

Повышение качества данных: изучение контрактов на передачу данных с Lyft
19 января 2024 г.Похоже, это вторая часть моей серии статей о качестве данных!
В предыдущей публикации я исследовал стратегию Airbnb по повышению качества данных за счет стимулы. Они внедрили единую систему оценки и четкие критерии оценки, чтобы установить общее понимание между производителями и потребителями данных и способствовать подлинному чувству сопричастности.
https://hackernoon.com/data-quality -score-one-score-to-rule-them-all?embedable=true
Теперь Lyft использует особый подход, не пытаясь делать то же самое по-разному, а скорее концентрируясь на разных аспектах качества данных. И стратегия Lyft дополняет усилия Airbnb. Хотя я считаю оценку DQ Airbnb (или любую аналогичную оценку) эффективным средством консолидации различных попыток повышения качества данных, Lyft решает эту проблему под другим углом.
Оценка Airbnb DQ служит ценным инструментом для обеспечения конкретной визуализации качества данных. По сути, любая инициатива по повышению качества данных должна оказывать заметное влияние на этот показатель. С другой стороны, Lyft представляет одну из возможных инициатив по активному повышению качества путем тестирования и проверки данных на соответствие конкретным критериям качества.
По сути, это другой этап жизненного цикла качества данных. Внедрение механизма улучшения качества требует возможности его измерения на начальном этапе.
Таким образом, хотя основное внимание Airbnb уделяется измерению и наблюдению качества данных, полагаясь на заинтересованность производителя в повышении этого качества и «выглядении хорошо, Lyft придерживается другого подхода. Lyft уделяет особое внимание активному тестированию и проверке качества данных, предоставляя производителям и потребителям средства для эффективного улучшения и контроля качества.
В совокупности эти подходы представляют собой комплексную стратегию по обеспечению и повышению качества данных на протяжении их жизненного цикла.
По этой причине мне было особенно интересно поближе познакомиться с подходом Lyft.
Еще один фактор, который меня заинтриговал, — это тестирование, точнее, контрактное тестирование, которое уже много лет используется в базовой разработке программного обеспечения с появлением микросервисной архитектуры. Контракты данных, однако, являются чем-то более новым в области инженерии данных и рассматриваются как вершина или один из последних шагов на пути к построению высококачественных конвейеров данных. Вот почему я хотел более подробно изучить подход Lyft и изучить некоторые потенциальные параллели.
Как уже упоминалось, подходы Airbnb и Lyft дополняют друг друга и направлены на достижение одной и той же цели: повышение качества данных.
Airbnb разработала оценку DQ, которая фокусируется на измерении и улучшении четырех различных аспектов качества данных:
<блок-цитата>DQ Score имеет руководящие принципы, включая полный охват, автоматизацию, практичность, многомерность и возможность развития. Он имеет такие параметры, как точность, надежность, управление и удобство использования.**
Verity от Lyft – это платформа, предназначенная для повышения качества данных по пяти измерениям
<блок-цитата>Определяет качество данных как меру того, насколько хорошо данные могут использоваться по назначению, охватывая такие аспекты, как семантическая корректность, последовательность, полнота, уникальность, правильность формирования и своевременность.
