

Руководство по c# tesseract ocr и сравнение с Ironocr
7 августа 2025 г.В современном мире цифрового мира оптическое распознавание символов (OCR) необходимо для автоматизации сбора данных, оптимизации рабочих процессов и разблокировки значения, пойманного в сканированных файлах. Независимо от того, обрабатываете ли вы счета -фактуры на логистической платформе или оцифруете рукописные рецепты в здравоохранении, OCR служит основным фактором.
В этой статье предлагается всеобъемлющее руководство по использованию Google Tesseract With H C#, исследует его технические ограничения и представляет Ironocr, надежную, дружелюбную для разработчиков библиотека .NET OCR, которая нарастает и улучшает Tesseract.
Хотите лучшего OCR в C# с меньшим количеством головных болей? Загрузите бесплатную пробную версию Ironocr и следуйте нашим примерам.
Что такое tesseract ocr?
Краткая история Tesseract
Tesseract начался как внутренний исследовательский проект в HP в 1980-х годах, а затем был открыт и принят Google. Он написан в C/C ++ и теперь является зрелым и широко используемым двигателем OCR с поддержкой более 100 языков, что делает его популярным и простым в использовании инструмент для извлечения текста и данных из файлов изображений и многого другого.
Почему Tesseract популярен
Есть много причин, по которым Tesseract стала популярным инструментом, но некоторые из наиболее ключевых причин включают в себя:
- Бесплатный и открытый источник: Лицензировано в соответствии с Apache 2.0, он идеально подходит для личного или академического использования.
- Очень многоязычный: При поддержке 100+ языков он охватывает почти все глобальные варианты использования.
- Точный и стабильный: Двигатель на основе LSTM (V4+) предлагает гораздо лучшее распознавание, чем более ранние версии.
- Расширяется: Языковая обучение, настройка шрифтов и разработка пользовательской модели возможны, хотя и сложны.
Основные варианты использования
Tesseract OCR может быть применен для различных вариантов использования для таких задач, как извлечение текста из изображений и отсканированных документов. Некоторые общие варианты использования включают:
- Извлечь текст из отсканированных юридических документов или форм
- Оцифровать рукописные заметки (со смешанными результатами)
- Создание инструментов автоматизации документов для счетов, идентификаторов и билетов
- Преобразовать отсканированные страницы в цифровые архивы для поиска
Как работает Tesseract под капюшоном
В то время как мощные функции Tesseract легко использовать и реализовать в ваших проектах, под этими функциями есть мощные элементы, которые работают, чтобы обеспечить каждые функции, как и должно, в том числе:
- Предварительная обработка изображения: Подготовьте изображение, удаляя шум, преобразуя в серогойский или двоичный, и исправляя перекоси. Это обычно обрабатывается извне через такие библиотеки, как ImageMagick или OpenCV.
- Анализ макета: Tesseract пытается обнаружить структуру страницы, текстовые строки сегмента и идентифицировать блоки.
- Двигатель OCR: Используя модели LSTM, он распознает символы и слова, пытаясь реконструировать логический текстовый поток.
- Доверие забивание: Каждое распознаваемое слово сопровождается достоверной метрикой, которая может использоваться для фильтрации или флагирования результатов с низкой достоверностью.
- Выработка генерации: Вы можете извлечь простой текст, HOCR (HTML с позиционированием) или TSV (значения, разделенные TAB) для структурированной пост-обработки.
Основная реализация в C#
Использование Tesseract в среде C# обычно включает в себя обертку Чарльза Уэлда (tesseract.netSDK), что упрощает вызов нативного Tesseract DLL.
Предварительные условия
- Добавьте пакет Tesseract Nuget в свой проект.
- Загрузить соответствующие файлы.Tesseract Github RepoПолем
- Убедитесь, что ваше приложение может получить доступ к собственным двоичным файлам на целевой платформе (Windows X64, Linux и т. Д.).
