
Сравнение пользовательских оптимизаторов с использованием API -интерфейсов TensorFlow Core
19 июля 2025 г.Обзор контента
- Введение
- Обзор оптимизаторов
- Настраивать
- Градиент спуск
- Градиент спуск с импульсом
- Оценка адаптивного момента (Адам)
- Заключение
Введение
АКерас оптимизаторыМодуль является рекомендуемым инструментом оптимизации для многих общих учебных целей. Он включает в себя различные предварительно построенные оптимизации, а также функциональность подкласса для настройки. Оптимизаторы Keras также совместимы с пользовательскими слоями, моделями и тренировочными петлями, построенными с основными API. Эти предвзятые и настраиваемые оптимизаторы подходят для большинства случаев, но основные API позволяют полностью контролировать процесс оптимизации. Например, такие методы, как минимизация с учетом резкости (SAM), требуют соединения модели и оптимизатора, что не соответствует традиционному определению оптимизаторов ML. Это руководство проходит через процесс создания пользовательских оптимизаторов с нуля с основными API, что дает вам возможность полного контроля над структурой, реализацией и поведением ваших оптимизаторов.
Обзор оптимизаторов
Оптимизатор - это алгоритм, используемый для минимизации функции потери в отношении обучения модели. Наиболее простой методикой оптимизации является градиент спуск, который итеративно обновляет параметры модели, сделав шаг в направлении самого крутого спуска его функции потери. Его размер шага прямо пропорционален размеру градиента, что может быть проблематичным, когда градиент либо слишком большой, либо слишком маленький. Есть много других оптимизаторов, основанных на градиентах, таких как Adam, Adagrad и RMSPROP, которые используют различные математические свойства градиентов для эффективности памяти и быстрой конвергенции.
Настраивать
import matplotlib
from matplotlib import pyplot as plt
# Preset Matplotlib figure sizes.
matplotlib.rcParams['figure.figsize'] = [9, 6]
import tensorflow as tf
print(tf.__version__)
# set random seed for reproducible results
tf.random.set_seed(22)
2024-08-15 02:37:52.102563: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:485] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered
2024-08-15 02:37:52.123704: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:8454] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered
2024-08-15 02:37:52.130222: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1452] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
2.17.0
Градиент спуск
Основной класс оптимизатора должен иметь метод инициализации и функцию для обновления списка переменных с учетом списка градиентов. Начните с внедрения основного оптимизатора спуска градиента, который обновляет каждую переменную, вычитая его градиент, масштабированный по скорости обучения.
class GradientDescent(tf.Module):
def __init__(self, learning_rate=1e-3):
# Initialize parameters
self.learning_rate = learning_rate
self.title = f"Gradient descent optimizer: learning rate={self.learning_rate}"
def apply_gradients(self, grads, vars):
# Update variables
for grad, var in zip(grads, vars):
var.assign_sub(self.learning_rate*grad)
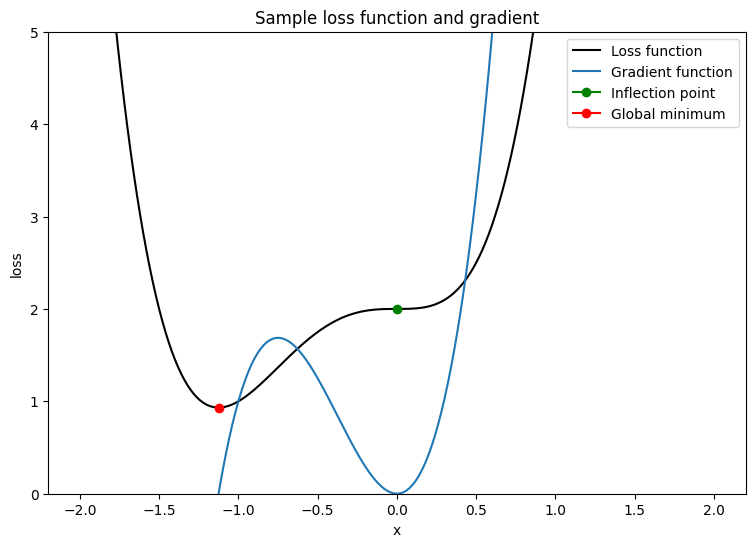
Чтобы проверить этот оптимизатор, создайте функцию потери образца, чтобы минимизировать с точки зрения одной переменной, x. Вычислить его градиентную функцию и решить для его минимизации значения параметра:
L = 2x4+3x3+2
dldx = 8x3+9x2
Dldx составляет 0 при x = 0, которая является седлой точкой и при x = −98, что является минимальным глобальным. Следовательно, функция потерь оптимизирована при x⋆ = −98.
