

Настоящие убийцы C++ (не вы, Rust)
15 февраля 2023 г.Привет! Меня зовут Александр Каленюк, я C++голик. Я пишу на C++ уже 17 лет и все эти 17 лет пытаюсь избавиться от этой пагубной зависимости.
Все началось в 2005 году с движка трехмерного космического симулятора. В движке было все, что было в C++ 2005 года. Трехзвездные указатели, восемь уровней зависимости и повсюду макросы в стиле C. Были и сборочные детали. Итераторы в стиле Степанова и метакод в стиле Александреску. В коде было все. Кроме, конечно, ответа на самый главный вопрос: зачем?
Через некоторое время даже на этот вопрос был дан ответ. Только не как "зачем", а как "как получилось". Как оказалось, движок писался около 8 лет 5 разными командами. И каждая команда привнесла в проект свою любимую причуду, завернув старый код в свеже оформленные обертки, добавив при этом всего около 10-20 микрокармаков функциональности.
Поначалу я честно пытался вникнуть в каждую мелочь. Это был не очень приятный опыт, совсем нет, и в какой-то момент я сдался. Я все еще закрывал задачи и исправлял ошибки. Не могу сказать, что я был очень продуктивным, но достаточно, чтобы меня не уволили. Но тут мой начальник спросил меня: «Не хочешь ли ты переписать часть кода шейдера с ассемблера на GLSG?» Я подумал, что бог знает, как выглядит этот GLSL, но он не может быть хуже, чем C++, и сказал «да». Хуже не было.
И это стало образцом. Я по-прежнему в основном писал на C++, но каждый раз, когда кто-то спрашивал меня: «Хочешь заняться чем-то другим, кроме C++?» Я был уверен!" и я сделал это, что бы это ни было. Я писал на C89, MASM32, C#, PHP, Delphi, ActionScript, JavaScript, Erlang, Python, Haskell, D, Rust и даже на ужасно плохом языке сценариев InstallShield. Я писал на VisualBasic, на bash и на нескольких проприетарных языках, о которых даже не могу юридически говорить. Я даже сделал один сам случайно. Я сделал простой интерпретатор в стиле lisp, чтобы помочь разработчикам игр автоматизировать загрузку ресурсов, и отправился в отпуск. Когда я вернулся, они писали целые игровые сцены в этом интерпретаторе, поэтому нам пришлось поддерживать его как минимум до конца проекта.
Итак, последние 17 лет я честно пытался бросить C++, но каждый раз, когда я пробовал что-то новое, я возвращался. Тем не менее, я считаю, что писать на C++ — дурная привычка. Это небезопасно, не так эффективно, как думают, и тратит огромное количество умственных способностей программиста на вещи, которые не имеют ничего общего с созданием программного обеспечения. Вы знаете, что в MSVC uint16_t(50000) + uin16_t(50000) == -1794967296? Ты знаешь почему? Да, я так и думал.
Я считаю, что моральная ответственность давних программистов на C++ заключается в том, чтобы отговорить молодое поколение от того, чтобы сделать C++ своей профессией, в значительной степени, как и моральная ответственность алкоголиков, которые не могут бросить, чтобы предупредить молодежь об опасности.
Но почему я не могу бросить? В чем дело? Дело в том, что ни один из языков, особенно так называемые «убийцы C++», не дает реального преимущества перед C++ в современном мире. Все эти новые языки в основном сосредоточены на том, чтобы держать программиста на привязи для их же блага. Это хорошо, но писать хороший код плохими программистами — это проблема ХХ века, когда транзисторы росли вдвое каждые 18 месяцев, а численность программистов росла вдвое каждые 5 лет.
Мы живем в 2023 году. В мире больше опытных программистов, чем когда-либо в истории. И сейчас нам нужно эффективное программное обеспечение больше, чем когда-либо.
В XX веке все было проще. У вас есть идея, вы оборачиваете ее в некий пользовательский интерфейс и продаете как десктопный продукт. Это медленно? Какая разница! В любом случае, через восемнадцать месяцев десктопы станут в 2 раза быстрее. Важно выйти на рынок, начать продавать фичи и желательно без багов. В таком климате, конечно, если компилятор удерживает программистов от ошибок — хорошо! Потому что ошибки не приносят денег, и вы должны платить своим программистам независимо от того, добавляют ли они функции или добавляют ошибки.
