Давайте узнаем об Elasticsearch из этих 40 бесплатных историй. Они упорядочены по наибольшему времени чтения, созданного на HackerNoon. Посетите /Learn Repo, чтобы найти самые читаемые истории о любой технологии.
1. Взгляд на использование Elixir Streams, Elasticsearch & АМС S3
 Использование Elixir Streams, Elasticsearch и AWS S3
Использование Elixir Streams, Elasticsearch и AWS S3
2. Сравнение AWS ECS и AWS Lambda
 Сравнение облачных сервисов? Прочтите наше руководство по Lambda и ECS. Учитывайте язык программирования, цены и преимущества.
Сравнение облачных сервисов? Прочтите наше руководство по Lambda и ECS. Учитывайте язык программирования, цены и преимущества.
3. Решайте несколько задач одновременно с помощью Kibana Tool

4. Clickhouse, Elasticsearch и Manticore Время поисковых запросов с 1,7 млрд поездок на такси в Нью-Йорке
 Поездки на такси в Нью-Йорке (NYC), вероятно, являются наиболее часто используемым ориентиром в области анализа данных.
Поездки на такси в Нью-Йорке (NYC), вероятно, являются наиболее часто используемым ориентиром в области анализа данных.
5. Регистрация всего в формате JSON
 Регистрация и мониторинг подобны Тони Старку и его костюму Железного человека, они будут идти вместе. Точно так же ведение журнала и мониторинг лучше всего работают вместе, поскольку они хорошо дополняют друг друга.
Регистрация и мониторинг подобны Тони Старку и его костюму Железного человека, они будут идти вместе. Точно так же ведение журнала и мониторинг лучше всего работают вместе, поскольку они хорошо дополняют друг друга.
6. Очередь недоставленных сообщений без эластичного стека

7. Анализ 110 миллионов комментариев от Hacker News
 В этой статье мы рассмотрим еще один тест с 1,1 миллионом комментариев, отобранных Hacker News, с числовыми полями
В этой статье мы рассмотрим еще один тест с 1,1 миллионом комментариев, отобранных Hacker News, с числовыми полями
8. Создание системы поиска сходства k-NN с использованием Amazon Elasticsearch и SageMaker
 Amazon Elasticsearch Service недавно добавила поддержку поиска k ближайших соседей. Он позволяет выполнять крупномасштабный поиск k-NN с малой задержкой в тысячах измерений с той же легкостью, что и любой обычный запрос Elasticsearch.
Amazon Elasticsearch Service недавно добавила поддержку поиска k ближайших соседей. Он позволяет выполнять крупномасштабный поиск k-NN с малой задержкой в тысячах измерений с той же легкостью, что и любой обычный запрос Elasticsearch.
9. Jaeger Persistent Storage с Elasticsearch, Cassandra и Kafka

