

Почему вы должны определить стандартную структуру при сборе веб-данных с веб-сайтов электронной коммерции
1 апреля 2023 г.Сбор веб-данных с веб-сайтов электронной коммерции очень распространен. Хотя каждый веб-сайт имеет свою собственную информацию, отображаемую в различных частях пользовательского интерфейса (страница со списком продуктов, страница с подробной информацией о продуктах, корзина и т. д.), чрезвычайно полезно определить стандартную структуру.
Преимущества стандартного подхода
Преимущества принятия стандартной структуры огромны, когда нам нужна координация между несколькими извлечениями с разных веб-сайтов или, вообще говоря, создание гибкой временной шкалы извлечения данных, которая остается неизменной для всех возможных изменений, которые даже один веб-сайт может иметь с течением времени. .
Мы хотим иметь возможность отделить извлечение данных от получения в базе данных или хранилище данных.
В databoutique.com мы провели несколько итераций идеальной структуры данных для сбора информации с веб-сайтов и пришли к следующим выводам (не стесняйтесь комментировать или, что еще лучше, присоединяйтесь к нашему обсуждению на Разногласия по этому поводу):
- Структуры данных должны быть стандартизированы в рамках определенной отрасли (скажем, моды, фармацевтики, продуктов питания, электроники).
- Структуры данных должны быть специфическими (или разными) в одних и тех же отраслях.
- Могут быть разные структуры в зависимости от того, на каком уровне собрана информация (страница списка продуктов PLP, страница сведений о продукте PDP или страница корзины). Этот пункт связан со стоимостью доступа к различным частям веб-сайта.
Дополнительным преимуществом такой организации структур данных является помощь в удовлетворении запроса конечного пользователя за счет прозрачности в отношении того, где он хочет получить информацию, таким образом согласовывая свой запрос с затратами на ее фактическое получение.
Преимущества разделения процессов PLP и PDP (и список полей)
Для доступа к PDP сначала необходимо получить доступ к PLP. Вот почему важно иметь структуру PLP, отличную от структуры PDP.
Предположим, мы хотим ежедневно сканировать товары модного веб-сайта, такого как Zalando.
Хотя часть информации может меняться ежедневно (например, цены на товары или доступность товаров), другие остаются неизменными, например описание и изображение товаров (в этом примере мы не будем учитывать доступность размеров товаров, это будет рассмотрено отдельно).
Мы могли бы ежедневно сканировать все страницы PLP и только один раз PDP каждой страницы продукта, когда нам нужно получить подробную информацию о каждом продукте. Давайте посчитаем и увидим разницу.
Предположения:
- Стоимость с точки зрения пропускной способности и прокси-сервера одинакова для извлечения одного PLP или PDP (фактическая стоимость здесь не имеет значения, нас интересует сравнение)
- Количество продуктов, которые появляются на веб-сайте Zalando в течение года, составляет 1 миллион (даже если этот аспект не имеет значения, но помогает сформулировать ситуацию).
- Среднее количество элементов, содержащихся на одной странице PLP со списком товаров, составляет 80 элементов.
- Заполнено 80% страниц PLP (это означает, что у нас есть 80 элементов почти на каждой странице, на некоторых страницах нет 80 элементов, потому что для этой конкретной категории больше нет элементов для отображения
В случае, если бы мы ежедневно сканировали страницу сведений о продукте (PDP), нам пришлось бы ежедневно получать доступ ко всем страницам PLP со списком продуктов (15 000 страниц = 1 млн элементов/80 элементов на странице/скорость заполнения 80%), чтобы затем пройти на каждую страницу сведений о продукте PDP (1 М), всего 370 Млн страниц (1 М X 365 + 15 000 > 365 страниц) в год.
Если бы мы сканировали PLP ежедневно, а PDP только один раз, нам пришлось бы сканировать только 6 М страниц в год (15 000 X 365 +1 М).
Это в 55 раз (!!) дешевле, или, если вы предпочитаете, если бы стоимость страницы составляла 0,0001 доллара США за страницу, сбор Zalando в течение года через страницу PLP стоил бы 6,7 тысяч долларов США в год по сравнению с 370 тысячами долларов США в год с ежедневным PDP. подход.
И это очень важно передать конечному пользователю, поэтому понятно, что если он или он хочет ежедневно обновлять информацию, которая доступна только на странице PDP, стоимость только данных будет в 50 раз выше.
