

Используйте каскадные модели для повышения скорости и точности задач компьютерного зрения
9 ноября 2022 г.Обнаружение объектов — очень распространенная задача в Computer Vision. Наверняка его можно использовать в огромном количестве областей. В последние пару лет мы получили модели, которые действительно могут работать в реальном времени и имеют производительность, близкую к SOTA. Но они не могут быть лучшими из коробки для каждой задачи. Давайте углубимся в это.
Какова наша задача?
Эта задача является лишь примером, идея может быть использована во множестве случаев. Допустим, у нас есть задача обнаружить повреждение на дороге. Камера внутри машины, и машина едет довольно быстро, мы хотели, чтобы наш детектор тоже был быстрым, поэтому мы взяли YOLOv5s.
Это хорошо, но иногда может иметь ложное срабатывание — обнаруживать тень вместо повреждения (или что-то еще, похожее на повреждение). Или он может иметь ложноотрицательный результат — повреждения не обнаружены.
Мы можем играть с уровнем достоверности, чтобы справиться с этим, мы можем добавить больше данных в обучающий набор данных, мы можем добавить больше фоновых изображений, мы можем настроить архитектуру для нашего случая, возиться с гиперпараметрами или дополнениями, но все это может не дать нужных результатов. или быть непрактичным, трудоемким, дорогим.
А как иначе?
Давайте воспользуемся двумя моделями. Один — для обнаружения с низким уровнем достоверности, чтобы избавиться от ложноотрицательных результатов, а второй — для классификации, чтобы избавиться от ложноположительных результатов. Давайте еще немного обсудим нашу архитектуру. п