Простой пример: извлечь текст из изображения
Входное изображение

Код:
using Tesseract;
using (var engine = new TesseractEngine(@"./tessdata", "eng", EngineMode.Default))
using (var img = Pix.LoadFromFile("invoice.png"))
using (var page = engine.Process(img))
{
Console.WriteLine("Text: " + page.GetText());
Console.WriteLine("Confidence: " + page.GetMeanConfidence());
}
Выход
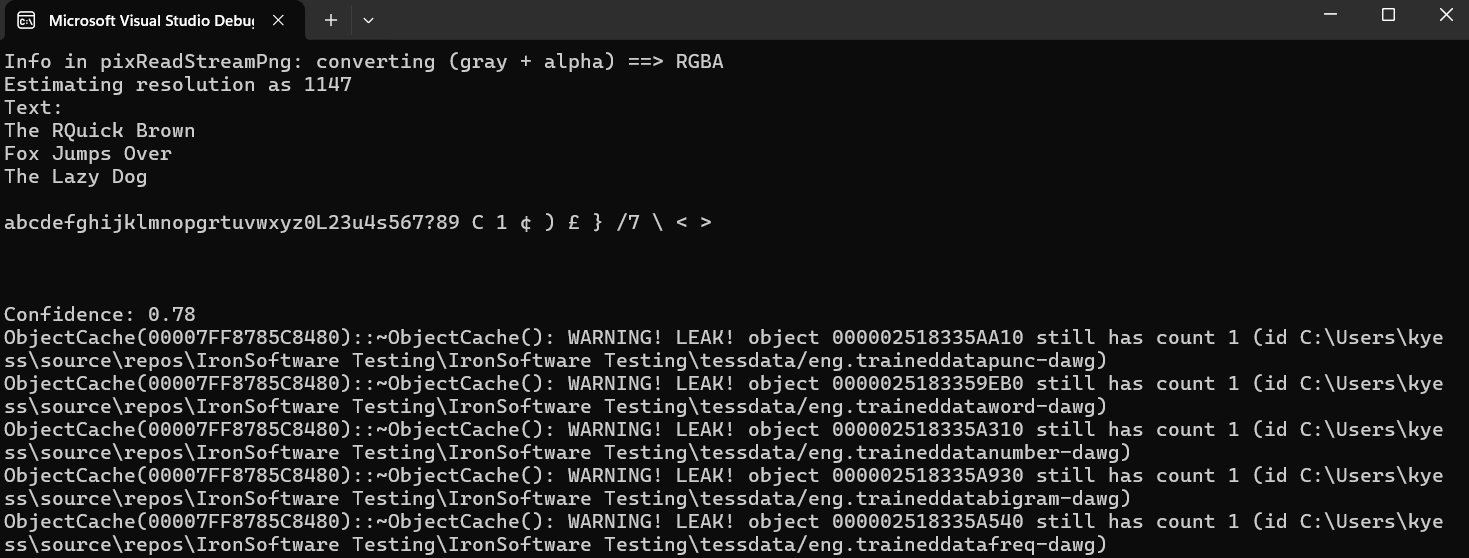
Ловушки, чтобы посмотреть
- Масштабирование DPI: Изображения с низким разрешением разлагают точность.
- Языковая конфигурация: Если не установлено правильно, может применяться распознавание только по английскому языку.
- Ошибки взаимодействия: Может быть сложно отлаживать по всей ОС или целям развертывания.
Усовершенствованные задачи OCR с Tesseract
Многоязычный OCR
Вы можете объединить несколько языков, присоединившись к ним с знаком плюс:
var engine = new TesseractEngine(@"./tessdata", "eng+deu", EngineMode.Default);
Но это увеличивает время обработки и использование памяти, и точность в значительной степени зависит от качества и выравнивания данных, обученных языком.
Предварительная обработка изображения
Производительность Tesseract связана непосредственно с качеством изображения. Разработчики часто используют внешние библиотеки, такие как:
- OpenCV(с помощьюOpenCVSharp): Размытие, изменение размера и денирования
- ImageMagick:Deskew, обрезать, преобразовать в Greyscale
- Skiasharp:Легкая обработка растровой карты
Пример: базовая бинаризация с OpenCVSharp
Cv2.CvtColor(src, gray, ColorConversionCodes.BGR2GRAY);
Cv2.Threshold(gray, binary, 0, 255, ThresholdTypes.Otsu);
PDF Текст извлечение
Поскольку tesseract не читает документы PDF напрямую, разработчики обычно конвертируют PDF в TIFF или PNG -изображения, сначала используя:
- Ghostscript
- PdfiumViewer
- Magick.net
Это добавляет сложность, вводит потерю верности и замедляет производительность.
Чтение таблиц, штрих -коды или QR -коды
Tesseract борется с табличным содержанием или пространственными данными, такими как штрих -коды и QR -коды. Чтобы надежно извлечь такой контент, вам понадобятся внешние инструменты или дорогостоящая постобработка.