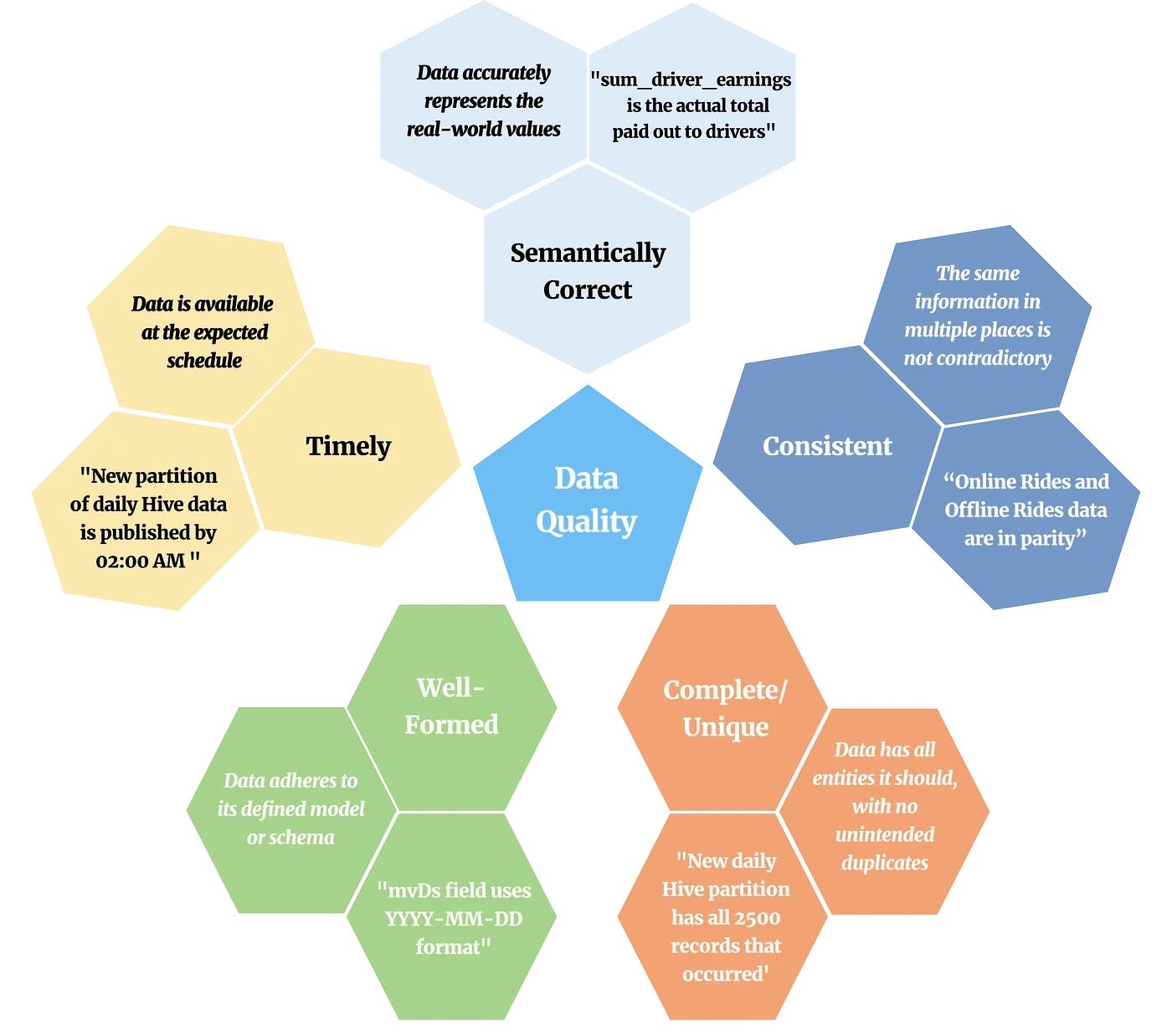
Легко провести параллели между пятью аспектами качества данных, улучшенными с помощью Verity от Lyft, и четырьмя аспектами качества данных, измеренными с помощью показателя DQ Airbnb. Например, такие аспекты, как своевременность, безусловно, будут способствовать повышению надежности оценки DQ, тогда как точность будет зависеть от семантической правильности, полноты и уникальности данных. С другой стороны, на показатель юзабилити влияет согласованность данных и другие факторы.
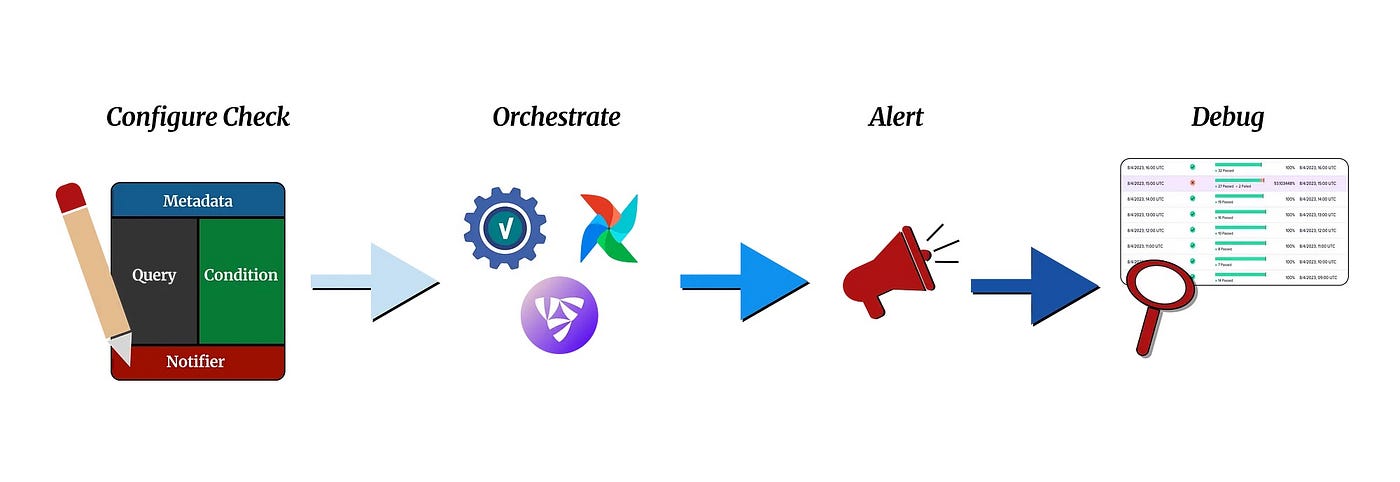
Verity компании Lyft фокусируется на определении проверок, связанных с семантической правильностью, согласованностью, полнотой, уникальностью, правильностью формирования и своевременностью. Он основан на подходе «сначала тестирование» и «проверка», тогда как в едином рейтинге DQ Airbnb особое внимание уделяется оценке качества данных по различным параметрам.
