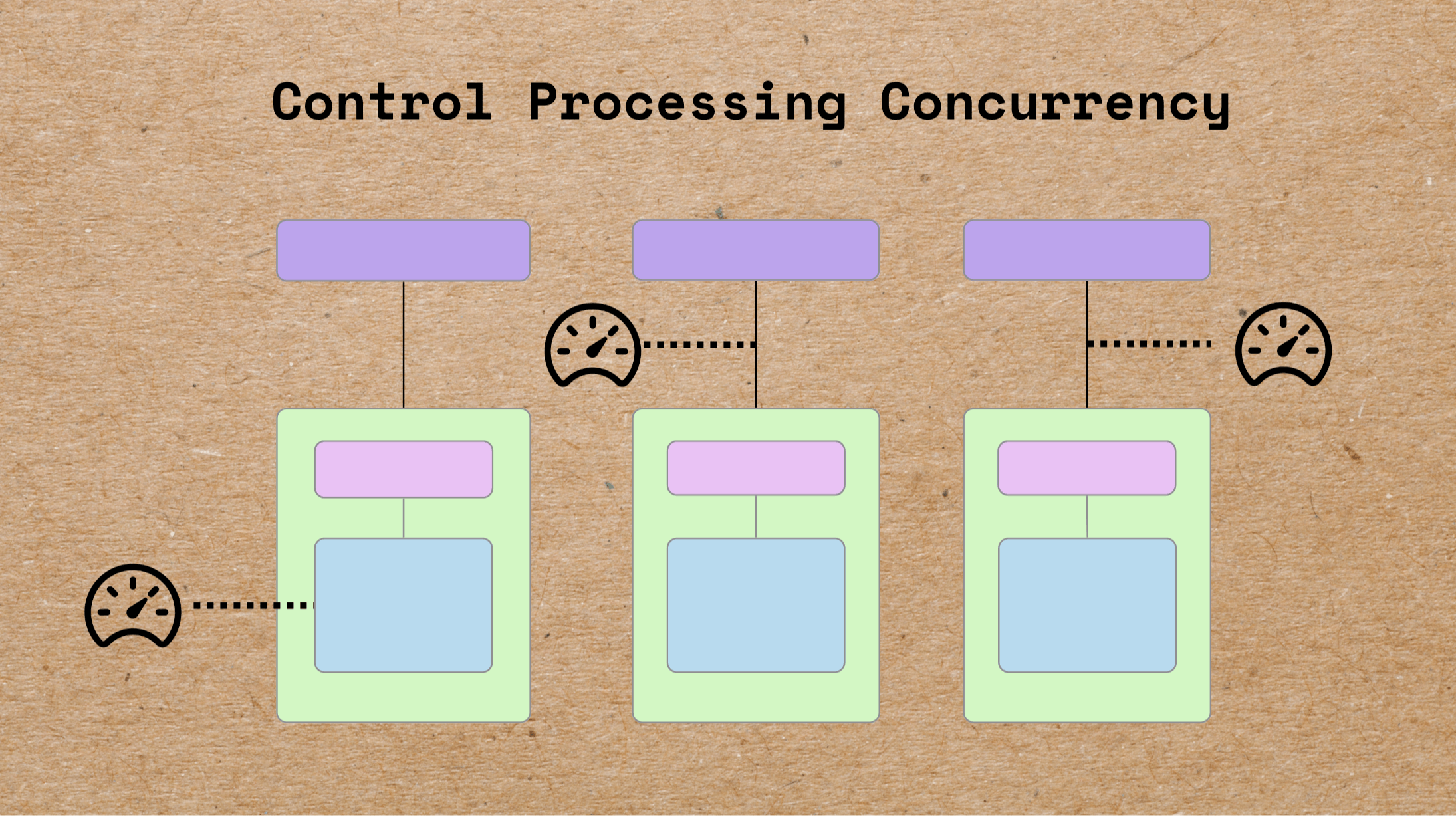
Модель параллелизма Cocoindex повышает скорость, обрабатывая несколько элементов данных одновременно, ноБольше параллелизма не всегда лучшеПолем Оставленная неограниченная, чрезмерная параллелизм может напрягаться - или даже дестабилизировать - ваши системы. Вот почему кокосоиндекс включаетВстроенные механизмы контроля параллелистикикоторые наносят правильный баланс междуСырая производительностьистабильность системы, даже в масштабе.
