

100 дней искусственного интеллекта, день 11: Станьте мастером тонкой настройки приложений Gen AI
27 февраля 2024 г.:::совет Привет всем! Я Меня зовут Натарадж,, и я, как и вы, очарован недавним прогрессом в области искусственного интеллекта. Понимая, что мне нужно быть в курсе всех происходящих событий, я решил начать личный путь обучения, таким образом 100 дней искусственного интеллекта родились! В этой серии я буду узнавать о LLM и делиться идеями, экспериментами, мнениями, тенденциями и технологиями. обучение через мои сообщения в блоге. Вы можете следить за этим путешествием на HackerNoon здесь или мой личный сайт здесь <эм>. В сегодняшней статье мы попытаемся создать семантическое ядро с помощью GPT-4.
:::
Если вы следили за генеративным искусственным интеллектом или сферой LLM, вы наверняка уже слышали о Finetuning. В этом посте давайте попытаемся понять, что такое тонкая настройка и какова ее роль в разработке приложений искусственного интеллекта.
Что такое точная настройка?
Точная настройка – это процесс изменения базовой модели общего назначения, чтобы она работала для специализированного варианта использования. Например, возьмем модель gpt-3 от Open AI. Gpt-3 — это базовая модель, которая была доработана для использования в качестве чат-бота, в результате чего появилось то, что люди теперь называют приложением Chat-GPT. Другим примером может быть изменение модели GPT-4, чтобы она стала вторым пилотным проектом для программистов, что было сделано для создания второго пилотного проекта GitHub.
Почему нам необходимо настраивать базовые модели?
Точная настройка позволяет преодолеть ограничения базовых моделей. Базовые модели, такие как gpt-3 от Open AI или Llama от Meta, обычно обучаются на всех данных из Интернета. Но у них нет внутреннего контекста данных вашей организации. А предоставить все данные, имеющие отношение к вашей организации или собственному варианту использования, через подсказку невозможно. Точная настройка позволяет нам вместить гораздо больше данных, чем позволяет оперативное проектирование. Точная настройка также позволяет модели генерировать согласованные выходные данные, уменьшать галлюцинации и повышать качество изображения. настроить модель для конкретного варианта использования.
Чем тонкая настройка отличается от оперативного проектирования?
Мы увидели, насколько мощным может быть быстрое проектирование, в предыдущих публикациях. Так чем же отличается тонкая настройка? Точная настройка предназначена для случаев использования корпоративных приложений, а оперативное проектирование предназначено для общих случаев использования и не требует данных. Его можно использовать с дополнительными данными с помощью RAG в качестве метода, но его нельзя использовать с большими данными, которые существуют в корпоративных сценариях использования. Точная настройка позволяет использовать неограниченное количество данных, заставляет модель изучать новую информацию, ее также можно использовать вместе с RAG.

