

Бесцена с более быстрым R-CNN и YOLOV5 для глобального обнаружения повреждений дорог в разных странах
13 августа 2025 г.Авторы:
(1) Рахул Вишвакарма, Лаборатория Analytics & Solutions и Solutions, Hitachi America Ltd., Санта -Клара, Калифорния, США (Rahul.vishwakarma@hal.hitachi.com);
(2) Равигопал Веннелаканти, Лаборатория Analytics & Solutions, Hitachi America Ltd., Research & Development, Санта -Клара, Калифорния, США (Ravigopal.vennelakanti@hal.hitachi.com).
Таблица ссылок
Аннотация и I. Введение
II Набор данных
Iii. Методы
IV Эксперименты
V. Результаты
VI Выводы и ссылки
**Абстрактный- ** В этом документе содержится отчет о нашем решении, включая выбор модели, стратегию настройки и результаты, полученные для глобального выявления обнаружения дорожных повреждений. Эта задача Cup Cup Big Data была проведена в рамках Международной конференции IEEE по большим данным 2020 года. Мы оцениваем одноэтажные и многоэтапные сетевые архитектуры для обнаружения объектов и предоставляем эталон с использованием популярных самых современных пит-средств с открытым исходным кодом, таких как Detectron2 и Yolov5. Обсуждается подготовка данных для предоставленного набора данных обучения на уроне дорожного повреждения, снятого с использованием камеры смартфона из Чехии, Индии и Японии. Мы изучили влияние обучения по каждой стране в отношении единой модели обобщаемой. Мы кратко опишем стратегию настройки для экспериментов, проведенных на двухэтапных более быстрых R-CNN с глубокой остаточной сетью (RESNET) и основной сетью Pyramid (FPN). Кроме того, мы сравниваем это с одноэтапной моделью Yolov5 с поперечной частичной сетью (CSPNET). Мы показываем среднюю оценку F1 0,542 на Test2 и 0,536 на наборах данных Test1 с использованием многоэтапной модели R-CNN с многоэтапной R-CNN с соответственно RESNET-50 и RESNET-101. Это показывает обобщение модели Resnet-50 по сравнению с ее более сложными аналогами. Эксперименты проводились с использованием Google Colab, имеющей K80 и ПК Linux с графическим процессором NVIDIA потребительского уровня. Код Detectron2 на основе Pytorch для предварительной обработки, тренировки, тестирования и отправки оценки AVG F1, доступный по адресу https://github.com/vishwakarmarhl/rdd2020
I. Введение
Дороги являются важнейшим активом инфраструктуры мобильности, который требует оценки состояния и мониторинга. Это традиционно делалось с помощью ручного обследования и дорогих методов проверки. Высокая стоимость и проблемы в существующих методах, таких как ручный труд, специализированное осмотрительное оборудование, предметные знания и материально -технические задержки в оценке, являются чрезмерными. Чтобы решить эту проблему, автоматизированная обработка изображений из готовой камеры смартфона показала, что она все более эффективна в обнаружении визуальных повреждений [1].
Методы обнаружения объектов и локализации на основе глубокого обучения показали огромный прогресс за последнее десятилетие. Свожденная нейронная сеть (CNN) с использованием подхода к подходу к обучению применяется к области распознавания изображений, которые трудно моделировать с использованием традиционных методов. ImageNet [3] Challenge ускорила задачу обнаружения объекта, и к 2015 году превысила человеческие способности. Целью данной работы является оценка методов обнаружения объектов и проведение экспериментов для обучения модели обнаружения повреждений с наиболее точной и обобщенной архитектурой. Мы достигаем следующего в этой статье.
• Предварительная обработка для достижения точных обнаружений
• Тренируйте обобщенную модель, которая может быть передана в разных странах. Сравните его с выделенной моделью на страну.
• Экспериментируйте и оцените одноэтапные и многоэтапные детекторы объектов для точного обнаружения
• Оценить прогресс, гиперпараметры и точность различных моделей
В следующем разделе описываются данные, эксперименты и анализ для достижения сообщенного оценки.
II Набор данных
Набор данных по повреждению дорог 2020 [2] был курирован и аннотирован для автоматической проверки. Этот многострановый набор данных выпускается в рамках задачи Cup Cup IEEE [23]. Задача состоит в том, чтобы обнаружить убытки дороги в глобальном масштабе и сообщить о производительности на наборах данных Test 1 и Test 2.