Обработка слишком много элементов одновременно может вызвать:
- Истощение памяти- Большие наборы данных, загруженные одновременно, потребляют огромное количество оперативной памяти.
- Ресурс- ЦП, диск ввода/вывод и пропускная способность сети перегружены конкуренцией.
- Системная нестабильность- тайм -ауты, ухудшенная производительность или прямые сбои.
В отличие от общих функций параллелизма, Cocoindex позволяет вам:
- Ограничьте как объем данных (строки), так и использование памяти (байты).
- Установите ограничения на нескольких уровнях: глобальный, на исходный источник и итерация для для строки.
- Объединить элементы управления:всеУказанные ограничения должны быть удовлетворены до переработки.
Этот многослойный подход гарантирует, что источники с тяжелыми ресурсами не перегружают систему, а вложенные задачи (такие как разделение документов на кусочки) остаются предсказуемыми и безопасными.
Вы можете просмотреть полную документациюздесьПолем Cocoindex вызывает процессы пользователей в масштабе миллионов производства.
Параметры параллелистики
Кокоиндекс предоставляет две основные настройки:
Вариант | Цель | Единица |
|---|---|---|
| Максимальное количество строк обрабатывается одновременно. | ряды |
| Максимальный след падежей одновременно обработанных данных (до преобразования). | байты |
Когда ограничен достигнут, кокоиндексПаузу новой обработкипока не завершится некоторая существующая работа. Это сохраняет высокую пропускную способность, не проталкивая вашу систему мимо своей границы.
Где применить контроль параллелизма
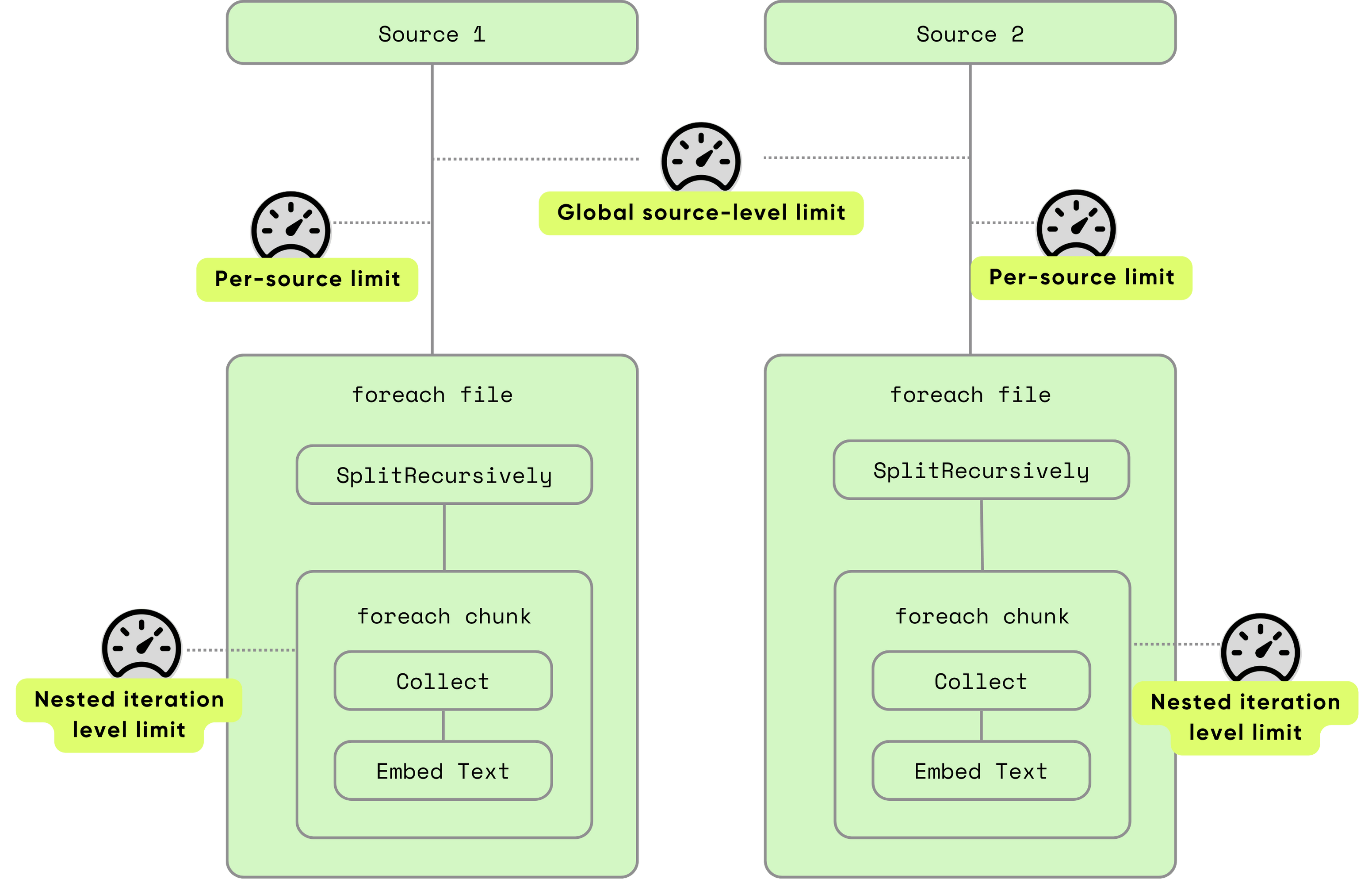
1. Уровень источника
Управляют, сколько строк из источника данных обрабатывается одновременно. Это предотвращает подавляющую вашу систему при употреблении больших наборов данных.
Управление уровнем источника происходит при двух разных гранулярности
- Global, в котором все источники во всех потоках индексации имеют одинаковый бюджет.
- Для каждого источника, в котором каждый источник имеет свой собственный бюджет.
ОбаГлобализа источникПределы должны пройти до того, как будет обработана новая строка - обеспечить два уровня безопасности.
