
Новый эталон в локализации на языке зрения
16 июля 2025 г.Таблица ссылок
Аннотация и 1. Введение
Связанная работа
Метод
3.1 Обзор нашего метода
3.2 грубое извлечение текстовых клеток
3.3 Оценка прекрасной позиции
3.4 Цели обучения
Эксперименты
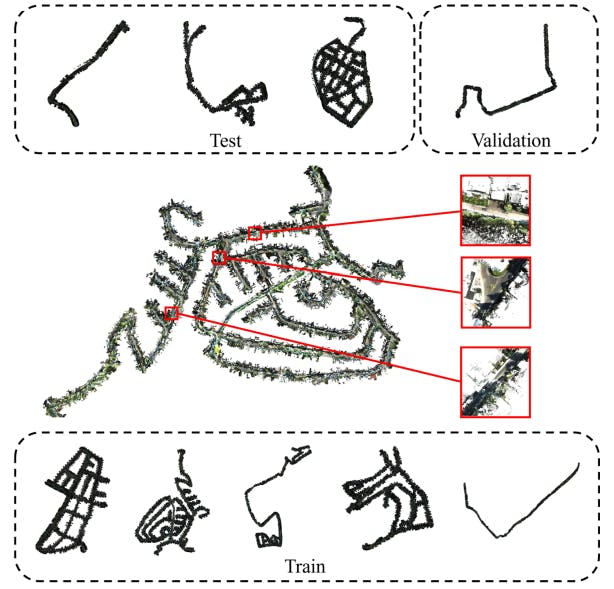
4.1 Описание набора данных и 4.2 Подробная информация
4.3 Критерии оценки и 4.4 результаты
Анализ производительности
5.1 Исследование абляции
5.2 Качественный анализ
5.3 Анализ встраивания текста
Заключение и ссылки
Дополнительный материал
- Подробная информация о наборе данных Kitti360
- Больше экспериментов по экстрактору запроса экземпляра
- Анализ космического пространства текстовых клеток
- Больше результатов визуализации
- Анализ устойчивости точек
Анонимные авторы
- Подробная информация о наборе данных Kitti360
- Больше экспериментов по экстрактору запроса экземпляра
- Анализ космического пространства текстовых клеток
- Больше результатов визуализации
- Анализ устойчивости точек
4.3 Критерии оценки
В соответствии с текущими исследованиями мы принимаем отзыв вверху 𝑘 (для 𝑘 = 1, 3, 5) в качестве нашего метрики для оценки грубой стадии возможности извлечения текстовых клеток. Для оценки тонкой стадии мы используем нормализованную ошибку расстояния евклидовы между положением Loundtruth и прогнозируемой позицией. Между тем, чтобы оценить комплексную эффективность нашего IFRP-T2P, мы оцениваем эффективность локализации на основе лучших результатов поиска, где 𝑘 установлено на 1, 5 и 10, и впоследствии сообщают об отзыве локализации. Отзыв о локализации определяется количественно как доля текстового запроса, точно локализованного в предопределенных полях ошибок, которая обычно составляет менее 5, 10 или 15 метров.