10. Как развернуть & Мониторинг Honeypots на GCP с помощью Kibana [учебник]
 Одна из моих любимых областей кибербезопасности — SIEM (Security Incident Event Management). В 2017 году я написал пост о том, как я получил роль в области кибербезопасности. Одной из моих рекомендаций было использование Elastic Stack в качестве SIEM в качестве отправной точки для тех, кто хочет понять анализ журналов и способы расследования инцидентов. Но одной из главных проблем, с которыми люди сталкивались, было то, где они могут получить данные для работы в своей домашней среде. Этот пост будет посвящен настройке приманки, которая уже использует стек ELK…
Одна из моих любимых областей кибербезопасности — SIEM (Security Incident Event Management). В 2017 году я написал пост о том, как я получил роль в области кибербезопасности. Одной из моих рекомендаций было использование Elastic Stack в качестве SIEM в качестве отправной точки для тех, кто хочет понять анализ журналов и способы расследования инцидентов. Но одной из главных проблем, с которыми люди сталкивались, было то, где они могут получить данные для работы в своей домашней среде. Этот пост будет посвящен настройке приманки, которая уже использует стек ELK…
11. Использование Jest для имитации Elasticsearch
 Протестируйте свои эластичные запросы как профессионал с помощью шутки!
Протестируйте свои эластичные запросы как профессионал с помощью шутки!
12. Пользовательский TraceID в Elastic APM
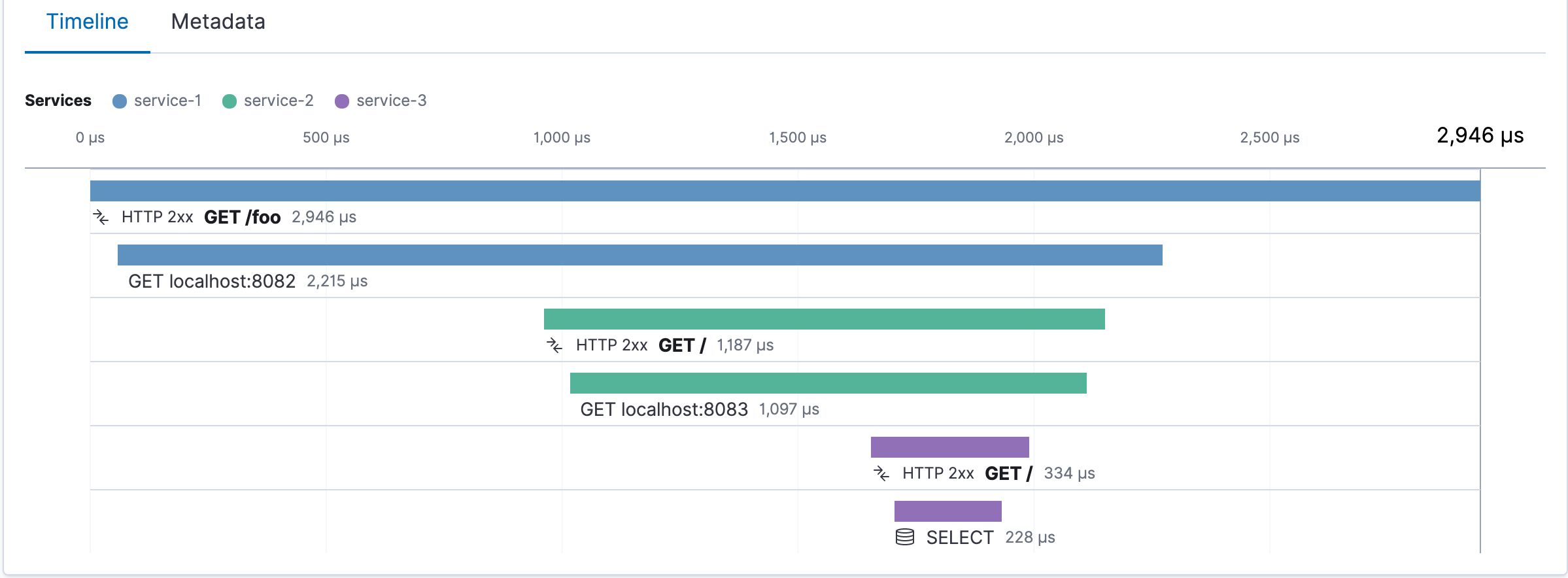
Эта статья призвана помочь или, по крайней мере, упростить отслеживание жизненного цикла HTTP-запроса после инструментирования. Golang используется в этой статье для фрагментов кода, но эту концепцию можно распространить и на другие языки.
13. 101 на ElastAlert & Как настроить
 Простая платформа для оповещения об аномалиях, всплесках и других закономерностях на основе данных в elasticsearch.
Простая платформа для оповещения об аномалиях, всплесках и других закономерностях на основе данных в elasticsearch.
14. Введение в PGSync: инструмент интеграции в реальном времени для PostgreSQL и Elasticsearch

