

Практическое руководство по машинному обучению для бизнеса
30 июня 2025 г.Каждый день мы слышим, что «ИИ меняет мир». Для основателей стартапов, менеджеров по продуктам и инженеров это звучит как возможность, так и головная боль. С чего начать? Как превратить модное слово в реальную прибыль?
Правда в том, что машинное обучение (ML) не волшебство. Это инженерная дисциплина. Успех в применении ML зависит не от выбора наиболее сложного алгоритма, а от способности сформулировать правильный бизнес -вопрос и выбрать для него подходящий инструмент.
Эта статья является практическим руководством, которое поможет вам понять, какие конкретные «подполи» машинного обучения существуют и какие конкретные бизнес -проблемы решают каждый из них. Мы отправимся в путешествие от определения проблем до реальных результатов бизнеса.
Этап 0. Все начинается с бизнес -вопроса
Наиболее распространенная ошибка, которую совершают компании, начинается с вопроса: «Как мы можем использовать ИИ?» Правильный подход заключается в том, чтобы сначала спросить: «Какую бизнес -проблему у нас есть, и может ли ИИ быть наиболее эффективным решением для этого?» Этот сдвиг в мышлении является фундаментальным для достижения позитивной рентабельности от ИИ.
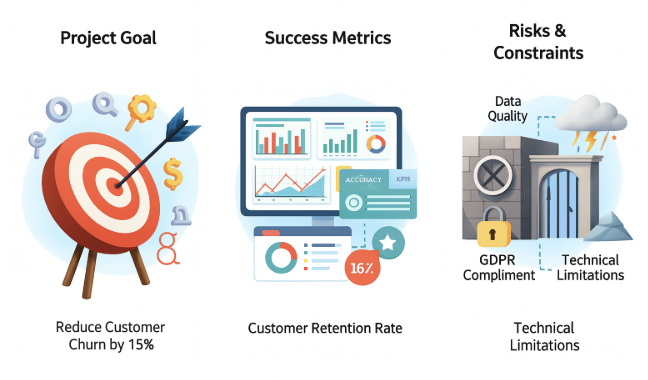
Перед началом какого -либо проекта ML все заинтересованные стороны от лидеров бизнеса до инженеров должны соответствовать трем ключевым аспектам:
Цель проекта:Какая конкретная бизнес -проблема решает модель? Это не может быть расплывчатой целью, например, «улучшить пользовательский опыт». Это должно быть измеримая задача, такая как «сокращение оттока клиентов на 15% в следующем квартале».
Метрики успеха:Как мы узнаем, что достигли цели? Необходимо определить ключевые показатели эффективности (KPI), которые непосредственно отражают бизнес -цель. Например, для модели, прогнозирующей отток, KPI могут включать не только технические показатели (такие как точность), но и бизнес-метрики (такие как процент удерживаемых клиентов из группы риска).
Риски и ограничения:Какие потенциальные препятствия могут возникнуть? Это включает в себя оценку доступности и качества данных, нормативных требований (таких как GDPR), а также технические ограничения, такие как вычислительные ресурсы или требования к отклике моделей.
Недооценка этой стадии создает порочный цикл неудачи. Плохо определенная проблема (например, построение регрессионной модели для прогнозирования «оценки риска» клиента, когда то, что фактически нуждается в бизнесе, является бинарным решением «утверждать/отстранение») приводит к сбору неправильных данных, оптимизации нерелевантных показателей или развертыванию модели, которая, хотя и технически «хороша» для своей (неконтроливой) задачи, не дает бизнес -стоимости. Этот провал, в свою очередь, подрывает бизнес -доверие к команде ML, что затрудняет поддержку будущих проектов, даже если эти проекты правильно сформулированы.
Этап 1.
Прежде чем погрузиться в реализацию, важно понять, какую проблему вы решаете и как создать ее в терминах машинного обучения. Этот шаг непосредственно определяет, какой тип моделей, данных и показателей оценки вы будете использовать. Давайте разберем три основных типа проблем, с которыми сталкивается почти каждый бизнес.