Общие проблемы с Tesseract в C#
- Требуется предварительная обработка вручную:Вы несете ответственность за то, чтобы сделать каждое изображение готовым к OCR.
- Развертывание сложно:Нативные двоичные файлы должны соответствовать платформе/архитектуре. Обученные в комплекте данные увеличивают размер установщика.
- УДАЛЕНИЕ ПЕРСОВЫХ ПРИМЕНЕНИЯ:Однопоточная операция. Обработка многих документов одновременно требует многопроцессорных обходных путей.
- Низкая достоверность отладка:Нет встроенной визуализации для уверенности или макета.
- Ограниченная поддержка нативной .NET:Все варианты использования .NET основаны на обертках с ограниченным охватом API.
Почему разработчики ищут альтернативы Tesseract
Для реальных бизнес-приложений Tesseract часто терпит неудачу из-за:
- Высокие усилия по настройке и настройке
- Умеренная точность из коробки
- Отсутствие встроенной поддержки файлов PDF, штрих-кодов и сложных документов
- Вялая производительность и отсутствие асинхронной/параллельной обработки
Это заставляет многих команд .NET искать управляемые альтернативы, такие как Ironocr, построенные специально для среды и производительности .NET.
Представляем Ironocr - Enhanced Tesseract для .net
Что такое Ironocr?
Линокэто коммерческий двигатель OCR, созданный для разработчиков .NET. Он интегрирует основные возможности Tesseract в рамках управляемой высокопроизводительной обертки (iRontesseract) и добавляет расширенные функции, разработанные для приложений реального мира.
Ironocr не простоупростить OCR; Он преобразует его в надежную, масштабируемую часть любого решения .NET, не беспокоясь о зависимостях или предварительной обработке.
Ключевые функции
- OCR непосредственно из PDF -документов, TIFFS, JPGS, PNGS или даже скриншотов.
- Встроенная многопоточная обработка.
- Умная предварительная обработка (удаление шума, повышение контрастности, автоматическое повышение, усиление разрешения).
- Более 125 языков, с автоматическим обнаружением языка.
- Установка NUGET- Нет хлопот DLL.
- Поддержка штрих -кода и QR, структурированный анализ документов.
- Сильная кроссплатформенная поддержка, с поддержкой .NET Framework, .NET CORE, .NET 5/6/7+, Azure, Docker и Maui.
Установка
Ironocr может быть легко реализован в ваши проекты Visual Studio через консоль Manager Package Package, просто запустите следующее:
Install-Package IronOcr
IronOCR Architecture: How It Improves Tesseract
- Управляемый код:Полностью .NET Native, без платформы C ++ двоичные файлы.
- Интеллектуальные фильтры:Встроенные фильтры предварительной обработки удаляют шум и перекосит без внешних библиотек.
- Единый ввод:Работайте с изображениями, PDF -файлами, потоками файлов, потоками памяти или байтовыми массивами.
- Визуализация доверия:Осмотрите макет, сегментацию линии и уверенность на слово.
- Скорость:Параллельная обработка с помощью асинхронного двигателя Ironocr для крупномасштабных рабочих нагрузок.
