Каждый день мы случайно просматриваем наши каналы Hackernoon, Twitter, Reddit или Facebook, никогда не замечая «скрытой руки» наших алгоритмических повелителей, которые рекомендуют нам новости, рекламные акции и специально подобранный контент по различным интересующим темам.
Например, Facebook размещает больше сообщений от ваших друзей и семьи в вашей ленте, в то время как другие платформы больше внимания уделяют релевантности сообщения.
Эти алгоритмы обладают большой силой в формировании нашей интуиции о том, что происходит в мире, но иногда они могут быть несправедливыми, предвзятыми или эксплуатироваться, в основном в ущерб конечным пользователям. Мы не будем здесь говорить об этичности таких алгоритмов, а скорее опишем основную техническую идею и проблемы, стоящие за ней. Итак, давайте рассмотрим, что для этого нужно и как мы будем это делать?
Алгоритмические арбитры социальных сетей
Лента социальных сетей состоит из контента, который создают ее пользователи. Все сообщения попадают в одну гигантскую глобальную очередь, откуда они соответственно доставляются в каналы пользователей. Тысячи таких постов будут соревноваться друг с другом, чтобы подняться в глазах нашего алгоритмического арбитра.
Как только алгоритм примет решение, лишь немногие из них попадут в нашу ленту новостей. Это принятие решений называется оценкой, и оно принимает во внимание определенные параметры.
Есть много способов оценить пост в зависимости от его текстового, визуального или звукового содержания. Некоторые сообщения могут включать видео или изображения, например, требующие машинного обучения, чтобы отличить NSFW или спам от обычного сообщения, но это другая тема.
Когда дело доходит до количества — чем больше пользователей на одной платформе, тем больше контента нужно оценивать, фильтровать и сопоставлять. Нам нужен быстрый и естественный способ держать ленту пользователей актуальной для них.
Задача здесь состоит в том, чтобы создать масштабируемый и эффективный алгоритм подсчета очков, понятный конечному пользователю и предоставляющий органичный и аутентичный контент.
В идеальном мире это было бы сделано прозрачным и стандартизированным способом, но эти правила обычно скрыты за сложными метриками.
Инвентарь
Давайте представим простой пост и его структуру, чтобы мы могли изучить его свойства и выбрать наиболее подходящие параметры для нашей цели.
Вот пример структуры, которую мы можем использовать для моделирования нашей формулы оценки:
СООБЩЕНИЕ
- ID: 0,
- TYPE: "текст" // это может быть видео, изображение, текст - в данном случае давайте просто текст
- СТРАНА: "DE"
- CREATION_DATE: "1234556789" // дата и время создания
- ПУНКТЫ: 502 // баллы представляют собой «лайки» или «плюсы».
- FLAGS: "соответствует" // это флаг модели машинного обучения
- СОДЕРЖАНИЕ: " … "
Мы хотим, чтобы наш алгоритм ранжирования учитывал ГЕО. Это означает, что основным каналом каждого пользователя является поток, основанный на его местной стране/языке. Эти локальные потоки иногда называют сегментами.
Далее мы хотим взять некоторые основные параметры из поста. Два ключевых параметра — это время создания поста и количество баллов. Время создания полезно, так как мы хотим сделать ленту хронологической — показывать от самого нового к самому старому, двигаясь сверху вниз. Количество баллов или лайков информирует нас о вовлеченности пользователей, но это может быть любой другой параметр по вашему выбору, к которому у вас есть доступ или который имеет отношение к вашему варианту использования. В этом примере мы будем использовать количество баллов в качестве вирусного индикатора.
Третий параметр, который нам нужно ввести, — это общий параметр управления, который мы можем использовать для ручной настройки и выполнения глобальных переопределений с помощью чего-то, называемого гравитацией.
Функция оценки алгоритма социальных сетей
Вот как будет выглядеть оценочная функция:
Оценка = (P-1) / (T+2)^G
куда,
P = количество баллов за сообщение (-1 просто аннулирует голос отправителя за его собственное сообщение)
T = время с момента отправки (в часах — это важно)
G = гравитация
Влияние гравитации и времени на алгоритм
Гравитация и время оказывают значительное влияние на счет.
Как правило, эти вещи должны быть верны:
- Оценка уменьшается по прошествии (T) времени, а это означает, что более старые сообщения будут получать все более и более низкие оценки.
- Оценка уменьшается намного быстрее для старых постов, если (G) гравитация увеличивается
Моделирование алгоритма
Намного легче понять, если мы изобразим алгоритм визуально. Мы можем использовать Wolfram Alpha, чтобы построить этот график и настроить его — вы можете сделать это здесь
Оценка с течением времени
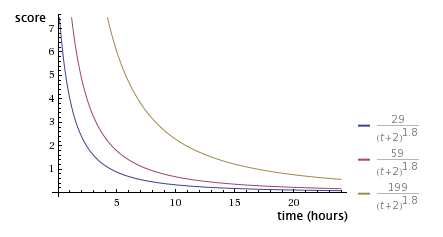
Используя приведенную выше формулу, за 24 часа с 3 разными сообщениями график показывает нам, что желтый, набравший наибольшее количество баллов (199), падает вниз, который пользователи кормят гораздо медленнее. Другие посты начинают затухать гораздо быстрее, но это уравновешивается параметром времени в формуле, который дает нам красивую кривую, делающую затухание плавным.
Как вы можете видеть, оценка сильно уменьшается с течением времени, например, * 24-часовая старая запись * будет иметь очень низкую оценку независимо от того, сколько баллов она набрала, освобождая место для новых сообщений и поддерживая поток сообщений в сети. кормить естественным образом.
Гравитация во времени
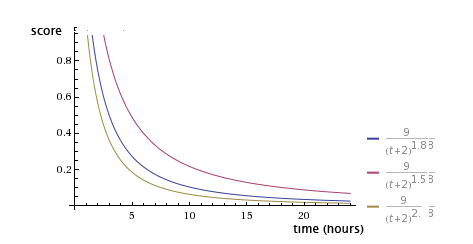
Здесь мы подправили только гравитацию, сохранив при этом одинаковое количество баллов для всех трех постов. Как вы можете видеть на графике, счет уменьшается намного быстрее, чем больше гравитация.
Чем больше гравитация поста, тем быстрее он падает в ленте пользователя.
Сильные стороны алгоритма
- Простая и масштабируемая формула
- Фид локальный, но доставка глобальная
- Хорошо работает, когда мы хотим выделить/подтолкнуть новые вещи глобально или локально
- Поддерживает ручное управление и пост-вмешательство
- Отсутствие дискриминации/предвзятости в инвентаризации или данных
- Предотвращает распространение непопулярных или нежелательных сообщений, разрушая их с помощью гравитации, оставляя больше места для целевого и организованного источника подачи
Слабые стороны алгоритма
- Настенные часы «наказывают» сообщение, даже если его никто не читает (например, ночью). Это может решить время, выраженное в тиках фактической активности.
- Пост, который не попал в аудиторию с первого раза, возможно, из-за плохого заголовка, может никогда не восстановиться, даже если позже наберется шквал баллов, намного превышающий то, что получают новые материалы.
Заключение: алгоритмы социальных сетей
Несмотря на свои недостатки, эта формула может быть усовершенствована и дополнена, чтобы преодолеть их, но даже в самой простой форме она показывает, как использование всего пары параметров иногда может быть достаточным для управления и обслуживания большого количества контента в естественной, удобной форме. органический способ.
Ни один алгоритм не идеален, хороший всегда развивается.
- Главное фото от charlesdeluvio на Unsplash*