
Что сообщают 162 Vinted A/B -тесты о ваших показателях конверсии
12 августа 2025 г.Таблица ссылок
Введение
Гипотеза тестирование
2.1 Введение
2.2 Байесовская статистика
2.3 тестируйте мартингингинг
2.4 P-значения
2.5 Дополнительная остановка и взгляды
2.6 Сочетание P-значений и дополнительного продолжения
2.7 А/б -тестирование
Безопасные тесты
3.1 Введение
3.2 Классический T-критерий
3.3 Безопасный T-критерий
3.4 χ2 -Test
3,5 безопасного теста на пропорцию
Безопасное моделирование тестирования
4.1 Введение и 4.2 реализация Python
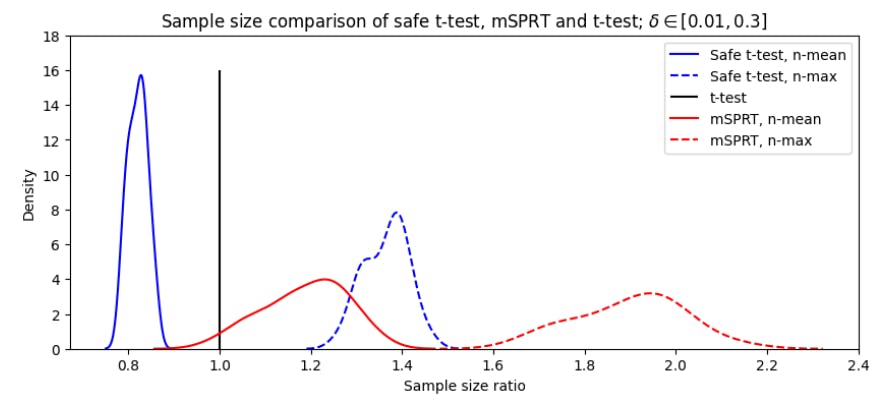
4.3 Сравнение t-теста с безопасным t-тестом
4.4 Сравнение χ2 -теста с тестом на безопасную пропорцию
Смесь последовательного теста вероятности
5.1 Последовательное тестирование
5.2 Смесь SPRT
5.3 MSPRT и безопасный T-критерий
Онлайн -контролируемые эксперименты
6.1 Безопасный t-тест на наборах данных OCE
Vinted A/B-тесты и 7.1 Safe T-критерий для Vinted A/B-тестов
7.2 безопасная пропорция для несоответствия соотношения образца
Заключение и ссылки
7 тестов на A/B.
Vinted - это онлайн -рынок для одежды и аксессуаров. С момента своего создания в 2008 году он приобрел более 75 миллионов пользователей для быстрого развития на крупнейшем в Европе рынка подержанной одежды. С таким количеством пользователей он проводит большое количество A/B -тестов одновременно, чтобы предоставить лучший опыт для своих пользователей. Это делает Vinted идеальной средой для оценки эффективности безопасных тестов. В этом разделе мы применяем безопасный T-критерий и безопасные тесты на пропорцию для экспериментальных данных Vinted. Безопасный t-критерий будет сравниваться с классическим t-критерием для оценки результатов A/B-тестов. Кроме того, безопасная пропорция будет сравниваться с тестом χ2 в качестве среднего значения для обнаружения несоответствия соотношения выборки экспериментов.
7.1 Safe T-тест для винтированных A/B-тестов
Метрики для 162 винтированных экспериментов с марта 2023 года по июнь 2023 года будут оценены для этого анализа. Мы собрали кумулятивные ежедневные снимки 143 метрики, содержащие среднее значение метрики, стандартное отклонение и размер выборки как для контрольных, так и для тестовых групп. Эксперименты с несколькими вариантами рассматриваются как отдельные тесты с одной и той же контрольной группой. Безопасный T-критерий и классический t-критерий сравнивались во всех 42115 экспериментальных/метрических комбинациях в этом наборе данных. В таблице 7 показаны результаты статистических тестов на уровне α = 0,05.