Если бы мы хотели включить оценку DQ в эту последнюю схему, это было бы на стороне этапов оповещения/отладки.
Оценка DQ Airbnb использует различные сигналы для оценки качества данных по аспектам точности, надежности, управления и удобства использования.
<блок-цитата>У нас также был набор входных сигналов, которые более непосредственно измеряют качество (сертификация Midas, проверка данных, ошибки, соглашения об уровне обслуживания, автоматические проверки качества и т. д.), тогда как другие больше походили на прокси качества (например, валидность). владение, надлежащая гигиена управления, использование инструментов для прокладки дорог).
Как обсуждалось ранее, вероятно, существует совпадение между оценками Airbnb DQ и Verity. В то время как Airbnb фокусируется на повышении качества данных, уделяя особое внимание измерению и оценке, Verity от Lyft использует упреждающий подход, смещая конфигурации определения проверок, процессы тестирования и проверки влево, уделяя особое внимание упреждающему улучшению качества данных.
Сейчас меня больше всего интересуют левые настройки, аспекты тестирования и проверки.
Как Lyft интегрирует тестирование качества данных в свои процессы?
Давайте сначала рассмотрим пути выполнения.
В настоящее время Verity компании Lyft в первую очередь сосредоточена на обеспечении качества данных, хранящихся в хранилище данных Hive. Однако в будущем планируется расширить его возможности для поддержки других источников данных.
Обратите внимание: хотя они называют Hive центром обработки данных, на самом деле они используют его как гибридное решение для хранения данных, работающее как хранилище данных для структурированных, обработанных и очищенных данных (серебряный уровень), а также служащее озером данных для необработанных событий. данные (бронзовый слой).
<блок-цитата>Низкое качество данных в Hive привело к искажению показателей экспериментов, неточности функций машинного обучения и некорректным информационным панелям для руководителей.
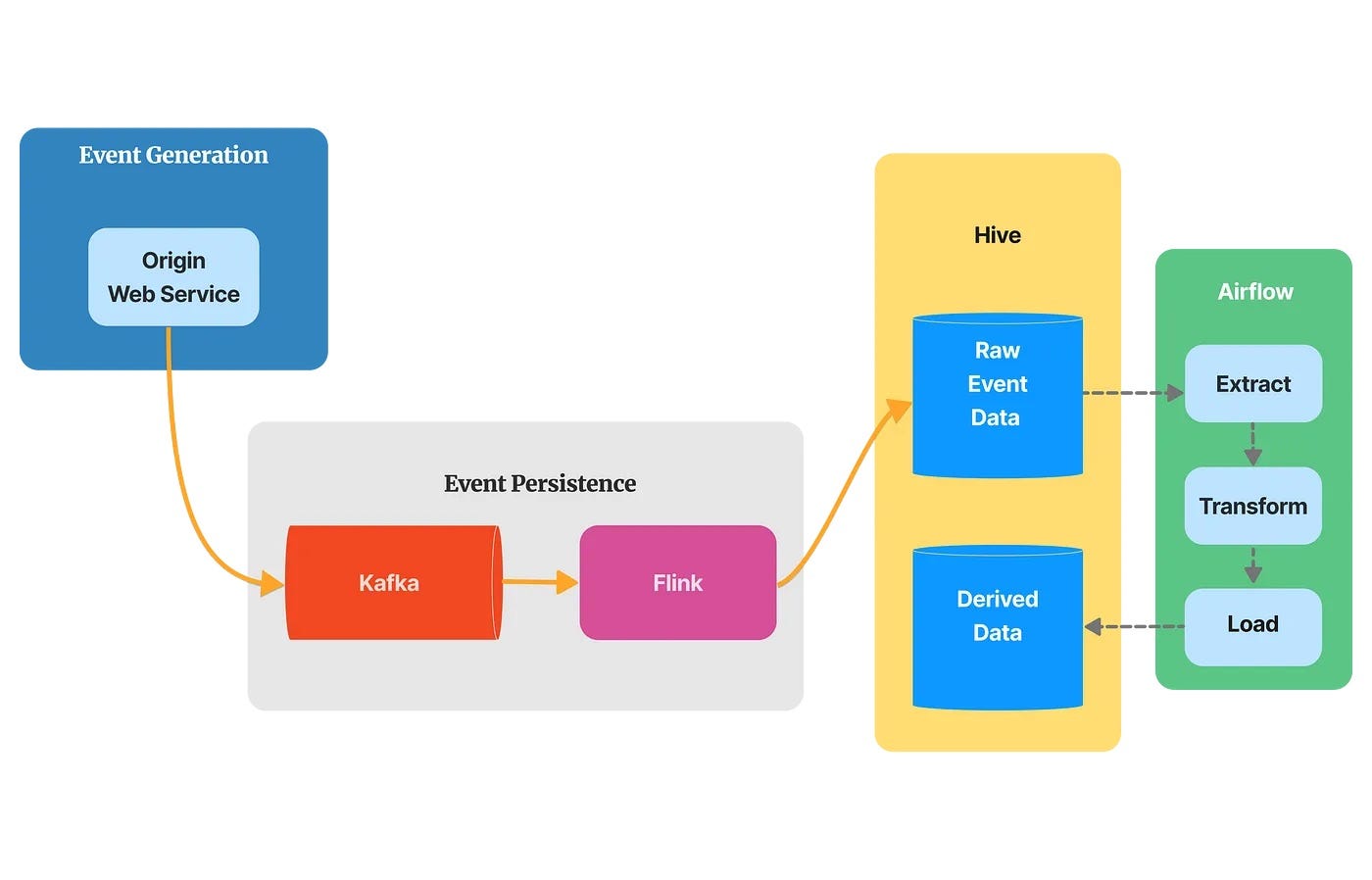
Проверки Verity можно интегрировать в группу обеспечения доступности баз данных Airflow, чтобы гарантировать обработку и сохранение в Hive только высококачественных необработанных данных в качестве производных данных.
