В прошлом месяце я писал о модульных монолитах и ценности современной монолитной архитектуры. Одно из наиболее интересных обсуждений, вытекающих из этого поста (и видео), — это обратное обсуждение: когда право по-прежнему выбирать микросервисы?
Как и любой выбор дизайна, ответ субъективен и зависит от многих вещей. Но есть еще общие практические правила и глобальные показатели, которые мы можем использовать. Прежде чем мы перейдем к этим проблемам, нам нужно понять, что значит иметь микросервисную архитектуру. Тогда мы сможем оценить преимущества и цену такой архитектуры.
https://www.youtube.com/watch?v=PrFZB9NqZ5E&embedable=true
Маленькие монолиты
Распространенное заблуждение состоит в том, что микросервисы — это просто разбитые монолиты. Это не так. Я разговаривал со многими людьми, которые до сих пор придерживаются этого мнения, и, честно говоря, они могут быть правы. Вот как AWS определяет микросервисы:
<цитата>Микрослужбы — это архитектурный и организационный подход к разработке программного обеспечения, при котором программное обеспечение состоит из небольших независимых служб, взаимодействующих через четко определенные API. Эти сервисы принадлежат небольшим автономным командам.
Архитектуры микросервисов упрощают масштабирование и ускоряют разработку приложений, что позволяет внедрять инновации и ускорять вывод новых функций на рынок.
Меньшие монолиты могут подходить под определение, но это не так, если читать между строк. Слова «независимый» и «легко масштабируемый» намекают на проблему. Проблема (и преимущество) монолита — единая точка отказа. Имея один сервис, мы обычно можем легче найти проблемы. Архитектура намного проще.
Если мы разобьем эту службу на более мелкие части, мы, по сути, создадим распределенные точки отказа. Если один элемент в цепочке выйдет из строя, вся архитектура выйдет из строя. Это не является независимым, и его не легче масштабировать. Микросервисы — это НЕ маленькие монолиты, а разрушение монолита — это не только работа с небольшими проектами. Речь идет об изменении методов работы.
Что такое микросервис?
Хорошая микрослужба должна следовать следующим принципам надежности и масштабируемости:
* Разделение по бизнес-функциям — это логическое разделение. Микросервис — это отдельный «продукт», который предоставляет полный пакет. Это означает, что команда, отвечающая за микросервис, может вносить все изменения, необходимые для бизнеса, без зависимостей. * Автоматизация с помощью CI/CD — без непрерывной поставки стоимость обновления сведет на нет все преимущества микросервисов. * Независимое развертывание — подразумевается, поскольку фиксация на одном микросервисе вызовет CD только этого конкретного сервиса. Мы можем добиться этого с помощью решений Kubernetes и Infrastructure as Code (IaC). * Инкапсуляция — она должна скрывать основные детали реализации. Служба действует как автономный продукт, который публикует API для других продуктов. Мы обычно добивались этого с помощью интерфейсов REST, а также промежуточного программного обеспечения для обмена сообщениями. Это дополнительно улучшено с помощью шлюзов API. * Децентрализовано без единой точки отказа — в противном случае мы бы распределили отказ. * Сбои должны быть изолированы — без этого выход из строя одного сервиса может создать эффект домино. Автоматические выключатели, вероятно, являются наиболее важными инструментами для изоляции сбоев. Чтобы удовлетворить эту зависимость, каждый микросервис обрабатывает свои собственные данные. Это означает, что многие базы данных могут быть сложными время от времени. * Наблюдаемый — требуется для устранения сбоев в масштабе. Без надлежащего наблюдения мы фактически слепы, поскольку различные команды могут развертываться автоматически.
Все это хорошо, но что это значит на практике?
В основном это означает, что нам нужно внести несколько больших изменений в то, как мы обращаемся с большими идеями. Нам нужно передать большую часть сложности команде DevOps. Нам нужно по-разному обрабатывать состояние транзакций между микросервисами. Это одна из самых сложных концепций при работе с микросервисами.
В идеальном мире все наши операции будут простыми и содержаться в небольшом микросервисе. Структура сервисной сетки, окружающая наши микросервисы, будет решать все глобальные сложности и управлять нашими отдельными сервисами вместо нас. Но это не реальный мир. На самом деле наши микросервисы могут иметь транзакционное состояние, которое переносится между сервисами. Внешние службы могут дать сбой, и для этого нам нужно использовать несколько уникальных подходов.