Сравнение Google Tesseract и Ironoc
Особенность | Google Tesseract | Линок |
|---|---|---|
.NET поддержка | Через обертку | Нативный .NET NUGET PACKE |
PDF OCR | Внешнее преобразование | Встроенный |
Многопоточный | Ручная установка | Автоматический |
Предварительная обработка изображения | Руководство | Встроенные фильтры |
Языковая поддержка | Требуется настройка | БУНДА + АВТО DETECT |
Точность | 85–90% | До 99,8% |
Развертывание | Сложный | Легкий |
Поддержка штрих -кода/QR | Внешний | Включен |
Лицензирование | Открытый исходный конец | Коммерческий с бесплатной пробной версией |
Визуальное сравнение: точность OCR
Чтобы сравнить, как Tesseract выдерживает Ironocr дляточностьПри выполнении задач OCR на изображениях мы будем использовать оба инструмента для чтения следующего входного изображения:

Вывод Tesseract
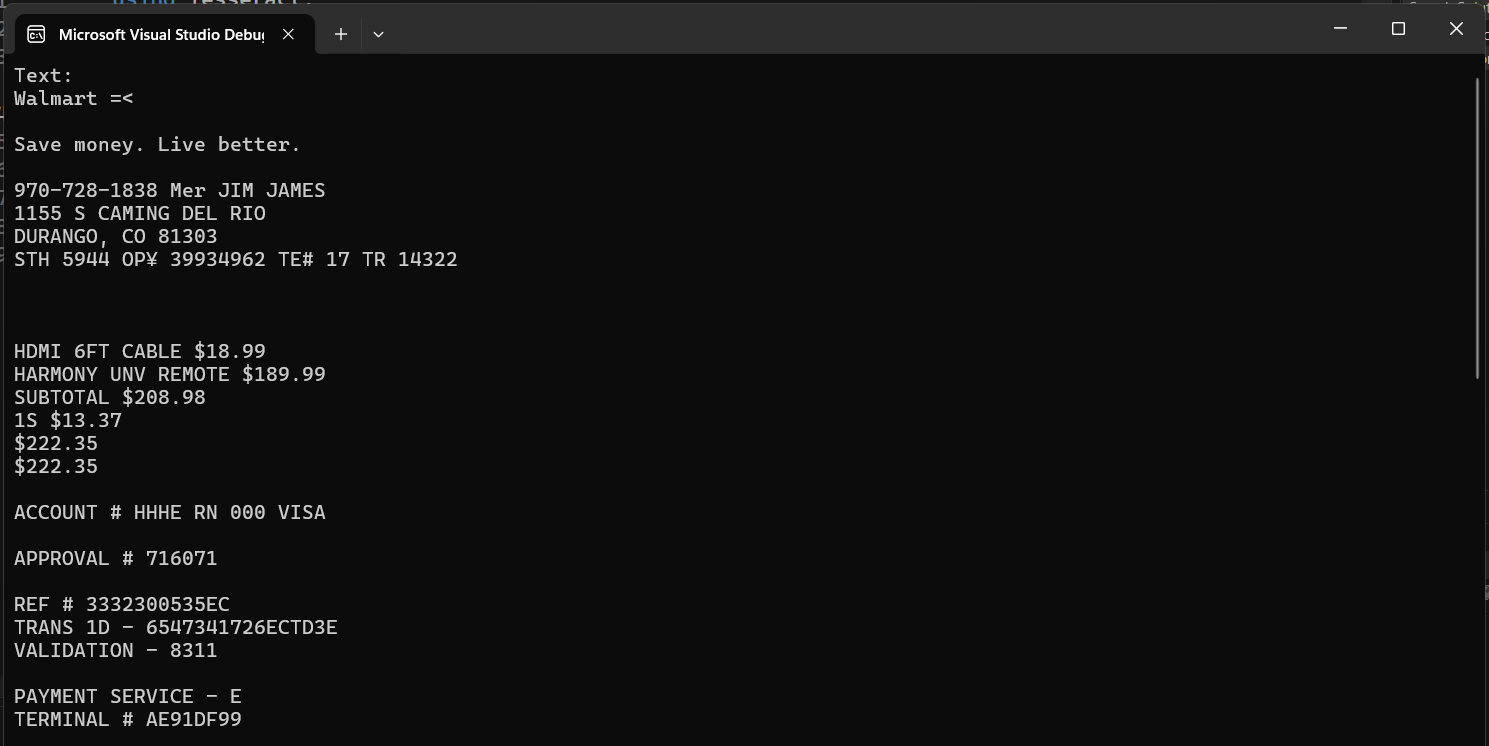
Irogocrower
Сравнение таблицы
Особенность | Tesseract Ocr | Линок |
|---|---|---|
Встроенная предварительная обработка | ❌ Требуются внешние либера | ✅ Автоматическое на загрузке |
Точность текста квитанции | ⚠ Средний (шумный выход) | ✅ выше (с нечеткой логикой) |
Сохранение макета | ❌ Слабо | ✅ Поддерживает выравнивание лучше |
Скорость в больших документах | ✅ быстро | ⚠ немного медленнее |
Языковая поддержка | ✅ Обширный | ✅ 125+ языков |
.NET Native Support | ⚠ через обертки | ✅ Нативная интеграция .net |
Работает без интернета | ✅ Да | ✅ Да |
Сравнение кода: Tesseract против Ironocr
При работе с OCR в C#опыт реализации значительно различается междуTesseractиЛинокПолем Ниже приведено сравнение обеих библиотек с использованием одной и той же задачи: извлечение текста из отсканированного изображения квитанции.