Категории страниц списка товаров
Страницу со списком продуктов в разных версиях, с которыми мы сталкивались, можно разделить на следующие категории:
- Категоризированные списки: товары представлены в определенном дереве категорий, которое может быть либо стабильным, либо динамическим (но об этом мы поговорим позже). Хорошим примером являются отраслевые веб-сайты, такие как магазины модной одежды, магазины электроники и т. д., где веб-сайт каким-то образом помогает пользователю найти то, что он или она ищет, но пока не знает точного продукта.
Nike.com является хорошим примером для этого: магазин направляет нас к нашему опыту покупок через категории, чтобы показать продукты, которые находятся в нашей области интересов. Конечно, мы можем использовать панель поиска, но это второстепенно с точки зрения UX, как видно из расположения самой панели поиска.
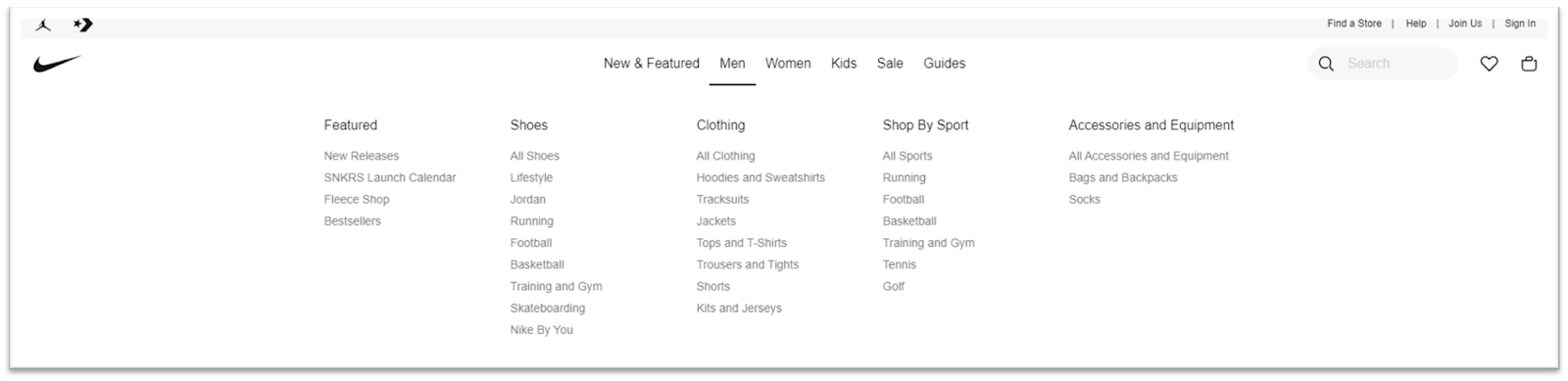
- Списки без категорий: товары отображаются не для поиска по категориям, а для поиска по сайту.
Amazon является хорошим примером этого. Несмотря на наличие дерева категорий, основной UX происходит через панель поиска.
Сейчас мы рассмотрим категоризированные списки и помните, что нам нужна структура, которая будет сканировать PLP, а не переходить на страницу сведений о продукте (PDP).
Это особенно полезно на крупных веб-сайтах, на которых представлено около миллиона продуктов или больше, где количество просканированных страниц различается на несколько порядков между PLP и PDP.
Стандартный список полей PLP
Теперь о структуре данных. Золотого стандарта не существует, наши решения исходили из сравнительного анализа многих веб-сайтов электронной коммерции и определения наилучшей общей структуры для всех из них.
у нас есть разные группы информации, которая нам нужна:
-
техническая информация
-
версия структуры поля
- веб-сайт, который мы захватываем
-
отметка времени или дата сбора информации
2. контекстная информация
-
к какой стране/географии относится приобретение
-
в какой валюте указаны цены
3. содержание
-
уровень категории 1
- уровень категории 2
- уровень категории 3
- торговая марка
- код продукта
- название продукта
- полная цена
-
цена со скидкой
4. поля ссылок
-
изображение
-
URL-адрес PDP
Примечание: не все веб-сайты будут иметь три уровня категорий, а в некоторых случаях не все ветви дерева категорий будут иметь полную длину. В обоих случаях мы принимаем «n.a.» как недоступные в полях.
Для веб-сайтов с ветками с более чем тремя уровнями (но не более 4 или 5) мы принимаем объединение последних уровней в уровень категории 3.
В версии Data Boutique мы используем дополнительные поля, связанные с нашей бизнес-моделью. Проверьте полную версию этого списка полей для будущих обновлений.
:::информация Также опубликовано здесь.
:::
Оригинал
🔥 Популярное на этой неделе
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27683)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)