<блок-цитата>Производители и потребители данных могут определять свои проверки качества данных и проверять данные при их создании или перед использованием внутри Airflow или Flyte.
…
VerityAirflowOperator можно использовать в режиме блокировки для остановки DAG в случае сбоя проверки, предотвращая попадание неверных данных в рабочую среду. При этом используется «Stage-Check-Exchange. Шаблон «»: мы создаем данные в поэтапной схеме, проверяем данные с помощью оператора блокировки, а затем переводим их в рабочую среду, если они проходят проверку качества.
Проверки также могут выполняться вручную или автоматически по расписанию для проверки как исходных, так и производных данных.
<блок-цитата>Запланированные проверки Verity изолированы от любого механизма оркестрации данных, поэтому они продолжают выполняться, даже если Airflow или Flyte полностью отключены. Это устраняет распространенную проблему, когда проверки не выдают оповещений, поскольку задача воздушного потока никогда не запускалась.
Таким образом, существует три основных способа запуска проверки: в рамках группы обеспечения доступности баз данных Airflow, вручную или по расписанию через платформу/пользовательский интерфейс Verity.
Я не верю, что текущие проверки можно интегрировать в потоковые конвейеры реального времени (такие как Flink + Kafka) для проверки, например, данных при их поступлении в Hive (или даже раньше).
Внедрение этого типа проверки в режиме реального времени позволит оперативно обнаруживать несоответствия, что приведет к снижению затрат на хранение и обработку и общему повышению качества данных.
Если быть точным, проверки Verity управляются через сервер API, который можно использовать для программного запуска проверок через некоторые API.
<блок-цитата>Сервер API Verity — эта служба обрабатывает все внешние API, связанные с выполнением проверок, а также сохранением и получением их результатов. Сервер API не выполняет никаких проверок, а записывает сообщение в нашу очередь проверок, которая использует SimpleQueueService (SQS).