Глобальная параллелизм: одна настройка для защиты всех потоков
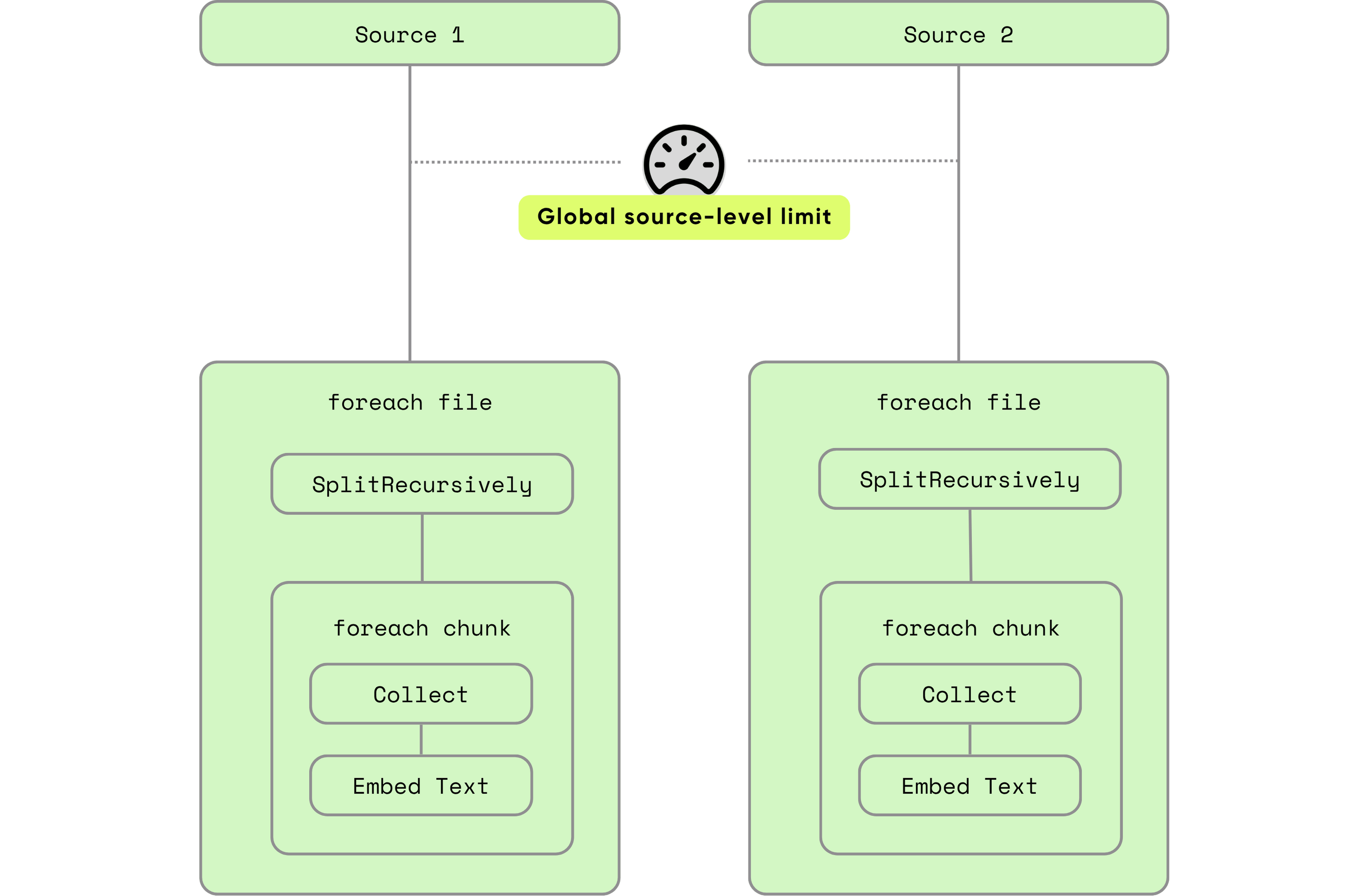
Глобальные ограничения гарантируют, что ваша система никогда не превышает безопасные пороговые значения работы, даже если отдельные потоки стараются более высоким параллелизмом.
Применить общеобразовательную защиту либо через переменные среды, либо программное управление:
Самый простой способ - это контролировать его с помощью переменных среды:
COCOINDEX_SOURCE_MAX_INFLIGHT_ROWS=256
COCOINDEX_SOURCE_MAX_INFLIGHT_BYTES=1048576
Программно, настройте его при вызовеcocoindex.init(), который будет иметь приоритет над переменной среды:
from cocoindex import GlobalExecutionOptions
cocoindex.init(
cocoindex.Settings(
...,
global_execution_options = GlobalExecutionOptions(
source_max_inflight_rows=256,
source_max_inflight_bytes=1_048_576
)
)
)
В настоящее время Cocoindex использует 1024 в качестве значения по умолчанию глобальных максимальных рядов, если вы не устанавливаете его.
