

Распаковка Cinnamon — новый подход Uber к обеспечению устойчивости
23 января 2024 г.В прошлом году команда инженеров Uber опубликовал статью о новом механизме распределения нагрузки, разработанном для их микросервисной архитектуры.< /п>
Эта статья очень интересна с разных точек зрения. Итак, во время чтения я сделал несколько заметок, чтобы уловить свое понимание и записать вещи, в которые мне хотелось бы углубиться позже, если я не получу ответы к концу. Я неоднократно убеждался, что это лучший способ узнать что-то новое.
Что меня с самого начала привлекло, так это ссылка на вековые принципы, использованные при создании этого решения. Я люблю это заимствовать концепции/идеи из разных областей и адаптировать их для решения проблем в другой области.
Если вас интересует отказоустойчивость и стабильность системы, я рекомендую также прочитать отличную книгу Майкла Т. Найгарда Release It!.
Это старая, но полезная книга, в которой подробно рассматриваются стратегии, шаблоны и практические рекомендации по созданию отказоустойчивых и стабильных программных систем, а также подчеркивается, как эффективно справляться с сбоями.
<блок-цитата>
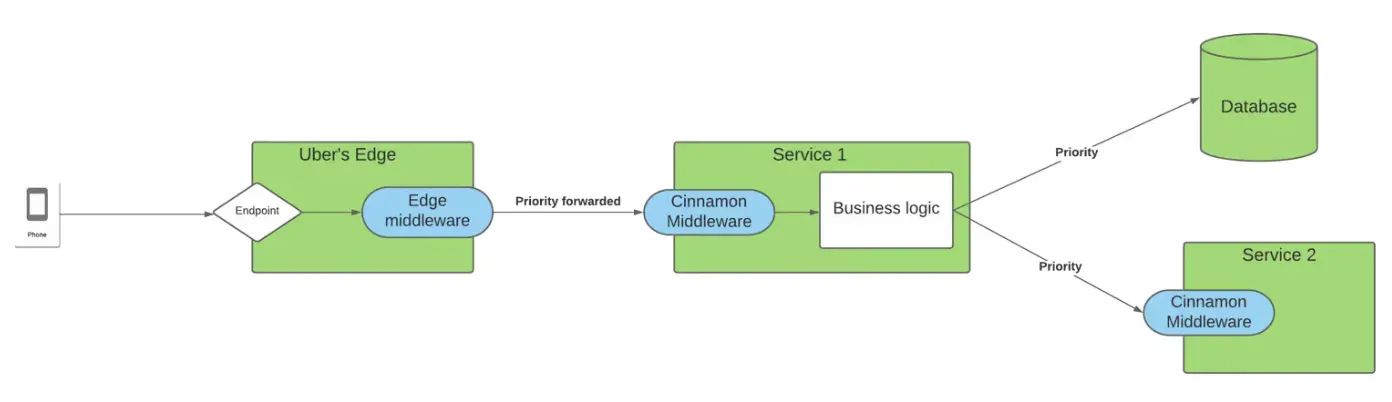
Uber внедрил новое решение для сброса нагрузки под названием Cinnamon, которое использует ПИД-регулятор (механизм многовековой давности) для принятия решения о том, какие запросы должны обрабатываться или отклоняться службой, на основе текущей нагрузки службы и приоритета запроса.
Он не требует какой-либо настройки на уровне сервиса (хотя у меня был вопрос по этому поводу), автоматически адаптируется и намного эффективнее предыдущего решения QALM. Помните также, что архитектура микросервисов Uber не для слабонервных…
Что это за знаменитый ПИД-регулятор и как он используется?
:::совет ПИД-регулятор — это инструмент, используемый в приложениях промышленного управления для регулирования температуры, расхода, давления, скорости и других переменных процесса. ПИД-регуляторы (пропорционально-интегрально-дифференциальные) используют механизм обратной связи контура управления для управления переменными процесса и являются наиболее точными и стабильными регуляторами.
— https://www.omega.co.uk/prodinfo/pid-controllers .html
:::
Если вам нужна дополнительная информация об этой многовековой концепции, посетите Википедию.
Теперь вернемся к статье. ПИД означает «пропорциональный», «интегральный» и «производный». В их случае они используют компонент, известный как ПИД-регулятор, для мониторинга работоспособности службы (входных запросов) на основе трех компонентов (или показателей).