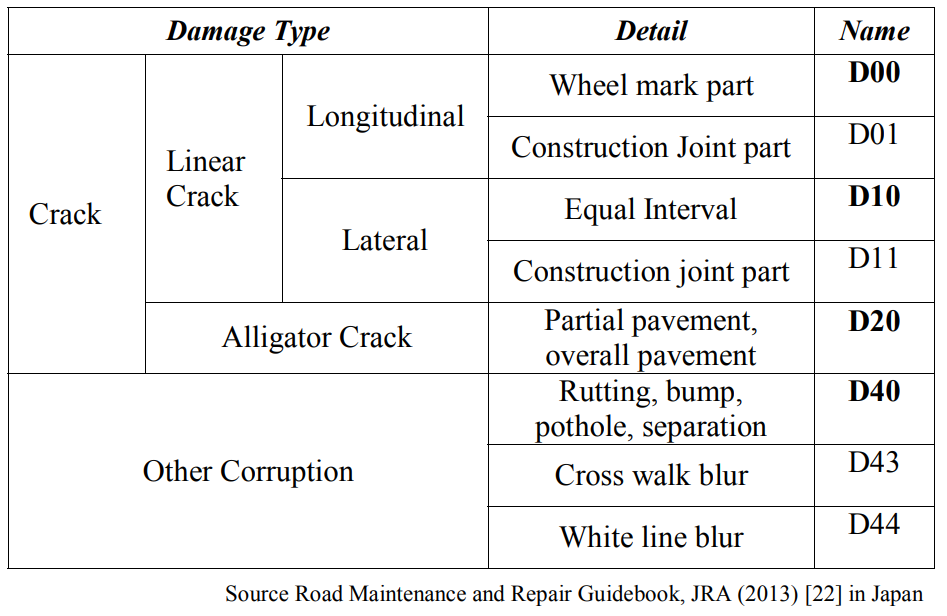
Убытки варьируются в разных странах. Чтобы обобщить обнаружение категории ущерба в таблице I, классы, рассматриваемые для анализа, являются; D00: продольная трещина, D10: поперечная трещина, D20: трещина аллигатора, D40: выбоина. Данные тестирования 1 и тестирования 2 предоставляются Комитетом по вопросам [23] для оценки и представления. После представления средний балл F1 добавляется в частную таблицу лидеров, а также в общедоступную таблицу лидеров, если он превышает все предыдущие оценки в нашей частной таблице лидеров.
A. Глобальный набор данных по повреждению дорог
Последний набор данных собирается из Чешской Республики и Индии в дополнение к тому, что было доступно Ассоциацией ГИС в Японии. Набор данных 2020 года обеспечивает обучающие изображения размера 600x600 с ущербом в качестве ограничивающей коробки с соответствующим классом урона. Метки классов и координаты ограничивающей коробки, определенные четырьмя числами (Xmin, Ymin, Xmax, Ymax), хранятся в формате XML в соответствии с Pascal VOC [12].

Предоставленные данные обучения имеют 21041 общего изображения. Он состоит из 2829 изображений из чешского (CZ); 10506 из Японии (JP); и 7706 из Индии (IN) с аннотациями, хранящимися в отдельных файлах XML. На рис. 1 мы можем увидеть структуру файла, ограничивающее поле в тегах XML и соответствующий пример изображения.