Теперь все по-другому. У вас есть идея, вы оборачиваете ее в контейнер Docker и запускаете в облаке. Теперь вы получаете доход от людей, использующих ваше программное обеспечение, если оно устраняет их проблемы. Даже если он сделает что-то одно, но сделает это правильно, вам заплатят. Вам не нужно наполнять свой продукт выдуманными функциями только для того, чтобы продать его новую версию. С другой стороны, тот, кто платит за неэффективность вашего кода, теперь вы сами. Каждая неоптимальная процедура отображается в вашем счете AWS.
Таким образом, в новых условиях вам нужно меньше функций, но более высокая производительность для всего, что у вас есть.
И вдруг оказывается, что все «убийцы C++», даже те, которых я искренне люблю и уважаю, вроде Rust, Julia и D, не решают проблемы XXI века. Они все еще застряли в ХХ. Они помогают вам писать больше функций с меньшим количеством ошибок, но они не очень помогают, когда вам нужно выжать последний провал из арендуемого вами оборудования.
Они просто не дают вам конкурентного преимущества перед C++. Или, если уж на то пошло, даже друг над другом. Большинство из них, например, Rust, Julia и Cland, даже используют один и тот же бэкенд. Вы не сможете выиграть автомобильную гонку, если у всех вас будет одна машина.
Итак, какие технологии действительно дают вам конкурентное преимущество перед C++ или, вообще говоря, перед всеми традиционными опережающими компиляторами? Хороший вопрос. Рад, что вы спросили.
Убийца C++ номер 1. Спираль
Но прежде чем перейти к самой спирали, давайте проверим, насколько хорошо работает ваша интуиция. Как вы думаете, что быстрее: стандартная синусоидальная функция C++ или четырехчастная полиномиальная модель синуса?
auto y = std::sin(x);
// vs.
y = -0.000182690409228785*x*x*x*x*x*x*x
+0.00830460224186793*x*x*x*x*x
-0.166651012143690*x*x*x
+x;
Следующий вопрос. Что работает быстрее, используя логические операции с коротким замыканием или обманывая компилятор, чтобы избежать этого и вычислить логическое выражение в большом количестве?
if (xs[i] == 1 && xs[i+1] == 1 && xs[i+2] == 1 && xs[i+3] == 1) // xs are bools stored as ints
// vs.
inline int sq(int x) {
return x*x;
}
if(sq(xs[i] - 1) + sq(xs[i+1] - 1) + sq(xs[i+2] - 1) + sq(xs[i+3] - 1) == 0)
И еще один. Что быстрее сортирует триплеты: сортировка с перестановкой или сортировка по индексу?
if(s[0] > s[1])
swap(s[0], s[1]);
if(s[1] > s[2])
swap(s[1], s[2]);
if(s[0] > s[1])
swap(s[0], s[1]);
// vs.
const auto a = s[0];
const auto b = s[1];
const auto c = s[2];
s[int(a > b) + int(a > c)] = a;
s[int(b >= a) + int(b > c)] = b;
s[int(c >= a) + int(c >= b)] = c;
Если вы ответили на все вопросы решительно и даже не подумав и не погуглив, значит, интуиция вас подвела. Вы не видели ловушку. Ни на один из этих вопросов нет однозначного ответа без контекста.
На какой ЦП или ГП нацелен код? Какой компилятор должен собирать код? Какие оптимизации компилятора включены, а какие выключены? Вы можете начать прогнозировать только тогда, когда знаете все это или, что еще лучше, измеряете время выполнения для каждого конкретного решения.
- Полиномиальная модель в 3 раза быстрее, чем стандартная синусоидальная модель, если она построена с помощью clang 11 с -O2 -march= родной и работал на Intel Core i7-9700F. Но если он собран на nvcc с --use-fast-math и на графическом процессоре, а именно на GeForce GTX 1050 Ti Mobile, стандартный синусоидальный сигнал в 10 раз быстрее, чем у модели.
2. Обмен короткозамкнутой логики на векторизованную арифметику имеет смысл и на i7. Заставляет сниппет работать в два раза быстрее. Но на ARMv7 с тем же clang и -O2 стандартная логика на 25 % быстрее, чем микрооптимизация.