Опирайтесь на команду DevOps
Если в вашей компании нет хороших команд DevOps и разработки платформ, микросервисы вам не подходят. Вместо развертывания одного приложения мы можем развернуть сотни из-за миграции. Хотя отдельные развертывания просты и автоматизированы, вам все равно придется много работать на операциях.
Когда что-то не работает или не подключается. Когда необходимо интегрировать новую услугу или принять конфигурацию службы. Операции несут большую нагрузку при работе с микросервисами. Это требует большого общения и сотрудничества. Это также означает, что команда, управляющая конкретной службой, должна взять на себя часть бремени OPS. Это непростая задача.
Как разработчики, мы должны знать многие инструменты, используемые для связывания наших отдельных сервисов с единым унифицированным сервисом:
* Service Mesh позволяет нам комбинировать отдельные сервисы и эффективно действует как балансировщик нагрузки между ними. Он также обеспечивает безопасность, авторизацию, контроль трафика и многое другое. * Вместо прямого вызова API следует использовать шлюзы API. Иногда это может быть неловко, но часто необходимо, чтобы избежать затрат, предотвратить ограничение скорости и многое другое. * Флаги функций и усилители; Секреты полезны и в монолите. Но ими невозможно управлять в масштабе микросервиса без специальных инструментов. * Circuit Breaking позволяет нам отключить разорванное соединение с веб-сервисом и изящно восстановить его. Без этого один сломанный сервис может вывести из строя всю систему. * Управление идентификацией должно быть отдельным. Вы не можете обойтись без таблицы аутентификации в базе данных при работе со средой Microservice.
Я пропущу оркестровку, CI/CD и т. д., но их тоже нужно адаптировать для каждого нового сервиса. Некоторые из этих инструментов непонятны разработчикам, но нам нужна помощь DevOps на всех этапах.
Шаблон саги
Службы без сохранения состояния были бы идеальными, поскольку наличие состояния делает все гораздо сложнее. Если мы сохранили состояние в клиенте, нам нужно постоянно отправлять его туда и обратно. Если он находится на сервере, нам нужно будет либо постоянно его извлекать, либо кэшировать, либо сохранять локально, а затем все взаимодействие будет выполняться с текущей системой. Это исключает масштабируемость системы.
Типичный микросервис будет хранить в собственной базе данных и работать с локальными данными. Служба, которой требуется удаленная информация, обычно кэширует некоторые данные, чтобы избежать обращения к другой службе. Это одна из главных причин, по которой микросервисы могут масштабироваться. В Monolith база данных должна стать узким местом приложения, что означает, что Monolith эффективен и ограничен скоростью, которую мы можем хранить и извлекать данные. У этого есть два основных недостатка:
* Размер — чем больше у нас данных, тем больше база данных, а производительность влияет на всех пользователей одновременно. Представьте, что вы запрашиваете таблицу SQL для каждой покупки, когда-либо сделанной на Amazon, только для того, чтобы найти вашу конкретную покупку. * Домен — базы данных имеют разные варианты использования. Некоторые базы данных оптимизированы для согласованности, скорости записи, скорости чтения, временных данных, пространственных данных и многого другого. Микросервис, который отслеживает информацию о пользователях, вероятно, будет использовать базу данных временных рядов, оптимизированную для информации, связанной со временем, в то время как сервис покупки сосредоточится на традиционной консервативной базе данных ACID.
Обратите внимание, что Monolith может использовать более одной базы данных. Это может работать отлично и может быть очень полезным. Но это исключение. Не правило.
Шаблон саги работает с использованием компенсирующих транзакций для отмены эффектов саги в случае сбоя. При сбое саги выполняется компенсирующая транзакция, чтобы отменить изменения, сделанные предыдущей транзакцией. Это позволяет системе восстанавливаться после сбоев и поддерживать согласованное состояние.
