
Подход к обнаружению аномалий с нулевым разглашением для надежного федеративного обучения
3 января 2024 г.:::информация Этот документ доступен на arxiv под лицензией CC BY-NC-SA 4.0 DEED.
Авторы:
(1) Shanshan Han & Qifan Zhang, UCI;
(2) Вэньсюань Ву, Техасский университет A&M;
(3) Baturalp Buyukates, Yuhang Yao & Weizhao Jin, USC;
(4) Салман Авестимер, USC & ФедМЛ.
:::
Таблица ссылок
Предлагаемое двухэтапное обнаружение аномалий
Проверяемое обнаружение аномалий с использованием ZKP
АННОТАЦИЯ
Системы федеративного обучения (FL) уязвимы для злонамеренных клиентов, которые отправляют зараженные локальные модели для достижения своих враждебных целей, таких как предотвращение конвергенции глобальной модели или побуждение глобальной модели к неправильной классификации некоторых данных. Многие существующие механизмы защиты непрактичны в реальных системах FL, поскольку они требуют предварительного знания количества злонамеренных клиентов или полагаются на повторное взвешивание или изменение представленных данных. Это связано с тем, что злоумышленники обычно не объявляют о своих намерениях перед атакой, а повторное взвешивание может изменить результаты агрегирования даже в отсутствие атак. Для решения этих проблем в реальных системах FL в данной статье представлен передовой подход к обнаружению аномалий со следующими функциями: i) Обнаружение возникновения атак и выполнение защитных операций только тогда, когда атаки происходят; ii) при возникновении атаки дальнейшее обнаружение вредоносных клиентских моделей и их устранение без ущерба для безопасных; iii) Обеспечение честного выполнения защитных механизмов на сервере за счет использования механизма доказательства с нулевым разглашением. Мы подтверждаем превосходную эффективность предлагаемого подхода с помощью обширных экспериментов.
1 ВВЕДЕНИЕ
Федеративное обучение (FL) (McMahan et al., 2017a) позволяет клиентам совместно обучать модели машинного обучения, не передавая свои локальные данные другим сторонам, сохраняя конфиденциальность и безопасность своих локальных данных. Благодаря своей природе сохранения конфиденциальности FL привлек значительное внимание в различных областях и использовался во многих областях (Hard et al., 2018; Chen et al., 2019; Ramaswamy et al., 2019; Leroy et al., 2019; Byrd & Polychroniadou, 2020; Chowdhury et al., 2022). Однако, несмотря на то, что FL не требует обмена необработанными данными с другими, его децентрализованный и совместный характер непреднамеренно создает уязвимости конфиденциальности и безопасности (Cao & Gong, 2022; Bhagoji et al., 2019; Lam et al., 2021; Jin et al.). ., 2021; Томсетт и др., 2019; Чен и др., 2017; Толпегин и др., 2020; Карияппа и др., 2022; Чжан и др., 2022в). Вредоносные клиенты в системах FL могут нанести вред обучению, предоставляя ложные модели, чтобы помешать сходимости глобальной модели (Fang et al., 2020; Chen et al., 2017), или внедряя бэкдоры, чтобы заставить глобальную модель работать неправильно для определенных выборок (Fang et al., 2020; Chen et al., 2017). Багдасарян и др., 2020б;а; Ван и др., 2020).
Существующая литература по надежному обучению и смягчению состязательного поведения включает Blanchard et al. (2017); Ян и др. (2019); Фунг и др. (2020); Пиллутла и др. (2022 г.); Он и др. (2022 г.); Цао и др. (2022 г.); Кариредди и др. (2020); Сан и др. (2019); Фу и др. (2019); Оздайи и др. (2021 г.); Сан и др. (2021) и т. д. Эти подходы имеют недостатки, что делает их менее подходящими для реальных систем ВЛ. Некоторые из этих стратегий требуют предварительного знания количества злонамеренных клиентов в системе FL (Blanchard et al., 2017), хотя на практике злоумышленник не уведомляет систему перед атакой. Кроме того, некоторые из этих методов смягчают воздействие потенциально вредоносных сообщений клиентов путем повторного взвешивания локальных моделей (Fung et al., 2020), сохраняя только несколько локальных моделей, которые, скорее всего, будут безопасными, удаляя при этом другие (Blanchard et al., 2017) или модификацию функции агрегации (Pillutla et al., 2022). Эти методы могут непреднамеренно изменить результаты агрегирования при отсутствии преднамеренных атак, учитывая, что атаки происходят нечасто.