3. При использовании индексной сортировки и своп-сортировки сортировка по индексу в Intel выполняется в 3 раза быстрее, а своп-сортировка в 3 раза быстрее. на GeForce.
Таким образом, милые микрооптимизации, которые мы все так любим, могут как ускорить наш код в 3 раза, так и замедлить его на 90%. Все зависит от контекста. Как было бы замечательно, если бы компилятор мог выбрать для нас наилучшую альтернативу, т.е. г. индексная сортировка чудесным образом превратится в своп-сортировку, когда мы переключим цель сборки. Но не получилось.
- Даже если мы позволим компилятору повторно реализовать синус как полиномиальную модель, чтобы обменять точность на скорость, он все равно не знает нашу целевую точность. В C++ нельзя сказать, что «эта функция может иметь эту ошибку». Все, что у нас есть, это флаги компилятора, такие как «--use-fast-math», и только в рамках единицы перевода.
2. Во втором примере компилятор не знает, что наши значения ограничены либо 0, либо 1, и не может предложить оптимизацию, которую можем мы. Вероятно, мы могли бы намекнуть на это, используя правильный тип bool, но это была бы совершенно другая проблема.
3. А в третьем примере фрагменты кода сильно различаются, чтобы их можно было признать синонимами. Мы слишком детализировали код. Если бы это был просто std::sort, это уже дало бы компилятору больше свободы выбора алгоритма. Но он не выбрал бы ни сортировку индексом, ни сортировку подкачки, поскольку они обе неэффективны для больших массивов, а std::sort работает с универсальным итерируемым контейнером.
Вот так мы и добрались до Spiral. Это совместный проект Университета Карнеги-Меллона и Eidgenössische Technische Hochschule Zürich. TL&DR: специалистам по обработке сигналов надоело вручную переписывать любимые алгоритмы для каждого нового устройства, и они написали программу, которая делает это за них. Программа берет высокоуровневое описание алгоритма и подробное описание аппаратной архитектуры и оптимизирует код до тех пор, пока не будет реализована наиболее эффективная реализация алгоритма для указанного аппаратного обеспечения.
Важное различие между Fortran и ему подобными состоит в том, что Spiral действительно решает задачу оптимизации в математическом смысле. Он определяет время выполнения как целевую функцию и ищет ее глобальный оптимум в факторном пространстве вариантов реализации, ограниченных аппаратной архитектурой. Это то, чего компиляторы никогда не делают.
Компилятор не ищет истинный оптимум. Он оптимизирует код, руководствуясь эвристикой, которой его научили программисты. По сути, компилятор работает не как машина, ищущая оптимальное решение, а как программист на ассемблере. Хороший компилятор работает как хороший программист на ассемблере, но не более того.
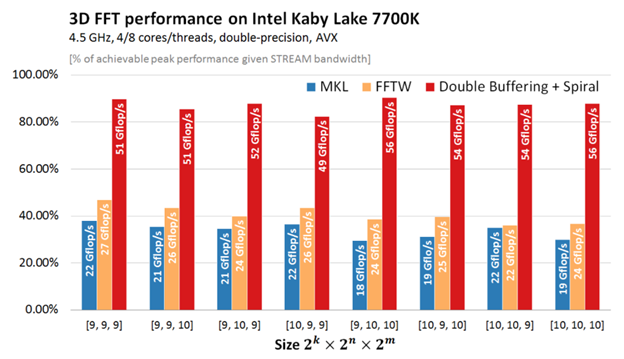
Спираль — исследовательский проект. Он ограничен по объему и бюджету. Но результаты, которые он показывает, уже впечатляют. При быстром преобразовании Фурье их решение значительно превосходит реализации как MKL, так и FFTW. Их код примерно в 2 раза быстрее. Даже на Intel.
Просто чтобы подчеркнуть масштаб достижений, MKL — это библиотека математического ядра, разработанная самой Intel, то есть ребятами, которые знают, как использовать свое оборудование больше всего. А WWTF A.K.A. «Самое быстрое преобразование Фурье на Западе» — это узкоспециализированная библиотека от ребят, которые знают алгоритм лучше всех. Они оба чемпионы в своем деле, и сам факт того, что Spiral превосходит их обоих дважды, просто поразителен.