Параллелизм в отношении источника: гранулированная настройка
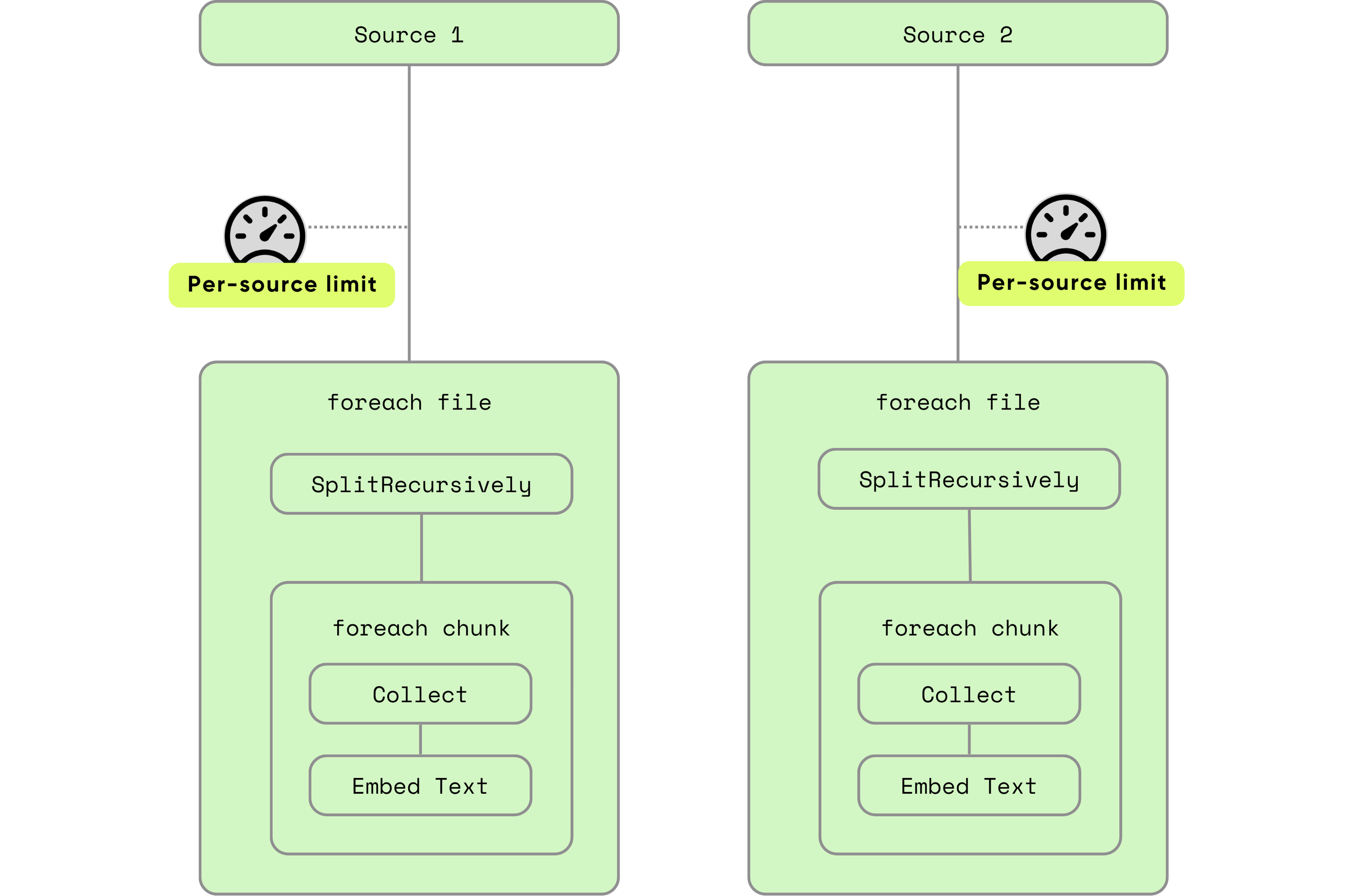
Установите разные ограничения для каждого источника в соответствии с рабочей нагрузкой и характеристиками данных:
@cocoindex.flow_def(name="DemoFlow")
def demo_flow(flow_builder: cocoindex.FlowBuilder, data_scope: cocoindex.DataScope):
data_scope["documents"] = flow_builder.add_source(
DemoSourceSpec(...),
max_inflight_rows=10,