x_vals = tf.linspace(-2, 2, 201)
x_vals = tf.cast(x_vals, tf.float32)
def loss(x):
return 2*(x**4) + 3*(x**3) + 2
def grad(f, x):
with tf.GradientTape() as tape:
tape.watch(x)
result = f(x)
return tape.gradient(result, x)
plt.plot(x_vals, loss(x_vals), c='k', label = "Loss function")
plt.plot(x_vals, grad(loss, x_vals), c='tab:blue', label = "Gradient function")
plt.plot(0, loss(0), marker="o", c='g', label = "Inflection point")
plt.plot(-9/8, loss(-9/8), marker="o", c='r', label = "Global minimum")
plt.legend()
plt.ylim(0,5)
plt.xlabel("x")
plt.ylabel("loss")
plt.title("Sample loss function and gradient");
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
I0000 00:00:1723689474.551312 124187 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689474.555159 124187 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689474.558916 124187 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689474.562138 124187 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689474.573919 124187 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689474.577367 124187 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689474.580786 124187 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689474.583786 124187 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689474.587331 124187 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689474.590801 124187 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689474.594185 124187 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689474.597140 124187 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689475.839513 124187 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689475.841532 124187 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689475.844269 124187 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689475.846345 124187 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689475.848395 124187 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689475.850251 124187 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689475.852146 124187 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689475.854142 124187 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689475.856078 124187 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689475.857966 124187 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689475.859861 124187 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689475.861827 124187 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689475.899762 124187 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689475.901715 124187 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689475.903659 124187 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689475.905680 124187 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689475.907718 124187 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689475.909592 124187 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689475.911505 124187 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689475.913511 124187 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689475.915419 124187 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689475.917727 124187 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689475.919991 124187 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
I0000 00:00:1723689475.922410 124187 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
Напишите функцию, чтобы проверить сходимость оптимизатора с помощью одной функции потери переменной. Предположим, что конвергенция была достигнута, когда значение обновленного параметра в TimeStep T такое же, как и его значение, хранящееся при TimeStep T - 1. Завершите тест после установленного числа итераций, а также отслеживайте любые взрывающиеся градиенты в процессе. Чтобы по -настоящему оспорить алгоритм оптимизации, плохо инициализируйте параметр. В приведенном выше примере x = 2 является хорошим выбором, поскольку он включает в себя крутой градиент, а также приводит к точке перегиба.
def convergence_test(optimizer, loss_fn, grad_fn=grad, init_val=2., max_iters=2000):
# Function for optimizer convergence test
print(optimizer.title)
print("-------------------------------")
# Initializing variables and structures
x_star = tf.Variable(init_val)
param_path = []
converged = False
for iter in range(1, max_iters + 1):
x_grad = grad_fn(loss_fn, x_star)
# Case for exploding gradient
if tf.math.is_nan(x_grad):
print(f"Gradient exploded at iteration {iter}\n")
return []
# Updating the variable and storing its old-version
x_old = x_star.numpy()
optimizer.apply_gradients([x_grad], [x_star])
param_path.append(x_star.numpy())
# Checking for convergence
if x_star == x_old:
print(f"Converged in {iter} iterations\n")
converged = True
break
# Print early termination message
if not converged:
print(f"Exceeded maximum of {max_iters} iterations. Test terminated.\n")
return param_path
Проверьте конвергенцию градиентного оптимизатора спуска для следующих скоростей обучения: 1E-3, 1E-2, 1E-1
param_map_gd = {}
learning_rates = [1e-3, 1e-2, 1e-1]
for learning_rate in learning_rates:
param_map_gd[learning_rate] = (convergence_test(
GradientDescent(learning_rate=learning_rate), loss_fn=loss))
Gradient descent optimizer: learning rate=0.001
-------------------------------
Exceeded maximum of 2000 iterations. Test terminated.