Так что, возможно, вы могли бы запускать эти задания в более реальном времени, например, из потокового задания или даже, в долгосрочной перспективе, путем интеграции с системой отслеживания измененных данных Hive (CDC).
Однако при выполнении вне Airflow эти задания не смогут заблокировать задание по обработке данных; вместо этого они будут генерировать асинхронные оповещения, помещаемые в очередь проверки. Некоторые потребители предпочитают отложить обработку данных в случае неудачной проверки, в то время как другие предпочитают продолжить и получить предупреждение.
Теперь давайте посмотрим на эти тесты качества данных.
Вот пример, который проверяет, никогда ли rider_events.session_id не имеет значения null. Это достигается за счет сочетания компонентов запроса и условия.
core rider events session_id is not null: # check name
metadata:
id: 90bde4fa-148b-4f06-bd5f-f15b3d2ad759
ownership_slack: #dispatch-service-dev
tags: [rides, core-data, high-priority]
query:
type: dsl
data_source_id: hive.core.rider_events
filters:
- session_id = null
condition:
type: fixed_threshold
max: 0
notifier_group:
pagerduty_policy: dispatch-service
email: dispatch-service@lyft.pagerduty.com
Verity в первую очередь ориентирована на определение и обеспечение проверок качества данных, а не на определение полных схем данных.
Проверка схемы не является новой концепцией. Существует несколько методов определения схем данных событий в системах, основанных на событиях, таких как схема JSON, буферы протоколов, Avro или форматы хранения, такие как Parquet. Оптимальный выбор зависит от вашего технологического набора, условий использования и конкретных требований.
Хотя схемы данных полезны для определения общей структуры объектов данных или строк таблицы, они не справляются с более сложными проверками, специфичными для потребителей, такими как распределение данных, бизнес-правила, соглашения об уровне обслуживания и пороговые значения.
Контракты данных выходят за рамки проверки схемы, которая направлена на выявление синтаксических ошибок. Лично я считаю, что JSON Schema предлагает здесь более подходящий и удобочитаемый вариант, эффективно отделяя возможности структурной и синтаксической проверки от проблем сериализации или хранения.
Однако для устранения семантических ошибок и повышения точности данных наличие эффективных средств определения проверок данных позволяет определить другой аспект контрактов данных.
Именно здесь в игру вступает Verity DSL.
Помимо семантической проверки, контракты данных предлагают еще один важный аспект, заслуживающий внимания.
С синтаксической точки зрения проверки остаются согласованными независимо от того, участвует ли потребитель или производитель. Набор правил проверки не привязан к какому-либо конкретному потребителю или производителю и может быть определен раз и навсегда как единая схема.
Однако контракт данных Verity DSL предлагает более тонкую детализацию, определяющую небольшие независимые правила, что особенно хорошо подходит для этого контекста: семантическое значение и использование данных варьируются в зависимости от конкретного потребителя. Кроме того, не всем потребителям необходимо использовать все свойства объекта. Их ожидания различаются. Это не означает, что они противоречивы (что, безусловно, будет проблемой), а скорее дополняют друг друга и различны.
Поэтому крайне важно предоставить всем потребителям возможность устанавливать уникальные правила, которые при совместном использовании могут обеспечить всестороннее понимание семантической значимости качества данных.
И именно этот аспект сотрудничества особенно резонирует со мной. Потерпите, это может показаться натяжкой, но, с моей точки зрения, об этом стоит упомянуть. :)
Обмен данными позволяет различным командам (производителям и потребителям) эффективно сотрудничать. Установление общего понимания этого обмена данными имеет первостепенное значение, как и API в традиционной разработке программного обеспечения. В микросервисных архитектурах появился подход совместного тестирования, известный как контракты, управляемые потребителем (CDC), где потребители определяют ожидаемое поведение API, предоставляемых производителями. Производители несут ответственность за проверку этих контрактов перед выпуском новых версий.
Я думаю, что контракты на передачу данных разделяют схожий дух сотрудничества. Несмотря на то, что проверка данных выполняется на реальных данных, а не во время выпуска, и не блокирует выпуск, она основана на сотрудничестве и поощряет совместную работу между производителями и потребителями данных. Я твердо убежден, что этот совместный подход является ключом к улучшению качества данных и его следует и дальше интегрировать в этот процесс.
Ну, я большой любитель проводить параллели...