Пропорционально
Термин «пропорциональный» означает, что предпринятое действие пропорционально текущей ошибке. Проще говоря, это означает, что применяемая коррекция прямо пропорциональна разнице между желаемым и фактическим состоянием. Если ошибка велика, корректирующие действия пропорционально велики.
<блок-цитата>Когда конечная точка перегружена, фоновая горутина начинает отслеживать приток и отток запросов в приоритетную очередь.
Таким образом, компонент «Пропорциональный» (P) в устройстве распределения нагрузки регулирует скорость сброса нагрузки в зависимости от того, насколько текущий размер очереди отличается от целевого или желаемого размера очереди. Если очередь больше желаемого, происходит большее отбрасывание; если он меньше, выделение уменьшается.
Я так понимаю.
Интеграл
<блок-цитата>Задача ПИД-регулятора — свести к минимуму количество запросов в очереди, тогда как задача автонастройки — максимизировать пропускную способность службы, не жертвуя задержками ответа (слишком сильно).
Хотя в тексте явно не упоминается «Интеграл (I)» в контексте размера очереди, это указывает на то, что роль ПИД-регулятора заключается в минимизации количества запросов в очереди. Минимизация количества запросов в очереди соответствует цели компонента Integral по устранению накопленных ошибок с течением времени.
<блок-цитата>Чтобы определить, перегружена ли конечная точка, мы отслеживаем, когда в последний раз очередь запросов была пустой, и если она не была очищена в течение последних, скажем, 10 секунд, мы считаем, что конечная точка перегружена (по мотивам Facebook).< /п>
В устройстве распределения нагрузки это может быть связано с решениями, связанными с историческим поведением очереди запросов, например временем с момента ее последнего пустования.
Честно говоря, мне это не совсем понятно. Должен сказать, это немного расстраивает. Хотя они упоминают об использовании многовекового механизма, было бы полезно, если бы они четко указали, какая часть соответствует чему и как он работает. Я не хочу принижать ценность их замечательной статьи. Это всего лишь моя напыщенная речь... В конце концов, я француз... ;)
Производная
Думаю, это легче идентифицировать.
В классическом ПИД-регуляторе (пропорционально-интегрально-дифференциальный) действие «Производная (D)» особенно полезно, когда вы хотите, чтобы контроллер предвидел будущее поведение системы на основе текущей скорости изменения ошибки. Это помогает гасить колебания и повышать стабильность системы.
В контексте устройства распределения нагрузки и ПИД-регулятора, упомянутых в статье, компонент Derivative, скорее всего, используется для оценки того, насколько быстро заполняется очередь запросов. Тем самым это помогает принимать решения, направленные на поддержание стабильной системы и предотвращение внезапных или непредсказуемых изменений.
<блок-цитата>Компонент отклонения имеет две обязанности: а) выяснить, не перегружена ли конечная точка, и б) если конечная точка перегружена, отбросить процент запросов, чтобы убедиться, что очередь запросов как можно меньше. Когда конечная точка перегружена, фоновая горутина начинает отслеживать приток и отток запросов в приоритетную очередь. На основе этих чисел он использует ПИД-регулятор для определения соотношения запросов к сбросу. ПИД-регулятор очень быстро (поскольку требуется очень мало итераций) находит правильный уровень, и как только очередь запросов будет опустошена, ПИД-регулятор гарантирует, что мы только медленно уменьшаем соотношение.
В упомянутом контексте ПИД-регулятор используется для определения соотношения запросов к сбросу при перегрузке конечной точки, а также отслеживает приток и отток запросов. Производный компонент ПИД-регулятора, который реагирует на скорость изменения, неявно участвует в оценке того, насколько быстро заполняется или опустошается очередь запросов. Это помогает принимать динамичные решения для поддержания стабильности системы.
Интегральный и производный компоненты участвуют в мониторинге поведения очереди запросов с течением времени
- Интегральный компонент
В контексте определения перегрузки интегральный компонент может быть связан с отслеживанием того, как долго очередь запросов находилась в непустом состоянии. Это соответствует идее накопления интеграла сигнала ошибки с течением времени.
«Интегральный — в зависимости от того, как долго запрос находится в очереди…»
* Производный компонент
С другой стороны, производная составляющая связана со скоростью изменения. Он реагирует на то, насколько быстро меняется состояние очереди запросов.