Контролируемое обучение
Это самый распространенный и простой тип ML. У вас есть исторические данные с «правильными ответами», и вы хотите, чтобы ваша модель узнала, как найти эти ответы на новых данных.
Классификация: это «а» или «б»?
Классификация - это задача назначения объекта одной из нескольких категорий. Вы «показываете» модель тысячи маркированных примеров (например, электронные письма, помеченные как «спам» и «не спам»). Модель изучает шаблоны и способна определять категорию новых, ранее невидимых электронных писем.
Бизнес -заявки:
- Прогноз оттока. Уйдет ли клиент или остаться? (Бинарная классификация: да/нет). Это позволяет маркетинговой команде сосредоточиться на сохранении клиентов из группы риска.
- Обнаружение спама. Это спам по электронной почте?
- Кредитный счет. Следует ли отдать кредит заемщику? (Надежный/рискованный).
- Медицинский диагноз. Есть ли признаки заболевания на сканировании?
Регрессия: сколько? Сколько?
Регрессия используется, когда вам нужно предсказать не категорию, а конкретное числовое значение. Модель анализирует взаимосвязь между различными факторами (например, размером дома, соседством, количеством комнат) и ее цены на основе исторических данных, чтобы научиться прогнозировать цены на новые дома.
Бизнес -заявки:
- Прогнозирование спроса. Сколько единиц будет продано в следующем месяце? Это помогает оптимизировать закупки и инвентарь.
- Оценка LTV (значение жизни). Какой доход будет приносить клиент на все отношения с компанией? Это позволяет вам сегментировать клиентов и инвестировать больше в самые ценные.
- Прогноз цен. Какова будет цена на акции, продукт или авиабилет через неделю?
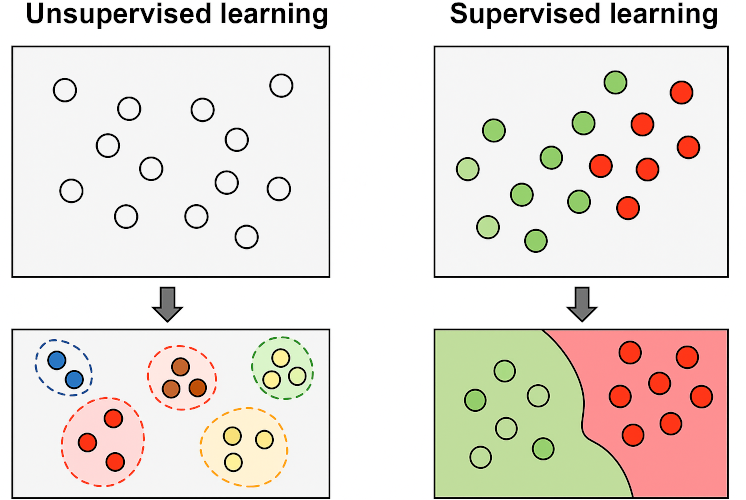
Неконтролируемое обучение
Что если у вас нет данных с «правильными ответами»? Именно здесь приходит неконтролируемое обучение, в поисках скрытых структур и аномалий в данных.
Кластеризация: группировка похожих объектов
Кластеризация автоматически группирует сходные объекты вместе (в кластеры). Вы можете не знать, что это за группы, но алгоритм найдет их. Представьте, что вы наливаете тысячи различных кнопок на стол. Алгоритм кластеризации будет сгруппировать их по размеру, цвету и форме, даже если вы не дали эти инструкции.
Бизнес -заявки:
- Сегментация клиента. Разделение вашей клиентской базы на группы с аналогичным поведением (например, «Бюджетный», «Охотники за сделкой», «лояльные вип-персон»). Это позволяет вам создавать персонализированные маркетинговые кампании.
- Анализ рыночной корзины. Какие продукты часто покупают вместе? (Например, пиво и чипсы). Это основа для систем рекомендаций и оптимизации размещения продуктов.
- Новости группировки. Автоматически группировка новостных статей по теме.
Обнаружение аномалии: поиск иглы в стоге сена
Этот метод направлен на выявление данных, которые сильно отличаются от нормы.
Бизнес -заявки:
- Обнаружение мошенничества. Выявление необычных транзакций, которые не соответствуют типичному поведению клиентов.