max_inflight_bytes=100*1024*1024 # 100 MB
)
2. Вложенная итерационная параллельность: глубокий структурный контроль
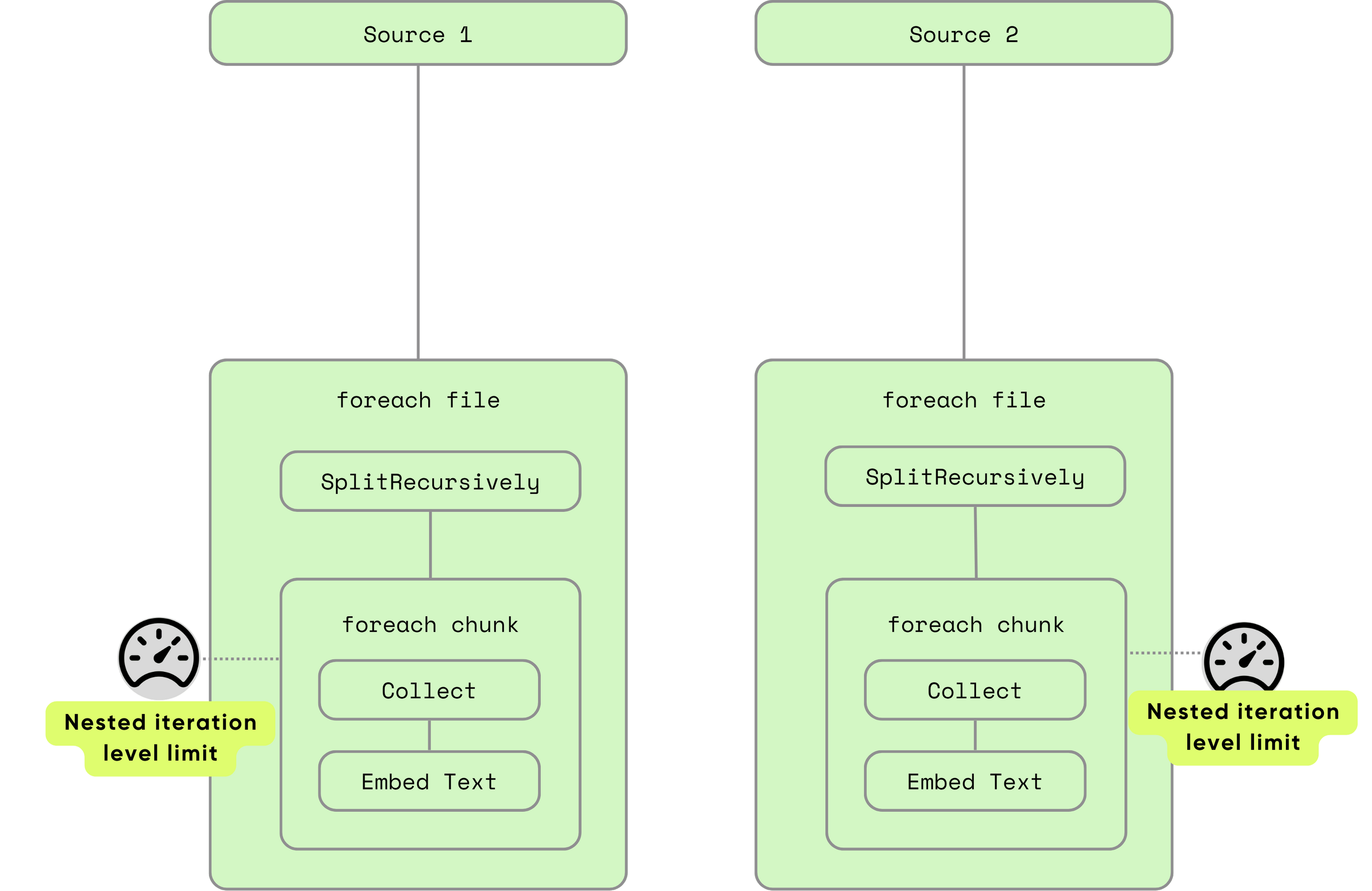
При обработке вложенных строк, таких как обработка каждого куска каждого документа, вы можете настроить максимальные одновременные строки и/или байты:
with data_scope["documents"].row() as doc:
doc["chunks"] = doc["content"].transform(SplitRecursively(...))