1Читать текст из изображения
Во -первых, мы посмотрим, как эти инструменты обрабатывают извлечение текста из следующего изображения:

Линок
using IronOcr;
var ocr = new IronTesseract();
using var input = new OcrImageInput("sample.png");
var result = ocr.Read(input);
Console.WriteLine(result.Text);
Выход

Ironocr делает чтение изображения кратким и высоким уровнем. Класс Ocrinput обрабатывает предварительную обработку (Deskew, Contrast и т. Д.) Автоматически, в то время как READ () устраняет обработку двигателей.
Tesseract
using Tesseract;
var engine = new TesseractEngine(@"./tessdata", "eng", EngineMode.Default);
using var img = Pix.LoadFromFile("sample.png");
using var page = engine.Process(img);
Console.WriteLine(page.GetText());
Выход

Подход Tesseract является более низким уровнем. Вы должны управлять двигателем OCR и загрузкой изображения. Несмотря на мощное, это требует большей настройки и шаблона.
2. ocr файл PDF
Линок
using IronOcr;
var ocr = new IronTesseract();
var input = new OcrPdfInput("sample.pdf");
input.ToGrayScale();
var result = ocr.Read(input);
Console.WriteLine("Text from PDF:" + result.Text);
Выход
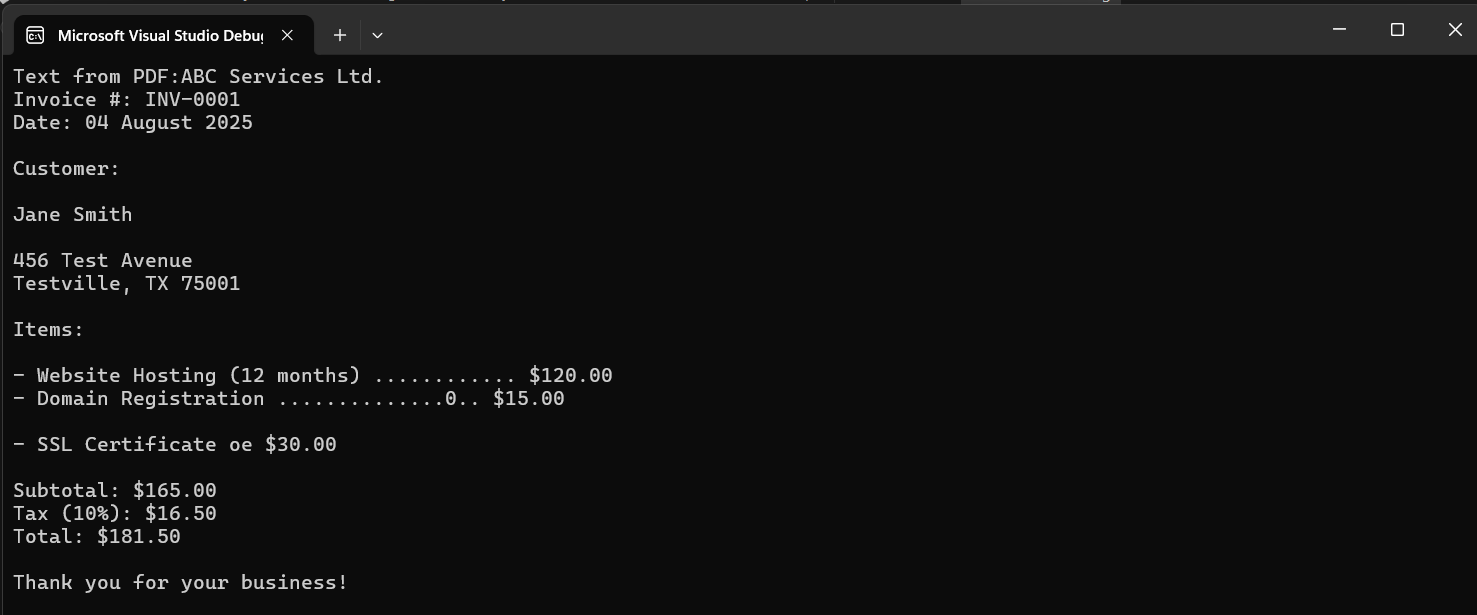
С Ironocr поддержка PDF является родной. Readpdf () непосредственно обрабатывает PDF -страницы внутренне - конверсии не требуется.
Tesseract (требует PDF для преобразования изображения)
// Tesseract doesn’t support PDFs directly.