15. Manticore — более быстрая альтернатива Elasticsearch на C++
 Manticore Search — это более быстрая альтернатива Elasticsearch, написанная на C++ с 21-летней историей
Manticore Search — это более быстрая альтернатива Elasticsearch, написанная на C++ с 21-летней историей
16. Графана Против. Кибана Против. Ноуи: Королевская битва 2020
 Введение: Графана, Кибана и Ноуи
Введение: Графана, Кибана и Ноуи
17. Как использовать нечеткие совпадения запросов в Elasticsearch
 Опечатки случаются часто и могут ухудшить работу пользователя. К счастью, Elasticsearch легко справляется с ними с помощью Fuzzy Query.
Опечатки случаются часто и могут ухудшить работу пользователя. К счастью, Elasticsearch легко справляется с ними с помощью Fuzzy Query.
18. Конфигурация GitHub Actions CI для MySQL, Redis, Elasticsearch в проекте Ruby on Rails с тестами RSpec
 Как запускать параллельные тесты с заданиями Github Actions для проекта Rails с MySQL, Redis, Elasticsearch.
Как запускать параллельные тесты с заданиями Github Actions для проекта Rails с MySQL, Redis, Elasticsearch.
19. Как создать простое поле автозаполнения и связать его с Elasticsearch

20. Как перколяция запросов в Elasticsearch упрощает оповещение
 Когда-то у компании, в которой я работал, возникла проблема: через наш конвейер данных каждую секунду проходили тысячи сообщений, и мы хотели иметь возможность отправлять оповещения по электронной почте и SMS нашим пользователям, когда были замечены сообщения, соответствующие определенным критериям.
Когда-то у компании, в которой я работал, возникла проблема: через наш конвейер данных каждую секунду проходили тысячи сообщений, и мы хотели иметь возможность отправлять оповещения по электронной почте и SMS нашим пользователям, когда были замечены сообщения, соответствующие определенным критериям.
21. Анализатор в Elasticsearch: введение