Мы можем добиться этого с помощью таких инструментов, как Apache Camel, но это нетривиально и требует гораздо большего участия, чем обычная транзакция в современной системе. Это означает, что для каждой крупной межсервисной операции вам потребуется выполнить эквивалентную операцию отмены, которая восстановит состояние обратно. Это нетривиально. Есть несколько инструментов для оркестровки саги, но это большая тема, выходящая за рамки этого поста, но я все же объясню ее в общих чертах.
Что важно понимать о Saga, так это то, что она избегает классических принципов базы данных ACID и фокусируется на «консистентности в конечном итоге». Это означает, что в какой-то момент операции приведут базу данных в согласованное состояние. Это очень трудный процесс. Представьте себе отладку проблемы, которая возникает только тогда, когда система находится в несогласованном состоянии…
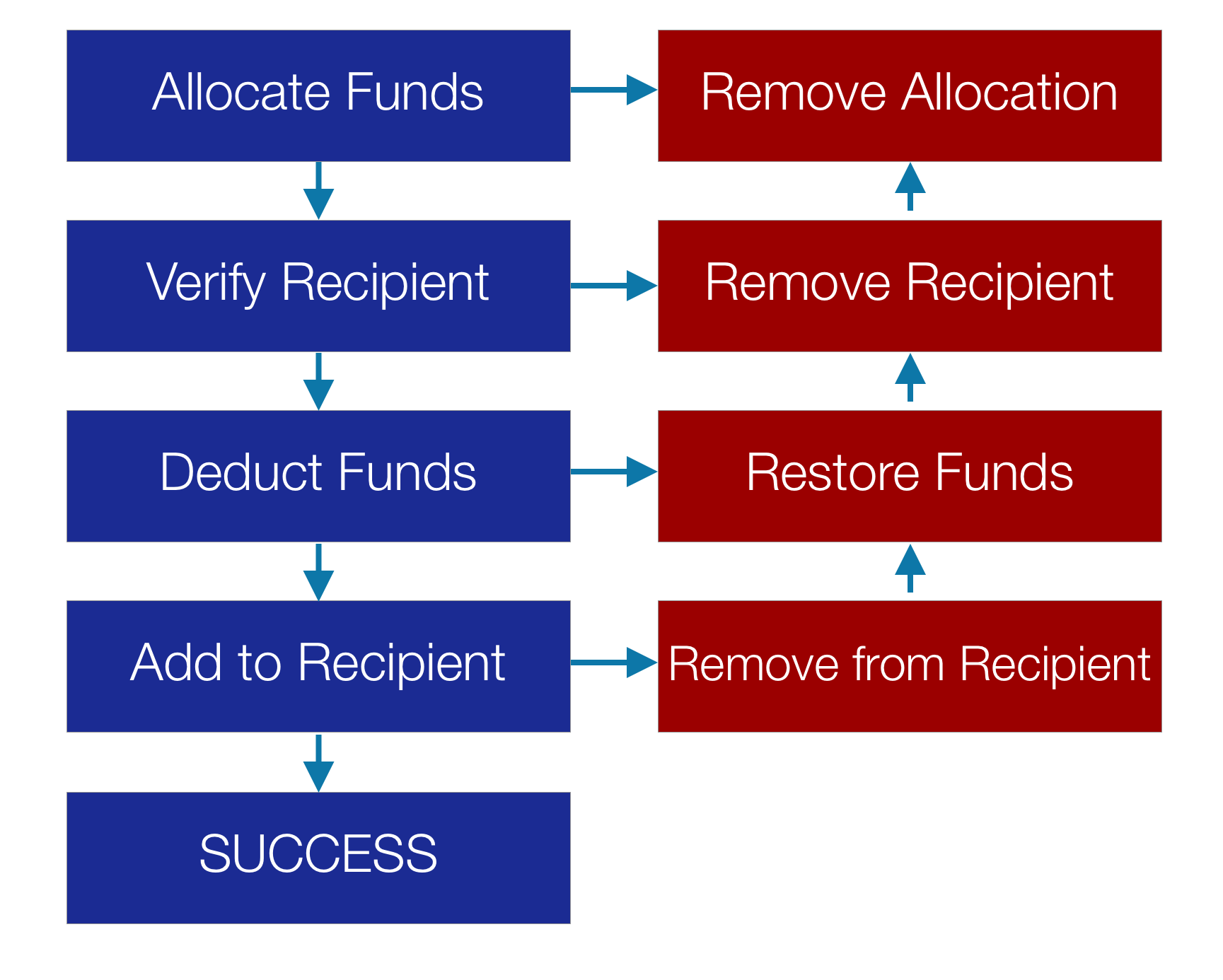
Следующее изображение продемонстрировало эту идею в общих чертах. Допустим, у нас есть процесс перевода денег.