Когда технология оптимизации, которую использует Spiral, будет доработана и коммерциализирована, не только C++, но и Rust, Julia и даже Fortran столкнутся с конкуренцией, с которой никогда раньше не сталкивались. Зачем кому-то писать на C++, если написание высокоуровневого языка описания алгоритмов делает ваш код в 2 раза быстрее?
Убийца C++ номер 2. Numba
Лучший язык программирования — это тот, который вы уже хорошо знаете. В течение нескольких десятилетий самым известным языком для большинства программистов был C. Он также лидирует в индексе TIOBE, а другие C-подобные плотно заполняют первую десятку. Однако всего два года назад произошло нечто неслыханное. Буква C уступила свое первое место чему-то другому.
«Что-то еще» оказалось Python. Язык, который никто не воспринимал всерьез в 90-е, потому что это был еще один скриптовый язык, которого у нас уже было предостаточно.
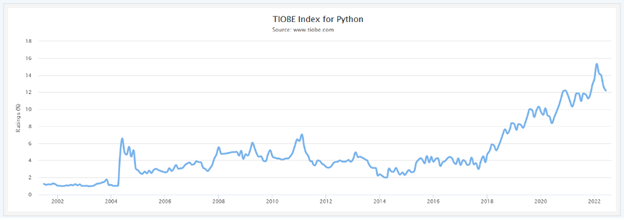
Кто-то скажет: «Ба, Python медленный», и будет выглядеть дураком, так как это терминологическая чушь. Так же, как аккордеон или сковородка, язык просто не может быть быстрым или медленным. Точно так же, как скорость аккордеона зависит от того, кто играет, «скорость» языка зависит от того, насколько быстр его компилятор.
«Но Python — это не компилируемый язык», — может продолжить кто-то и снова дать осечку. Существует множество компиляторов Python, и наиболее перспективным из них, в свою очередь, является скрипт Python. Позвольте мне объяснить.
У меня когда-то был проект. Моделирование 3D-печати, которое изначально было написано на Python, а затем переписано на C++ «для повышения производительности», а затем перенесено на GPU, и все это до того, как я пришел. Затем я потратил месяцы на перенос сборки на Linux, оптимизируя код GPU для Tesla M60, так как он был самым дешевым в AWS на тот момент, и проверка всех изменений в коде C++/CU, чтобы они соответствовали исходному коду на Python. Поэтому я делал все, кроме того, на чем обычно специализируюсь, а именно на разработке геометрических алгоритмов.
И когда у меня, наконец, все заработало, мне позвонил студент из Бремена, работающий неполный рабочий день, и спросил: «Так ты хорошо разбираешься в разнородных вещах, можешь помочь мне запустить один алгоритм на GPU?» Конечно! Я рассказал ему о CUDA, CMake, сборке Linux, тестировании и оптимизации; провел, может быть, час, разговаривая. Он все это выслушал очень вежливо, а в конце сказал: «Это все очень интересно, но у меня очень конкретный вопрос. Итак, у меня есть функция, я написал @cuda.jit перед ее определением, а Python что-то говорит о массивах и не компилирует ядро. Вы знаете, в чем здесь может быть проблема?»
Я не знал. Сам разобрался за день. Судя по всему, Numba не работает с нативными списками Python, он принимает данные только в массивах NumPy. Итак, он понял это и запустил свой алгоритм на графическом процессоре. В Питоне. У него не было ни одной из проблем, на решение которых я потратил месяцы. Вы хотите это на Linux? Не проблема, просто запустите его в Linux. Вы хотите, чтобы он соответствовал коду Python? Не проблема, это код Python. Вы хотите оптимизировать для целевой платформы? Опять не проблема. Numba оптимизирует код для платформы, на которой вы запускаете код, поскольку он не компилируется заранее, а компилируется по запросу, когда уже развернут.
Разве это не здорово? Ну нет. Во всяком случае, не для меня. Я потратил месяцы на C++, решая проблемы, которые никогда не возникают в Numba, а подработчик из Бремена сделал то же самое за несколько дней. Это могло занять несколько часов, если бы это не был его первый опыт общения с Numba. Так что же это за Нумба? Что это за колдовство?