22. Изучение малоизвестных функций Postgres
 Postgres обрабатывает больше, чем вы думаете
Postgres обрабатывает больше, чем вы думаете
23. Создайте приложение для поиска с полным автозаполнением с помощью Elasticsearch, Kibana, NestJS и React
 В этой статье я расскажу вам, как настроить elasticsearch на вашем ПК.
В этой статье я расскажу вам, как настроить elasticsearch на вашем ПК.
24. Использование модуля моментальных снимков Elasticsearch для резервного копирования данных в хранилище BLOB-объектов Azure
 При работе с самоуправляемым кластером elasticsearch, как и с любой другой базой данных, важно предусмотреть резервное копирование данных. Резервное копирование данных в Elasticsearch невозможно выполнить, просто скопировав файлы данных elasticsearch с одного диска на другой. В этом руководстве вы узнаете, как наилучшим образом использовать модуль моментальных снимков Elasticsearch для создания моментальных снимков кластера, а также использовать хранилище BLOB-объектов Azure для безопасного хранения ваших резервных копий. данные. Кроме того, помимо резервного копирования данных, API моментальных снимков также пригодится для переноса данных из одного кластера в другой.
При работе с самоуправляемым кластером elasticsearch, как и с любой другой базой данных, важно предусмотреть резервное копирование данных. Резервное копирование данных в Elasticsearch невозможно выполнить, просто скопировав файлы данных elasticsearch с одного диска на другой. В этом руководстве вы узнаете, как наилучшим образом использовать модуль моментальных снимков Elasticsearch для создания моментальных снимков кластера, а также использовать хранилище BLOB-объектов Azure для безопасного хранения ваших резервных копий. данные. Кроме того, помимо резервного копирования данных, API моментальных снимков также пригодится для переноса данных из одного кластера в другой.
25. Использование KSQL Stream Processing & Базы данных в реальном времени для анализа данных потоковой передачи Kafka [Практическое руководство]
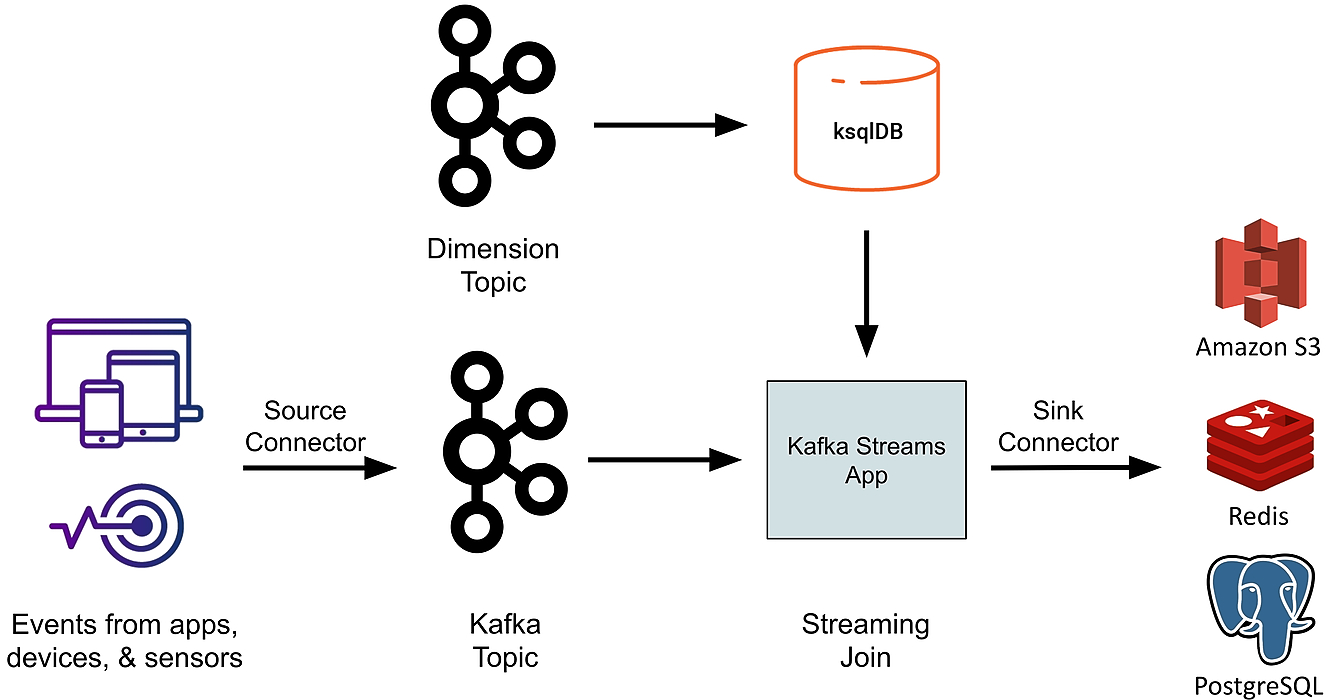 Введение
Введение
26. Как освоить DSL запросов Elasticsearch
 Фото Евгения Черкасского на Unsplash
Фото Евгения Черкасского на Unsplash
27. Как разработать собственную реализацию автозамены с помощью Manticore [Пошаговое руководство]
 В этом тексте я объясню, что такое коррекция орфографии в области функциональности поиска, как она работает в Google, Amazon и Pinterest, и покажу, как реализовать собственную реализацию с нуля с помощью пользовательской поисковой системы Manticore Search.
В этом тексте я объясню, что такое коррекция орфографии в области функциональности поиска, как она работает в Google, Amazon и Pinterest, и покажу, как реализовать собственную реализацию с нуля с помощью пользовательской поисковой системы Manticore Search.
28. Встроенная аналитика в Elasticsearch с Knowi

29. Графические базы данных: полный подробный обзор

30. Централизованное ведение журнала Docker со стеком ELK [ОБЪЯСНЕНИЕ]