* Для денежного перевода нам необходимо сначала выделить средства. * Затем мы проверяем, что получатель действителен и существует. * Затем нам нужно списать средства с нашего счета. * И, наконец, нам нужно добавить деньги на счет получателя.
Это успешная сделка. В обычной базе данных это будет одна транзакция, и мы можем видеть это в синем столбце слева. Но если что-то пойдет не так, нам нужно запустить обратный процесс.
* Если при выделении средств происходит сбой, нам необходимо удалить выделение. Нам нужно создать отдельный блок кода, который выполняет обратную операцию выделения. * Если проверка получателя не удалась, нам нужно удалить этого получателя. Но тогда нам нужно также удалить выделение. * Если вычесть средства не удается, нам нужно восстановить средства, удалить получателя и удалить распределение. * Наконец, если добавление средств получателю не удается, нам нужно выполнить все операции отмены!
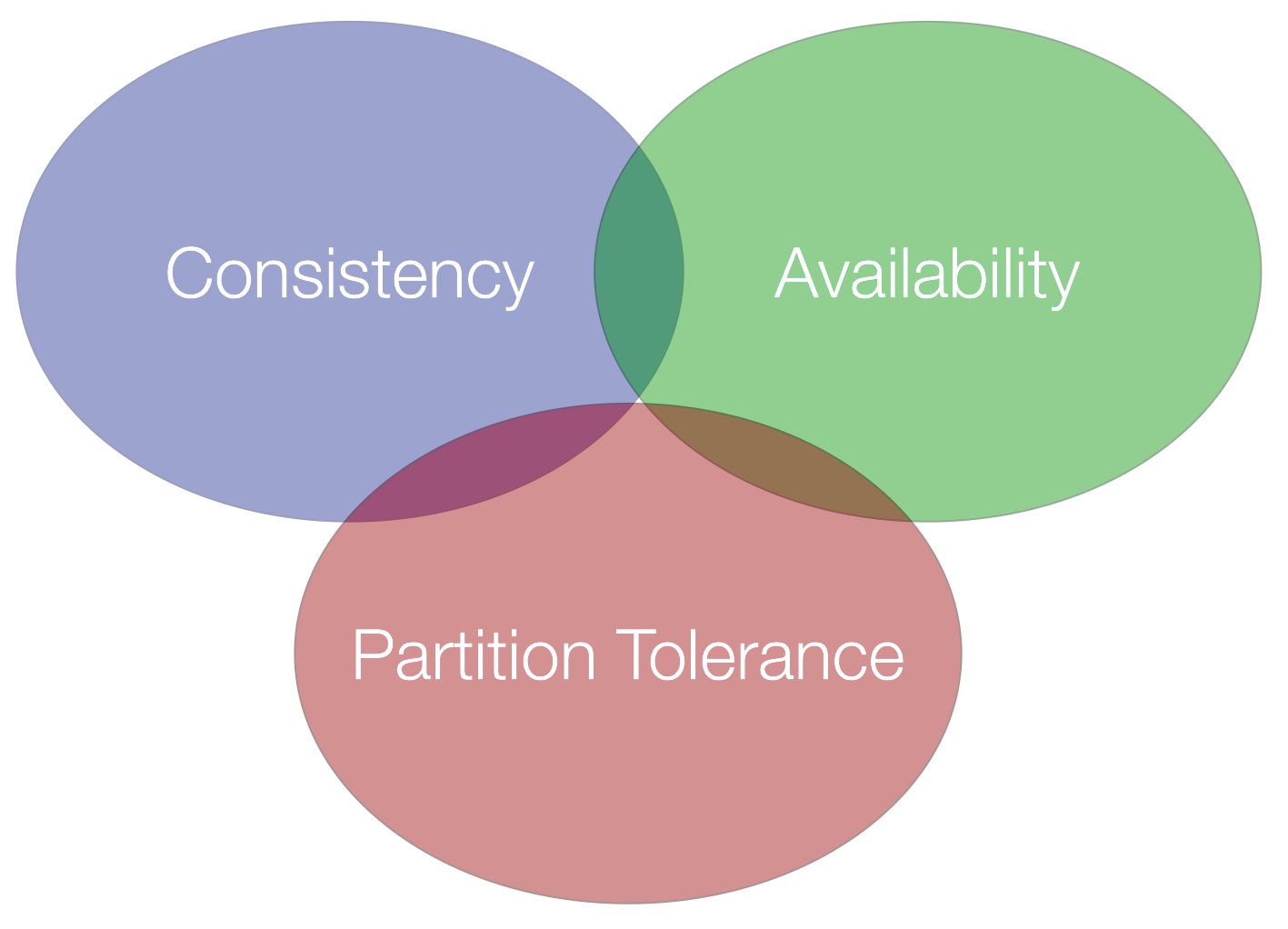
Еще одна проблема в Saga проиллюстрирована теоремой CAP. CAP расшифровывается как Consistency, Availability and Partition Tolerance. Проблема в том, что нам нужно выбрать любые два… Не поймите меня неправильно, у вас могут быть все три. Но в случае сбоя вы можете гарантировать только два.
Доступность означает, что запросы получают ответы. Но нет гарантии, что они содержат самые последние записи.
Согласованность означает, что каждое чтение получает самую последнюю запись об ошибке.
Терпимость означает, что все будет продолжать работать, даже если многие сообщения будут потеряны по пути.
Это сильно отличается от нашего исторического подхода к сбоям в транзакциях.
Должны ли мы выбрать микросервисы?
Надеюсь, теперь вы понимаете, насколько сложно правильно развернуть микросервисы. Нам нужно пойти на большие компромиссы. Этот новый способ не обязательно лучше, в некоторых отношениях он хуже. Но сторонники микросервисов по-прежнему правы: мы можем многого добиться с помощью микросервисов и должны сосредоточиться и на этих преимуществах.