Обратите внимание, что этот аспект сотрудничества также упоминается в Хартии правдивости Lyft.
<блок-цитата>VerityUI обеспечивает упрощенный поиск данных через домашнюю страницу Verity. Наш полнотекстовый поиск по метаданным определения проверки позволяет пользователям видеть все проверки, применяемые в данный момент, и их результаты. Здесь есть полезные статистические данные, такие как команда владельцев, имя таблицы и теги.
Мне не совсем понятно, как проблемы с контрактами данных распределяются между потребителями и производителями через пользовательский интерфейс платформы Verity, но я определенно осознаю важность сотрудничества через информационные панели:
*Производитель интерфейса продукта данных может с уверенностью гарантировать, что он непреднамеренно не вызовет непредвиденные сбои в дальнейшем.
* Потребитель интерфейса может быть уверен, что его доверие к интерфейсу не будет скомпрометировано.
Хотя Verity – замечательный инструмент для проверки качества данных, к сожалению, он не имеет открытого исходного кода.
К счастью, существует еще одна платформа качества данных с открытым исходным кодом под названием Soda Core, которая предоставляет аналогичные функции.
Soda Core — это бесплатный инструмент командной строки с открытым исходным кодом и библиотека Python, которая позволяет инженерам данных проверять качество данных. Он использует определяемый пользователем ввод для создания SQL-запросов, которые проверяют наборы данных в источнике данных для поиска недействительных, отсутствующих или неожиданных данных. Если проверки завершаются неудачей, они выявляют данные, которые вы определили при проверке как «плохие».
Во время сканирования набора данных Soda Core выполняет предопределенные проверки для выявления недействительных, отсутствующих или неожиданных данных.
Вот эквивалентная проверка с использованием синтаксиса Soda.core для теста Verity DSL, который был определен ранее.
name: rider_events_session_id_check
source: hive
query: SELECT * FROM rider_events WHERE session_id IS NULL;
raise_alert: true
threshold: 10
action: slack
message: "There are more than 10 rows that are null for the 'session_id' property in the 'rider_events' table. Please investigate this issue."
soda run --check checks/rider_events_session_id_check.yaml
Soda Core — мощный инструмент для обеспечения качества ваших данных. Это может помочь вам выявить и устранить проблемы с данными на ранней стадии, прежде чем они могут вызвать проблемы для вашего бизнеса.
Стоит отметить, что Soda Core также может облегчить проверку качества потоковых данных за счет полной интеграции с Spark DataFrames.
Хотя проверки качества данных Verity для Hive применяются к статическим наборам данных, проверки потоковой передачи данных должны быть более простыми и эффективными.
Данные обычно обрабатываются небольшими пакетами событий с очень низкой задержкой, что делает их пригодными для проверок в реальном времени и конкретных случаев использования, таких как обнаружение аномалий.
Наконец, отметим, что существуют и другие инструменты проверки данных, такие как DeeQu, Great Expectations,…
Подводя итоги, я надеюсь, что у вас появится более четкое представление о том, какие шаги можно предпринять для повышения качества данных.
Мы видели два разных подхода к улучшению качества данных, каждый из которых имеет свои сильные стороны и методологии. Один фокусируется на повышении наглядности и наблюдаемости, мотивируя производителей данных поднимать планку качества. Другой приоритет отдает повышению стандартов качества посредством подхода, основанного на тестировании и проверке. Оба дополняют друг друга.
Verity — это не просто предметно-ориентированный язык (DSL) для определения проверок данных; это централизованная платформа, которая позволяет специалистам по обработке данных эффективно сотрудничать. Эта платформа помогает производителям и потребителям согласовывать требования к качеству данных, включая формат, структуру и точность.
Возможности Verity по управлению контрактами на данные могут быть (есть?) дополнительно улучшены за счет интеграции с более широким набором функций, таких как управление и обнаружение метаданных, для удовлетворения более сложных потребностей в качестве данных.
Подобно рейтингу DQ Airbnb, Verity от Lyft способствует налаживанию обратной связи между производителями и потребителями данных. Стимулируя и предоставляя каждой команде возможность взять на себя ответственность за качество данных, Verity создает благоприятную среду, в которой качество данных постоянно улучшается.
Нашли эту статью полезной? Следуйте за мной в Linkedin, Hackernoon и Средний! Пожалуйста 👏 поделитесь этой статьей!
:::информация Также опубликовано здесь.
:::
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Лучшие новогодние подарки для владельцев домашних животных
29 мая 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27342)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)