// You must convert each page to an image first using a tool like Ghostscript or ImageMagick.
// Example assumes conversion to 'page1.png'
var engine = new TesseractEngine(@"./tessdata", "eng", EngineMode.Default);
using var img = Pix.LoadFromFile("page1.png");
using var page = engine.Process(img);
Console.WriteLine(page.GetText());
Выход
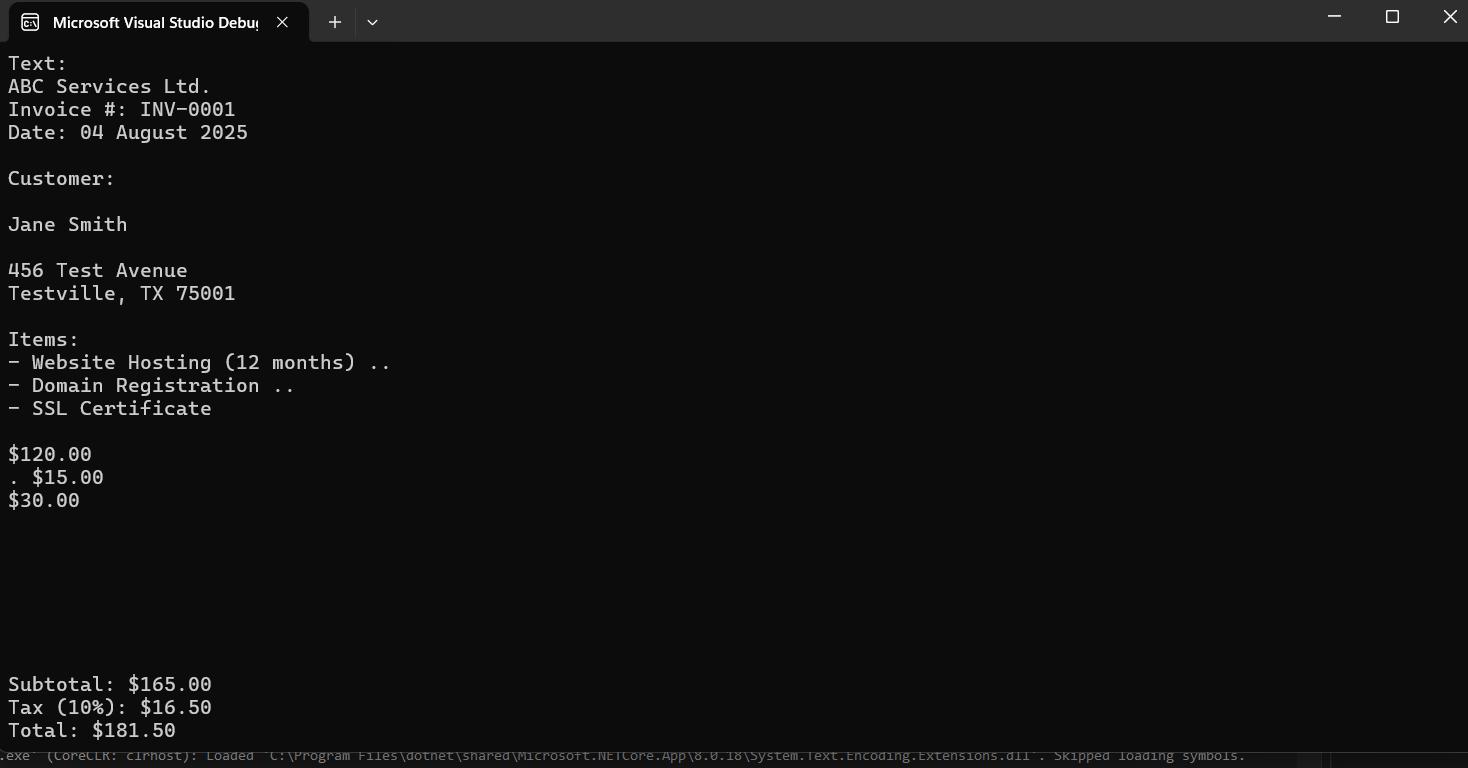
Tesseract не хватает поддержки PDF. Вам нужно будет предварительно обработать каждую страницу вручную и пройти через конвертированные изображения.