31. Быть актуальным или не быть: история поиска о точности и отзыве

32. Elasticsearch в Java Spring Boot: стартовый пакет
 В этой статье я хочу научить вас, как подключить Java Spring Boot 2 к Elasticsearch. Мы узнаем, как создать API, который будет вызывать Elasticsearch для производства
В этой статье я хочу научить вас, как подключить Java Spring Boot 2 к Elasticsearch. Мы узнаем, как создать API, который будет вызывать Elasticsearch для производства
33. Объединение журналов с помощью Elasticsearch, Kibana, Logstash & Докер
 Улучшите ведение журналов в своей архитектуре микросервисов, чтобы упростить отслеживание с помощью ELK Stack.
Улучшите ведение журналов в своей архитектуре микросервисов, чтобы упростить отслеживание с помощью ELK Stack.
34. Давайте экспортируем журналы Cloudwatch в ELK
35. Выделение в результатах поиска
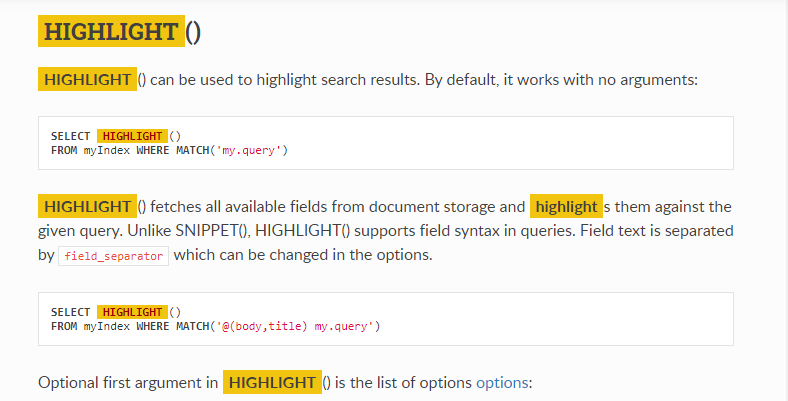 В этом уроке вы узнаете, как выделить результаты поиска в Manticore Search. Вы можете извлечь выгоду из выделения результатов поиска, если хотите улучшить читаемость результатов поиска в своем приложении или на веб-сайте.
В этом уроке вы узнаете, как выделить результаты поиска в Manticore Search. Вы можете извлечь выгоду из выделения результатов поиска, если хотите улучшить читаемость результатов поиска в своем приложении или на веб-сайте.
36. Первые шаги с оператором Kubernetes
 В этой статье показано, как использовать диспетчер жизненного цикла оператора для развертывания оператора Kubernetes в кластере. Затем вы будете использовать Operator для запуска кластера Elastic Cloud on Kubernetes (ECK).
В этой статье показано, как использовать диспетчер жизненного цикла оператора для развертывания оператора Kubernetes в кластере. Затем вы будете использовать Operator для запуска кластера Elastic Cloud on Kubernetes (ECK).
37. Спустя 3 года после разветвления Sphinx: краткий отчет о поиске Manticore
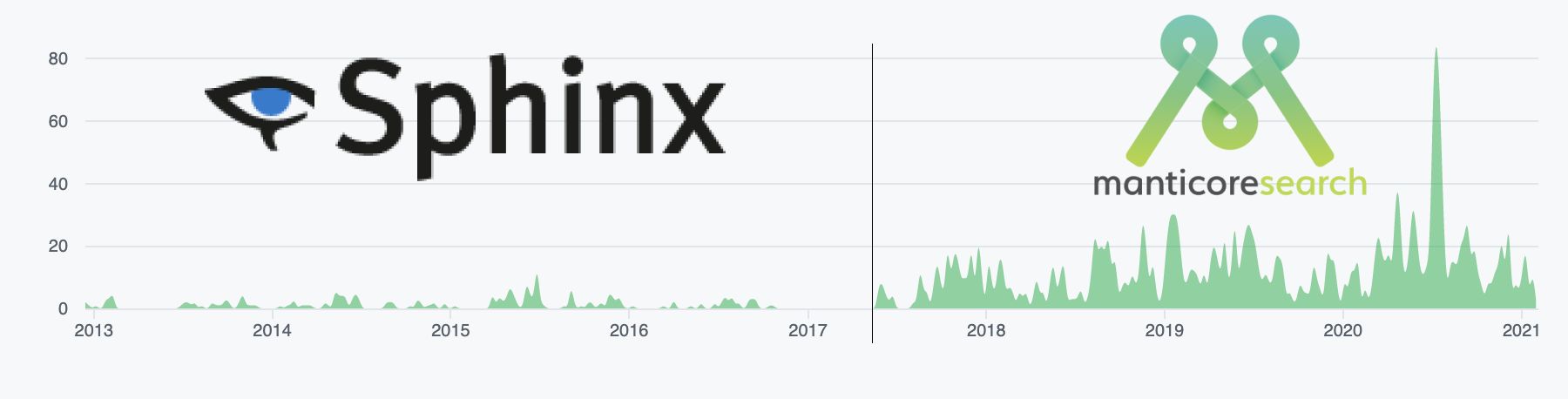 В мае 2017 года мы сделали форк Sphinxsearch 2.3.2, который назвали Manticore Search. Ниже вы найдете краткий отчет о Manticore Search как форке Sphinx и о наших достижениях с тех пор.
В мае 2017 года мы сделали форк Sphinxsearch 2.3.2, который назвали Manticore Search. Ниже вы найдете краткий отчет о Manticore Search как форке Sphinx и о наших достижениях с тех пор.
38. Введение в Elasticsearch: молниеносные решения для поиска