- Промышленный мониторинг. Обнаружение необычных показаний датчиков на оборудовании, что может сигнализировать о надвигающемся сбое.
- Кибербезопасность. Обнаружение ненормальной сетевой активности, которая может указывать на атаку.
Глубокое обучение и LLMS
Глубокое обучение - это не отдельный тип задачи, а скорее мощный набор методов (на основе нейронных сетей), которые приняли решения для задач, описанных выше, на новый уровень, особенно при работе со сложными данными.
- Распознавание изображений и видео. Модерация контента, диагностика из медицинских изображений, автономные системы вождения.
- Обработка естественного языка (NLP). Анализ настроений обзоров, чат -ботов, машинный перевод.
Большие языковые модели (LLMS), такие как GPT-4, являются последним прорывом в глубоком обучении. Они открыли новые горизонты для бизнеса:
Продвинутая поддержка клиентов. Чат -боты, которые не только следуют сценариям, но и понимают контекст и решают реальные проблемы.
Содержание генерации. Создание маркетинговых текстов, описания продуктов, рассылки по электронной почте.
Суммизация и анализ документов. Быстрый анализ юридических контрактов, научных статей или внутренних отчетов.
Этап 2. Данные - топливо для вашей модели ML
В мире машинного обучения есть одно золотое правило: качество вашей модели напрямую зависит от качества ваших данных. Вы можете провести недели, настраивая настройку самого сложного монстра нейронной сети, но если он был обучен «мусору», вы получите «мусор». Неудивительно, что до 80% случаев в любом проекте ML тратится на работу с данными. Этот процесс может быть разбит на четыре ключевых этапа.
Коллекция. Где вы получите данные?
Первый шаг - найти сырье. Современные источники разнообразны:
- Откройте наборы данных. Платформы, такие как Kaggle или Google DataSet Search, являются отличной отправной точкой для прототипирования.
- Апис Программный доступ к данным службы (например, API Twitter) для информации в реальном времени.
- Интернет. Автоматизированная коллекция информации с сайтов. Мощный, но требует осторожности от юридических и этических точек зрения.
- Внутренние данные. Часто наиболее ценным активом являются данные, которые уже владеет вашей компанией (журналы, отчеты о продажах, данные клиентов).
- Синтетические данные. Когда реальные данные скудны или слишком чувствительны, их можно создать искусственно, например, посредством увеличения изображения.
Хранилище. Библиотека, склад или гибрид?
Собранные данные должны быть где -то хранить, и выбор архитектуры критически важен.
- Хранилище данных. Это «библиотека» для структурированных, уже обработанных данных. Идеально подходит для бизнес-аналитики (BI), но негибко и не подходит для необработанных или неструктурированных данных.
- Данные озеро. Это «склад», где вы можете сбросить абсолютно все данные в его первоначальном формате. Он предлагает максимальную гибкость для исследований, но без надлежащего управления быстро превращается в хаотичный «болотный болот».
- Данные Лейкхаус. Новейший гибридный подход, стремящийся объединить упорядоченность склада с гибкостью озера. Его цель - стать единой платформой для задач BI и ML.