3Генерировать PDF -файл
Линок
using IronOcr;
using System;
using System.Data;
var ocr = new IronTesseract();
ocr.Configuration.ReadDataTables = true;
using var input = new OcrPdfInput("sample.pdf");
var result = ocr.Read(input);
result.SaveAsSearchablePdf("output.pdf");
Это создает настоящий доступ к поиску PDF за один раз. Овернутый текст встроен под исходное изображение, которое идеально подходит для индексации.
Tesseract
Tesseract не поддерживает создание файлов pdfs для поискаизначальноПолем Вам нужно:
- Конвертировать PDF в изображения
- Ocr каждое изображение
- Используйте такие инструменты, как HOCR2PDF, PDFSANDWICH или OCRMYPDF через командную строку
Не существует прямого решения для кода C# для PDF-файлов, доступных для поиска с Tesseract.
4Многоязычный OCR
Линок
using IronOcr;
var ocr = new IronTesseract();
ocr.Language = OcrLanguage.English;
ocr.AddSecondaryLanguage(OcrLanguage.Arabic);
ocr.AddSecondaryLanguage(OcrLanguage.ChineseSimplified);
С Ironocr вы можете легко объединить несколько языков, позволяя прочитать многоязычные документы.
Tesseract
var engine = new TesseractEngine(@"./tessdata", "eng+fra", EngineMode.Default);
🛈 Вы должны вручную загрузить и разместить файл. TraindatedData каждого языка в папку TessData.
5. Обнаружение и правильное вращение страницы
Перед ротацией:

Линок
using IronOcr;
var ocr = new IronTesseract();
using var input = new OcrImageInput(@"C:\Users\kyess\source\repos\IronSoftware Testing\IronSoftware Testing\bin\Debug\net8.0\rotated-page.png");
input.Deskew();
input.SaveAsImages("deskewed-pages", IronSoftware.Drawing.AnyBitmap.ImageFormat.Png);
Выход

Авторация обрабатывается Ironocry внутренне. Никакой предварительной обработки изображений не требуется для исправления перекоса или вращения сканирования.
Tesseract
// Tesseract does not auto-rotate.
// You need to use OpenCV or ImageMagick to detect/correct rotation first.
using var engine = new TesseractEngine(@"./tessdata", "eng", EngineMode.Default);
using var img = Pix.LoadFromFile("manually-fixed.jpg");
using var page = engine.Process(img);
TessEract не вытекает на автоматическую вытянутую. Разработчики должны интегрировать внешние библиотеки обработки изображений, чтобы исправить выравнивание.
Краткое содержание
Особенность | Линок | Tesseract |
|---|---|---|
Прочитайте текст изображения | ✅ Легко, 2 строки | ✅ Умеренная настройка |
OCR PDF | ✅ Нативная поддержка | ❌ нуждается в PDF для обработки обходного пути |
Доступен для поиска PDF | ✅ Встроенный метод | ❌ Требуются инструменты или сценарии CLI |
Многоязычный OCR | ✅ 125+ | ✅ Ручная конфигурация и загрузки |
Авто -дескью/вращение | ✅ Встроенный | ❌ Должен предварительно обращаться вручную |
Руководство по использованию: когда использовать Tesseract против Ironocr
Используйте Tesseract, если:
- Вы работаете над открытым источником или академическими проектами
- Вам нужен абсолютный контроль над внутренними видами OCR
- Вам удобно управлять конвейерами изображений и учебными данными
Используйте Ironocr, если:
- Вы хотите быстрое развитие с высокой точностью
- Вам нужна надежная поддержка PDF, распознавание таблиц или развертывание облака
- Ваш бизнес требует коммерческой поддержки и долгосрочной стабильности
Основной момент: Ironocr в железной номере
Ironocr - только одна частьIronsoftware Suite, разработан для приложений .NET, ориентированных на документы. С жесткой интеграцией между:
- Ironpdf(Создание и преобразование PDF)
- Ironxl(Excel Export/Import)
- Железное слово(Генерация файлов docx)
- Ironqr(Штрих -код и сканирование QR)
- Ironzip(сжатие/декомпрессия)
… Разработчики могут создавать полные трубопроводы документов под одним унифицированным инструментом.