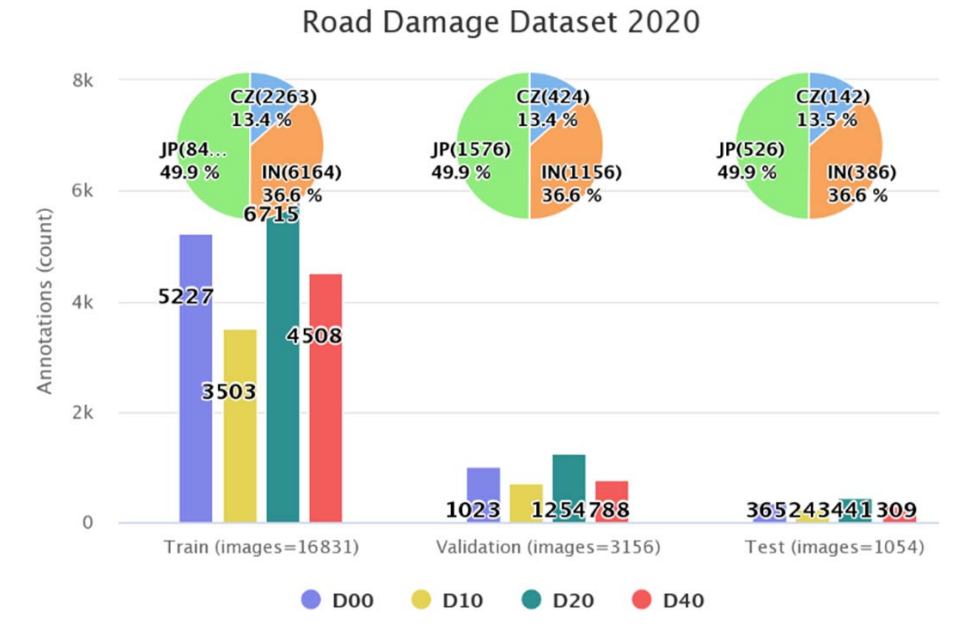
Общие данные тестирования разделены на два набора. Тест 1 состоит из 349 чешских, 969 Индии и 1313 Японских дорожных изображений без аннотированной наземной истины. Тест 2 состоит из 360 чешских, 990 Индии и 1314 Японских дорожных изображений без аннотированной наземной истины. Результаты обнаружения на этих тестовых изображениях представлены в задачу [23] для оценки оценки AVG F1.
Чтобы запустить эксперименты, мы разделили данный учебный набор данных пропорционально на 80: 15: 5 :: Train (T): Val (V): тест (T) данные. Это дает нам окончательное изображение и аннотации на рис. 2, которое будет использоваться для обучения и настройки.
Поскольку мы настраиваем модели, нам нужно создать композитные наборы данных с помощью набора данных Train+Test (T+T) и Train+Val (T+V) наборов данных. Это поможет моделировать целые данные для обучения и оценки.
Б. Стратегия оценки
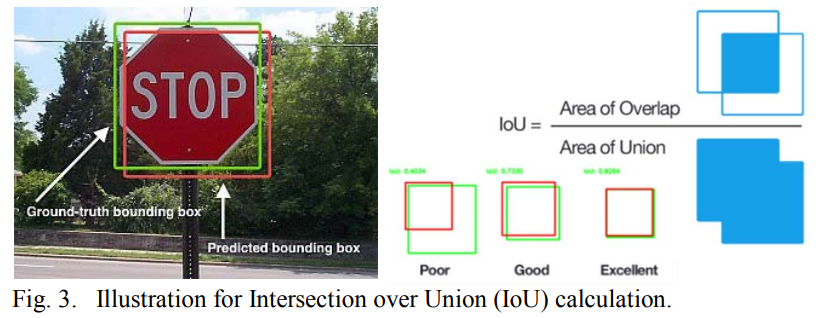
Стратегия оценки включает в себя сопоставление предсказанной метки класса для основной истинной коробки и что прогнозируемое ограничительное ящик имеет более 50% пересечения над Союзом (IOU) в области. Точность и отзыв основаны на оценке пересечения над Союзом (IOU), который определяется как отношение площади перекрытия между прогнозируемыми и территориями земли, ограничивающими землю по площади их союза.
Оценка матча проводится с использованием среднего показателя оценки F1. Оценка F1, обычно используемая в поиске информации, измеряет точность с использованием статистики точности P и Emplow r. Точность - это отношение истинных положительных результатов (TP) ко всем прогнозируемым положительным результатам (TP + FP), в то время как воспоминание является соотношением истинных положительных результатов ко всем реальным положительным результатам (TP + FN). Максимизация показателя F1 обеспечивает достаточно высокую точность и отзыв.
Оценка F1 определяется:
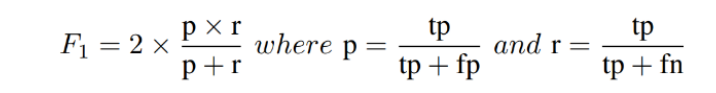
Оценка AVG F1 служит сбалансированной метрикой для точности и отзыва. Это метрика, которую мы получаем в нашем частном таблице лидеров, при подаче результатов оценки на наборах данных Test 1 или Test 2.
Эта статья есть
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27294)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)