Gradient descent optimizer: learning rate=0.01
-------------------------------
Exceeded maximum of 2000 iterations. Test terminated.
Gradient descent optimizer: learning rate=0.1
-------------------------------
Gradient exploded at iteration 6
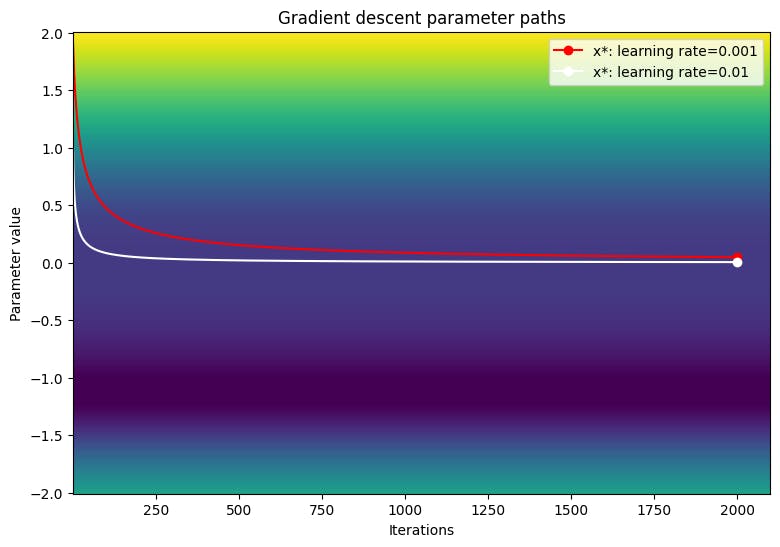
Визуализируйте путь параметров по контурному графику функции потери.
def viz_paths(param_map, x_vals, loss_fn, title, max_iters=2000):
# Creating a controur plot of the loss function
t_vals = tf.range(1., max_iters + 100.)
t_grid, x_grid = tf.meshgrid(t_vals, x_vals)
loss_grid = tf.math.log(loss_fn(x_grid))
plt.pcolormesh(t_vals, x_vals, loss_grid, vmin=0, shading='nearest')
colors = ['r', 'w', 'c']
# Plotting the parameter paths over the contour plot
for i, learning_rate in enumerate(param_map):
param_path = param_map[learning_rate]
if len(param_path) > 0:
x_star = param_path[-1]
plt.plot(t_vals[:len(param_path)], param_path, c=colors[i])
plt.plot(len(param_path), x_star, marker='o', c=colors[i],
label = f"x*: learning rate={learning_rate}")
plt.xlabel("Iterations")
plt.ylabel("Parameter value")
plt.legend()
plt.title(f"{title} parameter paths")
viz_paths(param_map_gd, x_vals, loss, "Gradient descent")
/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/IPython/core/events.py:82: UserWarning: Creating legend with loc="best" can be slow with large amounts of data.