Уборка. Превращение хаоса в заказ
Необработанные данные почти всегда грязны: у него отсутствуют значения, ошибки, дубликаты и выбросы. Процесс предварительной обработки приводит его к заказу. Ключевые шаги:
- Обработка недостающих значений. Удаление или заполнение средним/медианом
- Исправление ошибок и предоставление данных в общий формат
- Нормализация. Принесение численных особенностей в общее масштаб, так что доход в миллионах не «заглушает» количество детей в модели
- Маркировка данных. Для контролируемого обучения, например, маркировки «кошка» и «собака» на фотографиях
Функциональная инженерия. Творчество и здравый смысл
Это, пожалуй, самый важный этап. Функциональная инженерия - это искусство и наука о создании новых, более информативных функций из существующих данных. Вместо того, чтобы кормить модель с помощью необработанной метки времени, вы можете создавать такие функции, как day_of_week или is_holiday, которые гораздо более значимы. Простой алгоритм с хорошо разработанными функциями почти всегда превзойдет сложную модель с плохими.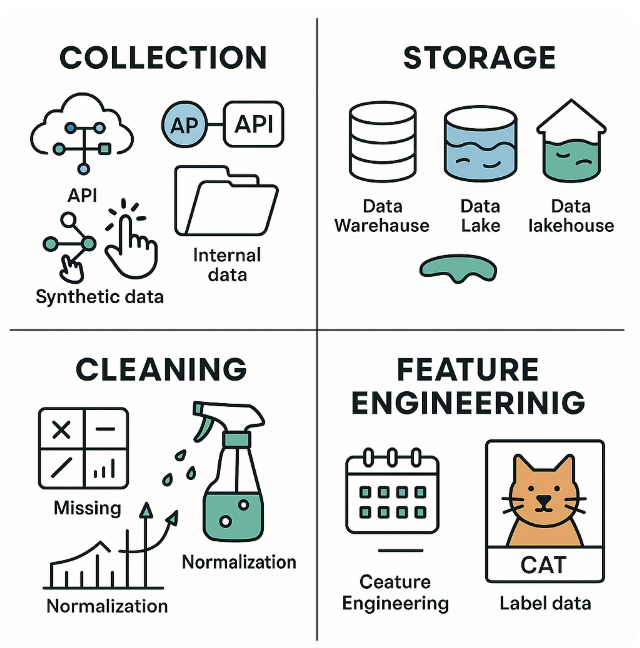
Этап 3. Стратегии для сравнения моделей
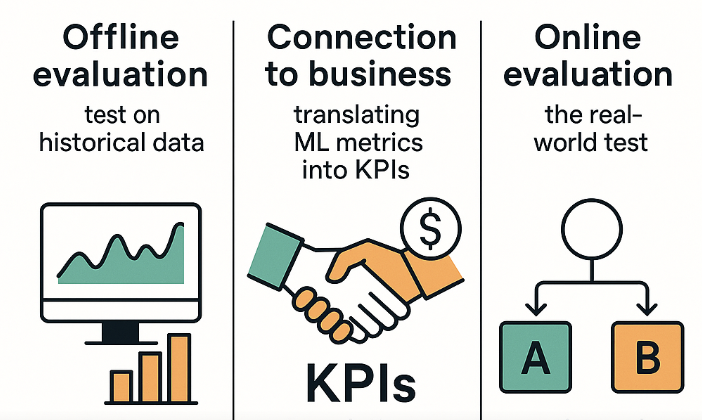
Определение того, является ли новая версия модели (модель B) на самом деле лучше, чем старая (модель A), является многоуровневой задачей, которая выходит далеко за рамки простого сравнения чисел в тестовом наборе. Уверенность в превосходстве новой модели построена на трех столпах: офлайн -оценка, связь с бизнес -метриками и онлайн -тестирование.
Отсутствие в автономном режиме. Проверка на исторические данные
Первым и важным шагом является офлайн -оценка. Здесь мы используем исторические данные для измерения качества модели, прежде чем развернуть ее для производства. Для этого мы используем технические показатели, описанные в предыдущем разделе (точность, F1-показатель, RMSE и т. Д.). Этот этап позволяет нам отфильтровать явно плохие модели и выбирать несколько кандидатов для дальнейшего, более глубокого анализа. Тем не менее, автономные метрики не всегда отражают реальную производительность модели, поскольку исторические данные могут не полностью соответствовать текущей ситуации.
Связь с бизнесом. Перевод метрик ML в KPI
Технические показатели, такие как точность и отзыв, мало говорят о бизнесе самостоятельно. Чтобы доказать ценность модели, их нужно перевести на язык ключевых показателей эффективности (KPI). Это количественные характеристики, которые показывают, насколько хорошо компания достигает своих целей.
Давайте рассмотрим пример модели прогнозирования оттока клиента:
- Ложный отрицательный (FN). Модель предсказала, что клиент останется, но он ушел. Для бизнеса это означает потерять всю жизнь (LTV) клиента.