Мы упомянули первое требование заранее: DevOps. Наличие хорошей команды DevOps является необходимым условием для рассмотрения микросервисов. Я видел, как команды пытались справиться с этим без команды OPS, и в итоге они тратили больше времени на операционную сложность, чем на написание кода. Это не стоило усилий.
Самая большая польза от Microservice для команды. Вот почему наличие стабильной команды и масштаба имеет решающее значение. Разделение команд на вертикальные группы, которые работают независимо друг от друга, является огромным преимуществом. Самый модульный монолит в мире не может конкурировать с этим. Когда у нас есть сотни разработчиков, следящих за git-коммитами в одиночку, и отслеживание изменений кода в масштабе становится несостоятельным.
Ценность микросервисов осознается только в большой команде. Это звучит достаточно разумно, но в стартапе все меняется внезапно. Мой коллега работает в стартапе, в котором работают десятки разработчиков. Они решили следовать архитектуре микросервисов и построили их много... Потом пришло сокращение, и поддержка десятков сервисов на нескольких языках стала проблемой.
Разделить монолит сложно, но выполнимо. Объединение микросервисов в монолит, вероятно, сложнее, я не знаю никого, кто серьезно пытался бы это сделать, но было бы любопытно услышать истории.
Не один размер
Чтобы перейти к микросервисной архитектуре, нам нужно немного изменить мышление. Хороший пример — базы данных. Хорошим примером может быть отслеживание пользователей Microservice. В монолите мы записывали данные в таблицу и продолжали свою работу. Но это проблематично…
По мере масштабирования данных эта таблица отслеживания пользователей может в конечном итоге содержать большое количество данных, которые трудно анализировать в режиме реального времени, не влияя на остальную часть операционной системы. С микросервисом мы можем предложить несколько преимуществ:
* Интерфейс к микросервису может использовать обмен сообщениями, что означает, что стоимость отправки информации для отслеживания будет минимальной. * Для отслеживания данных можно использовать базу данных временных рядов, которая будет более эффективной для этого варианта использования. * Мы можем передавать данные и обрабатывать их асинхронно, чтобы извлечь из этих данных дополнительную ценность.