Первый шаг - используйте быстрый детектор. Он обнаруживает объект, который должен быть поврежден на дороге, а затем обрезает его.
Второй шаг — используйте классификатор для этой культуры с предполагаемым ущербом и получите подтверждение, действительно ли это ущерб. Рекомендуется попробовать разные классификаторы, чтобы получить наилучшие результаты. EfficientNet — хорошее начало (но есть много предварительно обученных моделей как в PyTorch, так и в TensorFlow). Также важно его немного настроить (выбрать, сколько слоев переобучить, как перестроить голову). п
В этом случае детектор может быть обучен только на поврежденной дороге, а классификатор должен быть обучен на поврежденной дороге, фоне и других вещах, таких как грязь, тени, которые могут быть пропущены детектором.
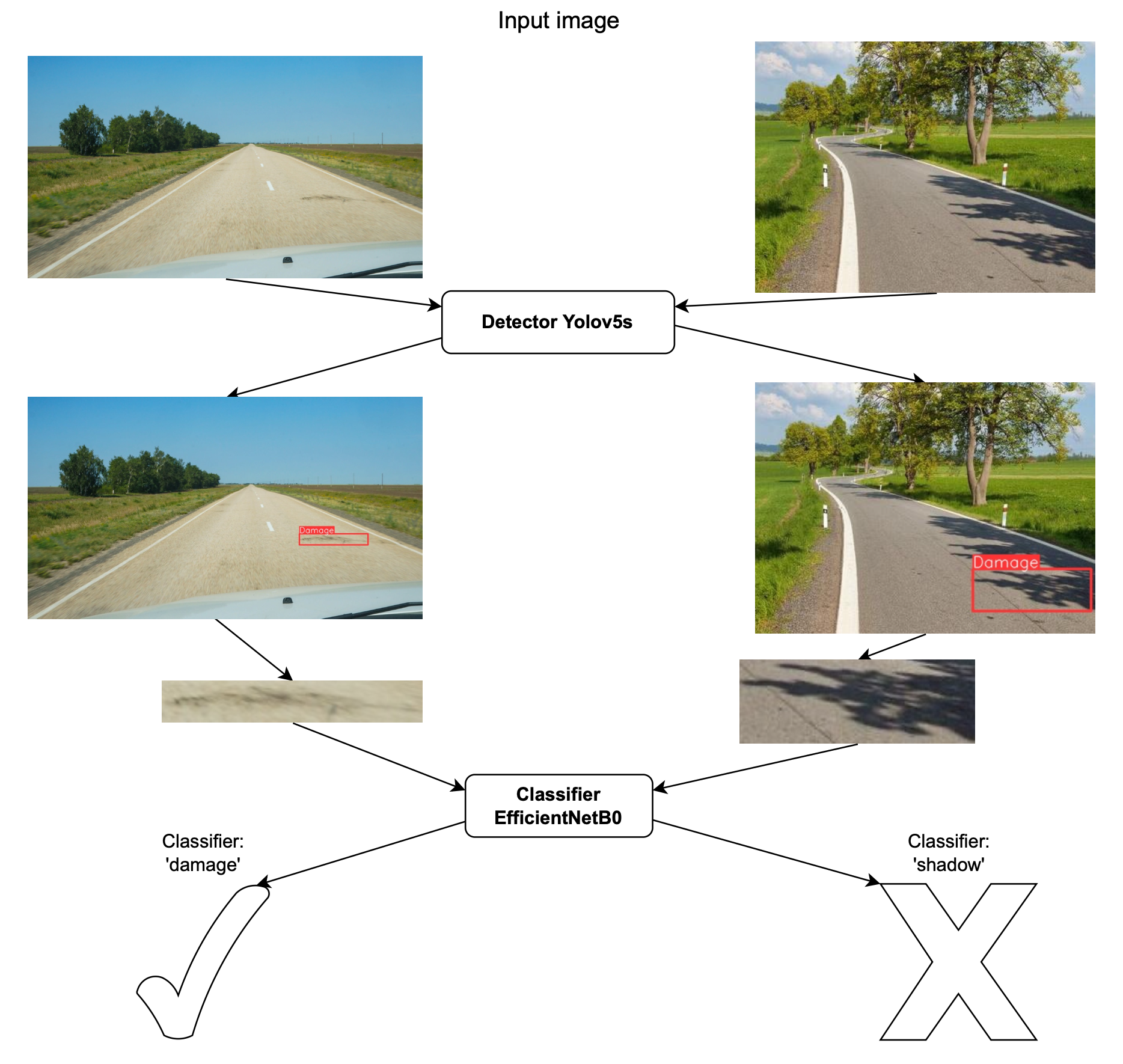
Почему лучше?
- Точность: Основная цель нашего детектора — обнаружить объект, с чем он справляется довольно хорошо. Проблема заключается в классификационной части модели детектора (он может классифицировать фон как цель, также известный как ложное срабатывание). А вот и классификатор, который заточен под классификацию именно в нашем случае. Классификатор можно обучать на нескольких метках, таких как цель (дефект) или фон (грязь, тени и прочее). Классификатор также легче переобучить на новых данных (разметка и обучение выполняются быстрее).
2. Скорость: Детектором (первая модель) обрабатывается каждый кадр, но классификатор (вторая модель) используется только в случаях обнаружения возможного повреждения. Таким образом, в этом случае у нас все еще есть скорость в реальном времени, поскольку мы ограничены только скоростью первой модели.