в реальных сценариях. Хотя защитные механизмы могут смягчить воздействие потенциальных атак, они могут непреднамеренно поставить под угрозу качество результатов при применении в неопасных случаях.
Более того, существующие механизмы защиты развертываются на сервере FL без каких-либо процедур проверки для обеспечения их корректной работы. Хотя большинство клиентов добродушны и желают совместно обучать модели машинного обучения, они также могут скептически относиться к надежности сервера из-за выполнения защитных механизмов, которые изменяют исходную процедуру агрегации. Таким образом, успешный подход к обнаружению аномалий должен одновременно удовлетворять следующим требованиям: i) Он должен иметь возможность обнаруживать возникновение атак и исключительно обрабатывать случаи, когда атаки происходят. ii) Если атака обнаружена, стратегия должна дополнительно обнаружить вредоносные клиентские материалы и, соответственно, смягчить (или устранить) их состязательное воздействие, не нанося вреда безвредным клиентским моделям. iii) Должен существовать надежный механизм подтверждения честного исполнения защитных механизмов.
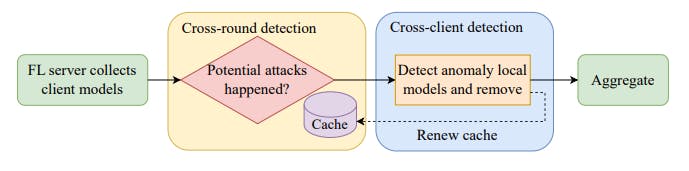
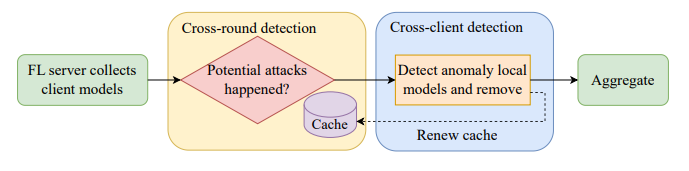
В этой работе мы предлагаем новый механизм обнаружения аномалий, специально предназначенный для решения реальных проблем, с которыми сталкиваются реальные системы FL. Наш подход основан на двухэтапной схеме на сервере для фильтрации вредоносных сообщений клиентов перед агрегированием. Он начинается с перекрестной проверки на основе некоего кеша, называемого «эталонными моделями», чтобы определить, произошли ли какие-либо атаки. В случае атак выполняется последующее межклиентское обнаружение для устранения моделей вредоносных клиентов без ущерба для безопасных моделей клиентов. Тем временем эталонные модели в кеше обновляются. Обзор представлен на рисунке 1. Наш вклад суммирован следующим образом:
i) Превентивное обнаружение атак. Наша стратегия оснащена первоначальной перекрестной проверкой для обнаружения потенциальных атак, гарантируя, что защитные методы активируются только в ответ на наличие атак, тем самым сохраняя неприкосновенность процесса в сценариях без атак.
ii) Улучшенное обнаружение аномалий. Сочетая перекрестную проверку с последующим обнаружением перекрестных клиентов, наш подход эффективно устраняет вредоносные сообщения клиентов, не нанося вреда безопасным локальным сообщениям.
iii) Автономность от предварительных знаний. Наш метод работает эффективно без каких-либо предварительных условий, таких как распространение данных или количество вредоносных клиентов. Такая автономная природа обеспечивает широкую применимость и адаптируемость нашего подхода к различным задачам FL, независимо от распределения данных и выбора моделей.
iv) Строгий протокол проверки. Используя методологию доказательства с нулевым разглашением (ZKP) (Goldwasser et al., 1989), наш подход гарантирует, что выполняется устранение вредоносных клиентских моделей. правильно, гарантируя, что клиенты могут доверять защитному механизму в системе FL.
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27222)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)