Никакого колдовства. Декораторы Python превращают каждый фрагмент кода в его абстрактное синтаксическое дерево, чтобы вы могли делать с ним все, что захотите. Numba — это библиотека Python, которая хочет компилировать абстрактные синтаксические деревья с любым имеющимся у нее бэкендом и для любой поддерживаемой платформы. Если вы хотите скомпилировать свой код Python для работы на ядрах ЦП с массовым параллелизмом — просто скажите Numba, чтобы он скомпилировал его. Если вы хотите запустить что-то на GPU, опять же, вы должны только спросить.
@cuda.jit
def matmul(A, B, C):
"""Perform square matrix multiplication of C = A * B."""
i, j = cuda.grid(2)
if i < C.shape[0] and j < C.shape[1]:
tmp = 0.
for k in range(A.shape[1]):
tmp += A[i, k] * B[k, j]
C[i, j] = tmp
Numba — один из компиляторов Python, который делает C++ устаревшим. Теоретически, однако, он ничем не лучше C++, поскольку использует те же серверные части. Он использует CUDA для программирования GPU и LLVM для CPU. На практике, поскольку не требуется заблаговременной перестройки для каждой новой архитектуры, решения Numba лучше адаптируются к каждому новому оборудованию и его доступным оптимизациям.
Конечно, было бы лучше иметь явное преимущество в производительности, как у Spiral. Но Spiral — это больше исследовательский проект, он может убить C++, но только в конце концов и только если повезет. Numba с Python душит C++ прямо сейчас, в режиме реального времени. Потому что, если вы можете писать на Python и иметь производительность C++, зачем вам писать на C++?
Убийца C++ номер 3. ForwardCom
Давайте сыграем в другую игру. Я дам вам три куска кода, и вы догадаетесь, какой из них, а может и больше, написан на ассемблере. Вот они:
invoke RegisterClassEx, addr wc ; register our window class
invoke CreateWindowEx,NULL,
ADDR ClassName, ADDR AppName,
WS_OVERLAPPEDWINDOW,
CW_USEDEFAULT, CW_USEDEFAULT,
CW_USEDEFAULT, CW_USEDEFAULT,
NULL, NULL, hInst, NULL
mov hwnd,eax
invoke ShowWindow, hwnd,CmdShow ; display our window on desktop
invoke UpdateWindow, hwnd ; refresh the client area
.while TRUE ; Enter message loop
invoke GetMessage, ADDR msg,NULL,0,0
.break .if (!eax)
invoke TranslateMessage, ADDR msg
invoke DispatchMessage, ADDR msg
.endw
(module
(func $add (param $lhs i32) (param $rhs i32) (result i32)
get_local $lhs
get_local $rhs
i32.add)
(export "add" (func $add)))
v0 = my_vector // we want the horizontal sum of this
int64 r0 = get_len ( v0 )
int64 r0 = round_u2 ( r0 )
float v0 = set_len ( r0 , v0 )
while ( uint64 r0 > 4) {
uint64 r0 >>= 1
float v1 = shift_reduce ( r0 , v0 )
float v0 = v1 + v0
}
Итак, какой из них или несколько находятся в сборке? Если вы думаете, что все три, поздравляю! ваша интуиция уже стала намного лучше!
Первый находится в MASM32. Это макроассемблер с «если» и «пока», на котором люди пишут нативные Windows-приложения. Правильно, не «привык писать», а «пишут» и по сей день. Microsoft ревностно защищает обратную совместимость Windows с Win32 API, поэтому все когда-либо написанные программы MASM32 хорошо работают и на современных ПК.
Ирония в том, что C был изобретен, чтобы упростить перевод UNIX с PDP-7 на PDP-11. Он был разработан как портативный ассемблер, способный пережить кембрийский взрыв аппаратных архитектур 70-х годов. Но в XXI веке аппаратная архитектура развивается так вяло, программы, которые я писал на MASM32 20 лет назад, прекрасно собираются и работают сегодня, но у меня нет уверенности, что приложение на C++, которое я построил в прошлом году на CMake 3.21, будет собираться сегодня на CMake. 3.25.
Второй фрагмент кода — Web Assembly. Это даже не ассемблер макросов, в нем нет «если» и «пока», это скорее человекочитаемый машинный код для вашего браузера. Или какой-нибудь другой браузер. Теоретически любой браузер.