Давайте посмотрим на пример точности и запоминания, используя эту технику:

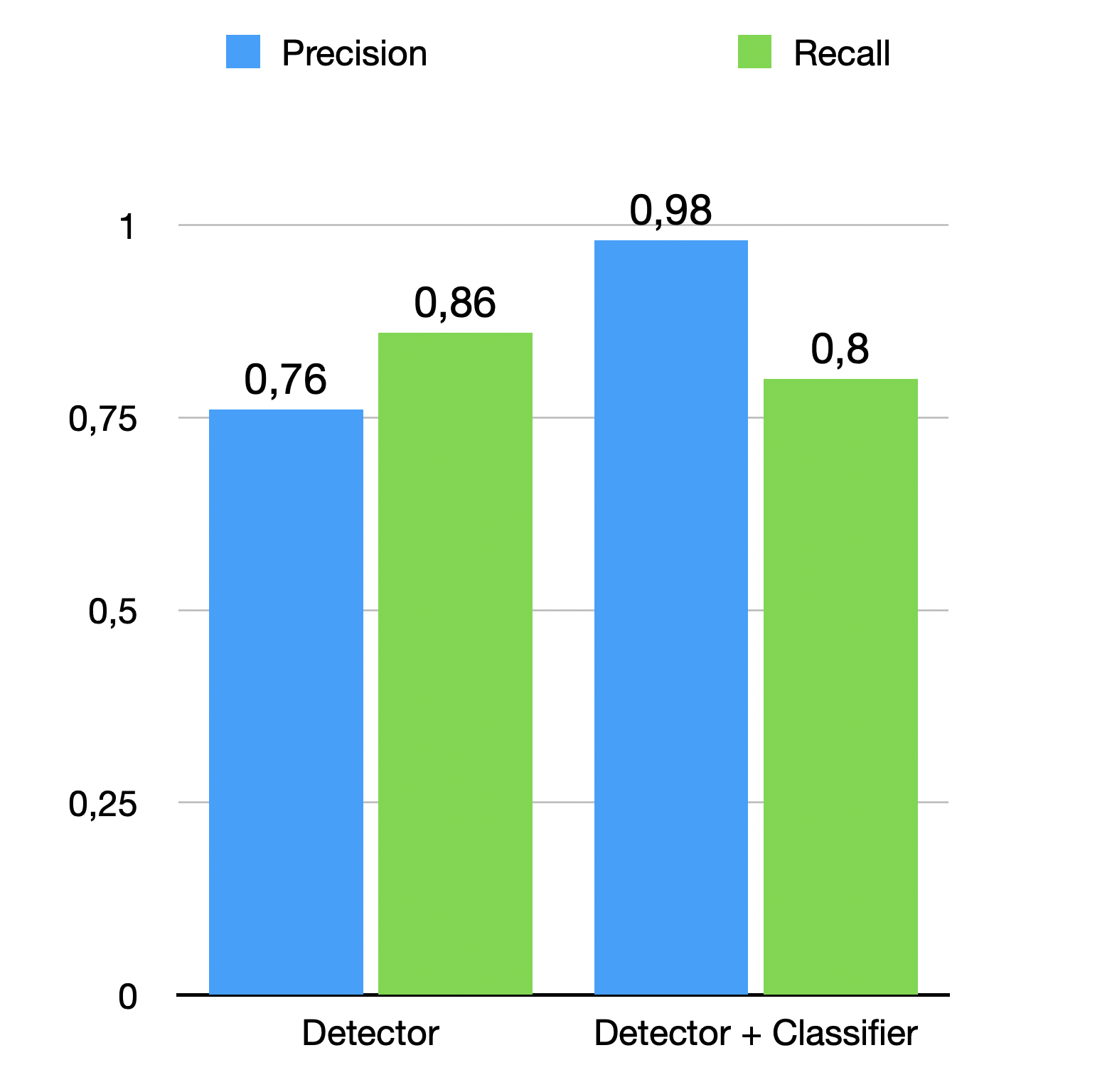
Таким образом, мы резко сократили количество ложных срабатываний, но немного потеряли отзыв. Этот метод может быть особенно полезен в тех случаях, когда ваши ложные срабатывания более критичны, чем ложноотрицательные, поскольку вы действительно не хотите, чтобы ваша система рассылала спам (это может легко произойти с системами, работающими круглосуточно и без выходных).
Итак, что мы получили в итоге?
Благодаря этой архитектуре легко получить лучшее из обоих миров - быстрый детектор и точный классификатор. Вам не нужно выбирать всю модель только потому, что она быстрая, но не очень точная. И это решение намного быстрее, чем настройка архитектуры детектора и переобучение модели с нуля, особенно в реальных задачах, когда данные всегда являются узким местом. п
И эта архитектура довольно универсальна. Это хорошо, когда вы действительно хотите точно классифицировать цель в своих задачах обнаружения.
Также важно отметить, что вы всегда хотели бы настраивать свои модели для достижения наилучшей производительности, переобучать новые данные и настраивать гиперпараметры после того, как у вас есть базовый уровень или даже хорошее рабочее решение.
Спасибо за внимание!
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Лучшие новогодние подарки для владельцев домашних животных
29 мая 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27328)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)