Почетные упоминания: другие альтернативы Tesseract
В то время как IRONOCR идеально подходит для большинства потребностей .NET, этиальтернативыстоит отметить:
- Aspose.ocr- Комплексный, но дорогой
- Leadtools Ocr- Отличное распознавание изображений, сложные цены
- PDFTRON OCR- в комплекте в полном SDK
- Syncfusion ocr- Часть крупного предприятия
- eiceblue ocr- Доступная, но ограниченная обработка в формате PDF
🔗 Для полного сравнения:Смотрите блог о сравнении Ironocr
Лицензирование: с открытым исходным кодом против коммерческого
При выборе двигателя OCR для вашего приложения .NET лицензирование является критическим фактором, особенно при рассмотрении развертывания, перераспределения или коммерческого использования.
Лицензирование Tesseract
Tesseract OCR выпускается подApache License 2.0, что делает этоБесплатный и открытый источникПолем Эта лицензия позволяет:
- Коммерческое использование
- Модификация и распространение
- Интеграция в проприетарные системы (с надлежащей атрибуцией)
Однако есть предостережения:
- ТыОтвечает за вашу собственную поддержку, исправления ошибок и обновленияПолем
- Соответствие лицензированию полностью падает на команду разработчиков.
- ЕстьНет официальной поддержкиили гарантии для безопасности, разработки функций или совместимости с обновлениями .NET.
Для внутренних инструментов или экспериментальных прототипов Tesseract может быть гибким и экономически эффективным выбором. Но как только ваше приложение масштабируется или нуждается в долгосрочной обслуживаемости, эти аспекты DIY могут стать узкими местами.
IROCOCRING LICENSING
IronocrКоммерческая библиотека OCRразработано специально для разработчиков .NET. Он поставляется с четкой структурой лицензирования:
- Бесплатная пробная версияс водяными знаками и ограничениями
- Лицензии вечных разработчиковДля настольных компьютеров, сервера или облачного развертывания
- Варианты предприятия и OEMДля крупномасштабного или коммерческого распределения
С оплачиваемой лицензией вы получаете:
- Полный доступ кПремиальные особенностиКак и для поиска, генерация PDF, усовершенствованное обнаружение таблиц и многоязычный OCR
- Профессиональная поддержка, исправления ошибок и непрерывные обновления
- АПрямая модель развертыванияне полагаясь на внешние инструменты, такие как исполняемые файлы Tesseract или каталоги TessData
Лицензирование Ironocr предназначено дляуменьшить юридическую сложностьиускорить доставку, особенно для коммерческих команд программного обеспечения.
Заключение и следующие шаги
Tesseract остается влиятельным игроком в OCR, особенно в среде с открытым исходным кодом. Тем не менее, для профессиональной разработки .NET, он вводит ограничения, которые могут препятствовать срокам проекта и пользовательским опытом.
Линокпредлагает современную, точную и удобную для разработчиков альтернативаПолем Он снижает код котла, улучшает распознавание из коробки и предлагает кроссплатформенную совместимость-создает его идеальное для команд, создающих интеллектуальные приложения .NET.
✅ Начните с бесплатной пробной версии IronocrИ изучите, как это может улучшить ваш следующий проект с поддержкой OCR.
Приложение: дополнительные ресурсы и соображения
Если вы оцениваете инструменты OCR для своих проектов .NET, вот несколько полезных ресурсов и тем, которые нужно изучить:
- Документация Ironocr-Получить подробные направляющие и ссылки на API для быстрого интеграции функций OCR сДокументация IronocrПолем
- Tesseract Github Repository-Исследуйте основной двигатель с открытым исходным кодом, стоящий за многими системами OCR:https://github.com/tesseract-ocr/tesseract
- Производительность-Рассмотрите возможность измерения скорости распознавания, точности и использования ресурсов в реальных приложениях .NET.Сравнительный анализможет помочь вам определить все это для инструментов, которые вы рассматриваете для ваших потребностей в OCR.
- Сравнение языковой поддержки-Оцените поддержку неанглийских языков, текста RTL и рукописного ввода между инструментами.
- Безопасность и развертывание- Фактор в локальной обработке облака, требованиях к лицензированию и вариантам коммерческой поддержки.
Для команд, сосредоточенных на доставке готовых к производству приложений .NET с функциями OCR,Линокпредлагает отполированный и полностью поддерживаемый опыт с минимальной настройкой.
✅ Начните строить более умные приложения OCR сегоднясБЕСПЛАТНЫЙ испытание IronocrПолем
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
4 признака того, что ваш Instagram взломали (и что делать)
16 ноября 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Предстоящие эксклюзивы для PS5 — график выхода подтвержденных игр
24 октября 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
Categories
- Технологии и IT (26631)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)