Код веб-сборки вообще не зависит от архитектуры вашего оборудования. Машина, которую она обслуживает, абстрактна, виртуальна, универсальна, называйте ее как хотите. Если вы можете прочитать этот текст, значит, он уже есть на вашей физической машине.
Но самый интересный фрагмент кода — третий. Это ForwardCom — ассемблер Агнер Фог, известный автор руководств по C++ и оптимизации сборки, предлагает. Как и в случае с Web Assembly, это предложение касается не столько ассемблера, сколько универсального набора инструкций, предназначенных для обеспечения не только обратной, но и прямой совместимости. Отсюда и название. Полное название ForwardCom: «открытая, совместимая с пересылкой архитектура набора инструкций». Другими словами, это не столько предложение о собрании, сколько предложение о заключении мирного договора.
Мы знаем, что все самые распространенные архитектурные семейства: x64, ARM и RISC-V имеют разные наборы инструкций. Но никто не знает веских причин, чтобы оставить его таким. Все современные процессоры, за исключением, может быть, самых простых, запускают не тот код, которым вы их кормите, а микрокод, в который они переводят ваш ввод. Таким образом, не только M1 имеет уровень обратной совместимости для Intel, каждый процессор по существу имеет уровень обратной совместимости для всех своих более ранних версий.
Так что же мешает дизайнерам архитектуры договориться об аналогичном уровне, но для прямой совместимости? Кроме противоречивых амбиций компаний, находящихся в прямой конкуренции, ничего. Но если производители процессоров в какой-то момент согласятся на общий набор инструкций, а не на внедрение нового слоя совместимости для каждого другого конкурента, ForwardCom вернет программирование на ассемблере в мейнстрим. Этот уровень прямой совместимости излечит худший невроз каждого программиста на ассемблере: «Что, если я напишу уникальный код для этой конкретной архитектуры, и эта конкретная архитектура устареет через год?»
Благодаря уровню прямой совместимости он никогда не устареет. В этом суть.
Программирование на ассемблере также сдерживается мифом о том, что писать на ассемблере сложно и поэтому непрактично. Предложение Фога решает и эту проблему. Если люди думают, что писать на ассемблере сложно, а на C нет, что ж, давайте просто сделаем ассемблер похожим на C. Не проблема. Нет веских причин для того, чтобы современный язык ассемблера выглядел точно так же, как его дедушка в 50-х годах.
Вы только что сами видели три образца сборки. Ни одна из них не похожа на «традиционную» сборку и не должна быть таковой.
Итак, ForwardCom — это сборка, на которой можно написать оптимальный код, который никогда не устареет, и который не заставляет вас учить «традиционную» сборку. По всем практическим соображениям, это C будущего. Не С++.
Так когда же наконец С++ умрет?
Мы живем в постмодернистском мире. Ничто больше не умирает, кроме людей. Так же, как латынь никогда не умирала на самом деле, как COBOL, Algol 68 и Ada, так и C++ обречен на вечное полусуществование между жизнью и смертью. C++ на самом деле никогда не умрет, его лишь вытеснят из мейнстрима более новые, более мощные технологии.
Ну, не "будут толкать", а "толкают". Я пришел на свою нынешнюю работу программистом на C++, и сегодня мой рабочий день начинается с Python. Я пишу уравнения, SymPy решает их за меня, а затем переводит решение на C++. Затем я вставляю этот код в библиотеку C++, даже не утруждая себя его форматированием, так как clang-tidy все равно сделает это за меня. Статический анализатор проверит, не перепутал ли я пространства имен, а динамический анализатор проверит наличие утечек памяти. CI/CD позаботится о кроссплатформенной компиляции. Профилировщик поможет мне понять, как на самом деле работает мой код, а дизассемблер — почему.
Если я поменяю C++ на «не C++», 80% моей работы останется точно такой же. C++ просто не имеет отношения к большей части того, что я делаю. Может ли это означать, что для меня C++ уже мертв на 80%?
Имидж лидера, созданный методом стабильной диффузии.
Оригинал
🔥 Популярное на этой неделе
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Как начать дружбу с Selenide
30 марта 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
4 признака того, что ваш Instagram взломали (и что делать)
16 ноября 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г.
Categories
- Технологии и IT (26944)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)