Есть сложности, данные больше не будут локализованы. Поэтому, если мы отправляем данные отслеживания асинхронно, нам нужно отправить все необходимое, поскольку служба отслеживания не сможет вернуться к исходной службе для получения дополнительных метаданных. Но у него есть преимущество, связанное с местоположением: если нормативные положения об отслеживании хранения изменятся, это будет храниться в одном месте.
Динамический контроль и развертывание
Приходилось ли вам когда-нибудь нажимать кнопку для выхода релиза, производство которого прерывалось?
Я делал это не раз (слишком много раз). Это ужасное чувство. Микросервисы по-прежнему могут давать сбои в производственной среде, а также катастрофические сбои, но часто их сбои носят более локальный характер. Их также проще развернуть на определенном подмножестве системы (Canary) и проверить. Все эти политики могут полностью контролироваться людьми, которые действительно держат руку на пульсе пользователя: OPS.
Наблюдаемость для микросервисов важна, дорога, но и более эффективна. Поскольку все происходит на сетевом уровне, все это доступно инструментам наблюдения. SRE или DevOps могут более подробно проанализировать сбой. Это происходит за счет разработчика, которому, возможно, придется столкнуться с повышенной сложностью и ограниченным набором инструментов.
Приложения могут стать слишком большими, чтобы потерпеть неудачу. Даже с учетом модульности некоторые из крупнейших монолитов содержат так много кода, что на выполнение полного цикла CI/CD уходят часы. Затем, если развертывание завершится ошибкой, возврат к последней исправной версии также может занять некоторое время.
Сегментация
Раньше мы делили команды по слоям. Клиент, сервер, БД и т. д. Это имело смысл, поскольку каждый из них требовал уникального набора навыков. Сегодня вертикальные команды имеют больше смысла, но у нас все еще есть особенности.
Как правило, мобильный разработчик не работает над бэкэндом. Но допустим, у нас есть мобильная команда, которая хочет работать с GraphQL вместо REST. С Monolith мы либо говорили им «жить с этим», либо нам приходилось делать всю работу. С помощью микросервисов мы можем создать для них простой сервис с очень небольшим количеством кода. Простой фасад основных услуг. Нам не нужно беспокоиться о том, что мобильная команда будет писать серверный код, так как это будет относительно изолировано. Мы можем сделать то же самое для каждого уровня клиента, это упрощает вертикальную интеграцию команды.
Слишком большой
Трудно указать размер, который делает монолит непрактичным, но вот что вы должны задать себе:
Сколько команд у нас есть или сколько мы хотим?
Если у вас есть пара команд, то монолит, вероятно, будет отличным решением. Если у вас есть дюжина команд, вы можете столкнуться с проблемой там.
Оценивайте запросы на вытягивание и время решения проблем.
По мере роста проекта ваши запросы на вытягивание будут тратить больше времени на ожидание слияния, а решение проблем будет занимать больше времени. Это неизбежно, поскольку сложность проекта имеет тенденцию к росту. Обратите внимание, что новый проект будет иметь более широкие функции, и это может повлиять на результаты, если вы учтете это в статистике проекта, снижение производительности должно быть измеримым.
Обратите внимание, что это одна метрика. Во многих случаях это может указывать на другие вещи, такие как необходимость оптимизации конвейера тестирования, процесса проверки, модульности и т. д.
Есть ли у нас специалисты, знающие код?
В какой-то момент огромный проект становится настолько большим, что специалисты начинают терять детали. Это становится проблемой, когда ошибки становятся несостоятельными и нет авторитетной фигуры, которая может принять решение без консультации.
Удобно ли вам тратить деньги?
Микросервисы будут стоить дороже. Обойти это невозможно. Есть особые случаи, когда мы можем настроить масштаб, но в конечном итоге наблюдаемость и затраты на управление исключат любую потенциальную экономию средств. Поскольку затраты на персонал обычно превышают затраты на облачный хостинг, общая сумма все равно может сыграть в вашу пользу, поскольку эти затраты могут уменьшиться, если масштаб будет достаточно большим.
Компромиссы
Соотношение между монолитом и микросервисом хорошо показано на следующей диаграмме.
Обратите внимание, что эта диаграмма была разработана для большого проекта. Чем меньше проект, тем лучше картинка для Монолита.