4.4 Результаты
Локализация трубопровода.Чтобы провести всестороннюю оценку IFRP-T2P, мы сравниваем нашу модель с тремя современными моделями [21, 39, 42] в двух сценариях: один принимает экземпляр грунтовой истины как вход, а другой использует необработанное облако точки в качестве входного ввода. В контексте сценария облака необработанных точек мы дополнительно сравниваем нашу модель с базовыми базовыми показателями 2D и 3D визуальной локализации, в частности, Netvlad [2] и PointNetVlad [36], чтобы продемонстрировать эффективность нашей мультимодальной модели. Мы сообщаем о результате Netvlad, доступном в Text2pos. Для PointNetVlad мы используем нисходящую одну треть центральную область облака клеточных точек в качестве запроса для извлечения верхних ячеек и применения центра ячейки в качестве основанной позиции, аналогичной настройки NetVlad в Text2PO. В таблице 1 иллюстрирует топ-𝑘 (𝑘 = 1/5/10) частота отзыва различных порогов ошибок 𝜖 <5/10/15𝑚 для сравнения. Наш IFRP-T2P достигает 0,23/0,53/0,64 в TOP-1/5/10 при границе ошибок 𝜖 <5𝑚 при наборе валидации. В сценарии, где необработанное облако точки применяется в качестве ввода, наша модель превосходит Text2loc с предыдущей моделью сегментации экземпляров на 27%/23%/17%в TOP-1/5/10 под границей ошибок 𝜖 <5𝑚. Сравнивая с Text2Loc, наша модель показывает сопоставимую производительность - нанесение всего лишь 17%/8%/7%при TOP1/5/10 в соответствии с границей ошибок 𝜖 <5𝑚. Обратите внимание, что мы сообщаем о результате нашего воспроизведенного Text2loc и значений, доступных в исходной публикации RET и Text2PO. Эта тенденция также наблюдается в тестовом наборе, указывая на нашу модель IFRP-T2P, эффективно снижает зависимость от экземпляров истины земли в качестве входных данных и эффективно интегрирует относительную информацию о положении в процесс крупной к покровому локализации для повышения общей производительности локализации. Кроме того, наша модель превосходит Netvlad и PointNetVlad
![Table 4: Ablation study of the row-column relative position-aware self-attention (RowColRPA) in coarse stage. “Naive” refers to the employment of standard self-attention mechanisms. “Value” denotes integrating pooled relative position features into the value, akin to the methodology described in RET [39]. “Row” signifies adding the query with row-wise pooled relative position features. “RowCol” stands for our proposed RowColRPA.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-18033ld.png)
на 28%/82%/88%и 10%/20%/19%в TOP-1/5/10 под границей ошибок 𝜖 <5𝑚. Этот результат указывает на то, что наша мультимодальная модель более эффективна по сравнению с 2D/3D мономодальными моделями.
Крупный поиск текстовых клеток.В соответствии с текущими работами, мы оцениваем грубую производительность извлечения текстовых клеток на валидации и тесте Kitti360. В таблице 2 представлены отзыв TOP-1/3/5 для каждого метода. Наш IFRP-T2P достигает отзыва 0,24/0,46/0,57, в наборе проверки. В сценарии, где необработанное облако точки применяется в качестве ввода, наша модель превосходит Text2loc с предыдущей моделью сегментации экземпляров на 26%/24%/23%при уровне отзыва TOP-1/3/5. Сравнивая с Text2Loc, наша модель показывает сопоставимую производительность-начисление всего лишь 17%/10%/8%при показателях отзыва TOP-1/3/5 в наборе валидации. Эта тенденция также наблюдается в тестовом наборе, что указывает на то, что предлагаемый нами экстрактор запроса экземпляра может эффективно генерировать запросы экземпляров с помощью семантической информации, а модуль Rowcolrpa может отразить важную информацию относительного положения потенциальных экземпляров. Более качественные результаты приведены в разделе 5.2.
Оценка прекрасной позиции.Чтобы оценить производительность модели тонкой стадии, мы используем парные ячейки и описания текста в качестве входных и вычисляющих нормализованное евклидовое расстояние между положением Groundtruth и прогнозируемой позицией. Мы нормализуем длину боковой ячейки до 1. Таблица 3 показывает, что при сценарии без экземпляров наша модель оценки тонкой положения дает 0,118 нормализованную эвклидовую ошибку расстояния, которая на 2% и 9% ниже по сравнению с Text2loc2PO в наборе валидации. Эта тенденция также наблюдается в тестовом наборе. Этот результат указывает на то, что наш модуль RPCA эффективно включает в себя информацию о пространственном соотношении в процессе слияния текста и облака точек и, таким образом, улучшает производительность оценки тонкой позиции.
Авторы:
(1) Lichao Wang, FNII, Cuhksz (wanglichao1999@outlook.com);
(2) Zhihao Yuan, FNII и SSE, Cuhksz (zhihaoyuan@link.cuhk.edu.cn);
(3) Jinke Ren, FNII и SSE, Cuhksz (jinkeren@cuhk.edu.cn);
(4) Shuguang Cui, SSE и FNII, Cuhksz (shuguangcui@cuhk.edu.cn);
(5) Чжэнь Ли, автор -соответствующий автор из SSE и FNII, Cuhksz (lizhen@cuhk.edu.cn).
Эта статья есть
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Лучшие новогодние подарки для владельцев домашних животных
29 мая 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27328)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)