«Дериватив — отказ в зависимости от того, насколько быстро заполняется очередь…»
Хотя и интегральный, и производный аспекты включают наблюдение за очередью запросов, они фокусируются на разных аспектах ее поведения
Интегральный компонент подчеркивает продолжительность непустого состояния, а производный компонент учитывает скорость изменения очереди.
В конце игры они используют эти три показателя, чтобы определить порядок действий по запросу.
У меня вопрос: как они сочетают эти три компонента, если вообще совмещают? Мне тоже интересно понять, как они за ними следят.
Тем не менее, думаю, идея у меня появилась...
Какой запрос они решают отложить в зависимости от этих трех компонентов и как?
<блок-цитата>Конечная точка на границе помечается приоритетом запроса, который распространяется от границы на все нижестоящие зависимости через Егерь. Распространяя эту информацию, все службы в цепочке запросов узнают о важности запроса и о том, насколько он важен для наших пользователей.
Первая мысль, которая приходит на ум, — это то, что это можно легко интегрировать в архитектуру сервисной сетки.
Я ценю концепцию использования распределенной трассировки служб и заголовков для распространения приоритета запроса. В этом смысле, зачем выбирать общую библиотеку с этой зависимостью, добавленной к каждому микросервису, вместо того, чтобы размещать ее вне службы, например, в виде плагина Istio? Учитывая преимущества, которые он предлагает: независимые циклы выпуска/развертывания, поддержка нескольких языков и т. д.
Вот еще несколько мыслей:
* Существует ли вероятность того, что со временем приоритет запроса может ухудшиться или измениться в зависимости от контекстуальных изменений, таких как запуск незапланированного пакетного процесса или задачи с высоким приоритетом или изменений на уровне часового пояса/региона?
* Как этот подход работает с другими «стандартными» подходами/шаблонами управления устойчивостью, такими как автоматические выключатели, тайм-ауты, аренда, перегородки и т. д.?
* Мне интересно понять, в какой степени сервис решает (принимает решение) отбрасывать запросы на основе приоритета входного запроса. Они упоминают об отсутствии конфигурации (аспект, который я хотел бы изучить подробнее), поэтому он не специфичен для сервиса и совершенно независим от реализации сервиса, что в некоторой степени прозрачно. Это возвращает точку зрения на циклы сервисной сетки/независимых выпусков по сравнению с зависимой библиотекой.
Ну, я предвзят, так как я не большой поклонник разделяемых библиотек хотя бы потому, что считаю, что они усложняют процесс выпуска/развертывания. Однако я не уверен, стоит ли учитывать какой-либо аспект конфигурации, специфичный для службы. Возможно, они настраивают, как долго служба должна ждать, прежде чем начать обработку запроса и завершить его?
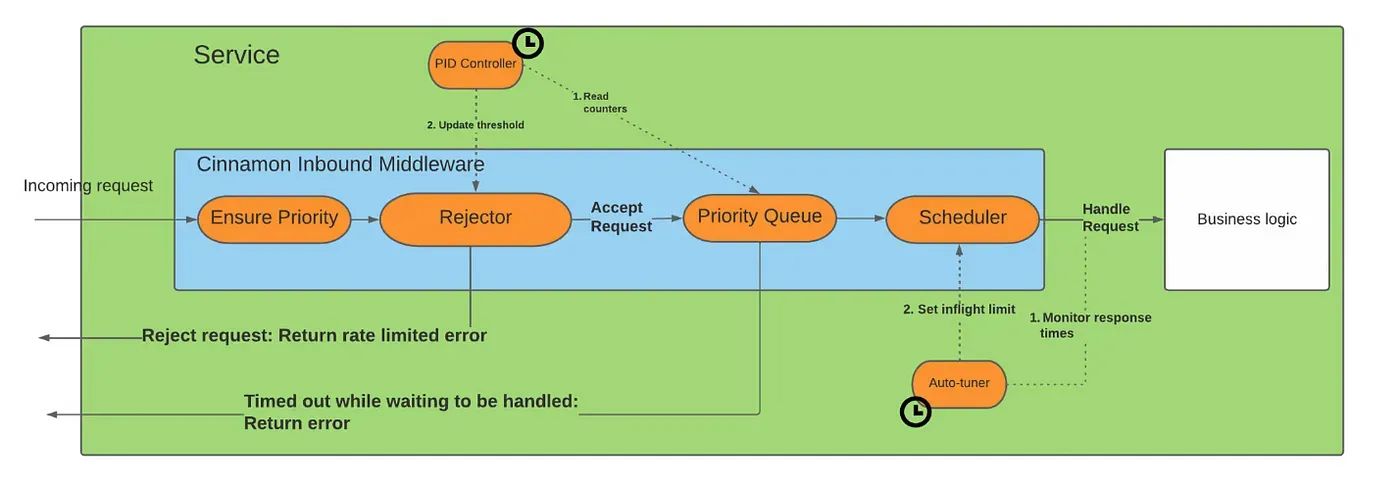
Возможно, один из аспектов, который стоит проверить, — это процесс принятия решений эжектором.