- Ложный положительный (FP)ПолемМодель предсказала, что клиент будет снимать, поэтому мы предложили им скидку, чтобы сохранить их. Но на самом деле они все равно не уходили. Для бизнеса это означает ненужные дисконтные затраты, которые снижают прибыль.
Таким образом, выбор между оптимизацией точности (минимизации FP) и отзывом (минимизация FN) напрямую влияет на бизнес -метрики, такие как LTV (стоимость жизни) и CAC (стоимость приобретения клиентов). Успешная модель должна улучшить отношение LTV/CAC, демонстрируя его экономическую жизнеспособность.
Онлайн -оценка. Реальный тест
Окончательный вердикт по качеству модели доставляется только после тестирования его с реальными пользователями. Золотой стандарт для этого - A/B -тестирование.
Процесс тестирования A/B для модели ML включает в себя следующие шаги:
- Гипотеза формулировка и отбор метрики. Во -первых, четкая гипотеза определяется. Например: «Новая модель рекомендаций (версия B) увеличит среднее значение заказа (AOV) на 5% по сравнению со старой моделью (версия A)». Как технические показатели (точность, скорость отклика), так и, что более важно, продукты и бизнес -метрики (CTR, Conversion, AOV, LTV) выбираются в качестве критериев оценки.
- Расщепление трафика. Пользователи случайно разделены на две группы. Группа A (Control) продолжает взаимодействовать со старой моделью, а группа B (тест) с новой.
- Запуск эксперимента. Тест проводится в течение определенного периода (например, две недели), в течение которых собираются поведенческие данные из обеих групп.
- Анализ результатов. После того, как тест заканчивается, собранные данные анализируются с использованием статистических методов (таких как T-тесты), чтобы определить, является ли разница в метрик между группами статистически значимой.
- Принятие решений. Если новая модель (B) демонстрирует статистически значимое улучшение в ключевых бизнес -метриках, принято решение для передачи его всем пользователям. Если нет, система переворачивается обратно в предыдущую версию (а).
Только проходя все три этапа от автономного сравнения с успешным испытанием A/B, доказывая положительное влияние на бизнес -KPI, вы можете с уверенностью сказать, что новая модель действительно лучше.
Стадия 4. от лаборатории в реальное мир
Итак, вы построили модель с отличными метриками в автономном режиме. Путешествие от ноутбука Jupyter к продукту, который обеспечивает реальную ценность, - это именно то, где большинство проектов ML терпят неудачу. Именно здесь вступает инженерная дисциплина. Чтобы ваша модель была воспроизводимой, безопасной и эффективной в долгосрочной перспективе, вам необходимо освоить три критических областях: ведение журнала, развертывание и мониторинг.
Регистрация. «Черный ящик» ваших экспериментов ML
Разработка моделей ML по своей природе экспериментально. Без строгой системы регистрации она превращается в хаос. Вам остается интересно: «Подожди, какая версия данных дала мне показатель F1 0,92? Это было до или после того, как я изменил скорость обучения?»
Регистрация - это ваш единственный источник истины. Вот почему это важно и что вам нужно отслеживать.
Почему это не подлежит обсуждению:
- Воспроизводимость. Так что любой член команды (включая ваше будущее) может точно воспроизвести результат.
- Сравнение. Объективно сравнить модели и точно понять, какие изменения привели к улучшению или регрессии.
- Отладка. Когда модель начинает вести себя странно, журналы являются лучшим и первым инструментом для поиска основной причины.
Необходимо журнал для каждого запуска:
- Все гиперпараметры (Learning_Rate, Tree_Depth и т. Д.).
- Метрики и результаты эксперимента (F1-показатель, RMSE, точность и т. Д.).
- Кодовая версия: git commit hash
- Набор данных хэш. Абсолютно критично. Инструменты, такие как DVC, созданы для этого.
- Фактические результаты: сериализованная модель (model.pkl), графики (матрица путаницы, кривая ROC) и любые профили данных.
- Среда. Снимок ваших зависимостей, как правило, в качестве требований.
Чтобы избежать обычной работы, используйте специализированные инструменты. Например, MLFLOW предлагает удобный API для регистрации всего этого, и его функции автологов являются спасателем, автоматически сохраняя большую часть этой информации с помощью одной строки кода.