func(*args, **kwargs)
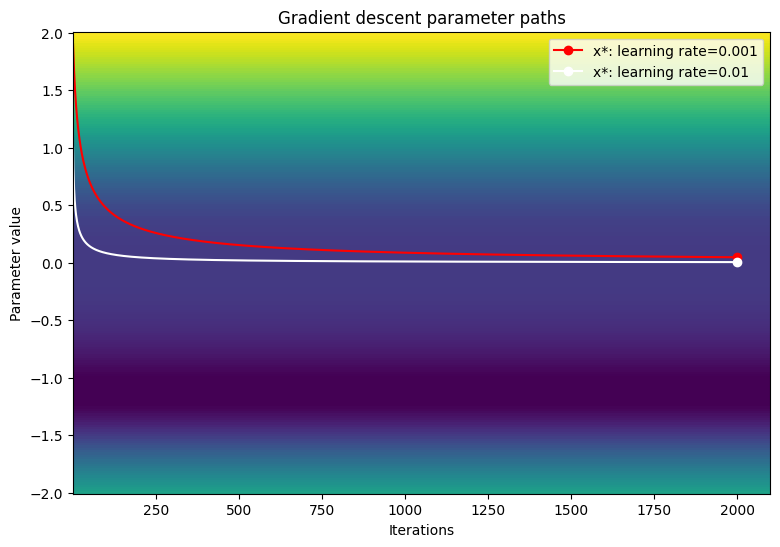
Градиент спуск, кажется, застрял в точке перегиба при использовании меньших уровней обучения. Увеличение уровня обучения может стимулировать более быстрое движение вокруг региона плато из -за большего размера шага; Тем не менее, это рискует взрываться градиентами в ранних итерациях, когда функция потери является чрезвычайно крутой.
Градиент спуск с импульсом
Градиент спуск с импульсом не только использует градиент для обновления переменной, но и включает изменение в положении переменной на основе ее предыдущего обновления. Параметр импульса определяет уровень влияния, который обновляется на TimeStep T -1 на обновление при TimeStep T. Накапливающийся импульс помогает перемещать переменные в районах платчи быстрее, чем базовый градиентный спуск. Правило обновления импульса заключается в следующем:
Δx [t] = lr> ′ (x [t -1])+p % [t - 1]
x [t] = x [t - 1] −Δx [t]
где
- X: оптимизированная переменная
- Δx: изменение в x
- LR: скорость обучения
- L ′ (x): градиент функции потери относительно x
- П: Параметр импульса
class Momentum(tf.Module):
def __init__(self, learning_rate=1e-3, momentum=0.7):
# Initialize parameters
self.learning_rate = learning_rate
self.momentum = momentum
self.change = 0.
self.title = f"Gradient descent optimizer: learning rate={self.learning_rate}"
def apply_gradients(self, grads, vars):
# Update variables
for grad, var in zip(grads, vars):
curr_change = self.learning_rate*grad + self.momentum*self.change
var.assign_sub(curr_change)
self.change = curr_change
Проверьте конвергенцию оптимизатора импульса для следующих скоростей обучения: 1E-3, 1E-2, 1E-1
param_map_mtm = {}
learning_rates = [1e-3, 1e-2, 1e-1]
for learning_rate in learning_rates:
param_map_mtm[learning_rate] = (convergence_test(
Momentum(learning_rate=learning_rate),
loss_fn=loss, grad_fn=grad))
Gradient descent optimizer: learning rate=0.001
-------------------------------
Exceeded maximum of 2000 iterations. Test terminated.
Gradient descent optimizer: learning rate=0.01
-------------------------------
Converged in 80 iterations
Gradient descent optimizer: learning rate=0.1
-------------------------------
Gradient exploded at iteration 6
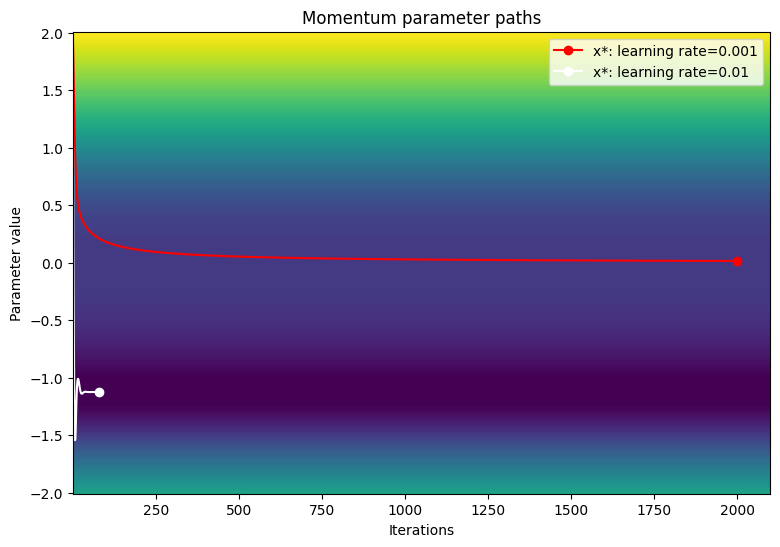
Визуализируйте путь параметров по контурному графику функции потери.