Насколько я понимаю, он определяет, отклонять ли запрос, на основе ПИД-регулятора, который локализован в сервисе. Есть ли вариант более глобального подхода? Например, если известно, что одна из нижестоящих служб в конвейере перегружена (из-за собственного ПИД-контроллера), может ли какая-либо вышестоящая служба принять решение отклонить запрос до того, как он достигнет этой перегруженной службы (что может быть на n шагов дальше по конвейеру) путь)?
Это решение может быть основано на значении, возвращаемом ПИД-регулятором или автонастройкой нижестоящей службы.
<блок-цитата>
Теперь я размышляю над различными упомянутыми аспектами, пока они завершают статью, и приводит некоторые цифры, демонстрирующие эффективность их системы, которая весьма впечатляет.
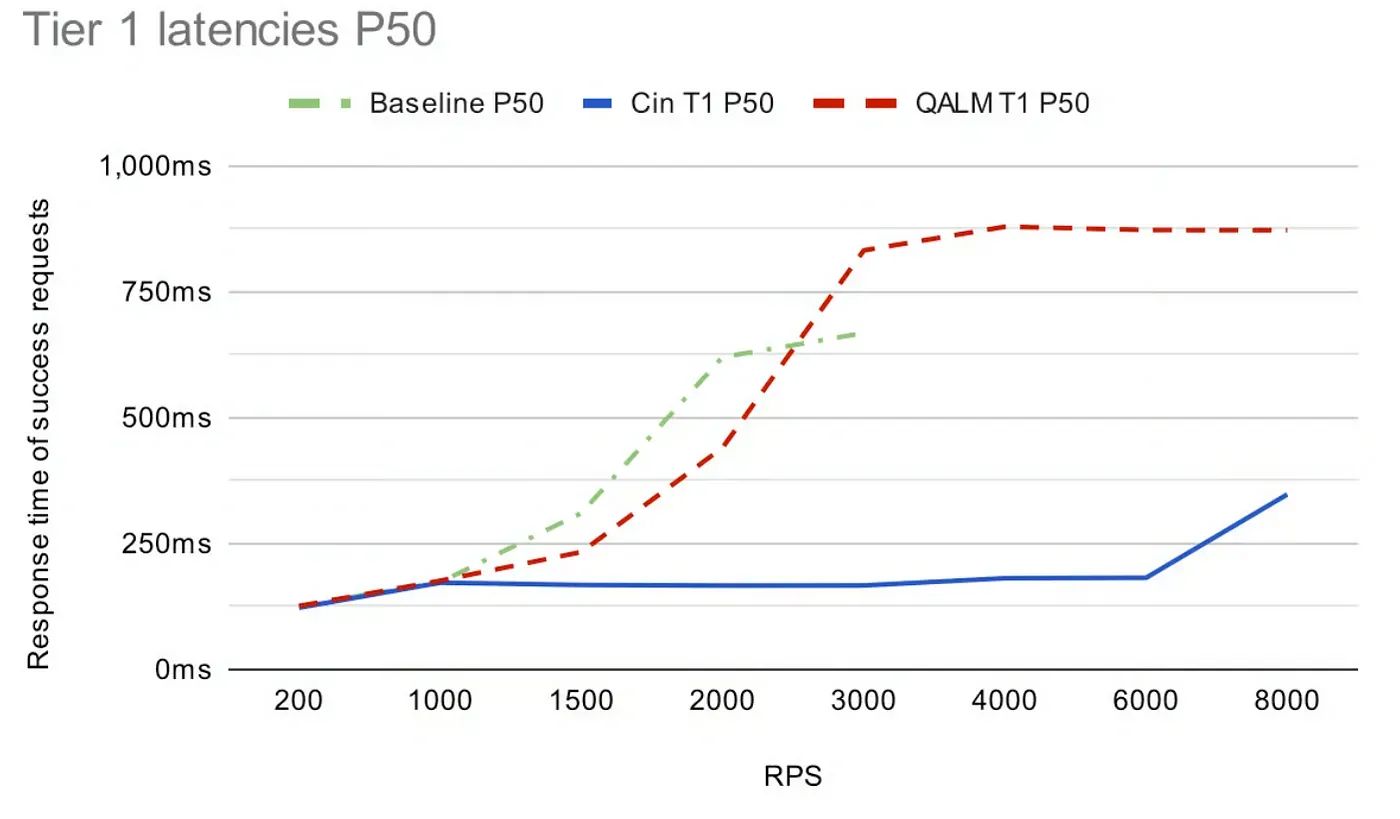
В какой-то момент они упоминают, что «время ожидания каждого запроса составляет 1 секунду».