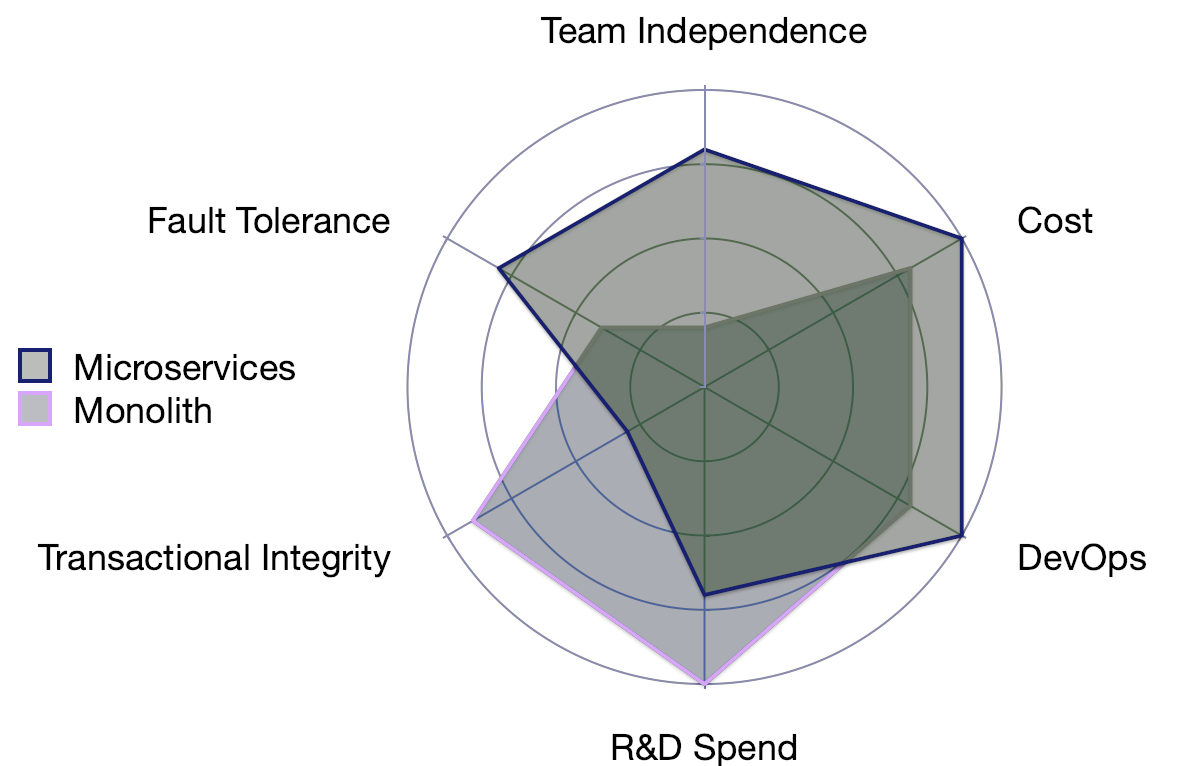
Обратите внимание, что микросервисы обеспечивают преимущество в более крупных проектах в отношении отказоустойчивости и независимости команды. Но они расплачиваются стоимостью. Они могут сократить расходы на НИОКР, но в основном перекладывают их на DevOps, так что это не является большим преимуществом.
Заключительное слово
Сложность микросервисов огромна, и иногда команды разработчиков игнорируют их.
Разработчики используют микросервисы как дубинку, чтобы выбросить части системы, которые они не хотят поддерживать, вместо того, чтобы создавать устойчивую, масштабируемую архитектуру, достойную замены монолита.
Я твердо верю, что проекты должны начинаться с монолита. Микросервисы — это оптимизация для масштабирования команды, а преждевременная оптимизация — корень всех зол. Вопрос в том, когда подходящее время для такой оптимизации?
Есть несколько показателей, которые мы можем использовать, чтобы упростить это решение. В конечном счете, изменение не просто расщепляет монолит. Это означает переосмысление транзакций и основных концепций. Начав с монолита, у нас есть план, который мы можем использовать для согласования нашей новой реализации по мере ее укрепления.
:::информация Также опубликовано здесь.
:::