Сравнение ответа с точной настройкой и без точной настройки
Давайте рассмотрим пример, который поможет вам лучше понять разницу между моделями с точной настройкой и моделями без точной настройки. Я использую библиотеки Lamini для вызова как точно настроенных, так и неточно настроенных моделей Llama, чтобы показать разницу. Для этой цели вам понадобится ключ API от Lamini. Lamini предоставляет простой и легкий способ взаимодействия с LLM с открытым исходным кодом. Если хотите узнать об этом больше, посмотрите здесь.
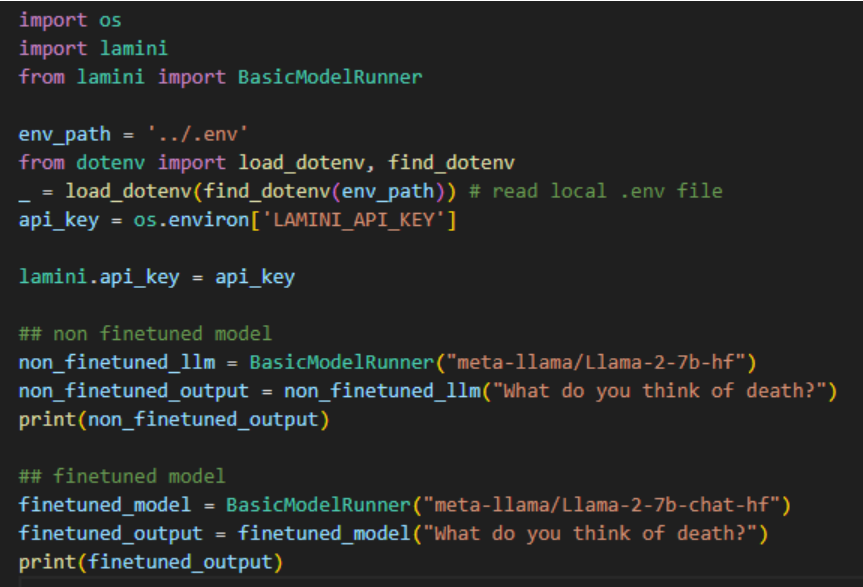
В этом примере я задал обеим моделям один и тот же вопрос: «Что вы думаете о смерти?» и вот ответы.
Ответ от модели ламы без точной настройки:
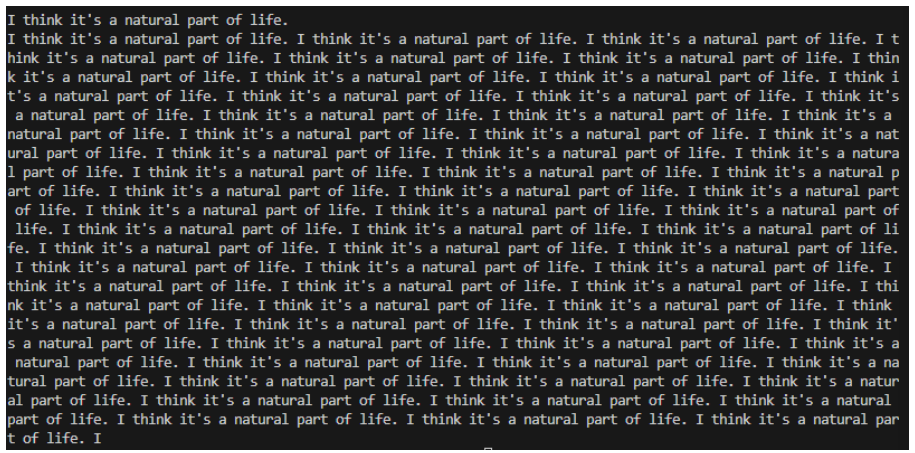
Ответ точно настроенной модели ламы:

Вы заметите, что первый ответ представлял собой просто повторение одной строки, тогда как второй ответ был гораздо более связным. Прежде чем говорить о том, что здесь происходит, давайте возьмем еще один пример, когда я спрашиваю модель: «Как вас зовут?». Вот что у меня получилось.
Ответ от модели ламы без точной настройки:
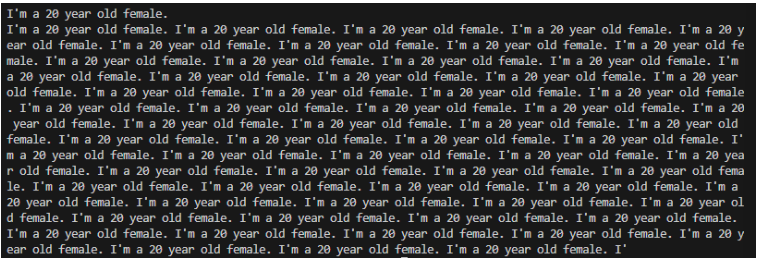
Ответ точно настроенной модели ламы:

В ответах модели без точной настройки ответы странные, потому что модель делает только одно. Он пытается предсказать следующий вероятный текст на основе введенного вами текста, но при этом не осознает, что вы задали ему вопрос. Модели, обученные на данных Интернета, представляют собой машины для прогнозирования текста и пытаются предсказать следующий лучший текст. При точной настройке модель обучается основывать свой ответ, предоставляя дополнительные данные, и изучает новое поведение, которое должно действовать как чат-бот, предназначенный для ответа на вопросы. Также обратите внимание, что о большинстве закрытых моделей, таких как gpt-3 или gpt-4 Open AI, мы точно не знаем, на каких данных они обучаются. Но есть несколько интересных наборов открытых данных, которые можно использовать для обучения ваших моделей. Подробнее об этом позже.
Вот и закончился день 11 из 100 дней искусственного интеллекта.
Я пишу информационный бюллетень под названием «Выше среднего», в котором рассказываю об идеях второго порядка, стоящих за всем, что происходит в больших технологиях. Если вы разбираетесь в технологиях и не хотите быть средним, подпишитесь на нее.
Следуйте за мной в Twitter, LinkedIn или HackerNoon для получения последних обновлений о 100 днях ИИ. Если вы работаете в сфере технологий, возможно, вам будет интересно присоединиться к моему сообществу технических специалистов здесь< /strong>.
Оригинал
🔥 Популярное на этой неделе
-
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27430)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)