viz_paths(param_map_mtm, x_vals, loss, "Momentum")
Оценка адаптивного момента (Адам)
Алгоритм оценки адаптивного момента (ADAM) является эффективной и очень обобщаемой методикой оптимизации, которая использует две ключевые метологии спуска градиента: импульс и среднее квадратное пропагандинг (RMSP). Импульс помогает ускорить спуск градиента, используя первый момент (сумма градиентов) вместе с параметром распада. RMSP похож; Тем не менее, это использует второй момент (сумма градиентов в квадрате).
Алгоритм ADAM объединяет как первый, так и второй момент, чтобы обеспечить более обобщаемое правило обновления. Знак переменной, x, может быть определен путем вычисления XX2. Оптимизатор ADAM использует этот факт для расчета шага обновления, который фактически является сглаженным знаком. Вместо расчета XX2 оптимизатор рассчитывает сглаженную версию X (первый момент) и X2 (второй момент) для каждого обновления переменной.
Адам Алгоритм
β1 ← 0,9 -х литературное значение
β2 ← 0,999 -х литературное значение
LR ← 1E-3▹configerawere Screed обучения
ϵ ← 1e-7▹prevents Разделите на 0 ошибку
VDV ← 0N × 1 → ▹Stores Обновления импульса для каждой переменной
SDV ← 0n × 1 → ▹Stores Обновления RMSP для каждой переменной
T ← 1
На итерации t:
Для (dldv, v) в парах градиентных переменных:
Vdv_i = β1vdv_i+(1 - β1) обновление dldv▹momentum
SDV_I = β2VDV_I+(1 - β2) (DLDV) обновление 2▹RMSP
VDVBC = VDV_I (1 -β1) Коррекция смещения t▹momentum
SDVBC = SDV_I (1 -β2) Коррекция смещения T▹RMSP
v = v -lrvdvbcsdvbc+ϵ▹parameter Обновление
t = t+1
Конец алгоритма
Учитывая, что VDV и SDV инициализируются до 0 и что β1 и β2 близки к 1, обновления импульса и среднеквадратичного среднего уровня естественным образом смещены в сторону 0; Следовательно, переменные могут извлечь выгоду из коррекции смещения. Коррекция смещения также помогает контролировать оскамируцию весов по мере приближения к минимальному минимальному минимальному минимальности.
class Adam(tf.Module):
def __init__(self, learning_rate=1e-3, beta_1=0.9, beta_2=0.999, ep=1e-7):
# Initialize the Adam parameters
self.beta_1 = beta_1
self.beta_2 = beta_2
self.learning_rate = learning_rate
self.ep = ep
self.t = 1.