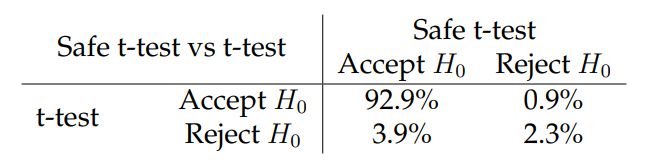
Результаты таблицы 7 показывают, что безопасное t-критерий и классический t-критерий последовательно достигают того же вывода о значении метрик. 379 случаев, в которых безопасное t-критерий отклоняет H0, который T-критерий не соответствует моделированию, демонстрирующим, что тесты не всегда согласны с тем, что представляет собой значительный результат. Большое количество 1645 случаев, в которых T-критерий отклоняет H0, в то время как безопасное t-критерий не связан с большим количеством. Безопасный T-тест более чувствителен, когда он наблюдает последовательно данные, предоставляя больше возможностей для отклонения H0. Эти данные агрегируются на ежедневном уровне, что эффективно снижает силу теста. С большим количеством гранулированных данных, безопасный t-критерий обнаружит больше эффектов, чем в этом групповом последовательном обстановке.
Тест последовательного соотношения смеси (MSPRT) проводился на одном и том же наборе экспериментов. Результаты можно найти в таблице 8.
Сравнение результатов таблицы 8 с таблицей 7 показывает, что MSPRT значительно меньше
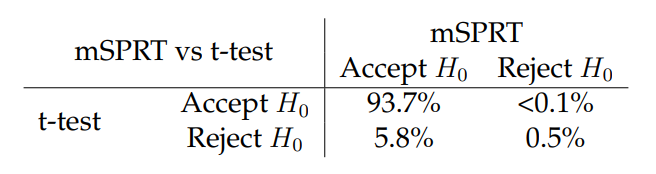
мощный, чем безопасное t-критерий. Хотя это частично из-за последовательной группы, результатов нашего моделирования показывают, что MSPRT является просто менее чувствительным статистическим тестом, чем безопасное t-критерий.
Вернувшись к безопасным результатам T-теста, было обнаружено, что безопасный T-критерий показал значительно лучше в некоторых показателях, чем другие. Здесь мы дополнительно проанализируем метрики, чтобы понять, почему это так. Чтобы количественно оценить производительность Safe T-теста на метрике, мы используем коэффициент PHI для сравнения его решений с классическим t-тестом. Коэффициент PHI, также известный как коэффициент корреляции Мэтьюса, используется для определения корреляции бинарных переменных. Чтобы понять цель каждой метрики, в рамках A/B тестирование Vinted есть текстовое описание. Краткое изложение тем в каждом описании можно извлечь с помощью скрытого распределения дирихле. Странное распределение Dirichlet (LDA) - это метод обработки естественного языка для моделирования тем из набора документов. В этом случае LDA используется для извлечения тем из метрических описаний в виде скрытых векторов. Мы умножаем скрытые векторы на коэффициент PHI, чтобы найти средний коэффициент PHI для каждой темы. В таблице 9 показаны слова, которые коррелируют с более высокими и более низкими коэффициентами PHI.

Во время введения в A/B -тестирование было упомянуто, что некоторые метрики занимают гораздо больше времени. Это означает, что данные не будут независимыми и одинаково распределяться по дням теста. Изучая Таблицу 9, мы видим высокую корреляцию между эффективностью безопасного T-критерия и классическим t-критерием на метриках, включающих поиски, сеансы и впечатления. Это все величины, которые имеют короткое время между воздействием теста и реализацией метрики. И наоборот, безопасный T-критерий не очень хорошо работает на долгосрочных показателях, включающих транзакции и отмены порядка. Вместе эти результаты показывают, что безопасное t-критерий будет оптимально работать на метриках, для которых результаты доступны мгновенно.
7.2 безопасная пропорция для несоответствия соотношения образца
Чтобы определить эффективность теста на безопасную пропорцию и тест χ2 при обнаружении несоответствия коэффициента образца (SRM), анализируются распределения 195 экспериментов из винтированных. Безопасной тест применяется к ежедневным снимкам распределений, в то время как тест χ2 применяется к распределению в последний день эксперимента. Для SRM уровень значимости α = 0,01 используется для ограничения количества ложных срабатываний. Бета -предварительные значения α1, β1 = 1000 используются для теста на безопасную долю. Сравнение результатов между тестом на безопасную долю и тестом χ 2 можно увидеть в таблице 10.

Автор:
(1) Даниэль Бизли
Эта статья есть
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27294)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)