with doc["chunks"].row(max_inflight_rows=100, max_inflight_bytes=100*1000*1000):
# Process up to 100 chunks in parallel per document
...
Сводная таблица: Конфигурация параллелизма в кокоиндексе
Уровень | Путь конфигурации | Относится к |
|---|---|---|
Глобальный | Переменные среды или пройти | Все источники, все потоки, складываются вместе |
За источник | Аргументы к | Конкретный источник/поток |
Итерация ряд | Аргументы на Dataslice. | Вложенные итерации |
Best PracticeSexpand CommentComment On Line R138ResolvedCode имеет комментарии. Нажмите Enter, чтобы просмотреть.
В фактических инкрементных трубопроводах узкое место в обработке обычно находится в нескольких тяжелых операциях, таких как выполнение вывода с использованием модели ИИ локально или через удаленный API. Обычно хранить больше данных в памяти, даже если его нельзя обработать немедленно - таким образом, как только занятый бэкэнд становится доступным, можно сразу же использовать новые рабочие нагрузки, чтобы занять бэкэнды. Тем не менее, нам нужно разумное связанное с этим, чтобы предотвратить истощение памяти и подобные проблемы. Вот где входит контроль параллелизма.
- Во многих случаях ограничение по умолчанию глобального источника Max Rows (1024) уже достаточно. Он соответствует ситуации, описанной выше: загрузка больше, чем то, что может употреблять тяжелые операции, но все же в пределах разумной границы. Вам не нужно ничего делать.
- Вы можете настроить предел глобального исходного строки, если по умолчанию не работает идеально. Например, если вы наблюдаете чрезмерное использование памяти или тайм -ауты в определенных операциях, уменьшите предел; С другой стороны, если система уже стабильна, но вы хотите, чтобы она работала быстрее, увеличьте предел, чтобы увидеть, поможет ли это.
- Если распределение размера ваших входных данных сильно варьируется (например, оно следует за длинным распределением, а не нормальным распределением), установка предела максимального байта может помочь предотвратить небольшое количество ненормально больших входов на перегрузку системы.
- Если вы хотите запустить несколько потоков в рамках одного и того же процесса или иметь несколько источников в одном и том же потоке, и они различаются при сложности обработки (например, один источник проходит через очень тяжелую и медленную модель, а другой делает только простое движение данных), вы можете использовать контроль на практическом материале для более строгого управления тяжелым путем.
- Если у вас есть большое количество вложенных рядов для обработки, и конкретное число значительно варьируется, настраивайте параметры контроля параллелизма на вложенные итерации.
Эта структура управления параллелизмом дает вамбезопасная, масштабируемая и настраиваемая производительность потокаПолем Вы получаете гибкость (настраивайтесь на плавание), управляете (устанавливают глобальные ограничения), а уверенность в масштабировании кокосоиндекса плавно течет по разным рабочим нагрузкам.
Поддержите нас
Мы постоянно улучшаем наше время выполнения. Пожалуйста, ⭐ StarКокоиндекс на GitHubи поделиться этим с другими.
Нужна помощь в разработке более подробного фрагмента кода или понимание использования байтовых или по умолчанию параллельных настроек? Просто дай мне знать!
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27294)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)
Для простоты,
max_inflight_bytesТолько измеряет размер данных, уже в памяти, до каких -либо преобразований - этонетВключите временную память, используемая на этапах обработки.