39. Быть актуальным или не быть: история поиска о точности и отзыве

40. Основы полнотекстовых операторов и базового поиска
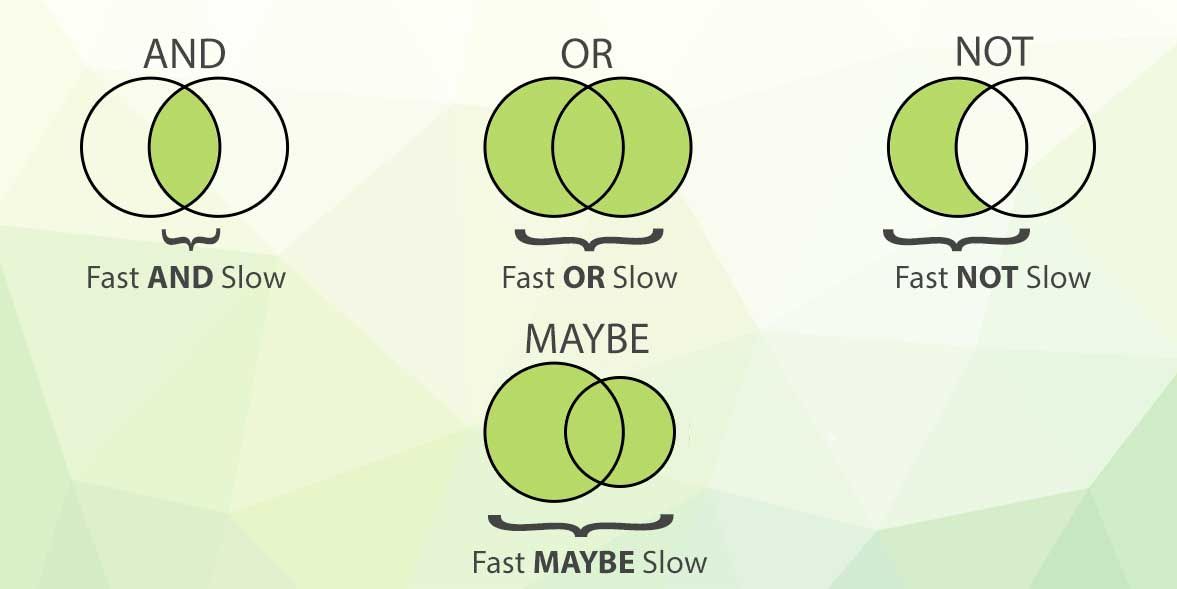
Спасибо, что ознакомились с 40 самыми читаемыми статьями об Elasticsearch на HackerNoon.
Посетите /Learn Repo, чтобы найти самые читаемые истории о любой технологии.