<блок-цитата>Мы запускаем тесты продолжительностью 5 минут, в ходе которых мы отправляем фиксированное количество запросов в секунду (например, 1000), где 50 % трафика приходится на уровень 1, а 50 % — на уровень 5. Каждый запрос имеет тайм-аут в 1 секунду.< /п>
В распределенных системах принято связывать запрос с определенным временем истечения срока действия или крайним сроком, при этом каждая служба на пути обработки отвечает за соблюдение этого ограничения по времени. Если время истечения срока действия достигнуто до завершения запроса, любая служба в цепочке имеет возможность прервать или отклонить запрос.
Я предполагаю, что этот 1-секундный тайм-аут привязан к запросу, и каждый сервис, в зависимости от того, где мы находимся в этот срок, может решить прервать запрос. Это глобальный показатель, поскольку он агрегируется по сервисам. Я думаю, что это перекликается с тем, что я говорил ранее о наличии глобального представления о полной работоспособности системы или зависимостях, чтобы принять решение как можно скорее прервать запрос, если у него нет возможности завершиться из-за одной из служб ниже путь.
Можно ли возвращать «работоспособность» нижестоящих служб (включая данные от их локальных ПИД-контроллеров) в виде заголовков, прикрепленных к ответам, и использовать их для создания более развитого механизма автоматического выключателя/раннего упреждающего отключения?
<блок-цитата>
Наконец, мне интересно узнать больше о предыдущем подходе, потому что, судя по описанию, данному в этой статье, он кажется разумным.
Когда вы изучаете показатели производительности и задержек, не возникает сомнений в том, какой из них, QALM или Cinnamon, работает лучше всего. Обратите внимание, что в статье упоминается ссылка на подход QALM. Вероятно, следует начать с там ;)
Как всегда, эти подходы не для всех. У Uber своя архитектура и нагрузка. На самом деле мне не терпится прочитать следующие статьи этой серии, особенно чтобы узнать больше о ПИД-регуляторе и автотюнере.
<блок-цитата>С помощью Cinnamon мы создали эффективное устройство распределения нагрузки, которое использует проверенные веками методы для динамического установления пороговых значений для отклонения и оценки мощности сервисов. Он решает проблемы, которые мы заметили с QALM (и, следовательно, с любым устройством распределения нагрузки на основе CoDel), а именно: Cinnamon может:
– Быстро находите стабильный процент отказов
- Автоматическая настройка мощности сервиса
- Использоваться без установки каких-либо параметров конфигурации
- Нести очень низкие накладные расходы.
Что интересно в этом подходе, так это то, что они рассматривают все запросы, подлежащие обработке, чтобы решить, что делать с каждым новым входным запросом, поскольку они используют (приоритетную) очередь. Как уже упоминалось, мне любопытно, может ли этот механизм также учитывать работоспособность всех зависимых служб на основе тех же показателей PID…
В этой статье есть и другие интересные аспекты, например, как они измеряют эффект своих стратегий и сравнение с предыдущим подходом. Однако оно не требует от меня более подробных заметок, чем уже изложенные. Итак, я настоятельно рекомендую вам прочитать оригинальная статья.
Нашли эту статью полезной? Следуйте за мной в Linkedin, Hackernoon и Средний ! Пожалуйста 👏 поделитесь этой статьей!
:::информация Также опубликовано здесь.
:::
Оригинал
🔥 Популярное на этой неделе
-
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27222)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)