Развертывание. Не ломайте производство
Развернуть новую «улучшенную» модель для 100% пользователей сразу же безрассудно. Модель, которая отлично работала в изоляции, может рухнуть при реальной нагрузке или вызвать непредвиденные негативные последствия. Используйте проверенные стратегии для снижения рисков запуска.
Стратегия 1. Развертывание тени
Думайте об этом как о полной репетиции без аудитории. Новая модель развернута параллельно со старой (производственной) моделью. Входящий пользовательский трафик дублируется и отправляется на обе модели. Старая модель по -прежнему служит ответам пользователей. Новые ответы «теневой» модели не показаны пользователям, они тихо вошли для анализа.
Стратегия 2. Выпуск канарских ресурсов
Названная в честь канарских шахтеров, используемых для обнаружения токсичных газов, эта стратегия позволяет вам «безопасно проверять воду». Новая модель развернута до крошечной доли пользователей - «Канарских островов» (например, 1–5%). Оставшиеся 95–99% продолжают использовать старую стабильную модель. Если все выглядит хорошо в группе «Канарской» (как технически, так и в бизнесе), вы постепенно увеличиваете долю трафика: 10%, 25%, 50%и, наконец, на 100%. Если проблемы возникают на любом этапе, вы сразу же откатаетесь обратно к старой модели.
Пост-запуск мониторинг
Ваша работа не выполнена после развертывания. На самом деле, это только началось. Каждая модель со временем ухудшается, потому что реальный мир под ним продолжает меняться. Это явление называется модельным дрейфом, и игнорирование его является рецептом тихого неудачи.
Есть два основных типа дрейфа, на которые вы должны следить:
Дрифт данных.
Происходит, когда статистические свойства входных данных изменяются. Дрейф данных означает изменение в распределении входных данных модели. Пример: модель оценки кредита была обучена данным, где средний возраст заемщика составлял 35 лет. Год спустя новая маркетинговая кампания приводит к наводнению заявок от молодых 22-летних выпускников. Распределение для функции возраста «дрейфовало». Производительность модели в этой новой демографии может быть ненадежной, поскольку она видит данные, на которые она никогда не обучалась.
Концепция дрейфа.
Это более глубокий сдвиг, где изменяется взаимосвязь между входными данными и целевой переменной. Концепция дрейфа означает изменение взаимосвязи между входными переменными и тем, что вы пытаетесь предсказать. Пример: во время экономического кризиса поведение покупателя меняется. Клиент с тем же доходом и возрастом, который раньше был надежным покупателем, теперь может быть чрезвычайно чувствительным к цене. «Правила игры» изменились. Образо.
Систематический мониторинг для обоих типов дрейфа является краеугольным камнем MLOP. Это будильник, который говорит вам, что ваша модель устарела. Когда он звонит, пришло время вернуться в лабораторию, переучить модель на свежих, актуальных данных и перераспределить ее, чтобы она продолжала приносить ценность.
Заключение
Мы проследили весь путь от абстрактной бизнес-идеи до сложной, отслеживаемой и ценностной системы ИИ, работающей в производстве. Нервная система всего этого процесса - трубопровод ML. Он превращает отключенные шаги в единый, автоматизированный и надежный механизм.
Это путешествие ясно демонстрирует, как изменилась роль инженера машинного обучения. Сегодня это уже не просто специализированные модели здания в ноутбуке Юпитера. Современный инженер ML является системным архитектором, экспертом по стратегии данных и специалистом по операциям. Они должны понимать бизнес -контекст, разрабатывать архитектуры данных, создавать надежные и воспроизводимые трубопроводы и взять на себя ответственность за этическое и стабильное функционирование своих систем в реальном мире.
Освоение принципов и практик, описанных в этом руководстве, от формулировки проблем и обработки данных до развертывания, мониторинга и реализации передовых парадигм, таких как MLOP и ответственный ИИ, является ключом к успеху в этом сложном, но невероятно захватывающем поле.
Подписывайтесь на меня
GitHub
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Лучшие новогодние подарки для владельцев домашних животных
29 мая 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27342)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)