self.v_dvar, self.s_dvar = [], []
self.title = f"Adam: learning rate={self.learning_rate}"
self.built = False
def apply_gradients(self, grads, vars):
# Set up moment and RMSprop slots for each variable on the first call
if not self.built:
for var in vars:
v = tf.Variable(tf.zeros(shape=var.shape))
s = tf.Variable(tf.zeros(shape=var.shape))
self.v_dvar.append(v)
self.s_dvar.append(s)
self.built = True
# Perform Adam updates
for i, (d_var, var) in enumerate(zip(grads, vars)):
# Moment calculation
self.v_dvar[i] = self.beta_1*self.v_dvar[i] + (1-self.beta_1)*d_var
# RMSprop calculation
self.s_dvar[i] = self.beta_2*self.s_dvar[i] + (1-self.beta_2)*tf.square(d_var)
# Bias correction
v_dvar_bc = self.v_dvar[i]/(1-(self.beta_1**self.t))
s_dvar_bc = self.s_dvar[i]/(1-(self.beta_2**self.t))
# Update model variables
var.assign_sub(self.learning_rate*(v_dvar_bc/(tf.sqrt(s_dvar_bc) + self.ep)))
# Increment the iteration counter
self.t += 1.
Проверьте производительность оптимизатора ADAM с теми же показателями обучения, которые использовались с примерами градиентного спуска.
param_map_adam = {}
learning_rates = [1e-3, 1e-2, 1e-1]
for learning_rate in learning_rates:
param_map_adam[learning_rate] = (convergence_test(
Adam(learning_rate=learning_rate), loss_fn=loss))
Adam: learning rate=0.001
-------------------------------
Exceeded maximum of 2000 iterations. Test terminated.
Adam: learning rate=0.01
-------------------------------
Exceeded maximum of 2000 iterations. Test terminated.
Adam: learning rate=0.1
-------------------------------
Converged in 1156 iterations
Визуализируйте путь параметров по контурному графику функции потери.
viz_paths(param_map_adam, x_vals, loss, "Adam")
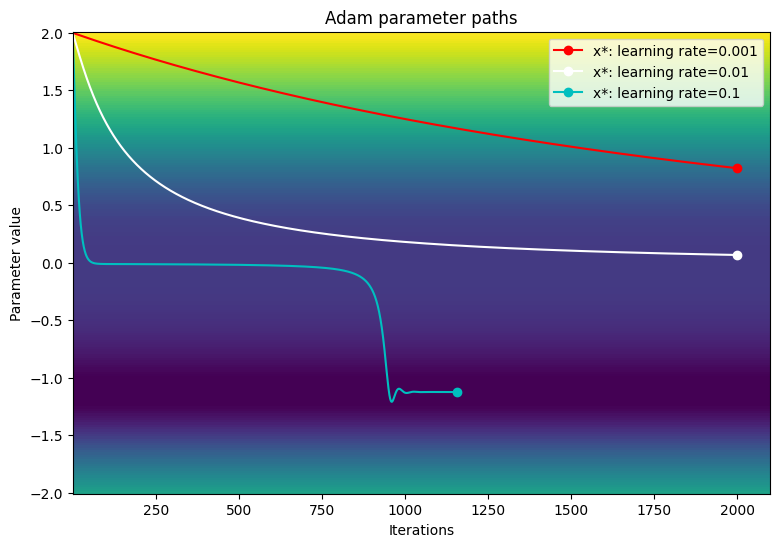
В этом конкретном примере оптимизатор ADAM имеет более медленную конвергенцию по сравнению с традиционным градиентным происхождением при использовании небольших скоростей обучения. Тем не менее, алгоритм успешно проходит мимо региона Платеу и сходится к глобальному минимуму при большей скорости обучения. Взрывные градиенты больше не являются проблемой из -за динамического масштабирования скорости обучения Адама при столкновении с большими градиентами.
Заключение
В этом записном книжке были представлены основы написания и сравнения оптимизаторов сTensorflow Core APIПолем Хотя предвзятые оптимизаторы, такие как Адам, являются обобщенными, они не всегда могут быть лучшим выбором для каждой модели или набора данных. Показанный контроль над процессом оптимизации может помочь оптимизировать учебные процессы ML и повысить общую производительность. Обратитесь к следующей документации для получения дополнительных примеров пользовательских оптимизаторов:
- Этот оптимизатор Адама используется вМногослойные персептроныУчебник иРаспределенное обучение
- Модельный садимеет разнообразиеПользовательские оптимизаторынаписано с основными API.
Первоначально опубликовано на
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27328)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)